python picture crawler experience
1, Process
1. Be familiar with the basic information of crawler web pages
2. Find the url of the picture in the web page source and try to open it
3. Writing python scripts
4. Execute script to download pictures
2, Familiar with the basic information of crawler web pages
Before crawling, first you need to understand the information of the web page where your crawler's picture is located, and find the picture according to these information, so as to find the url download link of the picture and try to download. If it is successful, it indicates that OK can carry out python scripted batch execution in this way.
Yimeng Tu Society: https://moetu.club/612.html For example:
Open the web page as follows:

The pictures are what we need, that is, the pictures we need to download
It is usually hidden in the source code of the web page, so we can check the source code directly
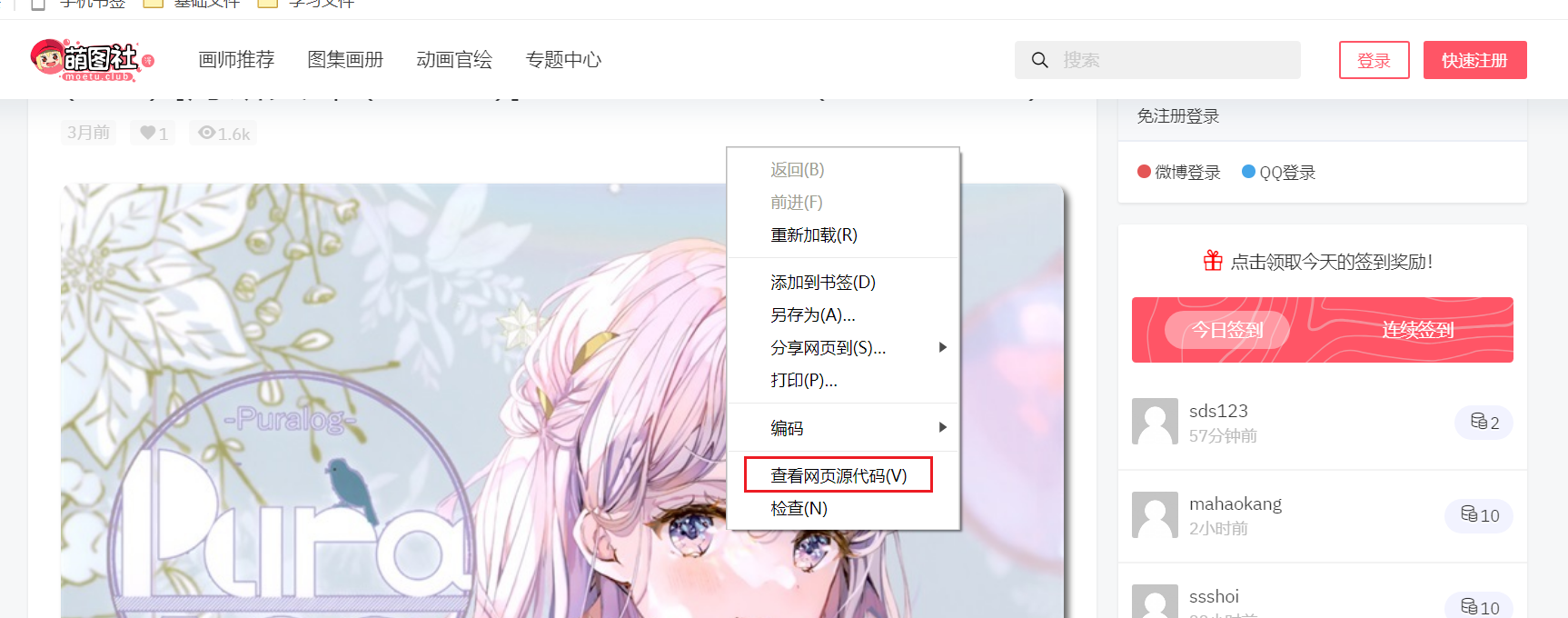
You will find that a pile of code looks hard. Don't worry at this time. Teach you how to find pictures by hand
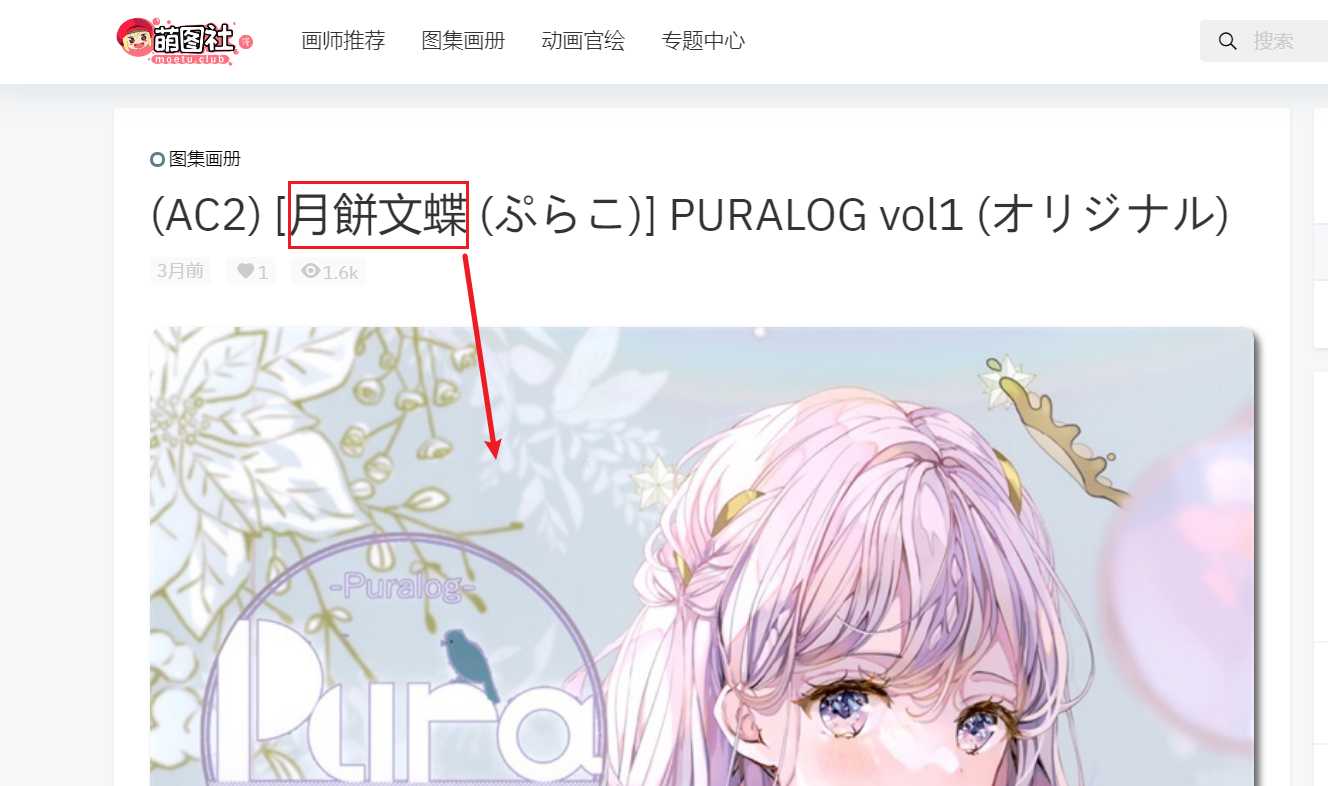
The most recent symbolic text of the specific picture on the web page is [moon cake Wendie]. We copy it and then search on the page
You will find that the next stroke, alas, these blue are links. The links look familiar. They are links to pictures
