1. Computer core foundation
1.1 what is language? What is programming language? Why programming languages?
Language is actually the medium of communication between people, such as English, Chinese, Russian, etc. Programming language is the medium of communication between people and computers, The purpose of programming is to let the computer work spontaneously according to the logic of human thinking (program), so as to liberate human resources
II. Principle of computer composition
2.1 what is a computer?
Commonly known as the computer, that is, the brain with electricity. The word "computer" contains the ultimate expectation of human beings for the computer, hoping that it can really work like the human brain, so as to liberate human resources.
2.2 why use computer?
The world is ruled by intelligent lazy people. At any time, there are always a group of intelligent lazy people who want to enslave others. In the slavery society, the intelligent lazy people enslave the real people, and people can't work all the time without eating, drinking and sleeping, but the computer can be done as a machine, so it's the best choice to treat the computer as a slave
2.3 five components of computer
1. Controller Controller is the command system of computer, which is used to control the operation of other components of computer, equivalent to human brain 2. Arithmetic unit An arithmetic unit is the operation function of a computer. It is used for arithmetic operation and logic operation. It is equivalent to a human brain ps: controller + calculator = cpu, cpu is equivalent to human brain 3. Memory Memory is the memory function of a computer to access data. Memory is mainly divided into memory and external memory: Memory is equivalent to short-term memory. Loss of power-off data External storage (such as disk), which is equivalent to a notebook, is used to store data permanently without loss of power-off data ps: memory access speed is much faster than external memory 4. input device Input device is a tool for calculating and receiving external input data, such as keyboard and mouse, which is equivalent to human eyes or ears. 5. output device Output device is a tool for computer to output data, such as display and printer, which is equivalent to what people say and write. ps: memory such as memory and disk are both input devices and output devices, collectively referred to as IO devices
The three core hardware are CPU, memory and hard disk.
The program is stored in the hard disk first. The program runs by loading the code from the hard disk into the memory, and then the cpu reads the instructions from the memory.
III. overview of operating system
3.1 origin of operating system
The function of the operating system is to help us encapsulate the complex hardware control into a simple interface. For the development of applications, we only need to call the interface provided by the operating system
3.2 system software and application software
The above hardware runs software, and the software is divided into two categories:
1, Application software (such as qq, word, storm video, we learn python to develop application software) 2, The operating system, a bridge between the application software and hardware of the operating system, is a control program to coordinate, manage and control the computer hardware and application software resources.
3.3 three layer structure of computer system
application program operating system computer hardware
Hardware + operating system = = platform
2. Programming language and Python introduction
Programming language classification:
machine language
Machine language is a language that a computer can understand from the point of view of a computer (slave). What a computer can understand directly is binary instructions. Therefore, machine language is directly binary programming, which means that machine language operates hardware directly. Because this machine language is a low-level language, the low-level here refers to the low-level and close to computer hardware
#Machine language
The instructions described by binary code 0 and 1 are called machine instructions. Because the internal of the computer is based on binary instructions, the machine language directly controls the computer hardware.
To write a program in machine language, the programmer should first memorize all the instruction codes and the meaning of the codes of the computer used, and then when writing the program, the programmer has to deal with the storage, distribution, input and output of each instruction and each data by himself, and also remember the state of the working unit used in each step of the programming process. This is a very tedious work. Writing a program often takes tens or hundreds of times as long as it actually runs. Moreover, the programs are all instruction codes of 0 and 1, which are not intuitive, not easy to read and write, but also easy to make mistakes, and depend on specific computer hardware models, with great limitations. Apart from the professionals of computer manufacturers, the vast majority of programmers are no longer learning machine languages.
Machine language is understood and used by microprocessors. There are up to 100000 machine language instructions. Here are some simple examples
#Example of instruction part
0000 for LOAD
0001 for storage
...
#Example of register part
0000 for register A
0001 for register B
...
#Example of memory part
000000000000 represents memory with address 0
000000000001 for memory with address 1
000000010000 represents memory with address 16
100000000000 for storage with address 2 ^ 11
#Integration example
00000000000000010000 for LOAD A, 16
00000001000000000001 for LOAD B, 1
00010001000000010000 for STORE B, 16
00010001000000000001 for STORE B, 1[1]
Summing up machine language
#1. Highest efficiency The program can be understood by the computer without any obstacles, run directly, and perform efficiently. #2. Lowest development efficiency Complex, inefficient development #3. Poor cross platform performance Close to / dependent on specific hardware, poor cross platform performance
assembly language
Assembly language only uses an English label to represent a group of binary instructions. There is no doubt that assembly language is a progress compared with machine language, but the essence of assembly language is still direct operation of hardware, so assembly language is still relatively low-level / low-level language, close to computer hardware
#Assembly language
The essence of assembly language is the same as that of machine language, which is directly operated on the hardware. Only the instruction adopts the identifier of English abbreviation, which is easier to identify and remember. It also requires the programmer to write out the specific operation of each step in the form of command. Every instruction of the assembler can only correspond to a very subtle action in the actual operation. For example, mobile and self increasing, assembly source programs are usually lengthy, complex and error prone, and using assembly language programming requires more computer expertise, but the advantages of assembly language are also obvious. The operation that can be completed by assembly language is not the same as that of high-level language, and the executable files generated by assembly are not only more than It's small and fast.
For the assembled hello world, to print a sentence of hello world, you need to write more than ten lines, as follows
; hello.asm
Section. Data; segment declaration
MSG DB "Hello, world!, 0xa; string to output
Len equ $- MSG; string length
Section. Text; snippet declaration
global _start; specify the entry function
A kind of start:; display a string on the screen
mov edx, len; parameter 3: string length
mov ecx, msg; parameter 2: string to display
mov ebx, 1; parameter 1: file descriptor (stdout)
mov eax, 4; system call number (sys_write)
int 0x80; call kernel function
; exit program
mov ebx, 0; parameter 1: exit code
mov eax, 1; system call number (sys_exit)
int 0x80; call kernel function
Summary assembly language
#1. High efficiency Compared with machine language, it is relatively simple and efficient to write programs with English tags, #2. Low development efficiency: It is still a direct operation of hardware. Compared with machine language, the complexity is slightly lower, but it is still high, so the development efficiency is still low #3. Poor cross platform performance It also depends on specific hardware and has poor cross platform performance
high-level language
From the perspective of human (slave owner), high-level language is to speak human language, that is, to write programs with human characters, while human characters are sending instructions to the operating system, rather than directly operating the hardware. Therefore, high-level language deals with the operating system. The high-level language here refers to the high-level, developers do not need to consider the hardware details, so the development efficiency can be greatly improved, But because high-level language is far away from hardware and closer to human language, which can be understood by human beings, and computers need to be understood through translation, so the execution efficiency will be lower than low-level language.
According to the different ways of translation, there are two kinds of high-level languages
Compiled (such as C language):
Similar to Google translation, it compiles all code of the program into binary instructions that can be recognized by the computer, and then the operating system will directly operate the hardware with the compiled binary instructions, as follows
#1. High efficiency Compilation refers to "translating" the program source code into the target code (i.e. machine language) before the application source program is executed, Therefore, the target program can be executed independently from its language environment, which is more convenient and efficient. #2. Low development efficiency: Once the application needs to be modified, it must first modify the source code, then recompile and generate a new target file to execute, However, if there is only target file but no source code, it will be inconvenient to modify. So the efficiency of development is lower than that of explanation #3. Poor cross platform performance Compiled code is translated for a certain platform. The results of current platform translation cannot be used by different platforms. It must be recompiled for different platforms, i.e. poor cross platform performance #Others Now most programming languages are compiled. The compiler translates the source program into the target program and saves it in another file. The target program can run directly on the computer several times without the compiler. Most software products are distributed to users in the form of target program, which is not only convenient for direct operation, but also makes it difficult for others to steal the technology. C. C + +, Ada and Pascal are all compiled and implemented
Interpretive (such as python):
Similar to simultaneous translation, an interpreter is needed. The interpreter will read the program code and execute it while translating. The details are as follows
#1. Low efficiency In the implementation of interpretive language, the translator does not generate the target machine code, but the intermediate code which is easy to execute. This kind of intermediate code is different from the machine code. The interpretation of the intermediate code is supported by software and cannot use hardware directly, Software interpreters often lead to low execution efficiency. #2. High development efficiency A program written in an interpreted language is executed by another interpreter that understands the intermediate code, unlike a compiler, The task of the interpreter is to interpret the statements of the source program into executable machine instructions one by one, without translating the source program into the target code for execution. The advantage of interpreter is that when there is a syntax error in the statement, it can immediately attract the attention of the programmer, and the programmer can correct it during the development of the program. #3. Strong cross platform Code operation depends on the interpreter. Different platforms have corresponding versions of the interpreter, so the interpreter is cross platform #Others For an interpreted Basic language, a special interpreter is needed to interpret and execute Basic programs. Each statement is translated only when it is executed, This interpretative language translates every time it is executed, so it is inefficient. Generally speaking, dynamic languages are explanatory, For example: Tcl, Perl, Ruby, VBScript, JavaScript, etc
ps: mixed language
Java is a special programming language. Java programs also need to be compiled, but they are not directly compiled into machine language, but rather into bytecode, The bytecode is then interpreted on the Java virtual machine.
summary
To sum up, choose different programming languages to develop application program comparison
#1. Execution efficiency: machine language > assembly language > high level language (compiled > interpreted) #2. Development efficiency: machine language < assembly language < high level language (compiled < interpreted) #3. Cross platform: interpretive type has a strong cross platform type
Three python introduction
When it comes to python, there are two meanings involved. One represents the syntax style of the language python, and the other represents the application program specially used to explain the syntax style Python interpreter.
Python advocates beauty, clarity and simplicity. It is an excellent and widely used language
The history of Python interpreter
Since its birth, Python has had: classes, functions, exception handling, core data types including tables and dictionaries, and module based extension systems.
What are the Python interpreters?
The essence of the official Python interpreter is a software developed based on C language. The function of the software is to read the content of the file ending with. py, and then translate and execute the corresponding code according to the syntax and rules defined by Guido.
# Jython JPython The interpreter uses JAVA Prepared by python The interpreter can directly Python Code compiled into Java Bytecode and execute, it not only makes the java Embedded on top of python Scripts are possible, and you can also java Program introduced to python In the process. # IPython IPython Is based on CPython An interactive interpreter on top, that is, IPython It's just an enhancement in the way of interaction, but the execution Python Code functions and CPython It's exactly the same. It's like many homegrown browsers have different appearance, but the kernel is actually called IE. CPython use>>>As a prompt, and IPython use In [No]:As a prompt. # PyPy PyPy yes Python Developers for better Hack Python But with Python Realized by language Python Interpreter. PyPy Provided JIT Compiler and sandbox capabilities, for Python The code is compiled dynamically (note that it is not interpreted), so it runs faster than CPython Faster. # IronPython IronPython and Jython Similar, but IronPython It's running at Microsoft.Net On platform Python The interpreter can directly Python Code compiled into.Net Bytecode of.
Four install Cpython interpreter
Python interpreter currently supports all mainstream operating systems. Python interpreter is provided on Linux, UNIX and MAC systems. It needs to be installed on Windows systems. The specific steps are as follows.
