Python POST crawler crawls Nuggets user information
1. General
Python third-party library requests provides two functions for accessing http web pages, get() function based on GET mode and post() function based on POST mode.
The get function is the most commonly used crawling method. It can obtain static HTML pages and most dynamically loaded json files. However, some websites encrypt some data files and cannot use get to obtain the file content. At this time, the post function needs to be used to obtain them. For example, the user information of the Nuggets website to be crawled in this article.
The main difference between post and GET is that post will attach some parameters when sending the request, and the server will select the content returned to the customer according to the parameters. Therefore, when using the post function, one important thing is to construct parameters. Some websites will encrypt the parameters. At this time, it needs to be decrypted through observation and some common decryption methods. The common encryption methods include Base64, Hex and compression. The parameters of the Nuggets website cracked in this paper use base64 encryption.
To sum up, this paper constructs encryption parameters through post function, obtains 5000 pages of article information under the five main categories of nuggets, extracts the author's personal user information, removes duplicate information, and obtains 16598 pieces of personal user information.
2. Web page observation
Nuggets, https://juejin.cn/ , the domestic well-known geek platform and programmer community, Nuggets have a lot of technical giants. By obtaining Nuggets' user information, we can extract a lot of valuable information about the current situation of domestic programmers.

Observing the Nuggets home page, we will find that there is no direct user display page. Therefore, in order to obtain a large amount of user data, we plan to obtain user data by obtaining the author information of the article. There are several tag categories on the home page of nuggets. Each tag category will display several articles. We plan to obtain them mainly for the five tag categories of "back end", "front end", "Android", "iOS" and "artificial intelligence".

Enter the "back end" page, pull down to the end, and find that the article loading of the page is not in the form of static page turning, but in the form of dynamic loading of json files.
F12 check, enter the network, pull down and load a new article:
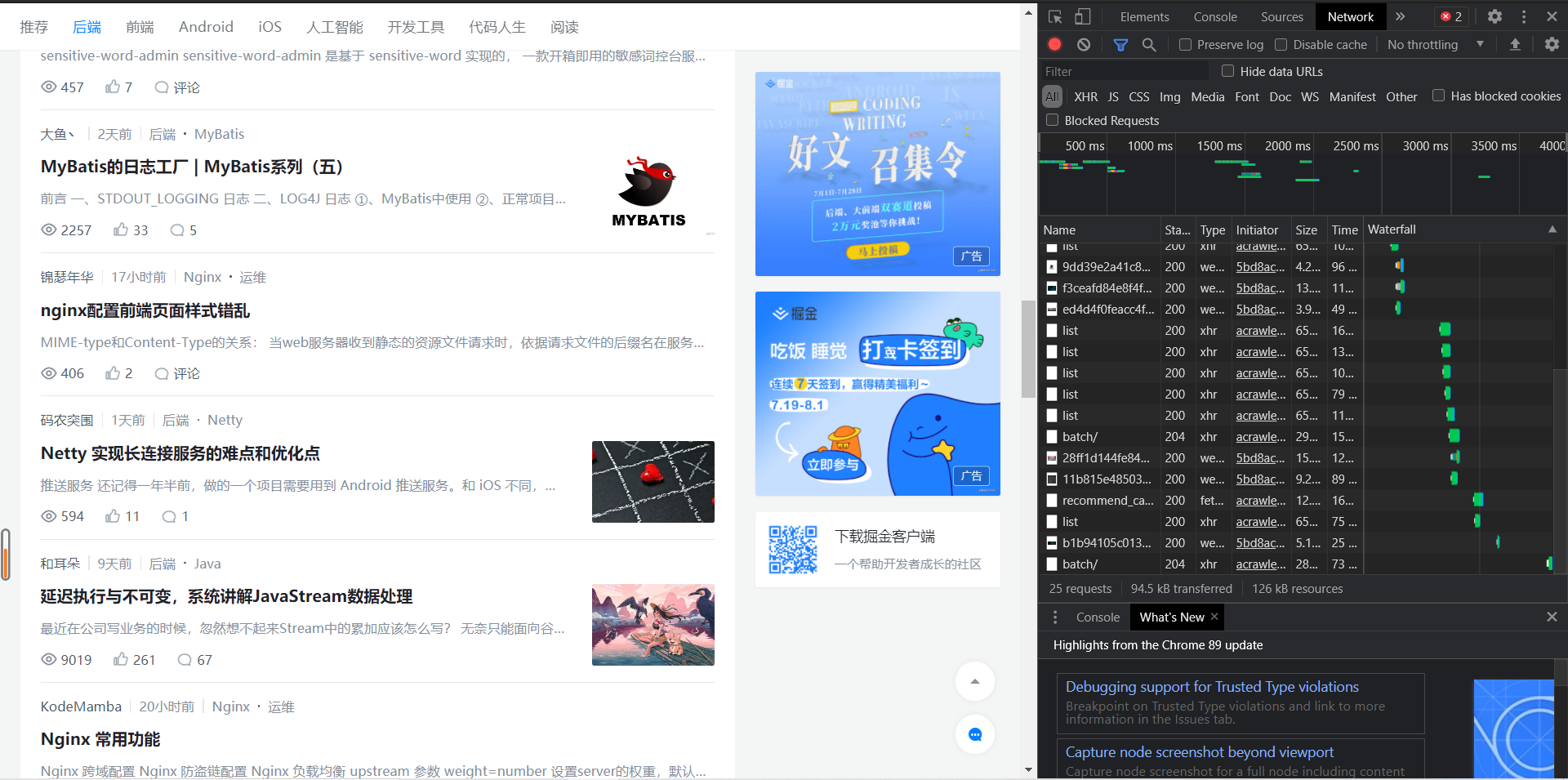
