I don't know if you have ever encountered such a situation, such as an e-book in pdf format. We often browse part of it, and the e-book has a large number of pages. Whenever you need to browse, you need to turn to the corresponding page number, which is a little cumbersome.
In other cases, for example, if we want to share part of the contents of the pdf file to others, we also need to use pdf paging, which can not only analyze the specified contents, but also reduce the size of the sent file O(∩∩) O ha~
In short, pdf pagination is something we will inevitably encounter in real life. When you encounter, how do you solve it?
In Python, pdf pagination is extremely simple. You only need to run a few lines of code to achieve it. No matter how large your pdf file is, let's take a look~
Note: I annotate the function of each part of the code, and then come back to the back of the code. Pay attention to check it~
from PyPDF2 import PdfFileReader, PdfFileWriter
import os
def split(path, page_num):
try: # The capture value is an abnormal error, that is, when only one page number is entered
page_start, page_end = page_num.split()
except ValueError:
page_start = page_num
page_end = page_num
output_name = os.path.splitext(path)[0] + f'({page_start}-{page_end}).pdf' # Output split pdf file
page_start, page_end = int(page_start), int(page_end) # Convert page number to integer type
if os.path.splitext(path)[1] == '': # Determine whether the file format ends in. pdf
path = path + ".pdf"
try:
pdf = PdfFileReader(path) # Read pdf
except FileNotFoundError:
print("Error:Please confirm your input pdf Whether the file exists!")
return
pdf_writer = PdfFileWriter() # pdf write object
if page_start < 1 or page_end > pdf.getNumPages(): # Judge whether the page number is within a reasonable range, that is, whether it is less than or greater than the number of pages of pdf file
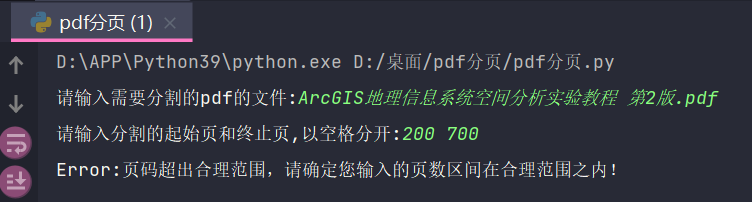
print("Error:The page number exceeds the reasonable range. Please make sure that the range of pages you entered is within the reasonable range!")
return
for page in range(page_start-1, page_end): # The range of pdf pages to be divided. Since the number of pages read starts from 0, it is reduced by 1
pdf_writer.addPage(pdf.getPage(page)) # pdf pages are read, stored in memory and not written
with open(output_name, 'wb') as output_pdf:
pdf_writer.write(output_pdf) # Start writing pdf in the specified page range
print("After paging, please check:" + output_name)
if __name__ == '__main__':
source_path = input("Please enter the to be split pdf File:") # pdf file to be split
pages = input("Please enter the start page and end page of the split,Separate with spaces:")
split(source_path, pages)
In fact, the main code is as follows:
pdf = PdfFileReader(path) # Read pdf
pdf_writer = PdfFileWriter() # pdf write object
for page in range(page_start, page_end): # pdf page number interval to be split
pdf_writer.addPage(pdf.getPage(page)) # pdf pages are read, stored in memory and not written
with open(output_name, 'wb') as output_pdf:
pdf_writer.write(output_pdf) # Start writing pdf in the specified page range
I just added some code for exception error capture and resolution on the basis of it, and realized the recycling of the code, not just for a pdf file.
Code usage display:
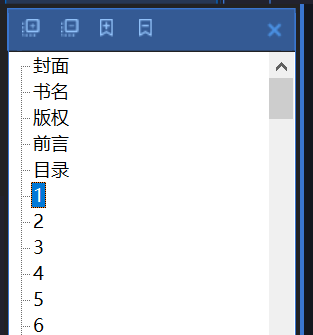
1. Source file

The number of pages in the book is still quite large

2. Target page range

Note that although the page number here is 271, it does not mean that it is 271, because the page number of the read pdf file is the page number of the whole file, such as the cover of the book and the number of pages in the table of contents.
Therefore, we can simply calculate the difference between the first page of the book page and the cover page. The difference here is 13 pages, so 271 + 13 = 284 is used as the starting page of segmentation. The number of pages to be intercepted corresponds to the page number on the book is 276276 + 13 = 289, so the ending page is 289