4.1 download python interpreter
https://www.python.org
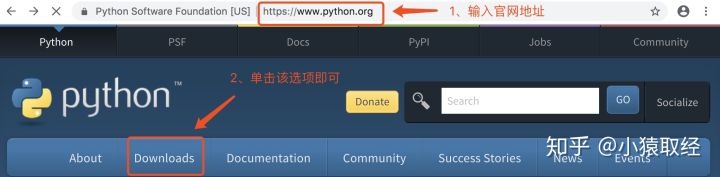
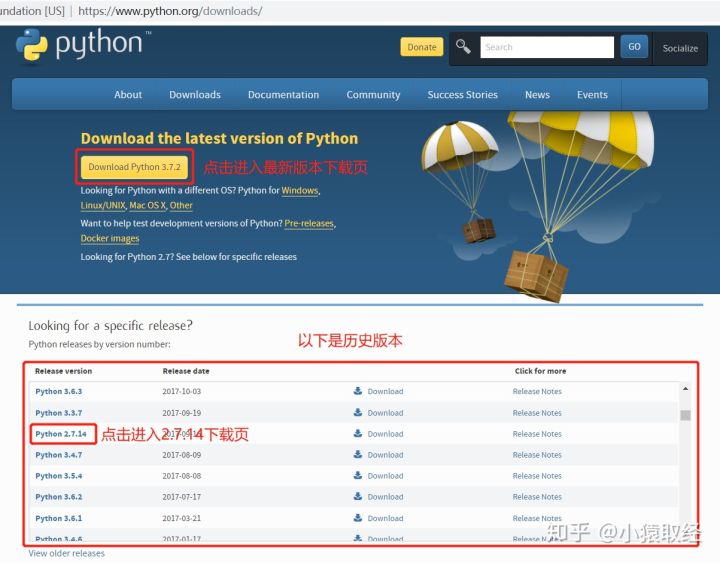

4.2. Install python interpreter
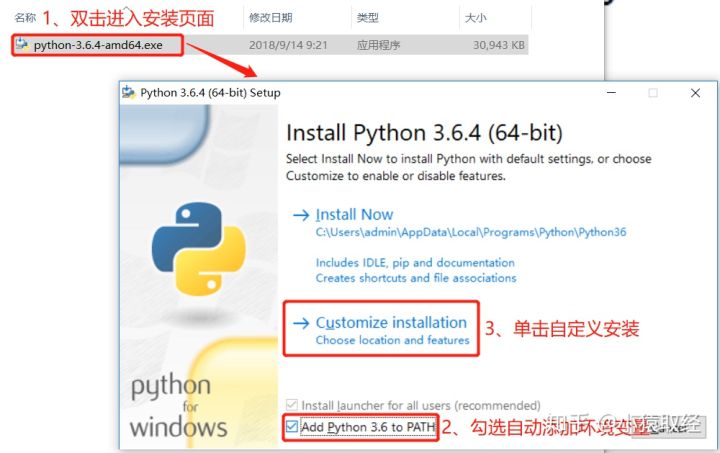
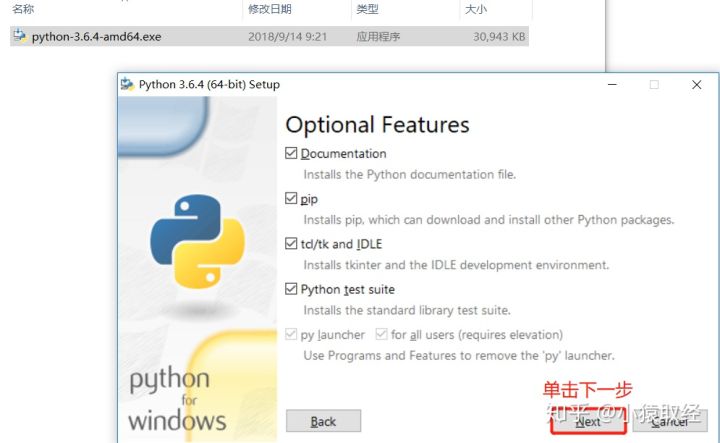
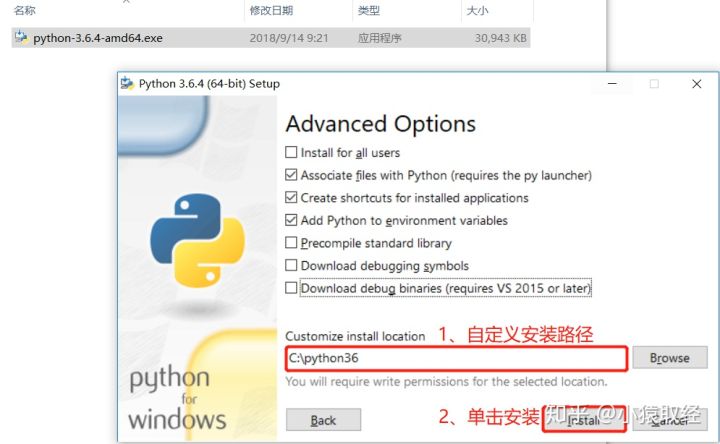
4.3 test whether the installation is successful
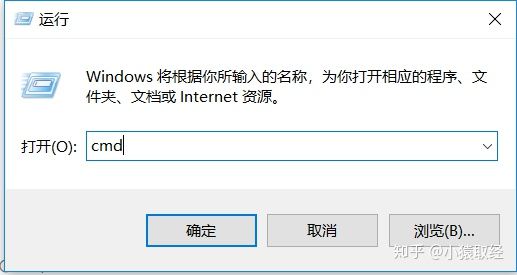
Windows > Run > Enter cmd, press enter, and the cmd program pops up. Enter python. If you can enter the interactive environment, the installation is successful.

The first python program
5.1 there are two ways to run python programs
Mode 1: interactive mode

Mode 2: script file
# 1. Open a text editing tool, write the following code, and save the file, where the path of the file is D:\test.py . Emphasis: the execution program of python interpreter is interpretation execution. The essence of interpretation is to open the file for reading. Therefore, the suffix of the file has no hard limit, but it is usually defined as the end of. Py
print('hello world')
# 2. Open cmd and run the command, as shown below

Summary:
#1. In interactive mode, code execution results can be obtained immediately, and debugging programs are very convenient #2. If you want to permanently save your code, you must write it to a file #3. In the future, we mainly need to open the interactive mode to debug some code and verify the results in the code writing file
5.2 notes
Before we formally learn python syntax, we must introduce a very important syntax in advance: Annotation
1. What is annotation
Annotation is the explanation of the code. The content of annotation will not be run as code
2. Why comment
Enhance code readability
3. How to use notes?
Code comment single line and multi line comments 1. Single line comments are marked with a ා, which can be directly above or directly behind the code 2. Multiline comments can use three pairs of double quotes "" "" ""
4. Principles of code annotation:
1. You don't need to annotate all of them. You just need to annotate the parts that you think are important or difficult to understand 2. Note can be in Chinese or English, but not in pinyin
Six IDE tool pycharm s
When writing the first python program, there are the following problems, which seriously affect the development efficiency
Problem 1: we learned that a python program needs to operate at least two software from development to operation
1. Open a software: text editor, create text to write program 2. Open cmd and enter the command to execute the pyton program
Problem 2: in the development process, there is no code prompt and error correction function
To sum up, if a tool can integrate the functions of n software, code prompt and error correction, it will greatly improve the development efficiency of programmers, which is the origin of IDE. The full name of IDE is Integrated Development Environment, that is, Integrated Development Environment. The best IDE for developing Python programs is PyCharm.
6.2. pychram installation
#Download address: https://www.jetbrains.com/pycharm/download Choose Professional
6.3 create folder by Pycharm
6.4 how to create documents and write programs for execution
Create py file test.py
stay test.py Write the code in. You can use the tab key to complete the beginning of the keyword, and there will be an error prompt for the code
3. Variables for getting started with Python syntax
I. Introduction
We learn python language to control computers and make computers work like human beings. So in python, the meaning of all the grammars is to make computers have a certain skill of human beings. This sentence is the basis of our understanding of all subsequent python grammars.
Bivariate
1, What are variables?
#Variable is the variable that can be changed. Quantity refers to the state of things, such as people's age, gender, the level of game characters, money, etc
2, Why do we have variables?
#In order to make the computer remember a certain state of things like human beings, and the state can change #In detail: #The essence of program execution is a series of state changes. Change is the direct embodiment of program execution, so we need a mechanism to reflect or save the state of program execution and the state changes.
3, How to use variables (define first, then use)
3.1 definition and use of variables
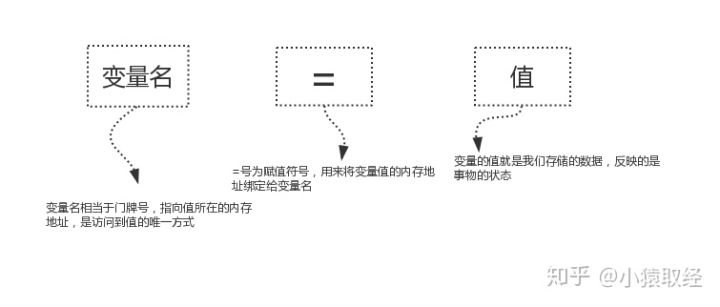
An example of defining variables is as follows
name = 'harry' # Write down the person's name as' harry ' sex = 'male' # Write down the gender of a man as male age = 18 # Write down the age of 18 salary = 30000.1 # The salary of the person recorded is 30000.1 yuan
When the interpreter executes the code defined by the variable, it will apply for memory space to store the variable value, and then bind the memory address of the variable value to the variable name. Take age=18 as an example, as shown in the following figure
Illustration: defining variable request memory
The corresponding value can be referenced by the variable name
# The value can be referenced by the variable name, and we can print it with the function of print() print(age) # Find the value 18 through the variable name age, then execute print(18), output: 18
#Naming conventions 1. Variable name can only be any combination of letters, numbers or underscores 2. The first character of a variable name cannot be a number 3. Keywords cannot be declared as variable names. Common keywords are as follows ['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from','global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield'] Age = 18. It is strongly recommended not to use Chinese names
3.3 naming style of variable name
# Style 1: hump AgeOfTony = 56 NumberOfStudents = 80 # Style 2: pure lowercase underline (in python, this style is recommended for variable name naming) age_of_tony = 56 number_of_students = 80
3.4 three characteristics of variable value
#1,id It reflects the unique number of variables in memory. Different memory addresses and IDS must be different #2,type Type of variable value #3,value Variable value
3, Constant
3.1 what is constant?
Constants are quantities that do not change during program operation
3.2 why constant?
In the process of program running, some values are fixed and should not be changed, such as PI 3.141592653
3.3 how to use constants?
There is no special syntax to define constants in Python. It is a convention to use all uppercase variable names to represent constants. For example, PI=3.14159. So in terms of syntax, the use of constants is exactly the same as that of variables.
4. Basic data types for getting started with Python syntax
I. Introduction
Variable values also have different types
salary = 3.1 # Record salary with floating point age = 18 # Using integer to record age name = 'lili' # Using string type to record person name
Binary type
2.1 int integer
2.1.1 function
It is used to record the integer related status of person's age, year of birth, number of students, etc
2.1.2 definitions
age=18 birthday=1990 student_count=48
2.2 float
2.2.1 function
It is used to record the decimal related status of people's height, weight, salary, etc
2.2.2 definition
height=172.3 weight=103.5 salary=15000.89
2.3 use of number type
1. Mathematical operation
>>> a = 1 >>> b = 3 >>> c = a + b >>> c 4
2. Compare sizes
>>> x = 10 >>> y = 11 >>> x > y False
Three string type str
3.1 function
The state of describing a person's name, home address, gender, etc
3.2 definitions
name = 'harry' address = 'Pudong New Area, Shanghai' sex = 'male'
With single quotation mark, double quotation mark and multiple quotation marks, you can define a string, which is essentially indistinguishable, but
#1. The pairing problem of nesting quotation marks should be considered
MSG = "my name is Tony, I'm 18 years old!" (inner layer has single quotation mark, outer layer needs double quotation mark.)
#2. Multiple quotes can write multiple lines of strings
msg = '''
There are only two kinds of people in the world. For example, when a bunch of grapes arrives, one chooses the best to eat first, and the other leaves the best to eat last.
As usual, the first kind of people should be optimistic, because every one he eats is the best of the leftover grapes; the second kind of people should be pessimistic, because every one he eats is the worst of the leftover grapes.
But the fact is just the opposite, because the second kind of people still have hope, the first kind of people only have memories.
'''
3.3 use
Numbers can be added, subtracted, multiplied, and divided. What about strings? Yes, but you can only add and multiply. >>> name = 'tony' >>> age = '18' >>>The addition of name + age is actually a simple string splicing 'tony18' >>>The multiplication of name * 5 is equivalent to adding strings five times 'tonytonytonytonytony'
Four list
4.1 function
If we need to use a variable to record the names of multiple students, it is impossible to use the number type. The string type can be recorded, for example
stu_names = 'Zhang Sanli, Si Wangwu', but the purpose of saving is to get the name of the second student. At this time, if you want to get the name of the second student, it's quite troublesome. The list type is specially used to record the values of multiple attributes of the same kind (such as the names of multiple students in the same class, multiple hobbies of the same person, etc.), and the access is very convenient
4.2 definitions
>>> stu_names=['Zhang San','Li Si','Wang Wu']
4.3 use
# 1. The list type uses an index to correspond to the value, and the index represents the position of the data, counting from 0 >>> stu_names=['Zhang San','Li Si','Wang Wu'] >>> stu_names[0] 'Zhang San' >>> stu_names[1] 'Li Si' >>> stu_names[2] 'Wang Wu' # 2. The list can be nested with the following values >>> students_info=[['tony',18,['jack',]],['jason',18,['play','sleep']]] >>> students_info[0][2][0] #Take out the first student 's first hobby 'play'
Five dict ionary
5.1 function
If we need to record multiple values with one variable, but multiple values are of different attributes, such as person's name, age and height, we can save them with the list, but the list is corresponding to the value with the index, and the index can't clearly express the meaning of the value, so we use the dictionary type, which stores the data in the form of key: value, in which the key can have a descriptive function for value
5.2 definitions
>>> person_info={'name':'tony','age':18,'height':185.3}
5.3 use
# 1. The dictionary type uses the key to correspond to the value. The key can describe the value, usually the string type
>>> person_info={'name':'tony','age':18,'height':185.3}
>>> person_info['name']
'tony'
>>> person_info['age']
18
>>> person_info['height']
185.3
# 2. Dictionaries can be nested with the following values
>>> students=[
... {'name':'tony','age':38,'hobbies':['play','sleep']},
... {'name':'jack','age':18,'hobbies':['read','sleep']},
... {'name':'rose','age':58,'hobbies':['music','read','sleep']},
... ]
>>> students[1]['hobbies'][1] #Take the second hobby of the second student
'sleep'
Six bool
6.1 function
It is used to record the true and false states
6.2 definitions
>>> is_ok = True >>> is_ok = False
6.3 use
It is usually used as a condition of judgment. We will use it in if judgment
5. Garbage collection mechanism for Python grammar beginners
I. Introduction
When the interpreter executes the syntax of defining variables, it will apply for memory space to store the values of variables, and the memory capacity is limited, which involves the problem of reclaiming the memory space occupied by variable values. When a variable value is not used (garbage for short), it should reclaim the memory occupied by it. What kind of variable value is not used? From the logic level alone, we define variables to store variable values for later use. To obtain variable values, we need to use the bound direct reference (e.g. x=10, 10 is directly referenced by x) or indirect reference (e.g. l=[x, ], x=10, 10 is directly referenced by X and indirectly referenced by container type l), so when a variable value is no longer bound to any reference, we can no longer access the variable value. Naturally, the variable value is useless and should be treated as a garbage collection. There is no doubt that the application and recovery of memory space are very energy consuming, and there is a great danger. A little carelessness may cause memory overflow. Fortunately, Cpython interpreter provides an automatic garbage collection mechanism to help us solve this problem.