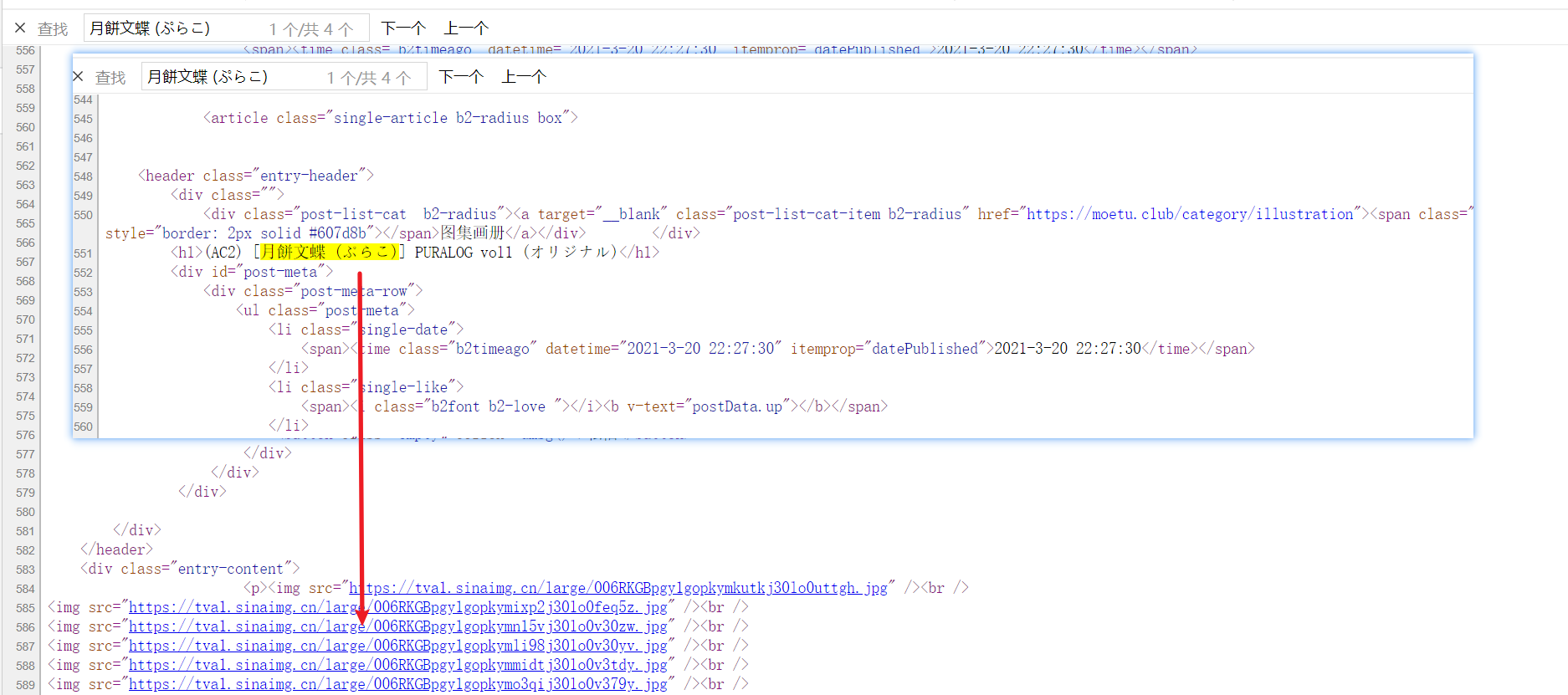
Let's open it and have a look
It's really the picture we need. The task of this stage is completed. As long as we find the picture url we need, we can download it.
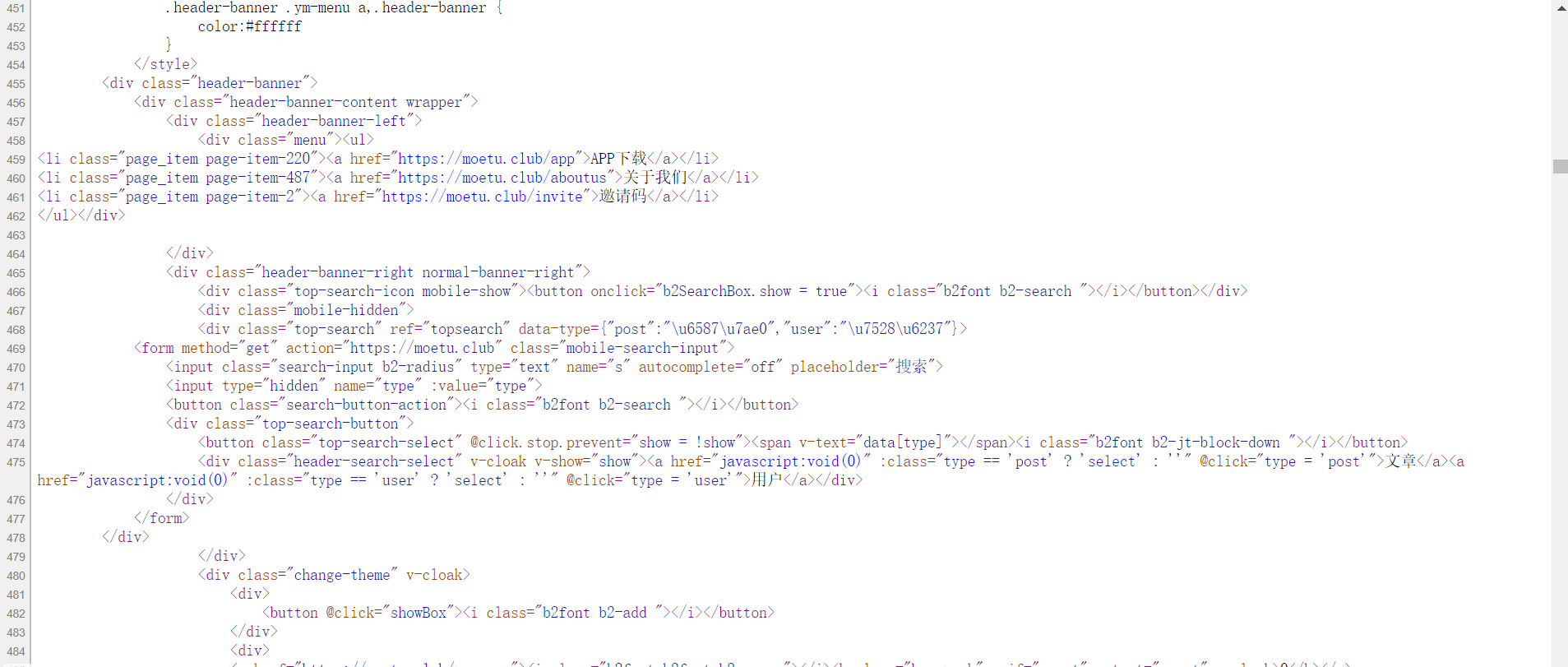
The source code of some web pages may only display the url of the image part, which needs to be spliced by ourselves
Example:‘ https://tva1.sinaimg.cn/large/ ’+Variable + ' jpg’
3, Writing python scripts
1. Write method function
Analysis: steps to download pictures,
(1) First, open the source code according to the url of the web page, and then regularly extract the url of the picture from the source code
(2) Download the extracted url
(3) Pass in the url, call the (1) method, and then pass the value returned by the 1 method to the (2) method for download
2. Write a method to get the picture url:
import urllib.request # Actions for linking
import re # For regular extraction of data
# Get the picture link address in the url
def img_png(url):
page = urllib.request.urlopen(url) # It is used to open a remote url and send a request to the link to get the results
html_a = page.read() # Get the source code of the page
html_b = html_a.decode('utf-8') # Source code formatting
png = re.findall(r'img src="(.*?)" /><br',html_b) # Regular extract the required picture link information