Observe the loaded new file and find a new file "recommend_cat_feed":

Click the file, select the Preview section, and find that it is a dictionary with several keys. Open the data key and find that it contains several article information. You can determine that this file is the file we need:
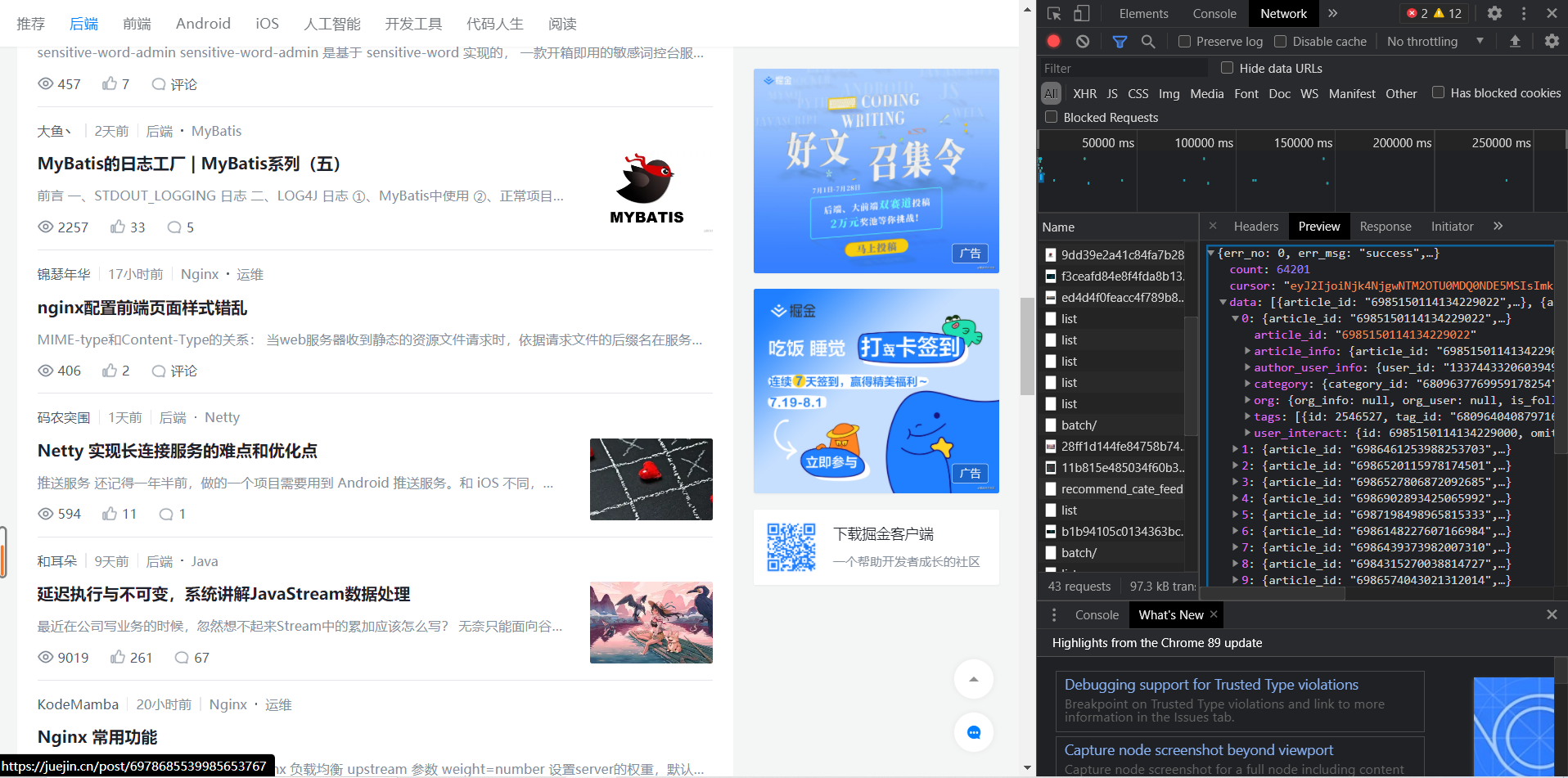
Directly open this linked website, and the page displays "404", which can not be accessed directly through GET, but need to be accessed through POST.
Then we continue to pull down the window and load a new file. Compared with the previous files, we find that the link URLs of the two are the same. The difference is that the cursor value in the parameters sent by POST is different:
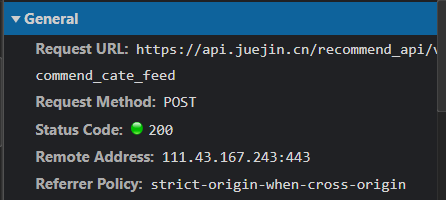
(overall information of the original document)
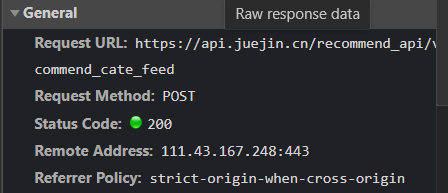
(new document overall information)

(original file parameters)

(new file parameters)
Therefore, we can infer that the parameters controlling page turning and category label are cursor. We can see that cursor is the encrypted value. If you want to use it to simulate page turning, you need to decrypt it.
3. Data extraction
From the above, we have obtained the URL Location of the required information. Next, we are going to try crawling with Python and decrypt its parameters.