2, What is garbage collection mechanism?
Garbage collection mechanism (GC for short) is a machine provided by Python interpreter, which is specially used to reclaim the memory space occupied by unavailable variable values
3, Why garbage collection mechanism?
A large amount of memory space will be applied for in the process of program running. If some useless memory space is not cleaned up in time, it will lead to memory exhaustion (memory overflow) and program crash. Therefore, managing memory is an important and complicated thing. The garbage collection mechanism of python interpreter frees the programmer from the complicated memory management.
4, Knowledge needed to be reserved to understand GC principle
4.1 heap area and stack area
When defining variables, both the variable name and the variable value need to be stored, corresponding to two areas in memory: heap area and stack area
#1. The relationship between variable name and value memory address is stored in the stack area #2. The variable values are stored in the heap area, and the contents of the heap area are recycled by memory management,
4.2 direct reference and indirect reference
Direct reference refers to the memory address directly referenced from the stack area.
Indirect reference refers to the memory address that can be reached by further reference after starting from stack area to heap area.
as
l2 = [20, 30] # The list itself is directly referenced by the variable name l2, and the contained elements are indirectly referenced by the list x = 10 # Value 10 is directly referenced by variable name x l1 = [x, l2] # The list itself is directly referenced by the variable name l1, and the contained elements are indirectly referenced by the list
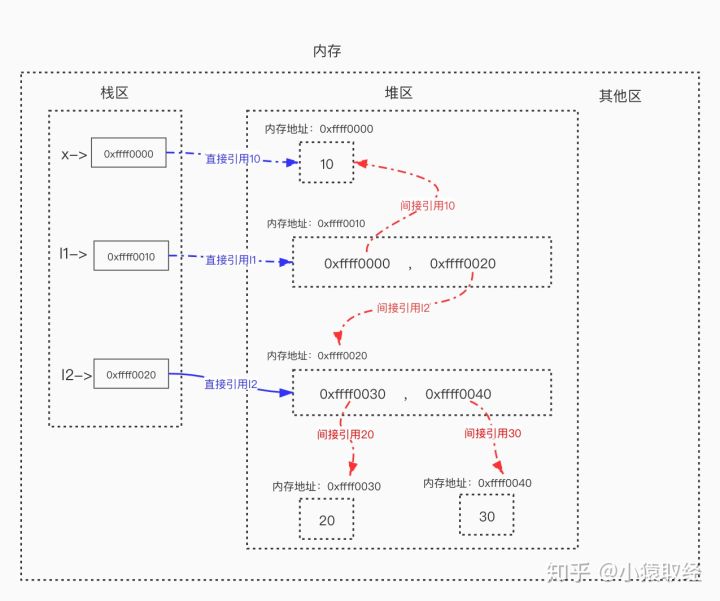
5, Principle analysis of garbage collection mechanism
Python's GC module mainly uses "reference counting" to track and recycle garbage. On the basis of reference counting, we can also solve the problem of circular references that may be generated by container objects through mark and sweep, and further improve the efficiency of garbage collection by the way of space in exchange for time through generation collection.
5.1 reference count
Reference count is the number of times a variable value is associated with a variable name
For example: age=18
Variable value 18 is associated with a variable name age, which is called reference count 1
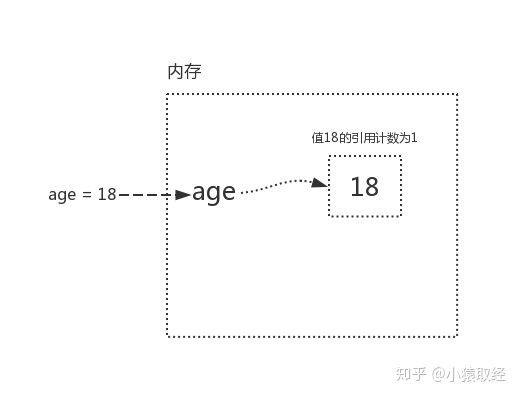
Reference count increase:
age=18 (at this time, the reference count of variable value 18 is 1)
m=age (when the memory address of age is given to m, m and age are all associated with 18, so the reference count of variable value 18 is 2)
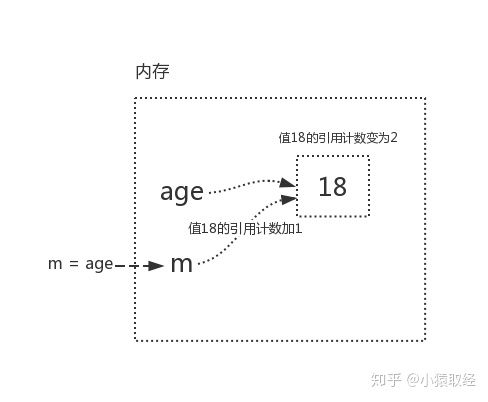
Reduce reference count:
age=10 (the name is disassociated from the value 18, and then associated with 3. The reference count of the variable value 18 is 1)
del m (del means to disassociate variable name x from variable value 18. At this time, the reference count of variable 18 is 0)
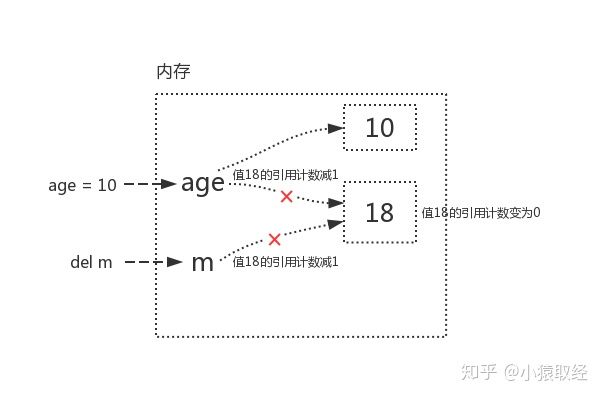
Once the reference count of value 18 changes to 0, the memory address occupied by it should be recycled by the interpreter's garbage collection mechanism
5.2 problems and solutions of reference counting
5.2.1 question 1: circular reference
A fatal weakness of the reference counting mechanism is circular reference (also known as cross reference)
# As follows, we define two lists, namely list 1 and list 2 for short. Variable name l1 points to list 1 and variable name l2 points to list 2 >>> l1=['xxx'] # List 1 is referenced once, and the reference count of list 1 changes to 1 >>> l2=['yyy'] # List 2 is referenced once, and the reference count of list 2 changes to 1 >>> l1.append(l2) # Append Listing 2 to l1 as the second element, and the reference count of Listing 2 becomes 2 >>> l2.append(l1) # Append Listing 1 to l2 as the second element, and the reference count of Listing 1 becomes 2 # There are mutual references between l1 and l2 # l1 = ['xxx 'memory address, list 2 memory address] # l2 = ['yyy 'memory address, list 1 memory address] >>> l1 ['xxx', ['yyy', [...]]] >>> l2 ['yyy', ['xxx', [...]]] >>> l1[1][1][0] 'xxx'
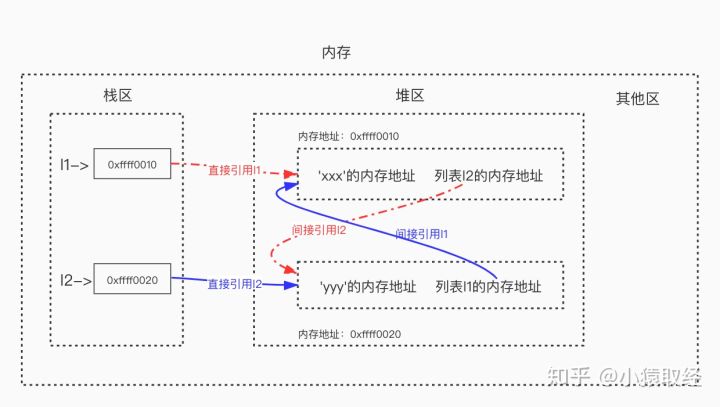
python introduces "mark clear" and "generational recycle" to solve the problem of circular reference and low efficiency of reference count
5.2.2 solution: mark clear
Container objects (such as list, set, dict, class, instance) can contain references to other objects, so circular references may be generated. The mark clear count is to solve the problem of circular references.
The method of mark / clear algorithm is that when the available memory space of the application is exhausted, the whole program will be stopped, and then two works will be carried out, the first is the mark, the second is the clear
5.2.3 question 2: efficiency
Based on the recycling mechanism of reference count, every time the memory is recycled, the reference count of all objects needs to be traversed once, which is very time-consuming, so the generational recycling is introduced to improve the recycling efficiency, and the generational recycling adopts the strategy of "space for time".
5.2.4 solution: recycling by generations
Generation:
The core idea of generational recycling is: in the case of multiple scans, there is no recovered variable. The gc mechanism will think that this variable is a common variable, and the frequency of gc scanning for it will be reduced. The specific implementation principle is as follows:
Generation refers to the classification of variables into different levels (i.e. different generations) according to their survival time The newly defined variable is placed in the new generation level, assuming that the new generation is scanned every 1 minute. If the variable is still referenced, then the weight of the object (the weight essence is an integer) is increased by one. When the weight of the variable is greater than a set value (assuming 3), it will be moved to a higher level of youth, and the frequency of gc scanning of the youth is lower than that of the new generation (the scanning interval is longer). Suppose that the youth generation is scanned once in 5 minutes, so that the total number of variables to be scanned by each gc becomes less, saving the total scanning time. Next, the objects in the youth generation will be moved to the old generation in the same way. That is, the higher the level (generation), the lower the frequency of being scanned by the garbage collection mechanism
Recycling:
Recycling still uses reference count as the basis for recycling
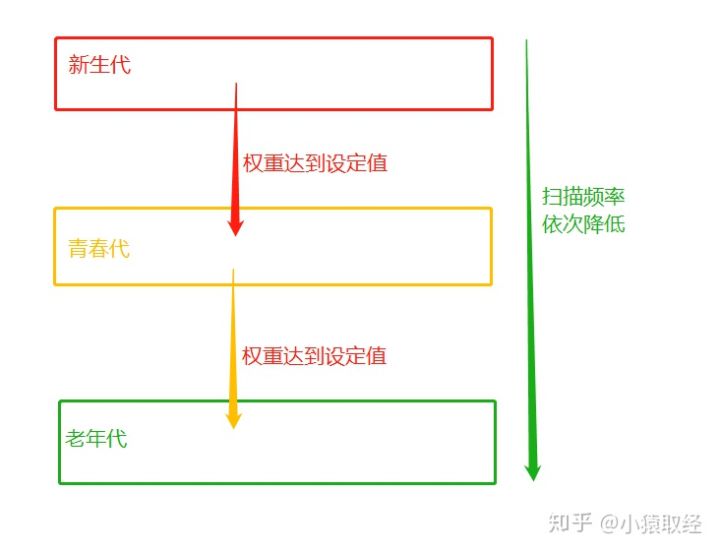
Although generational recycling can improve efficiency, there are some disadvantages:
For example, as soon as a variable is transferred from the new generation to the youth generation, the binding relationship of the variable is released, and the variable should be recycled, but the scanning frequency of the youth generation is lower than that of the new generation, which leads to that the garbage that should be recycled is not cleaned up in time. There is no perfect solution: There is no doubt that if there is no generational recycling, that is, the reference counting mechanism keeps scanning all variables all the time, which can clean up the memory occupied by garbage in a more timely manner. However, this way of scanning all variables all the time is extremely inefficient, so we can only neutralize them. To sum up In the background of garbage cleaning and memory freeing, garbage collection mechanism allows generation by generation collection at the cost that a small part of garbage will not be released in time, in exchange for the reduction of the overall scanning frequency of reference count, so as to improve its performance. This is a solution catalog of space for time
6. Introduction to Python syntax: user interaction and operators
One program and user interaction
1.1 what is interaction with users
User interaction is that people input / input data into the computer, and the computer print / output results
1.2 why interact with users?