# The required data can be directly intercepted according to the left and right boundaries in regular expressions (. *?) Represents the content to be intercepted
# In this paper, img src = "and" / > < Br are extracted as boundaries, which is exactly what we need
print('This is the link address of the picture we got')
print(png)
return png
url = 'https://moetu.club/612.html'
a = img_png(url)
Let's take a look at the results after implementation:
This is the link address of the picture we got ['https://tva1.sinaimg.cn/large/006RKGBpgy1gopkymkutkj30lo0uttgh.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gopkymixp2j30lo0feq5z.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gopkymn15vj30lo0v30zw.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gopkymli98j30lo0v30yv.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gopkymmidtj30lo0v3tdy.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gopkymo3qij30lo0v379y.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gopkymrt8uj30lo0v3jyx.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gopkyomlvij30lo0v3tfe.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gopkymxdlkj30lo0v3jyi.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gopkymzxnfj30lo0v3n4i.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gopkymza5cj30lo0v310d.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gopkyn2tqdj30lo0v3agn.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gopkyn0ulfj30lo0v3wje.jpg']
At this time, we can directly see the picture by visiting a single link.
So far, the method for us to obtain the link of the picture from the url has been completed. You can call this method directly when you need to use it;
3. How to write and download pictures
# The following is how to write a picture download
def img_downlad(list):
# Set the location where you want to save the file
path = 'D:\\test1'
# Judge whether the folder exists or not, and create it if it does not exist
if not os.path.isdir(path):
os.makedirs(path)
path = path +'\\' # The folder location where the picture was last saved
x = 0 # Add a variable to name the picture
# for loop to extract the link address of the picture and download it
for list_d in list:
print(list_d)
try: # Error judgment mechanism, the card owner will not make an error
print('----------The pictures are starting to download----------')
urllib.request.urlretrieve(list_d,'{0}{1}.jpg'.format(path,x)) #Download the picture to the specified location
x = x + random.randint(5,999999) # Random numbers ensure that they are inconsistent every time
except:
print('Download failed')
You can write a list of links with pictures, then call the download function to see if the download is successful.