First import the required libraries:
import requests #For data acquisition import pandas as pd #For data storage
Use the website found above as the target website;
url = r"https://api.juejin.cn/recommend_api/v1/article/recommend_cate_feed"
First copy all the parameters in the file viewed above as POST parameters (information in Request Payload):
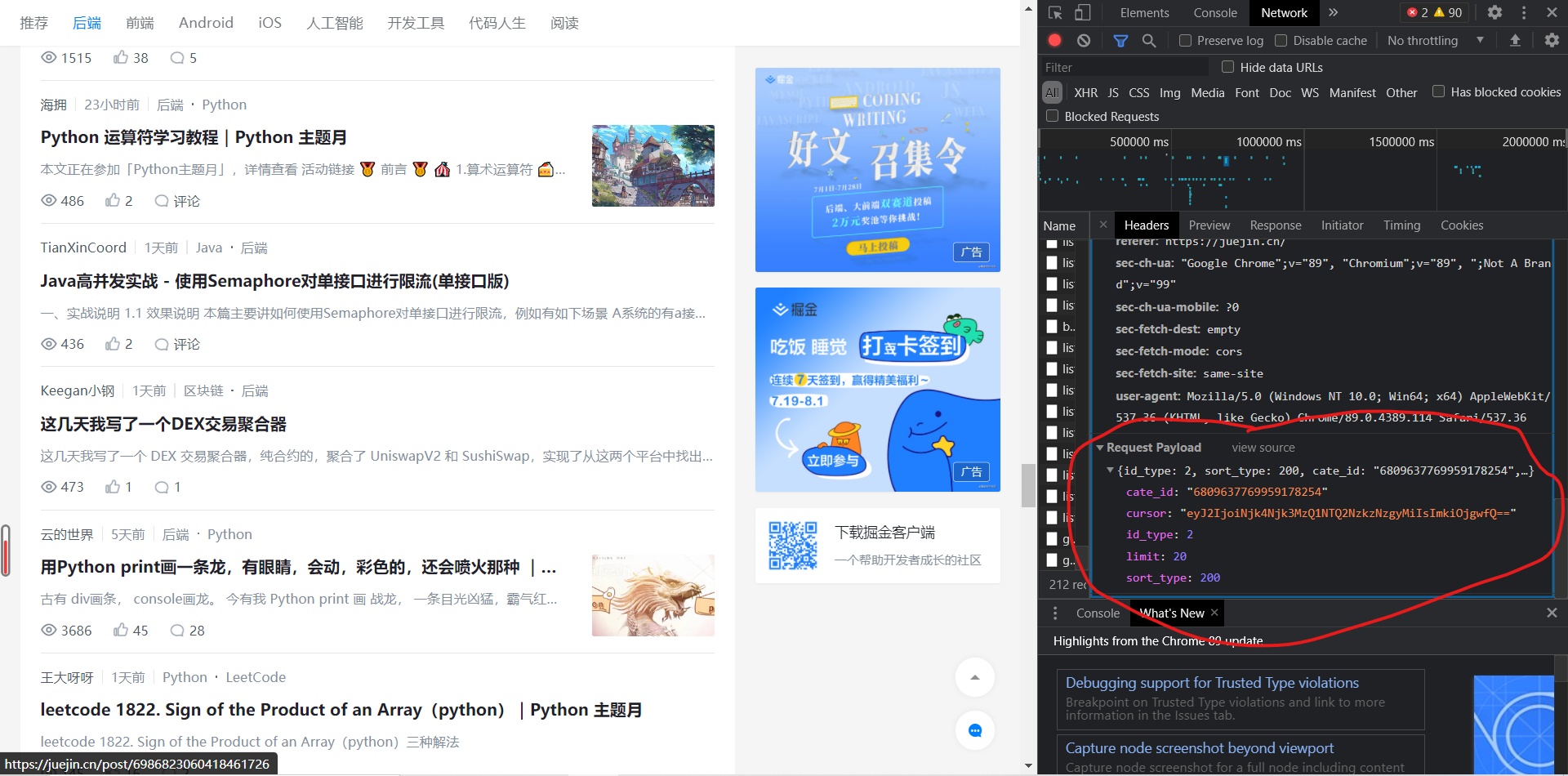
Copy to dictionary type:
p = {'id_type': 2, 'sort_type': 200, 'cate_id': '6809637769959178254', 'cursor': 'eyd2JzogJzY5ODY2NTI5MjU5NjM1MzQzNTAnLCAnaSc6IDYwfQ==', 'limit': 20}
Reconstruct the request header. Generally, the necessary request headers for POST requests include: user agent, accept encoding, accept language, content length and content type.