In order to make computers communicate with users like people
1.3 how to interact with users
The essence of interaction is input and output
1.3.1 input:
#In python3, the input function will wait for the user's input. Any content entered by the user will be saved as a string type, and then assigned to the variable name to the left of the equal sign
>>>Username = input ('Please enter your username: ')
Please enter your user name: Jack ා username = "Jack"
>>>Password = input ('Please enter your password: ')
Please enter your password: 123 ා password = "123"
#Knowledge:
#1. There is a raw in python2_ The input function is as like as two peas in the python3 input.
#2. There is also an input function in python2, which requires the user to input a clear data type, and save whatever type is input
>>>L = input ('whatever type of input will be saved as: ')
The input type is saved as the type: [1,2,3]
>>> type(l)
<type 'list'>
1.3.2 output print:
>>> print('hello world') # Output only one value
hello world
>>> print('first','second','third') # Output multiple values at once, separated by commas
first second third
# The default print function has an end parameter. The default value of this parameter is "\ n" (for line feed). You can change the value of the end parameter to any other character
print("aaaa",end='')
print("bbbb",end='&')
print("cccc",end='@')
#The overall output is aaaabbbb & CCCC@
1.3.3 format output of output
(1) What is formatted output?
To replace some contents of a string and then output it is to format the output.
(2) Why format the output?
We often output content with some fixed format, such as: 'hello dear XXX! Your monthly call fee is XXX, and the balance is xxx '. What we need to do is to replace XXX with specific content.
(3) How to format the output?
Placeholders are used, such as:% s,% d:
# %s placeholder: can receive any type of value
# %d placeholder: can only receive numbers
>>> print('dear%s Hello! you%s The monthly call charge is%d,The balance is%d' %('tony',12,103,11))
//Hello, dear tony! Your call charge in December is 103, and the balance is 11
# Exercise 1: receive user input and print to the specified format
name = input('your name: ')
age = input('your age: ') #User input 18 will be saved as string 18, unable to pass to% d
print('My name is %s,my age is %s' %(name,age))
# Exercise 2: the user enters the name, age, work, hobbies, and then prints them into the following format
------------ info of Tony -----------
Name : Tony
Age : 22
Sex : male
Job : Teacher
------------- end -----------------
Two basic operators
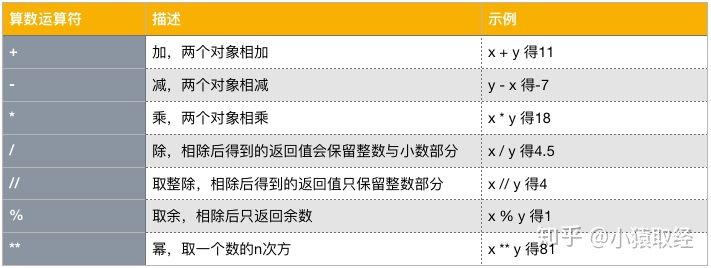
2.1 arithmetic operators
The arithmetic operators supported by python are consistent with the symbols used in mathematical calculation. Let's take x=9 and y=2 as examples to introduce them in turn
2.2 comparison operators
The comparison operation is used to compare two values. It returns the Boolean value True or False. We take x=9 and y=2 as examples to introduce them in turn

2.3 assignment operators
In addition to the simple assignment operation of = sign, python syntax also supports incremental assignment, chain assignment, cross assignment and decompression assignment. The meaning of these assignment operators is to make our code look more concise. Let's take x=9, y=2 as an example to introduce incremental assignment
2.3.1 incremental assignment

2.3.2 chain assignment
If we want to assign the same value to multiple variable names at the same time, we can do this
>>> z=10 >>> y=z >>> x=y >>> x,y,z (10, 10, 10)
Chain assignment means that you can do it in one line of code
>>> x=y=z=10 >>> x,y,z (10, 10, 10)
2.3.3 cross assignment
We define two variables m and n
If we want to swap the values of m and n, we can do this
>>> temp=m >>> m=n >>> n=temp >>> m,n (20, 10)
Cross assignment refers to a line of code that can do this
>>> m=10 >>> n=20 >>> m,n=n,m # Cross assignment >>> m,n (20, 10)
2.3.4 decompression and assignment
If we want to take out multiple values in the list and assign them to multiple variable names in turn, we can do this
>>> nums=[11,22,33,44,55] >>> >>> a=nums[0] >>> b=nums[1] >>> c=nums[2] >>> d=nums[3] >>> e=nums[4] >>> a,b,c,d,e (11, 22, 33, 44, 55)
Unzip assignment means that one line of code can do this
>>> a,b,c,d,e=nums # nums contains multiple values, just like a compressed package. It is named after decompressing and assigning values >>> a,b,c,d,e (11, 22, 33, 44, 55)
Note that for the above decompression and assignment, the number of variable names on the left side of the equal sign must be the same as the number of values on the right side, otherwise an error will be reported
#1. Variable names are missing >>> a,b=nums Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: too many values to unpack (expected 2) #2. Too many variable names >>> a,b,c,d,e,f=nums Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: not enough values to unpack (expected 6, got 5)
But if we only want to take a few values of the head and tail, we can use*_ matching
>>> a,b,*_=nums >>> a,b (11, 22)
ps: string, dictionary, tuple and set type all support decompression and assignment
2.4 logical operators
Logical operators are used to connect multiple conditions for association judgment, and return Boolean value True or False

2.4.1 continuous multiple and
You can use and to connect multiple conditions, which will be judged from left to right. Once a condition is False, you don't need to judge from right. You can immediately determine that the final result is False. Only when the results of all conditions are True, the final result is True.
>>> 2 > 1 and 1 != 1 and True and 3 > 2 # After judging the second condition, it will end immediately. The final result is False False
2.4.2 consecutive or
You can use or to connect multiple conditions, which will be judged from left to right. Once a condition is True, you don't need to judge from right. You can immediately determine that the final result is True. Only when the results of all conditions are False, the final result is False
>>> 2 > 1 or 1 != 1 or True or 3 > 2 # When the first condition is judged, it ends immediately, and the final result is True True
2.4.3 priority not > and > or
#1. The priority relationship of the three: not > and > or. The same priority is calculated from left to right by default.
>>> 3>4 and 4>3 or 1==3 and 'x' == 'x' or 3 >3
False
#2. It's best to use parentheses to distinguish priorities, which means the same as above
'''
The principle is:
(1) The highest priority of not is to reverse the result of the condition immediately following, so not and the condition immediately following cannot be separated
(2) If all statements are connected with and, or all statements are connected with or, then the calculation can be done from left to right
(3) If there are both and and or in the statement, first enclose the left and right conditions of and with brackets, and then perform the operation
'''
>>> (3>4 and 4>3) or (1==3 and 'x' == 'x') or 3 >3
False
#3. Short circuit operation: once the result of logical operation can be determined, the current calculated value will be used as the final result to return
>>> 10 and 0 or '' and 0 or 'abc' or 'egon' == 'dsb' and 333 or 10 > 4
Let's use parentheses to clarify the priority
>>> (10 and 0) or ('' and 0) or 'abc' or ('egon' == 'dsb' and 333) or 10 > 4
Short circuit: 0 ''abc'
False false true
Back: 'abc'
#4. Short circuit questions:
>>> 1 or 3
1
>>> 1 and 3
3
>>> 0 and 2 and 1
0
>>> 0 and 2 or 1
1
>>> 0 and 2 or 1 or 4
1
>>> 0 or False and 1
False
2.5 member operators

Note: Although the following two judgments can achieve the same effect, we recommend the second format, because the semantics of not in is more explicit
>>> not 'lili' in ['jack','tom','robin'] True >>> 'lili' not in ['jack','tom','robin'] True
2.6 identity operator

It should be emphasized that = = the double equal sign compares whether the value s are equal, while the is compares whether the IDs are equal
#1. The same ID and memory address means the same type and value #2. The same value type must be the same, but the id may be different, as follows >>> x='Info Tony:18' >>> y='Info Tony:18' >>> id(x),id(y) # x and y have different IDS, but they have the same values (4327422640, 4327422256) >>> x == y # The equal sign compares value True >>> type(x),type(y) # Same value, same type (<class 'str'>, <class 'str'>) >>> x is y # is compares the id. the values of x and y are the same, but the id can be different False
7. Process control of getting started with Python syntax
An introduction:
Process control is the control process, which specifically refers to the execution process of the control program. The execution process of the program can be divided into three structures: sequence structure (the code we wrote before is sequence structure), branch structure (using if judgment), and loop structure (using while and for)
Two branch structure
2.1 what is branch structure
Branch structure is to execute the sub code corresponding to different branches according to the true or false conditions
2.2 why to use branch structure
People sometimes need to decide what to do according to the conditions, such as: if it rains today, take an umbrella
So there must be a corresponding mechanism in the program to control the judgment ability of the computer
2.3 how to use branch structure
2.3.1 if syntax
Use the if keyword to implement the branch structure. The complete syntax is as follows
If condition 1: if the result of condition 1 is True, execute code 1, code 2
Code 1
Code 2
......
elif condition 2: if the result of condition 2 is True, execute in sequence: Code 3, code 4
Code 3
Code 4
......
elif condition 3: if the result of condition 3 is True, execute in sequence: code 5, code 6
Code 5
Code 6
......
else: in other cases, code 7, code 8
Code 7
Code 8
......
#Note:
#1. python uses the same indentation (4 spaces for an indentation) to identify a group of code blocks, and the same group of codes will run from top to bottom in turn
#2. The condition can be any expression, but the execution result must be of boolean type
#All data types are automatically converted to Boolean types in if judgment
#2.1, None, 0, empty (empty string, empty list, empty dictionary, etc.) the Boolean value converted into is False
#2.2. The rest are True
2.3.2 if application case
Case 1:
If a woman's age is more than 30, then it's called an aunt
age_of_girl=31
if age_of_girl > 30:
print('Hello, auntie')
Case 2:
If: the age of a woman is more than 30, then: call aunt, otherwise: call Miss
age_of_girl=18
if age_of_girl > 30:
print('Hello, auntie')
else:
print('Hello, miss')
Case 3:
If a woman's age is more than 18 and less than 22 years old, her height is more than 170, her weight is less than 100 and she is beautiful, then: to express her love, otherwise: to call her aunt**
age_of_girl=18
height=171
weight=99
is_pretty=True
if age_of_girl >= 18 and age_of_girl < 22 and height > 170 and weight < 100 and is_pretty == True:
print('Confession...')
else:
print('Hello, auntie')
Case 4:
If: score > = 90, then: excellent
If the score is > = 80 and < 90, then: good
If the score is > = 70 and < 80, then: Average
Other situation: very bad
score=input('>>: ')
score=int(score)
if score >= 90:
print('excellent')
elif score >= 80:
print('good')
elif score >= 70:
print('ordinary')
else:
print('Very bad')
Case 5: if nesting
#Continue on the basis of confession:
#If the confession is successful, then: together
#Otherwise: print...
age_of_girl=18
height=171
weight=99
is_pretty=True
success=False
if age_of_girl >= 18 and age_of_girl < 22 and height > 170 and weight < 100 and is_pretty == True:
if success:
print('Successful confession,in harness')
else:
print('What love is not love,love nmlgb Love of,love nmlg ah...')
else:
print('Hello, auntie')
Exercise 1: login function
name=input('Please enter user name:').strip()
password=input('Please input a password:').strip()
if name == 'tony' and password == '123':
print('tony login success')
else:
print('Wrong user name or password')
Exercise 2:
#!/usr/bin/env python
#Print permissions based on user input
'''
egon --> Super administrator
tom --> General administrator
jack,rain --> Business Director
//Other general users
'''
name=input('Please enter user name:')
if name == 'egon':
print('Super administrator')
elif name == 'tom':
print('General administrator')
elif name == 'jack' or name == 'rain':
print('Business Director')
else:
print('Ordinary users')
Three cycle structure
3.1 what is circular structure
Loop structure is to execute a block of code repeatedly
3.2 why to use cycle structure
Human beings need to do something repeatedly sometimes
So there must be a corresponding mechanism in the program to control the computer to have the ability of human beings to do things in this cycle
3.3 how to use cycle structure
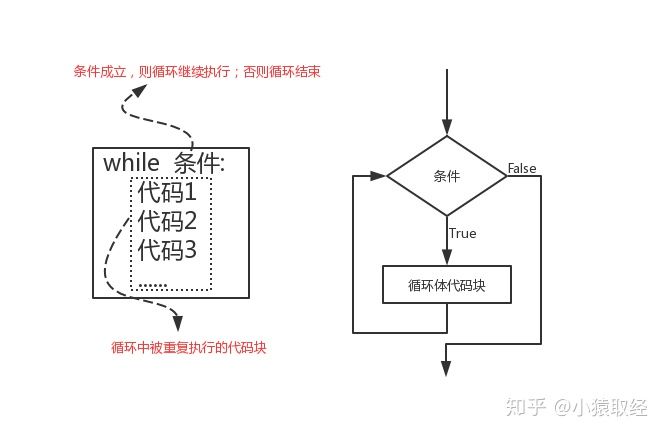
3.3.1 while loop syntax
In python, there are two circulation mechanisms: while and for. The while loop is called conditional loop. The syntax is as follows
while condition:
Code 1
Code 2
Code 3
Running steps of while:
Step 1: if the condition is true, execute in sequence: Code 1, code 2, code 3
Step 2: judge the condition again after execution. If the condition is True, execute again: Code 1, code 2, code 3,..., if the condition is False, the loop will terminate
3.3.2 while loop application case
Case 1: basic use of while loop
User authentication procedure
#The basic logic of the user authentication program is to receive the user name and password input by the user, and then judge with the user name and password stored in the program. If the judgment is successful, the login is successful, and if the judgment is unsuccessful, the output account or password is wrong
username = "jason"
password = "123"
inp_name = input("Please enter the user name:")
inp_pwd = input("Please input a password:")
if inp_name == username and inp_pwd == password:
print("Login succeeded")
else:
print("The user name or password entered is wrong!")