So far, our method of downloading pictures is finished.
4. Call two methods to download pictures
url = 'https://moetu.club/612.html '# pass in the url to download a = img_png(url) # Call img_png method to get the picture link address on the web page b = img_downlad(a) # Call img_ The downlad method downloads the image to the local
The following is the result of the execution
This is the link address of the picture we got ['https://tva1.sinaimg.cn/large/006RKGBpgy1gopkymkutkj30lo0uttgh.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gopkymixp2j30lo0feq5z.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gopkymn15vj30lo0v30zw.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gopkymli98j30lo0v30yv.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gopkymmidtj30lo0v3tdy.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gopkymo3qij30lo0v379y.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gopkymrt8uj30lo0v3jyx.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gopkyomlvij30lo0v3tfe.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gopkymxdlkj30lo0v3jyi.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gopkymzxnfj30lo0v3n4i.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gopkymza5cj30lo0v310d.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gopkyn2tqdj30lo0v3agn.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gopkyn0ulfj30lo0v3wje.jpg'] https://tva1.sinaimg.cn/large/006RKGBpgy1gopkymkutkj30lo0uttgh.jpg ----------The pictures are starting to download---------- https://tva1.sinaimg.cn/large/006RKGBpgy1gopkymixp2j30lo0feq5z.jpg ----------The pictures are starting to download---------- https://tva1.sinaimg.cn/large/006RKGBpgy1gopkymn15vj30lo0v30zw.jpg ----------The pictures are starting to download---------- https://tva1.sinaimg.cn/large/006RKGBpgy1gopkymli98j30lo0v30yv.jpg ----------The pictures are starting to download---------- https://tva1.sinaimg.cn/large/006RKGBpgy1gopkymmidtj30lo0v3tdy.jpg ----------The pictures are starting to download---------- https://tva1.sinaimg.cn/large/006RKGBpgy1gopkymo3qij30lo0v379y.jpg ----------The pictures are starting to download---------- https://tva1.sinaimg.cn/large/006RKGBpgy1gopkymrt8uj30lo0v3jyx.jpg ----------The pictures are starting to download---------- https://tva1.sinaimg.cn/large/006RKGBpgy1gopkyomlvij30lo0v3tfe.jpg ----------The pictures are starting to download---------- https://tva1.sinaimg.cn/large/006RKGBpgy1gopkymxdlkj30lo0v3jyi.jpg ----------The pictures are starting to download---------- https://tva1.sinaimg.cn/large/006RKGBpgy1gopkymzxnfj30lo0v3n4i.jpg ----------The pictures are starting to download---------- https://tva1.sinaimg.cn/large/006RKGBpgy1gopkymza5cj30lo0v310d.jpg ----------The pictures are starting to download---------- https://tva1.sinaimg.cn/large/006RKGBpgy1gopkyn2tqdj30lo0v3agn.jpg ----------The pictures are starting to download---------- https://tva1.sinaimg.cn/large/006RKGBpgy1gopkyn0ulfj30lo0v3wje.jpg ----------The pictures are starting to download----------
The final results show

5. Total code
import random # For adding random numbers
import urllib.request # Actions for linking
import re # For regular extraction of data
import os # For file processing
# Get the picture link address in the url
def img_png(url):
page = urllib.request.urlopen(url) # It is used to open a remote url and send a request to the link to get the results
html_a = page.read() # Get the source code of the page
html_b = html_a.decode('utf-8') # Source code formatting
png = re.findall(r'img src="(.*?)" /><br',html_b) # Regular extract the required picture link information
# The required data can be directly intercepted according to the left and right boundaries in regular expressions (. *?) Represents the content to be intercepted
# In this paper, img src = "and" / > < Br are extracted as boundaries, which is exactly what we need
print('This is the link address of the picture we got')
print(png)
return png
# The following is how to write a picture download
def img_downlad(list):
# Set the location where you want to save the file
path = 'D:\\test1'
# Judge whether the folder exists or not, and create it if it does not exist
if not os.path.isdir(path):
os.makedirs(path)
path = path +'\\' # The folder location where the picture was last saved
x = 0 # Add a variable to name the picture
# for loop to extract the link address of the picture and download it
for list_d in list:
print(list_d)
try: # Error judgment mechanism, the card owner will not make an error
print('----------The pictures are starting to download----------')
urllib.request.urlretrieve(list_d,'{0}{1}.jpg'.format(path,x)) #Download the picture to the specified location
x = x + random.randint(5,999999) # Random numbers ensure that they are inconsistent every time
except:
print('Download failed')
# url to download the picture
url = 'https://moetu.club/543.html'
# Call img_png function gets the picture link in the web page
a = img_png(url_list_one)
#Call img_ The downlad function downloads the file locally