Copy the above items from Request Headers into a dictionary:

header = {"user-agent": "Mozilla/5.0",
"accept-encoding": "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7",
"content-length": "132",
"content-type": "application/json"
}
Note: sometimes the read code may be garbled. After the encoding conversion test, it is found that the request header supports br compression coding, and the returned code is compressed by BR. By default, the decompression of requests only supports gzip. Decompression is more troublesome. Directly remove the part in the request header that supports compression coding and only accept gzip compression.
Therefore, the request header is constructed as follows:
header = {"user-agent": "Mozilla/5.0",
"accept-encoding": "gzip",
"accept-language": "zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7",
"content-length": "132",
"content-type": "application/json"
}
Then use the post function to obtain its content, store its json format content, print it out and observe:
r = requests.post(url, data = json.dumps(p), headers = header) js_lst = r.json() print(js_lst)
Print as follows:

Observe the data and find that the data we need is stored in the data value as a list, and each article in the list is an element. Go deeper js_lst ["data"] observed that the author information is stored in the author_user_info value, which is used as a dictionary to store many user information of the author, and extract the data we care about:
for item in js_lst["data"]: #Traverse each article
info_dic = item["author_user_info"] #Dictionary of author information storage
if info_dic["user_id"] not in id_lst: #Check the id to determine whether the author information has been read
id_lst.append(info_dic["user_id"]) #id
user_info = {} #A dictionary that stores extracted author information
user_info["id"] = info_dic["user_id"] #id
user_info["name"] = info_dic["user_name"] #user name
user_info["company"] = info_dic["company"] #Company
user_info["job"] = info_dic["job_title"] #occupation
user_info["level"] = info_dic["level"] #User level
user_info["descrip"] = info_dic["description"] #Personal profile
user_info["fans"] = info_dic["followee_count"] #Number of fans
user_info["stars"] = info_dic["follower_count"] #Number of concerns
user_info["articles"] = info_dic["post_article_count"] #Number of original articles
user_info["get_like"] = info_dic["got_digg_count"]#Number of likes
user_info["views"] = info_dic["got_view_count"] #Views
info_lst.append(user_info) #Add the user's information to the user list
Here, the id of each user crawled is stored in a list. In each crawl, first judge whether the user id crawled at this time is in the list to avoid repeated crawling.
4. Parameter structure
Next, we construct parameters to realize multi page crawling.
According to the above analysis, there are five parameters attached to the POST request: id_type, sort_type, cate_id, cursor and limit.
According to the above analysis of different files, and then compare the parameters of different types of pages, we get the id_type,sort_type and limit are parameters that do not need to be changed. You can directly use the above parameters. And cat_ ID controls the classification of content (back end, front end, etc.), and cursor controls page turning.
Since our target category has only five main categories, we directly obtain the five categories of cat_ ID is enough. The troublesome parameter is cursor. It can be seen that it is an encrypted value. We need to decrypt it first.
According to the characteristics of cursor value, we speculate that it uses base64 encryption coding, and try to use Base64 to decode the cursor above:
import base64 #Import base64 Library print(base64.b64decode(b'eyJ2IjogIjY5ODY2NTI5MjU5NjM1MzQzNTAiLCAiaSI6IDIwfQ==')) #Print decoded content

It can be seen that base64 encoding is indeed used for encryption.
By comparing several different file parameters after decoding, we can draw a conclusion: v after decoding is the type value, and i is the number of pages. i starts from 20 and takes 40 as the unit.
