Python ヾ (≥ ▽≤ *) o SET set type
1, Concept of set
Set is one of the data types of Python, which is the same as the concept of set in mathematics
Before explaining Python sets, I think it is necessary to review the main categories of mathematical sets: Union, intersection and difference
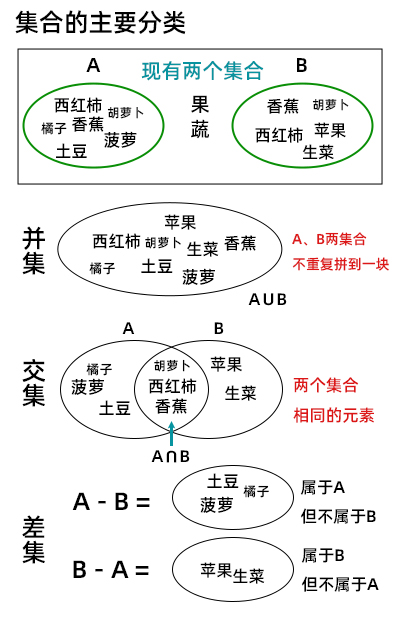
Collections in Python
If necessary, Python collection is definitely a very convenient data type
Python collection features
- Natural de duplication, each element is unique and different from each other, which is also the main feature of the set
- Only immutable elements can be stored. Variable data types such as lists and dictionaries cannot be stored in dictionaries
- The collection is out of order
Simple overview: a collection is an unordered and non repetitive data type
2, Create a new collection 🤶🏻
In Python, there are two common ways to create a new collection
-
Create by object instantiation
- If it is an empty set, you can directly use the built-in function of set(), such as s = set(), where s is the variable of an empty set
- set() can also get sets by converting other data types into sets
You can see that there are many 1s in the string, but due to the de duplication of the set, essentially only the last 1 is saved
In the following example, I will use set() with the built-in function of range() to quickly create a new dictionarys = set("1234511") print(s) # The result is {'2', '4', '3', '5', '1'}
- If it is an empty set, you can directly use the built-in function of set(), such as s = set(), where s is the variable of an empty set
-
Direct definition
You can directly create a new collection through a syntax similar to that defined by other data types
It is worth noting that the symbols of the set and the dictionary use curly braces, but the dictionary is a key value pair writing format with colon, and the set is a comma separated writing format# Definition of dictionary dic = {"language": "Python", "Get started": "simple"} # Definition of set s = {1, 1, 1, 1, 'dear', 'love', 'of', 'read', 'person', 'you', 'good'}
3, Using de duplication 👲🏻
As mentioned above, sets are naturally de duplicated, so you can use the de duplication of sets to do something
Zhang San used a cover up and created several fake Zhang San. Let's see how teacher Luo treats Zhang San
# name = ['Zhang San', 'Zhang San', 'Zhang San', 'Zhang San', 'Zhang San', 'Zhang San', 'Zhang San', 'Zhang San', 'Zhang San', 'Zhang San', 'Zhang San', 'Luo Xiang']
name = ["Zhang San"] * 10 # You can also add multiple Zhang San in this way
name.append("Luo Xiang")
name = set(name)
print(name)
{'Luo Xiang', 'Zhang San'}
Yes, you can use the collection to break Zhang San's deception and find out the only Zhang San
Next, let's look at a de duplication application. There is no repeat lottery
Program logic: use the random standard library to randomly select a name, and add the name to the collection. If it is repeated, the addition operation will not be carried out. The cyclic condition is to judge whether the number of people in the collection is less than 3
import random
selected, name = set(), ["Zhang San", "Li Si", "Xiao Ming", "Li Hua", "John", "Jone", "Mark", "Bill", "PrettyGirl"]
while len(selected) < 3:
selected.add(random.choice(name))
print(selected)
4, Set + operator 🏆
Set + operator, I personally think, is the essence of Python set, which is very convenient to use
Create two sets A and B respectively
A = {"Tomatoes", "a mandarin orange", "Banana", "pineapple", "Carrot", "potato"}
B = {"Banana", "Carrot", "Tomatoes", "Apple", "romaine lettuce"}
-
Union
print(A | B) # Union
{'Tomatoes', 'Apple', 'pineapple', 'Carrot', 'Banana', 'romaine lettuce', 'a mandarin orange', 'potato'} -
intersection
print(A & B) # Difference set
{'Tomatoes', 'Carrot', 'Banana'} -
Difference set
print(A-B) # A but not B print(B-A) # Belongs to B but not A
{'pineapple', 'potato', 'a mandarin orange'} {'Apple', 'romaine lettuce'}
The results returned by the above operators are of collection type
Method of collection
The following will explain the methods of collection objects in Python
1) .add(elem)
Add element elem to the collection
Because it is added to the collection, if the added element already exists, no operation will be performed
s = set(range(1, 10)) print(s) s.add(0) # Add an element 0 s.add(10) # Add an element 10 print(s) s.add(2) # Add another element 2 print(s)
{1, 2, 3, 4, 5, 6, 7, 8, 9}
{0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
{0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
2) .update(elems)
Update the collection and add all elements from others. If the added element already exists, no operation will be performed
This elems passes in an iteratable object, which means that data types such as string, tuple and list can be passed in