b = img_downlad(a)
4, Expand
1. Get the url address of each web page containing pictures from the list
It is very similar to the method of obtaining the link of the picture from the url. It also grabs the url link containing the web page from the source code of the list page and outputs the list
Then use the for loop to get the url from the output list, and then link the url to get the picture
url = 'https://moetu.club/category/illustration/page/2'
# Visit the link and get the source code of the list
page = urllib.request.urlopen(url).read().decode('utf-8')
# Read the url of the web page in the list
url_list = re.findall(r'href="(.*?)" rel="nofollow"',page)
# A for loop takes out the url and passes it to img_png executes to get the picture link and then calls img_downlad Download
for url_list_one in url_list:
try:
a = img_png(url_list_one)
b = img_downlad(a)
except:
print('Download error')
Execution results:
This is the link address of the picture we got ['https://tva1.sinaimg.cn/large/006RKGBpgy1gmqt1ngus2j30lo0ueq9d.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gmqt1nfis1j30lo0uetev.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gmqt1nmxucj30lo0uen4f.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gmqt1nhhmpj30lo0ue0z8.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gmqt1n16lxj30lo0ukq86.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gmqt1mkg8vj30lo0uetd9.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gmqt1mgln6j30lo0esq6m.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gmqt1ncvp3j30lo0urq92.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gmqt1nqaatj30lo0uen6h.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gmqt1nclcnj30lo0ujq90.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gmqt1nmr7pj30lo0uegsi.jpg'] https://tva1.sinaimg.cn/large/006RKGBpgy1gmqt1ngus2j30lo0ueq9d.jpg ----------The pictures are starting to download---------- https://tva1.sinaimg.cn/large/006RKGBpgy1gmqt1nfis1j30lo0uetev.jpg ----------The pictures are starting to download---------- https://tva1.sinaimg.cn/large/006RKGBpgy1gmqt1nmxucj30lo0uen4f.jpg ----------The pictures are starting to download---------- https://tva1.sinaimg.cn/large/006RKGBpgy1gmqt1nhhmpj30lo0ue0z8.jpg ----------The pictures are starting to download---------- https://tva1.sinaimg.cn/large/006RKGBpgy1gmqt1n16lxj30lo0ukq86.jpg ----------The pictures are starting to download---------- https://tva1.sinaimg.cn/large/006RKGBpgy1gmqt1mkg8vj30lo0uetd9.jpg ----------The pictures are starting to download---------- https://tva1.sinaimg.cn/large/006RKGBpgy1gmqt1mgln6j30lo0esq6m.jpg ----------The pictures are starting to download---------- https://tva1.sinaimg.cn/large/006RKGBpgy1gmqt1ncvp3j30lo0urq92.jpg ----------The pictures are starting to download---------- https://tva1.sinaimg.cn/large/006RKGBpgy1gmqt1nqaatj30lo0uen6h.jpg ----------The pictures are starting to download---------- https://tva1.sinaimg.cn/large/006RKGBpgy1gmqt1nclcnj30lo0ujq90.jpg ----------The pictures are starting to download---------- https://tva1.sinaimg.cn/large/006RKGBpgy1gmqt1nmr7pj30lo0uegsi.jpg ----------The pictures are starting to download---------- This is the link address of the picture we got ['https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5ndoo2j30lo0utwlt.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5nd32kj30lo0v6die.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5ncq1vj30lo0v6wlg.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5nfr5gj30lo0v6ag7.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5nf12yj30lo0v6450.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5nec2oj30lo0v6qap.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5nlpg1j30lo0v6n3p.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5nn4dlj30lo0v6dkq.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5nu8ujj30lo0v60xc.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5nqdnaj30lo0vednt.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5np4tbj30lo0v6n57.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5nopxtj30lo0f4tcl.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5nx8eaj30lo0fiq80.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5nuxabj30lo0v6794.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5nurkaj30lo0v6jvg.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5ny748j30lo0vpdly.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5nzqtvj30lo0v6dlo.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5o0toij30lo0v6tck.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5o18xqj30lo0v642r.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5o4ruij30lo0v60w3.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5o6giej30lo0v6q8d.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5o5visj30lo0v6dki.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5o8cm0j30lo0v6gsz.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5obk0bj30lo0v6wls.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5oa8zfj30lo0v6jx7.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5ock1lj30lo0v6tes.