For v, because it is the same as the type number cat above_ The IDs are different. We manually obtain the v parameters of five target categories and coexist them into a dictionary:
cate_dict = {
"back-end": ["6809637769959178254","6986652925963534350"],
"front end": ["6809637767543259144","6986785259966857247"],
"Android": ["6809635626879549454","6986154038312042504"],
"artificial intelligence": ["6809637773935378440","6986885294276476958"],
"IOS": ["6809635626661445640", "6986425314301870094"]}
Then we select the corresponding v and i for coding to see whether the comparison coding is correct.
for key in list(cate_dict.keys()): #Traverse each category
cate_id = cate_dict[key][0] #cate_id
cate_password = cate_dict[key][1] #v
for page in range(20, 40060, 40): #Control flipping
encode_dic = {} #The original form of cursor to be encoded is a dictionary
encode_dic["v"] = cate_password
encode_dic["i"] = page
#code
cursor = base64.b64encode(str(encode_dic).replace("'", "\"").encode()) #j convert the dictionary into a string, convert the single quotation marks into double quotation marks, encode them into byte types, and then encode them with base64
print(cate_id)
print(cursor.decode()) #Print the encoded results and display them in strings
The coding results are as follows:
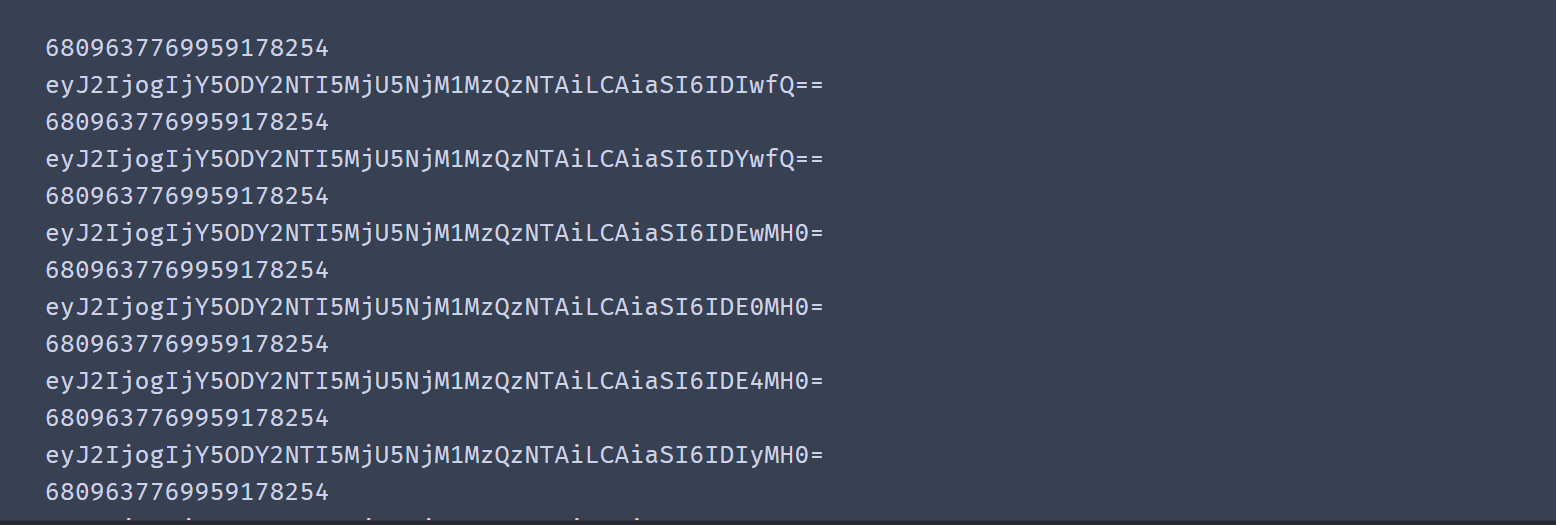
Notice a tip here. Because Python supports both single quotation marks and double quotation marks, and the default is single quotation marks, the items in the dictionary use single quotation marks after converting the dictionary to a string. However, the dictionary after parameter decoding is double quotation marks, so you need to use the replace function to convert the single quotation marks in the string into double quotation marks, otherwise the encoded result is incorrect
Thus, we have constructed the required parameters.
5. Result storage
After constructing parameters and extracting data, we can crawl in large quantities. Because it is a dynamic API interface for crawling, it is generally not detected because the crawling speed is too fast, and sleep is not required. In order to ensure the quality, sleep can also be carried out appropriately.