3. Code operation
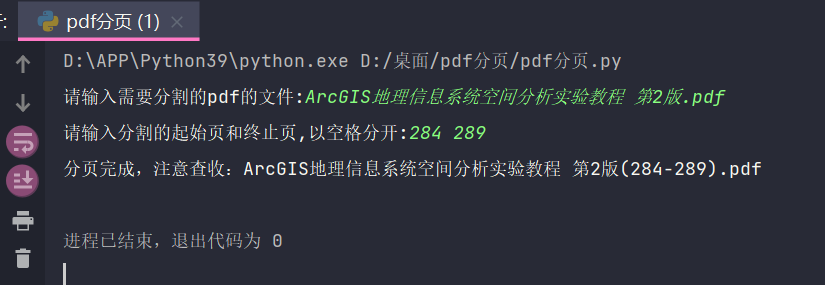
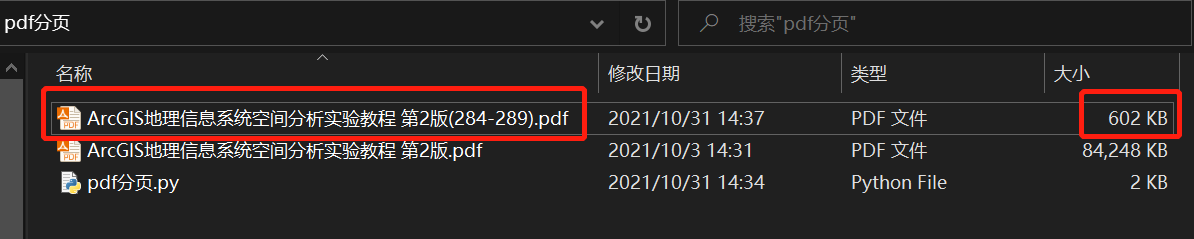
4. Code display of exception capture:
The start page entered is less than 1:
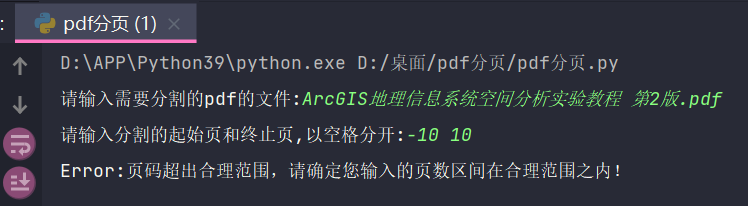
The pdf page number is only 600 in total, and then the end page is 700:
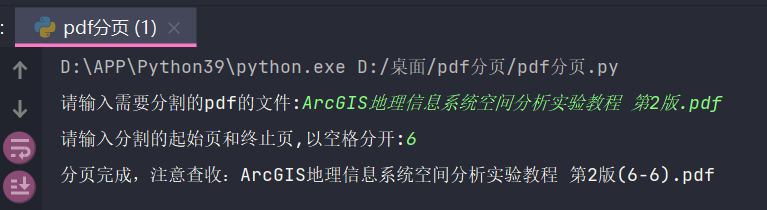
5. Others
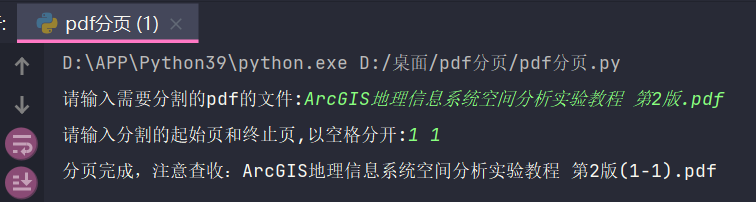
The interval is required, but you can enter 1,1:
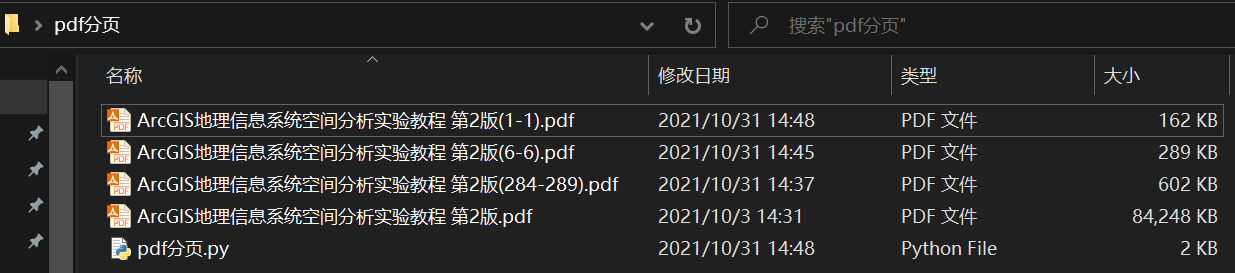
The code can continue to be improved. Interested partners can start their smart head, melon seeds haha