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5odwn4j30lo0v643j.jpg', 'https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5ofv37j30lo0vlwja.jpg'] https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5ndoo2j30lo0utwlt.jpg ----------The pictures are starting to download---------- https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5nd32kj30lo0v6die.jpg ----------The pictures are starting to download---------- https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5ncq1vj30lo0v6wlg.jpg ----------The pictures are starting to download---------- https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5nfr5gj30lo0v6ag7.jpg ----------The pictures are starting to download---------- https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5nf12yj30lo0v6450.jpg ----------The pictures are starting to download---------- https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5nec2oj30lo0v6qap.jpg ----------The pictures are starting to download---------- https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5nlpg1j30lo0v6n3p.jpg ----------The pictures are starting to download---------- https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5nn4dlj30lo0v6dkq.jpg ----------The pictures are starting to download---------- https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5nu8ujj30lo0v60xc.jpg ----------The pictures are starting to download---------- https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5nqdnaj30lo0vednt.jpg ----------The pictures are starting to download---------- https://tva1.sinaimg.cn/large/006RKGBpgy1gmof5np4tbj30lo0v6n57.jpg ----------The pictures are starting to download----------
Total code:
import random # For adding random numbers
import urllib.request # Actions for linking
import re # For regular extraction of data
import os # For file processing
# Get the picture link address in the url
def img_png(url):
page = urllib.request.urlopen(url) # It is used to open a remote url and send a request to the link to get the results
html_a = page.read() # Get the source code of the page
html_b = html_a.decode('utf-8') # Source code formatting
png = re.findall(r'img src="(.*?)" /><br',html_b) # Regular extract the required picture link information
# The required data can be directly intercepted according to the left and right boundaries in regular expressions (. *?) Represents the content to be intercepted
# In this paper, img src = "and" / > < Br are extracted as boundaries, which is exactly what we need
print('This is the link address of the picture we got')
print(png)
return png
# The following is how to write a picture download
def img_downlad(list):
# Set the location where you want to save the file
path = 'D:\\test1'
# Judge whether the folder exists or not, and create it if it does not exist
if not os.path.isdir(path):
os.makedirs(path)
path = path +'\\' # The folder location where the picture was last saved
x = 0 # Add a variable to name the picture
# for loop to extract the link address of the picture and download it
for list_d in list:
print(list_d)
try: # Error judgment mechanism, the card owner will not make an error
print('----------The pictures are starting to download----------')
urllib.request.urlretrieve(list_d,'{0}{1}.jpg'.format(path,x)) #Download the picture to the specified location
x = x + random.randint(5,999999) # Random numbers ensure that they are inconsistent every time
except:
print('Download failed')
url = 'https://moetu.club/category/illustration/page/2'
# Visit the link and get the source code of the list
page = urllib.request.urlopen(url).read().decode('utf-8')
# Read the url of the web page in the list
url_list = re.findall(r'href="(.*?)" rel="nofollow"',page)
# A for loop takes out the url and passes it to img_png executes to get the picture link and then calls img_downlad Download
for url_list_one in url_list:
try:
a = img_png(url_list_one)
b = img_downlad(a)
except:
print('Download error')
2. The name of the saved picture is obtained from the web page
In the last called img_png function to extract the title of the web page
Write the extracted name to img_ Go to the picture title in the downlad function. Here is all the code
import random # For adding random numbers
import urllib.request # Actions for linking
import re # For regular extraction of data
import os # For file processing
# Get the picture link address in the url
def img_png(url):
page = urllib.request.urlopen(url) # It is used to open a remote url and send a request to the link to get the results
html_a = page.read() # Get the source code of the page
html_b = html_a.decode('utf-8') # Source code formatting
png = re.findall(r'img src="(.*?)" /><br',html_b) # Regular extract the required picture link information
# The required data can be directly intercepted according to the left and right boundaries in regular expressions (. *?) Represents the content to be intercepted
# In this paper, img src = "and" / > < Br are extracted as boundaries, which is exactly what we need
print('This is the link address of the picture we got')