Finally, a problem involved is the storage of the crawled data. Because the amount of crawled data is large and the crawl takes a long time, it is best to write it to the csv file many times, so as to ensure that even if there are network errors in the crawl process, it will not need to start all over again.
To store data, this paper uses the pandas library for storage, converts the crawled list into the DataFrame type of pandas, and then uses to_csv function can be written.
data = pd.DataFrame(info_lst) #Data type conversion data.to_csv(r"juejin.csv")
In order to realize batch writing, we maintain a num variable in the crawling process, add 1 for each page of num, and set info when num is equal to 25_ The contents of LST are written to the file and info_lst is emptied to avoid causing too much memory consumption. In this way, additional writing is required. Otherwise, each write will clear the original content. For additional writing, only set mode to a.
if num == 25: #Page 25 crawled
data = pd.DataFrame(info_lst) #Data type conversion
data.to_csv(r"juejin.csv", mode = "a") #Append write
info_lst = [] #Empty staging list
num = 0
print("Write successful")
Crawling results:
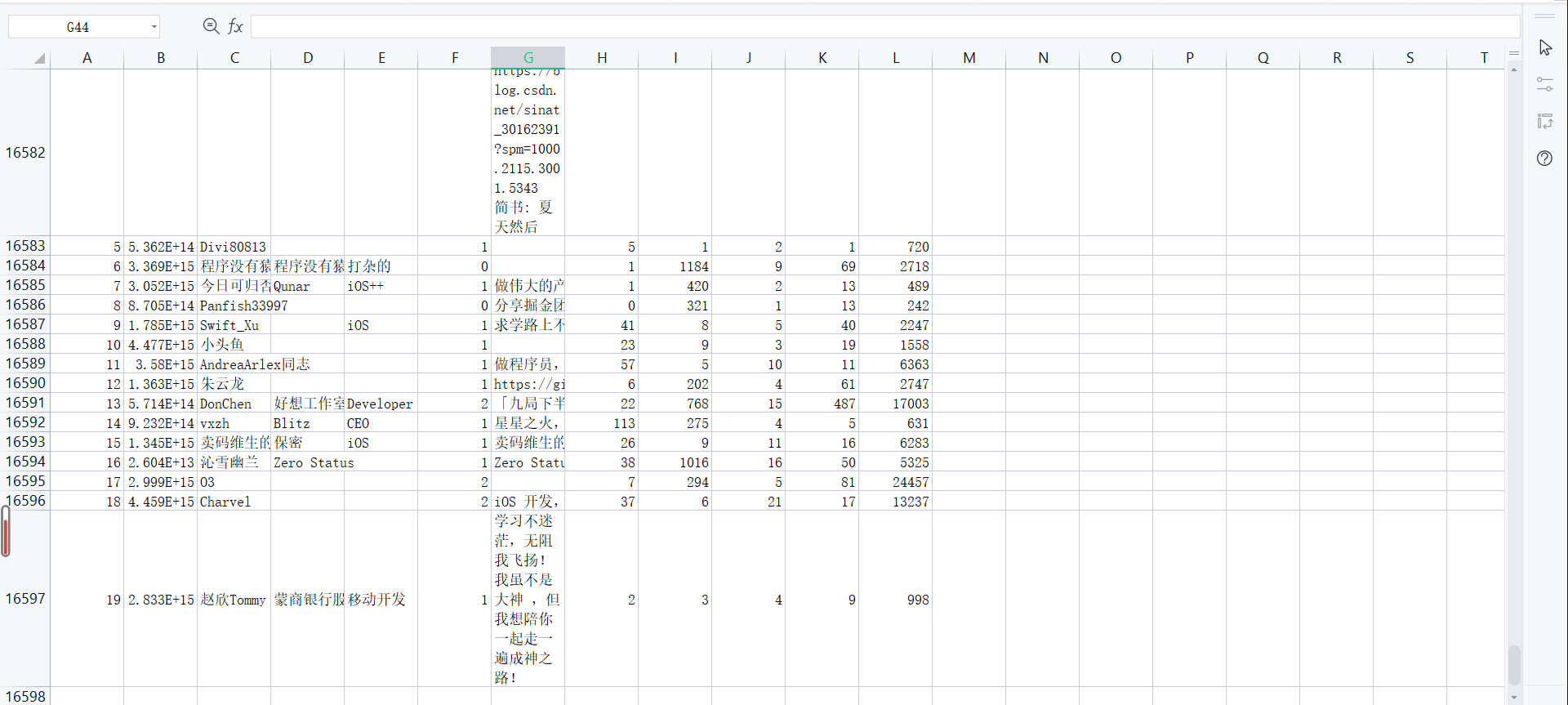
A total of 16598 user data without duplication.