#Generally, in case of authentication failure, the user will be required to re-enter the user name and password for authentication. If we want to give the user three trial and error opportunities, the essence is to run the above code three times, you will not want to copy the code three times....
username = "jason"
password = "123"
# First verification
inp_name = input("Please enter the user name:")
inp_pwd = input("Please input a password:")
if inp_name == username and inp_pwd == password:
print("Login succeeded")
else:
print("The user name or password entered is wrong!")
# Second verification
inp_name = input("Please enter the user name:")
inp_pwd = input("Please input a password:")
if inp_name == username and inp_pwd == password:
print("Login succeeded")
else:
print("The user name or password entered is wrong!")
# Third verification
inp_name = input("Please enter the user name:")
inp_pwd = input("Please input a password:")
if inp_name == username and inp_pwd == password:
print("Login succeeded")
else:
print("The user name or password entered is wrong!")
#Even if you are Xiaobai, do you think it's too low? You have to modify the function three times in the future. So remember, writing repeated code is the most shameful behavior of programmers.
#So how to make a program repeat a piece of code many times without writing duplicate code? Loop statements come in handy (using while loops)
username = "jason"
password = "123"
# Record the number of bad validations
count = 0
while count < 3:
inp_name = input("Please enter the user name:")
inp_pwd = input("Please input a password:")
if inp_name == username and inp_pwd == password:
print("Login succeeded")
else:
print("The user name or password entered is wrong!")
count += 1
Case 2: use of while+break
After using the while loop, the code is indeed much simpler, but the problem is that the user can not end the loop after entering the correct user name and password, so how to end the loop? This needs to use break!
username = "jason"
password = "123"
# Record the number of bad validations
count = 0
while count < 3:
inp_name = input("Please enter the user name:")
inp_pwd = input("Please input a password:")
if inp_name == username and inp_pwd == password:
print("Login succeeded")
break # Used to end the layer cycle
else:
print("The user name or password entered is wrong!")
count += 1
Case 3: while loop nesting + break
If there are many layers nested in the while loop, to exit each layer loop, you need to have a break in each layer loop
username = "jason"
password = "123"
count = 0
while count < 3: # First level cycle
inp_name = input("Please enter the user name:")
inp_pwd = input("Please input a password:")
if inp_name == username and inp_pwd == password:
print("Login succeeded")
while True: # Second layer cycle
cmd = input('>>: ')
if cmd == 'quit':
break # Used to end the layer cycle, i.e. the second layer cycle
print('run <%s>' % cmd)
break # Used to end the layer cycle, i.e. the first layer cycle
else:
print("The user name or password entered is wrong!")
count += 1
Case 4: use of while loop nesting + tag
For nested multi-layer while loops, if our purpose is clear that we want to directly exit the loops of all layers in a certain layer, there is a trick, that is, let all the conditions of the while loop use the same variable, the initial value of the variable is True, once the value of the variable is changed to False in a certain layer, the loops of all layers will end
username = "jason"
password = "123"
count = 0
tag = True
while tag:
inp_name = input("Please enter the user name:")
inp_pwd = input("Please input a password:")
if inp_name == username and inp_pwd == password:
print("Login succeeded")
while tag:
cmd = input('>>: ')
if cmd == 'quit':
tag = False # tag becomes False, and the conditions of all while loops become False
break
print('run <%s>' % cmd)
break # Used to end the layer cycle, i.e. the first layer cycle
else:
print("The user name or password entered is wrong!")
count += 1
Case 5: use of while+continue
break means to end this layer's cycle, while continue is used to end this cycle and directly enter the next cycle
# Print between 1 and 10, all numbers except 7
number=11
while number>1:
number -= 1
if number==7:
continue # End this loop, that is, the code after continue will not run, but directly enter the next loop
print(number)
Case 5: use of while+else
After the while loop, we can follow the else statement. When the while loop executes normally and is not interrupted by break, it will execute the statement after else. Therefore, we can use else to verify whether the loop ends normally
count = 0
while count <= 5 :
count += 1
print("Loop",count)
else:
print("The cycle is running normally")
print("-----out of while loop ------")
//output
Loop 1
Loop 2
Loop 3
Loop 4
Loop 5
Loop 6
//The loop is running normally. It is not interrupted by break, so this line of code is executed
-----out of while loop ------
If it is broken during execution, the else statement will not be executed
count = 0
while count <= 5 :
count += 1
if count == 3:
break
print("Loop",count)
else:
print("The cycle is running normally")
print("-----out of while loop ------")
//output
Loop 1
Loop 2
-----out of while loop ------ #Since the loop is interrupted by break, the output statement after else is not executed
Exercise 1:
Find the maximum multiple of the number 7 between 1 and 100 (the result is 98)
number = 100 while number > 0: if number %7 == 0: print(number) break number -= 1
Exercise 2:
age=18
count=0
while count<3:
count+=1
guess = int(input(">>:"))
if guess > age :
print("It's too big to guess. Try small...")
elif guess < age :
print("It's too small to guess. Try the big one...")
else:
print("Congratulations, that's right...")
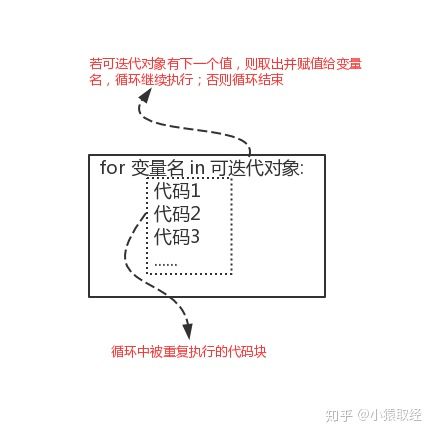
3.3.3 for loop syntax
The second way to implement the loop structure is the for loop. All the things that the for loop can do can be realized by the while loop. The reason why the for loop is used is that the use of the for loop is more concise than that of the while loop when it takes values (i.e. traversal values),
for loop syntax is as follows
for variable name in iteratable object: ා at this time, you only need to know that the iteratable object can be a string \ list \ dictionary. We will explain the iteratable object specifically later
Code one
Code two
...
#Example 1
for item in ['a','b','c']:
print(item)
#Operation results
a
b
c
#Refer to example 1 to introduce the operation steps of for loop
#Step 1: read out the first value from the list ['a','b','c '] and assign it to item (item ='a'), then execute the loop body code
#Step 2: read out the second value from the list ['a','b','c '] and assign it to the item (item ='b'), then execute the loop body code
#Step 3: repeat the above process until the values in the list are read out
3.3.4 for circular application case
# Simple version: implementation of for loop
for count in range(6): # range(6) will generate 6 numbers from 0-5
print(count)
# Complex version: the implementation of while loop
count = 0
while count < 6:
print(count)
count += 1
Case 2: traversal dictionary
# Simple version: implementation of for loop
for k in {'name':'jason','age':18,'gender':'male'}: # for loop takes the key of dictionary and assigns it to variable name k by default
print(k)
# Complex version: while loop can traverse the dictionary, which will be described in detail in the iterator section later
Case 3: for loop nesting
#Please use for loop nesting to print the following figure:
*****
*****
*****
for i in range(3):
for j in range(5):
print("*",end='')
print() # print() for line feed
Note: break and continue can also be used for loops, with the same syntax as while loops
Exercise 1:
Print multiplication table
for i in range(1,10):
for j in range(1,i+1):
print('%s*%s=%s' %(i,j,i*j),end=' ')
print()
Exercise 2:
Print pyramid
# analysis
'''
#max_level=5
* # current_level=1, number of spaces = 4, * sign = 1
*** # current_level=2, number of spaces = 3, * sign = 3
***** # current_level=3, number of spaces = 2, * sign = 5
******* # current_level=4, number of spaces = 1, * sign = 7
********* # current_level=5, number of spaces = 0, * sign = 9
# mathematical expression
//Number of spaces = max_level-current_level
*Number=2*current_level-1
'''
# realization:
max_level=5
for current_level in range(1,max_level+1):
for i in range(max_level-current_level):
print(' ',end='') #Print multiple spaces in a row
for j in range(2*current_level-1):
print('*',end='') #Print multiple spaces in a row
print()
8. Basic data types and built-in methods
A primer
The data type is used to record the state of things, and the state of things is constantly changing (such as: the growth of a person's age (operation int type), the modification of a single person's name (operation str type), the addition of students in the student list (operation list type), etc.), which means that we need to frequently operate data when developing programs, in order to improve our development efficiency, python has built in a series of methods for each of these common operations. The topic of this chapter is to give you a detailed understanding of them, as well as the detailed definition and type conversion of each data type.
Binary type int and float
2.1 definitions
# 1. Definition: # 1.1 definition of int age=10 # Essential age = int(10) # 1.2 definition of float salary=3000.3 # Essence salary=float(3000.3) # Note: Name + bracket means to call a function, such as # print(...) calls the print function # int(...) calls the ability to create integer data # float(...) calls the ability to create floating-point data
2.2 type conversion
# 1. Data type conversion
# 1.1 int can directly convert a string composed of pure integers to integers. If it contains any other non integer symbols, an error will be reported
>>> s = '123'
>>> res = int(s)
>>> res,type(res)
(123, <class 'int'>)
>>> int('12.3') # Error demonstration: the string contains a non integer symbol
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: invalid literal for int() with base 10: '12.3'
# 1.2 base conversion
# Decimal to other base
>>> bin(3)
'0b11'
>>> oct(9)
'0o11'
>>> hex(17)
'0x11'
# Other decimal to decimal
>>> int('0b11',2)
3
>>> int('0o11',8)
9
>>> int('0x11',16)
17
# 1.3 float can also be used for data type conversion
>>> s = '12.3'
>>> res=float(s)
>>> res,type(res)
(12.3, <class 'float'>)
2.3 use
The number type is mainly used for mathematical operation and comparison operation, so there is no built-in method to master except for the combination of number type and operator
Three strings
3.1 definition:
# Definition: include a string of characters in single quotation mark \ double quotation mark \ triple quotation mark
name1 = 'jason' # Nature: name = str('content in any form ')
name2 = "lili" # Nature: name = str("any form of content")
name3 = """ricky""" # Nature: name = str("" content in any form ""))
3.2 type conversion
# Data type conversion: str() can convert any data type to a string type, for example
>>> type(str([1,2,3])) # list->str
<class 'str'>
>>> type(str({"name":"jason","age":18})) # dict->str
<class 'str'>
>>> type(str((1,2,3))) # tuple->str
<class 'str'>
>>> type(str({1,2,3,4})) # set->str
<class 'str'>
3.3 use
3.3.1 priority operation
>>> str1 = 'hello python!'
# 1. Value by index (forward, reverse):
# 1.1 forward direction (from left to right)
>>> str1[6]
p
# 1.2 reverse access (negative sign means right to left)
>>> str1[-4]
h
# 1.3 for str, the value can only be taken according to the index and cannot be changed
>>> str1[0]='H' # Error TypeError
# 2. Slice (look at the head and ignore the tail, step size)
# 2.1 ignore head and tail: take out all characters with index from 0 to 8
>>> str1[0:9]
hello pyt
# 2.2 step size: 0:9:2. The third parameter 2 represents step size. It will start from 0 and accumulate one 2 at a time, so the characters of index 0, 2, 4, 6 and 8 will be taken out
>>> str1[0:9:2]
hlopt
# 2.3 reverse sectioning
>>> str1[::-1] # -1 means right to left
!nohtyp olleh
# 3. Length len
# 3.1 get the length of the string, that is, the number of characters. All the characters in quotation marks are counted as characters.)
>>> len(str1) # Spaces are also characters
13
# 4. Member operations in and not in
# 4.1 int: judge whether hello is in str1
>>> 'hello' in str1
True
# 4.2 not in: judge whether tony is not in str1
>>> 'tony' not in str1
True
# 5.strip remove the characters specified at the beginning and end of the string (remove space by default)
# 5.1 no characters are specified in brackets. The first and last blank characters (spaces, n, t) are removed by default
>>> str1 = ' life is short! '
>>> str1.strip()
life is short!