print(png)
return png
# The following is how to write a picture download
def img_downlad(list,name):
# Set the location where you want to save the file
path = 'D:\\test1'
# Judge whether the folder exists or not, and create it if it does not exist
if not os.path.isdir(path):
os.makedirs(path)
path = path +'\\' # The folder location where the picture was last saved
x = 0 # Add a variable to name the picture
jpg_name = '{0}{1}' + str(name) + '.jpg' # Set the name of the picture
# for loop to extract the link address of the picture and download it
for list_d in list:
print(list_d)
try: # Error judgment mechanism, the card owner will not make an error
print('----------The pictures are starting to download----------')
urllib.request.urlretrieve(list_d,jpg_name.format(path,x)) #Download the picture to the specified location
x = x + random.randint(5,999999) # Random numbers ensure that they are inconsistent every time
except:
print('Download failed')
url = 'https://moetu.club/category/illustration/page/2'
# Visit the link and get the source code of the list
page = urllib.request.urlopen(url).read().decode('utf-8')
# Read the url of the web page in the list
url_list = re.findall(r'href="(.*?)" rel="nofollow"',page)
# A for loop takes out the url and passes it to img_png executes to get the picture link and then calls img_downlad Download
for url_list_one in url_list:
try:
try: #Prevent missing name
# Get the title in the url and pass it into the picture download function
m = urllib.request.urlopen(url_list_one).read().decode('utf-8')
name = re.findall(r'<title>(.*?) &#',m)
except:
name = 'Whatever' + str(random.randint(1,100))
# Call function
a = img_png(url_list_one)
b = img_downlad(a,name)
except:
print('Download error')
3. Download in multiple ways
In addition to the download method described above, you can also use open to download
for list_d in list:
print(list_d)
x = random.randint(5,999999)
try: # Error judgment mechanism, the card owner will not make an error
print('----------The pictures are starting to download----------')
list_d = requests.get(list_d).content
jpg_name = path + str(name) + str(x) + '.jpg' # Set the name of the picture
with open(jpg_name, "wb") as code:
code.write(list_d)
# urllib.request.urlretrieve(list_d,jpg_name.format(path,x)) #Download the picture to the specified location
except:
print('Download failed')
Total code:
import random # For adding random numbers
import urllib.request # Actions for linking
import re # For regular extraction of data
import os # For file processing
# Get the picture link address in the url
import requests
def img_png(url):
page = urllib.request.urlopen(url) # It is used to open a remote url and send a request to the link to get the results
html_a = page.read() # Get the source code of the page
html_b = html_a.decode('utf-8') # Source code formatting
png = re.findall(r'img src="(.*?)" /><br',html_b) # Regular extract the required picture link information
# The required data can be directly intercepted according to the left and right boundaries in regular expressions (. *?) Represents the content to be intercepted
# In this paper, img src = "and" / > < Br are extracted as boundaries, which is exactly what we need
print('This is the link address of the picture we got')
print(png)
return png
# The following is how to write a picture download
def img_downlad(list,name):
# Set the location where you want to save the file
path = 'D:\\test1'
# Judge whether the folder exists or not, and create it if it does not exist
if not os.path.isdir(path):
os.makedirs(path)
path = path +'\\' # The folder location where the picture was last saved
x = 0
# for loop to extract the link address of the picture and download it
for list_d in list:
print(list_d)
x = random.randint(5,999999)
try: # Error judgment mechanism, the card owner will not make an error
print('----------The pictures are starting to download----------')
list_d = requests.get(list_d).content
jpg_name = path + str(name) + str(x) + '.jpg' # Set the name of the picture
with open(jpg_name, "wb") as code:
code.write(list_d)
# urllib.request.urlretrieve(list_d,jpg_name.format(path,x)) #Download the picture to the specified location
except:
print('Download failed')
url = 'https://moetu.club/category/illustration/page/2'
# Visit the link and get the source code of the list
page = urllib.request.urlopen(url).read().decode('utf-8')
# Read the url of the web page in the list
url_list = re.findall(r'href="(.*?)" rel="nofollow"',page)
# A for loop takes out the url and passes it to img_png executes to get the picture link and then calls img_downlad Download
for url_list_one in url_list:
try:
try: #Prevent missing name
# Get the title in the url and pass it into the picture download function
m = urllib.request.urlopen(url_list_one).read().decode('utf-8')
name = re.findall(r'<title>(.*?) &#',m)
except:
name = 'Whatever' + str(random.randint(1,100))
# Call function
a = img_png(url_list_one)
b = img_downlad(a,name)
except:
print('Download error')