s = set(range(1, 6))
print(s)
s.update({6: 5, 8: 1, 7: 2}) # Key is the dictionary value
s.update("Hello world") # If it is a string, take each character
s.update([11, 12, 13])
s.update({11, 12, 13}) # Repeat the above list elements without any operation
print(s)
{1, 2, 3, 4, 5}
{1, 2, 3, 4, 5, 6, 7, 8, 'circles', 11, 12, 13, 'good', 'you', 'life'}
3) .remove(elem)
Remove element elem from collection
If elem does not exist in the collection, KeyError will be raised. You can judge whether this element exists first
s = set(range(1, 10))
target = 1
if target in s: # Determine whether this element exists
s.remove(target)
4) .discard(elem)
If the element elem exists in the collection, it is removed
This method is like remove() + a combined version that determines whether this element exists
s = set(range(1, 10)) target = 1 s.discard(target) s.discard(target) # At this time, the element does not exist, but no error will be reported
5) .pop()
To remove and return any element from a collection is to remove an element at random and return it
If the collection is empty, KeyError will be raised. You can judge whether the collection is empty first
Well ~ ♪ (´▽ '), these are all the statements in the official manual, but you will find that this is not completely correct in practical use pop() method can remove elements randomly sometimes, but sometimes it can't. let's see why 🍺
Through practical use, I found that The pop() method has the following effects: 👇
-
When all elements in the collection are numbers:
The smallest number will be removed and the changed number will be returned, which is not random
s = set(range(1, 10)) print(s) print(s.pop()) print(s)
{1, 2, 3, 4, 5, 6, 7, 8, 9} 1 {2, 3, 4, 5, 6, 7, 8, 9} -
When all elements in the collection are non numeric:
It is indeed consistent with the statement in the official manual. It can randomly delete non digital content and return it
s = set("Hello world Python") print(s.pop()) -
Elements in the collection are both numeric and non numeric:
This situation is equivalent to a combination of the above two. If the random number is a number, it will be in the way of number, and if it is not a number, it will be installed in the way of non number
s = set("Hello world Python") s.update(set(range(1, 6))) print(s.pop())
I'm using it When pop() tests a set of numbers, I find that the same element is removed and returned every time. I think it's a coincidence, but after dozens of tests, I find that it's not the same thing. Finally, I found this rule.
Does this method feel like a chicken rib? But in fact, it can be applied in the direction of lottery and so on
s_user = {"Zhang San", "Li Si", "Xiaomei", "Wang Hua", "Xiao Ming", "Li Hua"}
awarded = []
while len(awarded) < 3:
awarded.append(s_user.pop())
print(f"Award winning users: {' '.join(awarded)}")
6) .difference_update(elems)
Update the collection and remove the elements that also exist in others, that is, remove the elements that exist in both collections
s = set(range(10))
s.difference_update({1, 5, 6})
print(s)
{0, 2, 3, 4, 7, 8, 9}
7) .copy()
Returns the shallow copy of this collection
Regarding copy, Python has two types: deep copy and shallow copy
s = set(range(10)) new_s = s.copy()
8) .clear()
Remove all elements from the collection
s = set(range(10)) s.clear()
9) .isdisjoint(other)
Judge whether the collection and other collection contain the same elements. If it does not return True, otherwise it returns False
s = set(range(10))
print(s.isdisjoint({1, 2, 3}))
Returns True if both collections are empty
print(set().isdisjoint(set())) # Return True
10) .difference()
Returns the difference set of a set. This method works like the set + operator 🏆 Operator used in - same
A = {"Tomatoes", "a mandarin orange", "Banana", "pineapple", "Carrot", "potato"}
B = {"Banana", "Carrot", "Tomatoes", "Apple", "romaine lettuce"}
print(A.difference(B))
print(B.difference(A))
{'potato', 'pineapple', 'a mandarin orange'}
{'Apple', 'romaine lettuce'}
11) .intersection()
Returns the intersection of a set. This method works like the set + operator 🏆 Operators used in & are the same
A = {"Tomatoes", "a mandarin orange", "Banana", "pineapple", "Carrot", "potato"}
B = {"Banana", "Carrot", "Tomatoes", "Apple", "romaine lettuce"}
print(A.intersection(B))
{'Tomatoes', 'Banana', 'Carrot'}
12) .union()
Returns the union of sets. This method works like the set + operator 🏆 Use the same operator |
A = {"Tomatoes", "a mandarin orange", "Banana", "pineapple", "Carrot", "potato"}
B = {"Banana", "Carrot", "Tomatoes", "Apple", "romaine lettuce"}
print(A.union(B))
{'Tomatoes', 'Apple', 'pineapple', 'Carrot', 'Banana', 'romaine lettuce', 'a mandarin orange', 'potato'}
reference material
- Set concept: Wikipedia
- Python official Manual: Built in type