# 5.2 remove the first and last specified characters
>>> str2 = '**tony**'
>>> str2.strip('*')
tony
# 6. split
# 6.1 no characters are specified in brackets, and spaces are used as segmentation symbols by default
>>> str3='hello world'
>>> str3.split()
['hello', 'world']
# 6.2 if the separator character is specified in the bracket, the string will be cut according to the character specified in the bracket
>>> str4 = '127.0.0.1'
>>> str4.split('.')
['127', '0', '0', '1'] # Note: the result of split cutting is the list data type
# 7. Circulation
>>> str5 = 'How are you today?'
>>> for line in str5: # Extract each character in the string in turn
... print(line)
...
//this
//day
//you
//good
//Do you
?
3.3.2 operation to be mastered
1. strip, lstrip, rstrip
>>> str1 = '**tony***'
>>> str1.strip('*') # Remove left and right specified characters
'tony'
>>> str1.lstrip('*') # Remove only the specified characters on the left
tony***
>>> str1.rstrip('*') # Remove only the specified characters on the right
**tony
2. lower(),upper()
>>> str2 = 'My nAme is tonY!' >>> str2.lower() # Change all English strings to lowercase my name is tony! >>> str2.upper() # Capitalize all English strings MY NAME IS TONY!
3. startswith,endswith
>>> str3 = 'tony jam'
# Startswitch() determines whether the string starts with the character specified in parentheses, and the result is a Boolean value of True or False
>>> str3.startswith('t')
True
>>> str3.startswith('j')
False
# Endswitch() determines whether the string ends with the character specified in parentheses, and the result is a Boolean value of True or False
>>> str3.endswith('jam')
True
>>> str3.endswith('tony')
False
4. format of formatted output
Before we used% s to format and output strings, when passing values, we must strictly follow the position to correspond to% s one by one, while the built-in method format of strings provides a position independent way of passing values
Case:
# format parentheses can completely disrupt the order when passing parameters, but they can still pass values for specified parameters by name. Name = 'tony' is passed to {name}
>>> str4 = 'my name is {name}, my age is {age}!'.format(age=18,name='tony')
>>> str4
'my name is tony, my age is 18!'
>>> str4 = 'my name is {name}{name}{name}, my age is {name}!'.format(name='tony', age=18)
>>> str4
'my name is tonytonytony, my age is tony!'
Other ways to use format (learn)
# Similar to the usage of% s, the passed in value will correspond to {} one by one according to the location
>>> str4 = 'my name is {}, my age is {}!'.format('tony', 18)
>>> str4
my name is tony, my age is 18!
# Take the values passed in by format as a list, and then use {index} to get values
>>> str4 = 'my name is {0}, my age is {1}!'.format('tony', 18)
>>> str4
my name is tony, my age is 18!
>>> str4 = 'my name is {1}, my age is {0}!'.format('tony', 18)
>>> str4
my name is 18, my age is tony!
>>> str4 = 'my name is {1}, my age is {1}!'.format('tony', 18)
>>> str4
my name is 18, my age is 18!
5.split,rsplit
# Split will split the string from left to right, and you can specify the number of times to cut
>>> str5='C:/a/b/c/d.txt'
>>> str5.split('/',1)
['C:', 'a/b/c/d.txt']
# rsplit is just the opposite of split. It cuts from right to left. You can specify the number of cuts
>>> str5='a|b|c'
>>> str5.rsplit('|',1)
['a|b', 'c']
6. join
# Take multiple strings from the iteratable object, and then splice them according to the specified separator. The splicing result is string
>>> '%'.join('hello') # Take multiple strings from the string 'hello' and splice them with% as the separator
'h%e%l%l%o'
>>> '|'.join(['tony','18','read']) # Extract multiple strings from the list and splice them with * as a separator
'tony|18|read'
7. replace
# Replace the old character in the string with a new character
>>> str7 = 'my name is tony, my age is 18!' # Change tony's age from 18 to 73
>>> str7 = str7.replace('18', '73') # Syntax: replace('old content ',' new content ')
>>> str7
my name is tony, my age is 73!
# You can specify the number of modifications
>>> str7 = 'my name is tony, my age is 18!'
>>> str7 = str7.replace('my', 'MY',1) # Change only one my to my
>>> str7
'MY name is tony, my age is 18!'
8.isdigit
# Judge whether the string is composed of pure numbers, and the return result is True or False >>> str8 = '5201314' >>> str8.isdigit() True >>> str8 = '123g123' >>> str8.isdigit() False
3.3.3 understanding operation
# 1.find,rfind,index,rindex,count
# 1.1 find: find the starting index of the substring from the specified range, return the number 1 if found, and - 1 if not found
>>> msg='tony say hello'
>>> msg.find('o',1,3) # Find the index of character o in characters with index 1 and 2 (regardless of the end)
1
# 1.2 index: the same as find, but an error will be reported if it cannot be found
>>> msg.index('e',2,4) # Value error
# 1.3 rfind and rindex: omitted
# 1.4 count: count the number of times a string appears in a large string
>>> msg = "hello everyone"
>>> msg.count('e') # Count the number of occurrences of string e
4
>>> msg.count('e',1,6) # Number of occurrences of string e in index 1-5 range
1
# 2.center,ljust,rjust,zfill
>>> name='tony'
>>> name.center(30,'-') # The total width is 30, the string is displayed in the middle, not enough - fill
-------------tony-------------
>>> name.ljust(30,'*') # The total width is 30, the string is aligned to the left, not filled with *
tony**************************
>>> name.rjust(30,'*') # The total width is 30, the string is aligned to the right, not filled with *
**************************tony
>>> name.zfill(50) # The total width is 50, the string is right aligned, not enough to be filled with 0
0000000000000000000000000000000000000000000000tony
# 3.expandtabs
>>> name = 'tony\thello' # \t for tab
>>> name
tony hello
>>> name.expandtabs(1) # Modify \ tnumber of spaces represented by tabs
tony hello
# 4.captalize,swapcase,title
# 4.1 capitalization
>>> message = 'hello everyone nice to meet you!'
>>> message.capitalize()
Hello everyone nice to meet you!
# 4.2 swapcase: case flip
>>> message1 = 'Hi girl, I want make friends with you!'
>>> message1.swapcase()
hI GIRL, i WANT MAKE FRIENDS WITH YOU!
#4.3 title: capitalize each word
>>> msg = 'dear my friend i miss you very much'
>>> msg.title()
Dear My Friend I Miss You Very Much
# 5.is digital series
#In Python 3
num1 = b'4' #bytes
num2 = u'4' #unicode is unicode without u in python3
num3 = 'Four' #Chinese number
num4 = 'Ⅳ' #Roman numeral
#isdigt:bytes,unicode
>>> num1.isdigit()
True
>>> num2.isdigit()
True
>>> num3.isdigit()
False
>>> num4.isdigit()
False
#isdecimal:uncicode (no isdecimal method for bytes type)
>>> num2.isdecimal()
True
>>> num3.isdecimal()
False
>>> num4.isdecimal()
False
#I snumberic:unicode , Chinese number, Roman number (no IsNumeric method for bytes type)
>>> num2.isnumeric()
True
>>> num3.isnumeric()
True
>>> num4.isnumeric()
True
# Three cannot judge floating point
>>> num5 = '4.3'
>>> num5.isdigit()
False
>>> num5.isdecimal()
False
>>> num5.isnumeric()
False
'''
//Summary:
//The most commonly used is isdigit, which can judge the types of bytes and unicode, which is also the most common digital application scenario
//If you want to judge Chinese numbers or roman numbers, you need to use isnumeric.
'''
# 6.is others
>>> name = 'tony123'
>>> name.isalnum() #Strings can contain either numbers or letters
True
>>> name.isalpha() #String contains only letters
False
>>> name.isidentifier()
True
>>> name.islower() # Whether the string is pure lowercase
True
>>> name.isupper() # Whether the string is pure uppercase
False
>>> name.isspace() # Whether the string is full of spaces
False
>>> name.istitle() # Whether the initial letters of words in the string are all uppercase
False
Four lists
4.1 definition
# Definition: separate multiple values of any data type with commas within [] l1 = [1,'a',[1,2]] # Essence: l1 = list([1,'a',[1,2]])
4.2 type conversion
# Any data type that can be traversed by the for loop can be passed to list() to be converted into list type. list() will traverse every element contained in the data type like the for loop and then put it in the list
>>> list('wdad') # Results: ['w ',' d ',' a ',' d ']
>>> list([1,2,3]) # Results: [1, 2, 3]
>>> list({"name":"jason","age":18}) #Result: ['name ',' age ']
>>> list((1,2,3)) # Results: [1, 2, 3]
>>> list({1,2,3,4}) # Results: [1, 2, 3, 4]
4.3 use
4.3.1 priority operation
# 1. Value by index memory (forward access + reverse access): can be saved or retrieved
# 1.1 forward direction (from left to right)
>>> my_friends=['tony','jason','tom',4,5]
>>> my_friends[0]
tony
# 1.2 reverse access (negative sign means right to left)
>>> my_friends[-1]
5
# 1.3 for list, the value of specified location can be modified according to index or index. However, if index does not exist, an error will be reported
>>> my_friends = ['tony','jack','jason',4,5]
>>> my_friends[1] = 'martthow'
>>> my_friends
['tony', 'martthow', 'jason', 4, 5]
# 2. Slice (look at the head and ignore the tail, step size)
# 2.1 take care of the head and ignore the tail: take out the elements with an index of 0 to 3
>>> my_friends[0:4]
['tony', 'jason', 'tom', 4]
# 2.2 step size: 0:4:2. The third parameter 2 represents step size. It will start from 0 and accumulate one 2 at a time, so the elements of index 0 and 2 will be taken out
>>> my_friends[0:4:2]
['tony', 'tom']
# 3. Length
>>> len(my_friends)
5
# 4. Member operations in and not in
>>> 'tony' in my_friends
True
>>> 'xxx' not in my_friends
True
# 5. Add
# 5.1 append() append elements at the end of the list
>>> l1 = ['a','b','c']
>>> l1.append('d')
>>> l1
['a', 'b', 'c', 'd']
# 5.2 extend() adds multiple elements at the end of the list at one time
>>> l1.extend(['a','b','c'])
>>> l1
['a', 'b', 'c', 'd', 'a', 'b', 'c']
# 5.3 insert() inserts an element at a specified location
>>> l1.insert(0,"first") # 0 indicates interpolation by index position
>>> l1
['first', 'a', 'b', 'c', 'alisa', 'a', 'b', 'c']
# 6. Delete
# 6.1 del
>>> l = [11,22,33,44]