6. Source code:
import requests
import base64
import pandas as pd
num = 0
url = r"https://api.juejin.cn/recommend_api/v1/article/recommend_cate_feed"
p ={"id_type":2,"sort_type":200,"cate_id":"6809637769959178254",
"cursor":"eyJ2IjoiNjk4NjY1MjkyNTk2MzUzNDM1MCIsImkiOjQwMDIwfQ==","limit":20}
header = {"user-agent": "Mozilla/5.0",
"cookie":"MONITOR_WEB_ID=6df3866a-2cab-4818-bb57-e75e971da3f8; _ga=GA1.2.1480397537.1626829211; _gid=GA1.2.1556542559.1626829211",
"accept-encoding": "gzip",
"accept-language": "zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7",
"content-length": "132",
"content-type": "application/json"
}
id_lst = [] #List of IDS used for de duplication
info_lst = [] #Temporary result list
for key in list(cate_dict.keys()): #Traverse each category
cate_id = cate_dict[key][0] #Category number
cate_password = cate_dict[key][1] #v
for page in range(20, 40060, 40): #Turn pages
time.sleep(random.random()) #Random time of sleep 0-1
encode_dic = {} #cursor parameter dictionary
encode_dic["v"] = cate_password
encode_dic["i"] = page
#code
cursor = base64.b64encode(str(encode_dic).replace("'", "\"").encode())
#print(cursor)
p["cate_id"] = cate_id
p["cursor"] = cursor.decode()
#print(p)
r = requests.post(url, data = json.dumps(p), headers = header)
#print(r.apparent_encoding)
r.encoding = "utf-8"
#print(r.text)
js_lst = r.json()
for item in js_lst["data"]: #Traverse each article
info_dic = item["author_user_info"] #Dictionary of author information storage
if info_dic["user_id"] not in id_lst: #Check the id to determine whether the author information has been read
id_lst.append(info_dic["user_id"]) #id
user_info = {} #A dictionary that stores extracted author information
user_info["id"] = info_dic["user_id"] #id
user_info["name"] = info_dic["user_name"] #user name
user_info["company"] = info_dic["company"] #Company
user_info["job"] = info_dic["job_title"] #occupation
user_info["level"] = info_dic["level"] #User level
user_info["descrip"] = info_dic["description"] #Personal profile
user_info["fans"] = info_dic["followee_count"] #Number of fans
user_info["stars"] = info_dic["follower_count"] #Number of concerns
user_info["articles"] = info_dic["post_article_count"] #Number of original articles
user_info["get_like"] = info_dic["got_digg_count"]#Number of likes
user_info["views"] = info_dic["got_view_count"] #Views
info_lst.append(user_info) #Add the user's information to the user list
print("Complete section{}/{}page".format(int((page-20)/40), 1000))
num+=1 #Climb page number plus 1
if num == 25: #Store every 25 pages
data = pd.DataFrame(info_lst) #Data type conversion
data.to_csv(r"juejin.csv", mode = "a") #Append write
info_lst = []
num = 0
print("Write successful")
print("key:{}complete".format(key))
print()
print()