1, Explain
Download Middleware is a hook framework for scripy's request / response processing. It is a lightweight low-level system used to globally change the request and response of scripy. It is often used to add agents, add cookie s, reissue requests after failure, and so on.
2, Activate Download Middleware
To activate Download Middleware, go to settings Py to activate DOWNLOADER_MIDDLEWARES setting, which is a dict. Its key is the middleware class path and its value is the middleware command.
Here is an example:
DOWNLOADER_MIDDLEWARES = {
'myproject.middlewares.CustomDownloaderMiddleware': 543,
}
When the previous code is running, we can see in the log that many downloadermiddleware are configured and started by default through DOWNLOADER_MIDDLEWARES_BASE configured.
3, Disable built-in Middleware
DOWNLOADER_MIDDLEWARES_ The middleware defined and enabled by base by default must be in the downloader of the project_ Middleviews is defined as None in the settings. For example, if you want to disable user agent middleware:
DOWNLOADER_MIDDLEWARES = {
'myproject.middlewares.CustomDownloaderMiddleware': 543,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
}
4, Write your own download Middleware
Each middleware component is a Python class that defines one or more of the following methods:
1,process_request(request, spider)
This method is called for each request through Download Middleware.
process_request() should: return None, a Response object, a request object, or throw an IgnoreRequest exception.
If it returns None, Scrapy will continue to process the request and execute all other middleware until the end. This has no impact on the whole framework.
If it returns a Response object, Scrapy will not call other processes_ Request () or process_exception() method. In each Response, the process of the installed Middleware_ The Response () method will be called.
If it returns a request object, Scrapy will stop calling process_request method and reschedule the returned request. So as to schedule the request to the complex site in a circular manner.
If it throws an IgnoreRequest exception, the process of the installed download Middleware_ The exception () method will be called. If neither of them handles exceptions, the errback function in request()(Request.errback) is called. If there is no code to handle the exception thrown, it is ignored and will not be logged.
Parameters:
Request (request object) - the request being processed
Spider (spider object) - the spider for which this request is directed
2,process_response (request,response,spider)
process_response() should: return a response object, a Request object, or throw an IgnoreRequest exception.
If it returns a Response, it will continue to process the next middleware_ Response(). That is, it has no impact on other middleware.
If it returns a request object, process will not be called_ Instead of response (), process_request() rejoins the scheduling queue.
If it throws an IgnoreRequest exception, the process of the installed download Middleware_ The exception () method will be called. If neither of them handles exceptions, the errback function in request()(Request.errback) is called. If there is no code to handle the exception thrown, it is ignored and will not be logged.
Parameters:
Request (request object) - the request that initiates the response
Response (response object) - the response being processed
Spider (spider object) - the spider for which this response is directed
3,process_exception(requset, exception, spider)
process_exception() should return: either None is the Response object or Request object.
If it returns None, Scrapy will continue to handle this exception and execute any other installed middleware process_exception() method until there is no middleware left and the default exception handling starts.
If it returns a response object, process_response() starts the method chain of the installed middleware, and scripy will not call any other process_exception() middleware method.
If it returns a Request object, it reschedules the returned Request for future downloads. This stops the execution of the process_ The method of exception () middleware is like returning a response. This is useful when repeated calls fail.
Parameters:
Request (is a request object) - generates an exception request
Exception (an exception object) - exception thrown
Spider (spider object) - the spider for which this request is directed
5, Case
1. Through process_request() set proxy
Create a new crawler program to access Google. Normally, Google can't access it
2. Through process_request() set proxy
In middlewars Py, where I have a 1080 port proxy locally.
import logging
class ProxyMiddleware(object):
logger = logging.getLogger(__name__)
def process_request(self, request, spider):
self.logger.debug('Using Proxy')
request.meta['proxy'] = 'http://127.0.0.1:1080'
return None #Can be omitted
3. Activate configuration
In settings Py modify settings:
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36',
'Accept-Language': 'en',
}
# Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'google.middlewares.ProxyMiddleware': 543,
}
4. Operation results
Run scratch crawl mygoogle from the command line
200 status code returned successfully
2. Overwrite Response
1. Through process_response() modifies the status code, and other configurations are the same as in example 1
import logging
class ProxyMiddleware(object):
logger = logging.getLogger(__name__)
def process_request(self, request, spider):
self.logger.debug('Using Proxy')
request.meta['proxy'] = 'http://127.0.0.1:1080'
return None
def process_response(self, request, response, spider):
response.status = 201
return response
2. Operation results
The status code can be seen to change
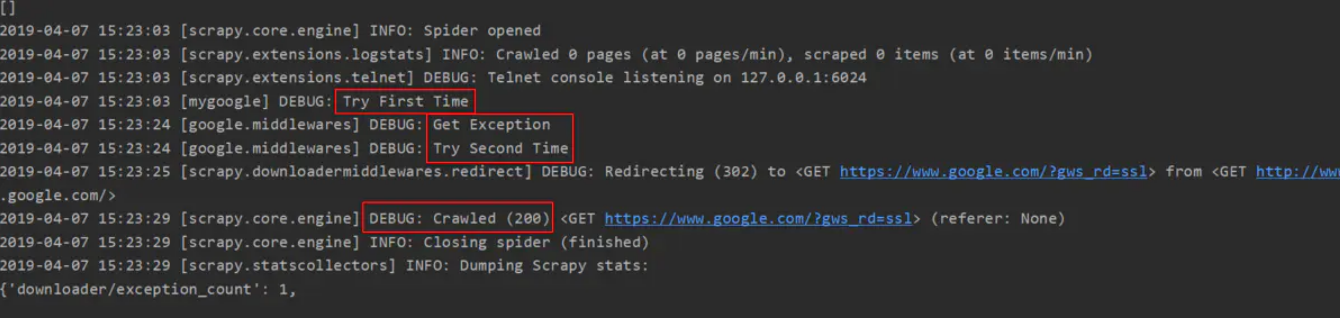
3. Crawl failed and try again
Other configurations are the same as the above example
1. Customize the request function and define the maximum waiting time of 10s
import scrapy
class MygoogleSpider(scrapy.Spider):
name = "mygoogle"
allowed_domains = ["www.google.com"]
start_urls = ['http://www.google.com/']
def make_requests_from_url(self, url):
self.logger.debug('Try First Time')
return scrapy.Request(url=url, meta={'downlord_timeout': 10}, callback=self.parse, dont_filter=True)
def parse(self, response):
pass
2. Close failed to reconnect, otherwise it will take a long time
In settings Modify in PY
# Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'google.middlewares.ProxyMiddleware': 543,
'scrapy.downloadermiddlewares.retry.RetryMiddleware': None,
}
3. Replace agent reconnection after adding failure
import logging
class ProxyMiddleware(object):
logger = logging.getLogger(__name__)
# def process_request(self, request, spider):
# self.logger.debug('Using Proxy')
# request.meta['proxy'] = 'http://127.0.0.1:1080'
# return None
#
# def process_response(self, request, response, spider):
# response.status = 201
# return response
def process_exception(self, request, exception, spider):
self.logger.debug('Get Exception')
self.logger.debug('Try Second Time')
request.meta['proxy'] = 'http://127.0.0.1:1080'
return request
4. Operation results