>>> del l[2] # Delete element with index 2
>>> l
[11,22,44]
# 6.2 pop() deletes the last element of the list by default and returns the deleted value. You can specify the deleted element by adding index value in parentheses
>>> l = [11,22,33,22,44]
>>> res=l.pop()
>>> res
44
>>> res=l.pop(1)
>>> res
22
# 6.3 remove() indicates which element to delete with the name in parentheses. There is no return value
>>> l = [11,22,33,22,44]
>>> res=l.remove(22) # Find the element to be deleted in the first bracket from left to right
>>> print(res)
None
# 7.reverse() reverses the order of elements in the list
>>> l = [11,22,33,44]
>>> l.reverse()
>>> l
[44,33,22,11]
# 8.sort() sorts all elements in the list
# 8.1 during sorting, the list elements must be of the same data type and cannot be mixed. Otherwise, an error is reported
>>> l = [11,22,3,42,7,55]
>>> l.sort()
>>> l
[3, 7, 11, 22, 42, 55] # Sort from small to large by default
>>> l = [11,22,3,42,7,55]
>>> l.sort(reverse=True) # reverse is used to specify whether to sort falls. The default value is False
>>> l
[55, 42, 22, 11, 7, 3]
# 8.2 knowledge:
# We can directly compare the size of the commonly used number types, but in fact, strings, lists, etc. can all compare the size. The principle is the same: they compare the size of the corresponding elements in turn. If the size is divided, there is no need to compare the next element, such as
>>> l1=[1,2,3]
>>> l2=[2,]
>>> l2 > l1
True
# The size between characters depends on their order in the ASCII table, and the larger the later
>>> s1='abc'
>>> s2='az'
>>> s2 > s1 # The first character of s1 and s2 does not distinguish the winner, but the second character 'Z' >'b ', so s2 > s1 is valid
True
# So we can also sort the following list
>>> l = ['A','z','adjk','hello','hea']
>>> l.sort()
>>> l
['A', 'adjk', 'hea', 'hello','z']
# 9. Circulation
# Loop traversal my_ Values in friends list
for line in my_friends:
print(line)
'tony'
'jack'
'jason'
4
5
4.3.2 understanding operation
>>> l=[1,2,3,4,5,6] >>> l[0:3:1] [1, 2, 3] # Forward step >>> l[2::-1] [3, 2, 1] # Reverse step # List flipping by index value >>> l[::-1] [6, 5, 4, 3, 2, 1]
Quintuple
5.1 function
A tuple is similar to a list in that it can store multiple elements of any type. The difference is that the elements of a tuple cannot be modified, that is, a tuple is equivalent to an immutable list, which is used to record multiple fixed and immutable values and is only used to retrieve
5.2 definition method
# Comma separated multiple values of any type within ()
>>> countries = ("China","U.S.A","britain") # Essence: countries = tuple("China", "USA", "UK")
# Emphasis: if there is only one value in the tuple, a comma must be added, otherwise () is only the meaning of the tuple, not the definition of the tuple
>>> countries = ("China",) # Nature: countries = tuple("China")
5.3 type conversion
# Any data type that can be traversed by the for loop can be passed to tuple() to be converted into tuple type
>>> tuple('wdad') # Result: ('w ',' d ',' a ',' d ')
>>> tuple([1,2,3]) # Results: (1, 2, 3)
>>> tuple({"name":"jason","age":18}) # Result: ('name ',' age ')
>>> tuple((1,2,3)) # Results: (1, 2, 3)
>>> tuple({1,2,3,4}) # Results: (1,2,3,4)
# tuple() will traverse every element contained in the data type just like for loop and put it into tuple
5.4 use
>>> tuple1 = (1, 'hhaha', 15000.00, 11, 22, 33) # 1. Value by index (forward + reverse): can only be fetched, cannot be modified, otherwise an error will be reported! >>> tuple1[0] 1 >>> tuple1[-2] 22 >>> tuple1[0] = 'hehe' # Error reporting: TypeError: # 2. Slice (head, tail, step) >>> tuple1[0:6:2] (1, 15000.0, 22) # 3. Length >>> len(tuple1) 6 # 4. Member operations in and not in >>> 'hhaha' in tuple1 True >>> 'hhaha' not in tuple1 False # 5. Cycle >>> for line in tuple1: ... print(line) 1 hhaha 15000.0 11 22 33
Six Dictionaries
6.1 definition method
# Definition: separate multiple elements with commas within {}, each of which is key:value Value can be of any type, while key must be immutable. See Section 8 for details. Usually, key should be of str type, because str type has descriptive function for value
info={'name':'tony','age':18,'sex':'male'} #Essence info=dict({....})
# You can define a dictionary like this
info=dict(name='tony',age=18,sex='male') # info={'age': 18, 'sex': 'male', 'name': 'tony'}
6.2 type conversion
# Conversion 1:
>>> info=dict([['name','tony'],('age',18)])
>>> info
{'age': 18, 'name': 'tony'}
# Conversion 2: fromkeys will take each value from the tuple as a key, and then make up with None key:value Put it in the dictionary
>>> {}.fromkeys(('name','age','sex'),None)
{'age': None, 'sex': None, 'name': None}
6.3 use
6.3.1 priority operation
# 1. Access value by key: available for storage
# 1.1 take
>>> dic = {
... 'name': 'xxx',
... 'age': 18,
... 'hobbies': ['play game', 'basketball']
... }
>>> dic['name']
'xxx'
>>> dic['hobbies'][1]
'basketball'
# 1.2 for assignment, if the key does not exist in the dictionary, it will be added key:value
>>> dic['gender'] = 'male'
>>> dic
{'name': 'tony', 'age': 18, 'hobbies': ['play game', 'basketball'],'gender':'male'}
# 1.3 for assignment, if the key originally exists in the dictionary, the value corresponding to the value will be modified
>>> dic['name'] = 'tony'
>>> dic
{'name': 'tony', 'age': 18, 'hobbies': ['play game', 'basketball']}
# 2. Length len
>>> len(dic)
3
# 3. Member operations in and not in
>>> 'name' in dic # Determine whether a value is the key of the dictionary
True
# 4. Delete
>>> dic.pop('name') # Delete the key value pair of the dictionary by specifying the key of the dictionary
>>> dic
{'age': 18, 'hobbies': ['play game', 'basketball']}
# 5. Key keys(), value values(), key value pair items()
>>> dic = {'age': 18, 'hobbies': ['play game', 'basketball'], 'name': 'xxx'}
# Get all the key s in the dictionary
>>> dic.keys()
dict_keys(['name', 'age', 'hobbies'])
# Get all the value s of the dictionary
>>> dic.values()
dict_values(['xxx', 18, ['play game', 'basketball']])
# Get all key value pairs of dictionary
>>> dic.items()
dict_items([('name', 'xxx'), ('age', 18), ('hobbies', ['play game', 'basketball'])])
# 6. Cycle
# 6.1 the default traversal is the key of the dictionary
>>> for key in dic:
... print(key)
...
age
hobbies
name
# 6.2 traverse key only
>>> for key in dic.keys():
... print(key)
...
age
hobbies
name
# 6.3 traversal value only
>>> for key in dic.values():
... print(key)
...
18
['play game', 'basketball']
xxx
# 6.4 traverse key and value
>>> for key in dic.items():
... print(key)
...
('age', 18)
('hobbies', ['play game', 'basketball'])
('name', 'xxx')
6.3.2 operation to be mastered
1. get()
>>> dic= {'k1':'jason','k2':'Tony','k3':'JY'}
>>> dic.get('k1')
'jason' # If the key exists, get the value value corresponding to the key
>>> res=dic.get('xxx') # key does not exist, no error will be reported, but no will be returned by default
>>> print(res)
None
>>> res=dic.get('xxx',666) # When the key does not exist, the default returned value can be set
>>> print(res)
666
# ps: get method is recommended for dictionary value
2. pop()
>>> dic= {'k1':'jason','k2':'Tony','k3':'JY'}
>>> v = dic.pop('k2') # Delete the key value pair corresponding to the specified key and return the value
>>> dic
{'k1': 'jason', 'kk2': 'JY'}
>>> v
'Tony'
3. popitem()
>>> dic= {'k1':'jason','k2':'Tony','k3':'JY'}
>>> item = dic.popitem() # Randomly delete a set of key value pairs and return the deleted key value in the tuple
>>> dic
{'k3': 'JY', 'k2': 'Tony'}
>>> item
('k1', 'jason')
4. update()
# Update the old dictionary with the new one, modify if there is one, and add if there is none
>>> dic= {'k1':'jason','k2':'Tony','k3':'JY'}
>>> dic.update({'k1':'JN','k4':'xxx'})
>>> dic
{'k1': 'JN', 'k3': 'JY', 'k2': 'Tony', 'k4': 'xxx'}
5. fromkeys()
>>> dic = dict.fromkeys(['k1','k2','k3'],[])
>>> dic
{'k1': [], 'k2': [], 'k3': []}
6. setdefault()
# If the key does not exist, add a new key value pair and return the new value
>>> dic={'k1':111,'k2':222}
>>> res=dic.setdefault('k3',333)
>>> res
333
>>> dic # Key value pair added in dictionary
{'k1': 111, 'k3': 333, 'k2': 222}
# If the key exists, no modification will be made, and the value corresponding to the existing key will be returned
>>> dic={'k1':111,'k2':222}
>>> res=dic.setdefault('k1',666)
>>> res
111
>>> dic # Dictionary unchanged
{'k1': 111, 'k2': 222}
Seven sets
7.1 function
Set, list, tuple and dict can store multiple values, but set is mainly used for: de duplication and relational operation
7.2 definitions
"""
Definition: separate multiple elements with commas in {}, and the set has the following three characteristics:
1: Each element must be of immutable type
2: There are no duplicate elements in the collection
3: Disordered elements in set
"""
s = {1,2,3,4} essence s = set({1,2,3,4})
#Note 1: the list type is the index corresponding value, and the dictionary is the key corresponding value. You can get a single specified value. The collection type has neither index nor key corresponding value, so you can't get a single value. Moreover, for the collection, it is mainly used for de duplication and relationship elements, and there is no need to get a single specified value at all.
#Note 2: {} can be used to define both dict and collection, but the elements in the dictionary must be key:value Now we want to define an empty dictionary and an empty set. How to define them exactly?
d = {} ා default is empty dictionary
s = set() ා this is the definition of an empty set
7.3 type conversion
# Any data type that can be traversed by the for loop (emphasis: every value traversed must be immutable) can be passed to set() to convert to set type
>>> s = set([1,2,3,4])
>>> s1 = set((1,2,3,4))
>>> s2 = set({'name':'jason',})
>>> s3 = set('egon')
>>> s,s1,s2,s3
{1, 2, 3, 4} {1, 2, 3, 4} {'name'} {'e', 'o', 'g', 'n'}
7.4 use
7.4.1 relation operation
We define two sets, friends and friends2, to store the names of two people's friends, and then take these two sets as examples to explain the relationship operation of sets
>>> friends1 = {"zero","kevin","jason","egon"} # Friends of user 1
>>> friends2 = {"Jy","ricky","jason","egon"} # Friends of user 2
The relationship between the two sets is shown in the figure below

# 1. Union / Union (|): ask all friends of two users (only one duplicate friend is left) >>> friends1 | friends2 {'kevin', 'ricky', 'zero', 'jason', 'Jy', 'egon'} # 2. Intersection (&): seeking common friends of two users >>> friends1 & friends2 {'jason', 'egon'} # 3. Difference set (-): >>> friends1 - friends2 # Ask for unique friends of user 1 {'kevin', 'zero'} >>> friends2 - friends1 # Seeking unique friends of user 2 {'ricky', 'Jy'} # 4.Symmetric difference set(^) # Ask the unique friends of two users (that is, remove the shared friends) >>> friends1 ^ friends2 {'kevin', 'zero', 'ricky', 'Jy'} # 5. Is the value equal (= =) >>> friends1 == friends2 False # 6. Parent set: whether a set contains another set # 6.1 return True if included >>> {1,2,3} > {1,2} True >>> {1,2,3} >= {1,2} True # 6.2 return False if there is no containment relationship >>> {1,2,3} > {1,3,4,5} False >>> {1,2,3} >= {1,3,4,5} False # 7. Subsets >>> {1,2} < {1,2,3} True >>> {1,2} <= {1,2,3} True
7.4.2 weight removal
There are limitations in set de duplication
#1. Only for immutable types #2. The set itself is out of order. After de duplication, the original order cannot be preserved
An example is as follows
>>> l=['a','b',1,'a','a'] >>> s=set(l) >>> s # Convert list to set {'b', 'a', 1} >>> l_new=list(s) # Then transfer the collection back to the list >>> l_new ['b', 'a', 1] # The repetitions are removed, but the order is disrupted # For immutable types, and to ensure the order, we need to write our own code, for example l=[ {'name':'lili','age':18,'sex':'male'}, {'name':'jack','age':73,'sex':'male'}, {'name':'tom','age':20,'sex':'female'}, {'name':'lili','age':18,'sex':'male'}, {'name':'lili','age':18,'sex':'male'}, ] new_l=[] for dic in l: if dic not in new_l: new_l.append(dic) print(new_l) # Results: it not only eliminates the repetition, but also ensures the order, and it is aimed at the immutable type of de duplication [ {'age': 18, 'sex': 'male', 'name': 'lili'}, {'age': 73, 'sex': 'male', 'name': 'jack'}, {'age': 20, 'sex': 'female', 'name': 'tom'} ]
7.4.3 other operations
# 1. Length >>> s={'a','b','c'} >>> len(s) 3 # 2. Member operation >>> 'c' in s True # 3. Circulation >>> for item in s: ... print(item) ... c a b
7.5 exercise
"""
1, Relational operation
There are two sets as follows: python is the name set of students who sign up for python course, and linux is the name set of students who sign up for linux course
pythons={'jason','egon','kevin','ricky','gangdan','biubiu'}
linuxs={'kermit','tony','gangdan'}
1. Find out the name set of students who enroll in both python and linux courses
2. Find out the name set of all registered students
3. Find out the names of students who only sign up for python course
4. Find out the name set of students who do not have both courses at the same time
"""
#Find out the name set of students who enroll in both python and linux courses
>>> pythons & linuxs
#Find out the names of all the students
>>> pythons | linuxs
#Find out the names of students who only sign up for python courses
>>> pythons - linuxs
#Find out the name set of students who do not have both courses at the same time
>>> pythons ^ linuxs
VIII. Variable type and immutable type
**Variable data type: * when the value changes, the memory address remains unchanged, that is, the id remains unchanged, which proves that changing the original value
**Immutable type: * when the value is changed, the memory address is also changed, that is, the id is also changed. It is proved that the original value is not being changed, and a new value is generated
Number type:
>>> x = 10 >>> id(x) 1830448896 >>> x = 20 >>> id(x) 1830448928 # The memory address has changed, indicating that integer type is immutable data type, and floating-point type is the same
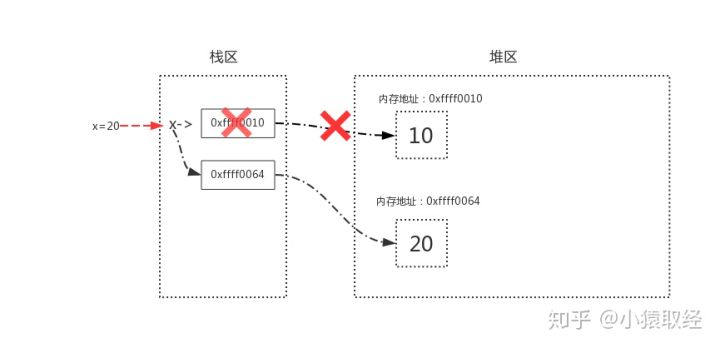
character string
>>> x = "Jy" >>> id(x) 938809263920 >>> x = "Ricky" >>> id(x) 938809264088 # Memory address changed, indicating that string is immutable data type
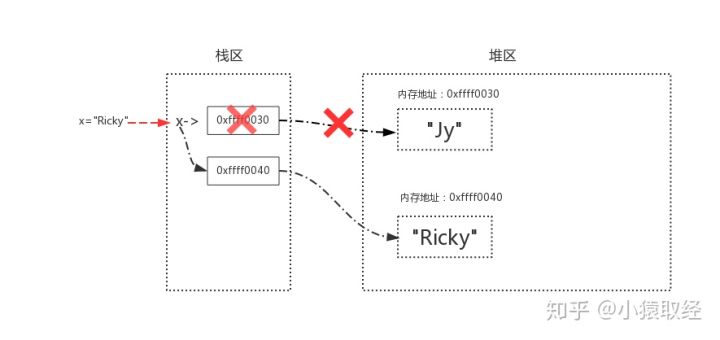
list
>>> list1 = ['tom','jack','egon'] >>> id(list1) 486316639176 >>> list1[2] = 'kevin' >>> id(list1) 486316639176 >>> list1.append('lili') >>> id(list1) 486316639176 # When you operate on the value of a list, the value changes but the memory address does not change, so the list is a variable data type
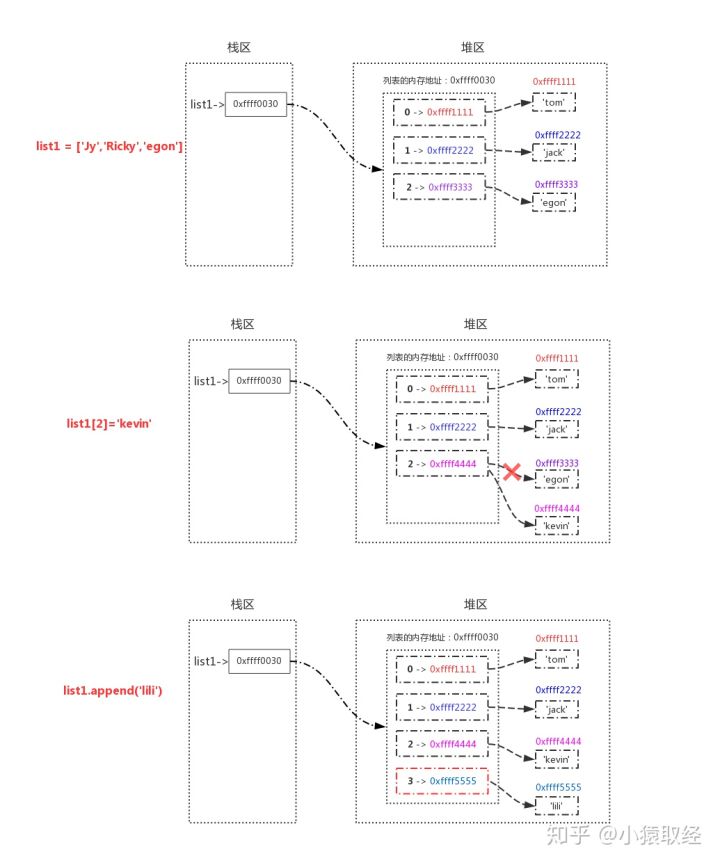
tuple
>>> t1 = ("tom","jack",[1,2]) >>> t1[0]='TOM' # Error reporting: TypeError >>> t1.append('lili') # Error reporting: TypeError # The element in the tuple cannot be modified, which means that the memory address pointed to by the index in the tuple cannot be modified >>> t1 = ("tom","jack",[1,2]) >>> id(t1[0]),id(t1[1]),id(t1[2]) (4327403152, 4327403072, 4327422472) >>> t1[2][0]=111 # If there is a variable type in the tuple, it can be modified, but the modified memory address does not change >>> t1 ('tom', 'jack', [111, 2]) >>> id(t1[0]),id(t1[1]),id(t1[2]) # View id remains unchanged (4327403152, 4327403072, 4327422472)
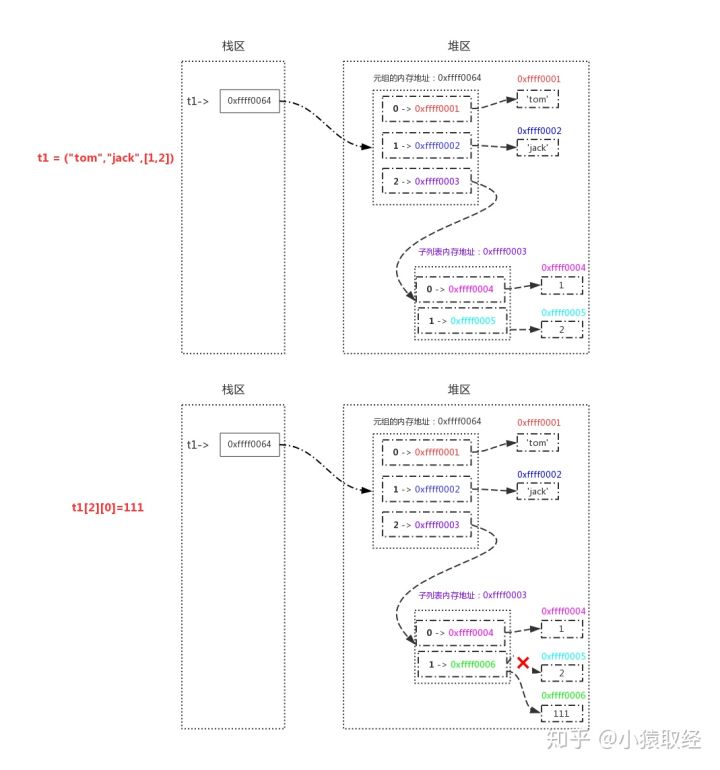
Dictionaries
>>> dic = {'name':'egon','sex':'male','age':18} >>> >>> id(dic) 4327423112 >>> dic['age']=19 >>> dic {'age': 19, 'sex': 'male', 'name': 'egon'} >>> id(dic) 4327423112 # When the dictionary is operated, the id of the dictionary is the same when the value changes, that is, the dictionary is also a variable data type
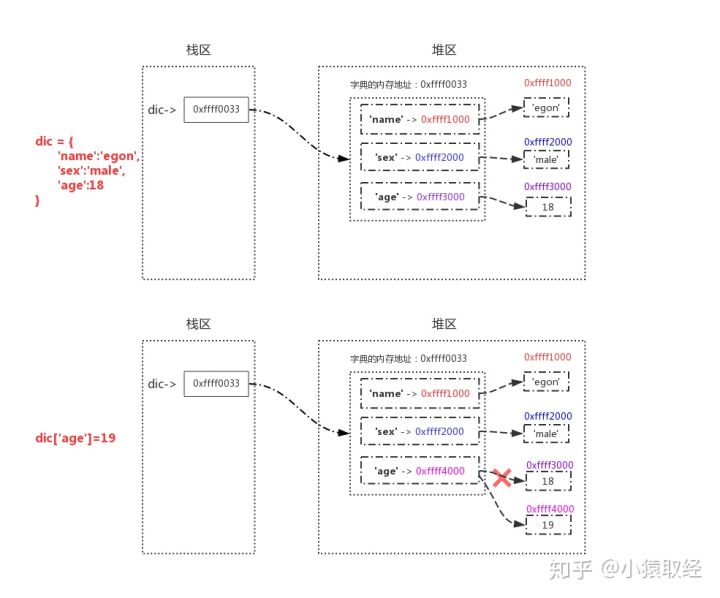
IX. summary of data types
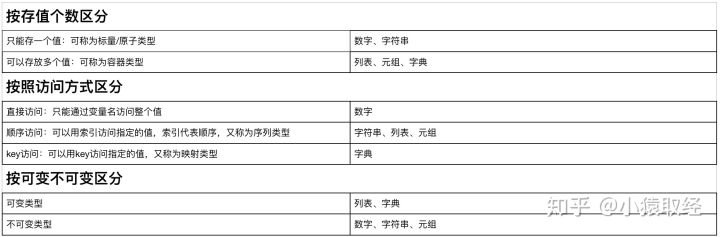
1. Number type: 2. String type 3. List type 4. Tuple type 5. Dictionary type 6. Collection type
','age':73,'sex':'male'},
{'name':'tom','age':20,'sex':'female'},
{'name':'lili','age':18,'sex':'male'},
{'name':'lili','age':18,'sex':'male'},
]
new_l=[]
for dic in l:
if dic not in new_l:
new_l.append(dic)
print(new_l)
Results: it not only eliminates the repetition, but also ensures the order, and it is aimed at the immutable type of de duplication
[
{'age': 18, 'sex': 'male', 'name': 'lili'},
{'age': 73, 'sex': 'male', 'name': 'jack'},
{'age': 20, 'sex': 'female', 'name': 'tom'}
]
### 7.4.3 other operations
```python
# 1. Length
>>> s={'a','b','c'}
>>> len(s)
3
# 2. Member operation
>>> 'c' in s
True
# 3. Circulation
>>> for item in s:
... print(item)
...
c
a
b
7.5 exercise
"""
1, Relational operation
There are two collections as follows: python is the collection of students' names who sign up for python courses, and linux is the collection of students' names who sign up for linux courses
pythons={'jason','egon','kevin','ricky','gangdan','biubiu'}
linuxs={'kermit','tony','gangdan'}
1. Find out the name set of students who enroll in both python and linux courses
2. Find out the name set of all registered students
3. Find out the names of students who only sign up for python course
4. Find out the name set of students who do not have both courses at the same time
"""
#Find out the name set of students who enroll in both python and linux courses
>>> pythons & linuxs
#Find out the names of all the students
>>> pythons | linuxs
#Find out the names of students who only sign up for python courses
>>> pythons - linuxs
#Find out the names of students who do not have both courses at the same time
>>> pythons ^ linuxs
VIII. Variable type and immutable type
**Variable data type: * when the value changes, the memory address remains unchanged, that is, the id remains unchanged, which proves that changing the original value
**Immutable type: * when the value is changed, the memory address is also changed, that is, the id is also changed. It is proved that the original value is not being changed, and a new value is generated
Number type:
>>> x = 10 >>> id(x) 1830448896 >>> x = 20 >>> id(x) 1830448928 # The memory address has changed, indicating that integer type is immutable data type, and floating-point type is the same
[external link picture transfer in storage (img-tFqCXMEe-1591518506013)]
character string
>>> x = "Jy" >>> id(x) 938809263920 >>> x = "Ricky" >>> id(x) 938809264088 # Memory address changed, indicating that string is immutable data type
[external link picture transfer in storage (img-RxG2CT3N-1591518506014)]
list
>>> list1 = ['tom','jack','egon'] >>> id(list1) 486316639176 >>> list1[2] = 'kevin' >>> id(list1) 486316639176 >>> list1.append('lili') >>> id(list1) 486316639176 # When you operate on the value of a list, the value changes but the memory address does not change, so the list is a variable data type
[external link picture transfer in storage (img-09sBZFjD-1591518506015)]
tuple
>>> t1 = ("tom","jack",[1,2]) >>> t1[0]='TOM' # Error reporting: TypeError >>> t1.append('lili') # Error reporting: TypeError # The element in the tuple cannot be modified, which means that the memory address pointed to by the index in the tuple cannot be modified >>> t1 = ("tom","jack",[1,2]) >>> id(t1[0]),id(t1[1]),id(t1[2]) (4327403152, 4327403072, 4327422472) >>> t1[2][0]=111 # If there is a variable type in the tuple, it can be modified, but the modified memory address does not change >>> t1 ('tom', 'jack', [111, 2]) >>> id(t1[0]),id(t1[1]),id(t1[2]) # View id remains unchanged (4327403152, 4327403072, 4327422472)
[external link picture transfer in storage (img-7lZK6ehv-1591518506016)]
Dictionaries
>>> dic = {'name':'egon','sex':'male','age':18} >>> >>> id(dic) 4327423112 >>> dic['age']=19 >>> dic {'age': 19, 'sex': 'male', 'name': 'egon'} >>> id(dic) 4327423112 # When the dictionary is operated, the id of the dictionary is the same when the value changes, that is, the dictionary is also a variable data type
[external link picture transfer in storage (img-zHZ9Kj43-1591518506017)]
IX. summary of data types
[external link picture transfer in storage (img-WvuuT9Ax-1591518506018)]
1. Number type: 2. String type 3. List type 4. Tuple type 5. Dictionary type 6. Collection type