python has its own urllib and third-party library requests for requesting http interfaces, but the urllib writing method is a little cumbersome. Therefore, in the process of interface automatic testing, a more concise and powerful requests library is generally used. Next, we use the requests library to send get requests.
1, requests Library
brief introduction
The requests library provides matching methods for common HTTP requests, corresponding to the following:
requests.get() # For GET requests requests.post() # For POST requests requests.put() # For PUT requests requests.delete() # For DELETE requests
Of course, there are more methods. Here are only the commonly used ones.
install
Installation command: pip install requests
2, Send get request
get request parameter format description
The source code of get method in requests is as follows:
def get(url, params=None, **kwargs):
r"""Sends a GET request.
:param url: URL for the new :class:`Request` object.
:param params: (optional) Dictionary, list of tuples or bytes to send
in the query string for the :class:`Request`.
:param \*\*kwargs: Optional arguments that ``request`` takes.
:return: :class:`Response <Response>` object
:rtype: requests.Response
"""
kwargs.setdefault('allow_redirects', True)
return request('get', url, params=params, **kwargs)
Parameter Description:
- url, i.e. interface address
- params, interface parameter, optional (optional)
- **kwargs, you can add other request parameters, such as setting request header headers, timeout, cookies, etc
Request without parameters
import requests res = requests.get(url="https://www.cnblogs.com/lfr0123/") # The requested Response is a Response object. If you want to see the returned text content, you need to use text print(res.text)
Request with parameters
import requests
url = "http://www.baidu.com/s"
params = {"wd": "Here's a blank page for you-Blog Garden", "ie": "utf-8"}
res = requests.get(url=url, params=params)
print(res.text)
Join request header
Some interfaces are restricted to be accessed only by the browser. In this case, the request according to the above code will be prohibited. We can add the header parameter to the code to disguise the browser to make the interface request. An example is as follows:
import requests
url = "http://www.baidu.com/s"
params = {"wd": "Here's a blank page for you-Blog Garden", "ie": "utf-8"}
# The value of user agent is browser type
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36"
}
res = requests.get(url=url, params=params, headers=headers)
print(res.text)
Some results are as follows:
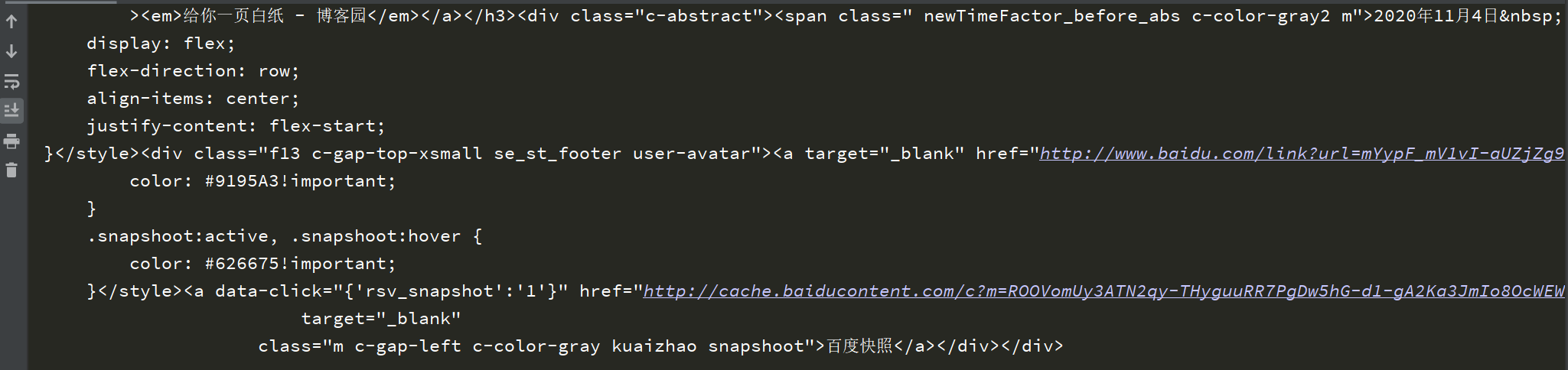
In fact, the response body here is to search in Baidu and give you a page of white paper - the result page of blog park.
In addition, you can also add timeout, cookies, etc., written as follows:
# Timeout only limits the timeout of the request. The unit is s. if it times out, an error will be reported res = requests.get(url=url, params=params, headers=headers, timeout=20, cookies=cookies)
Response content
After sending the request, the content of the interface response will be obtained, such as res.text in the above example. Other response contents are obtained as follows:
res.status_code # Response status code res.headers # Response header res.encoding # Response body coding format res.text # Response body, text information in string form res.content # The response body, text information in binary form, will be automatically decoded res.cookies # Response cookie res.json() # If the format of the response body is json, it needs to be decoded through json()
It should be noted here that the use of res.text and res.content and the specific method to obtain the content of the response body need to be selected according to the coding method. The stupidest way is to try another one instead of the other.
Examples are as follows:
import requests
url = "http://www.baidu.com/s"
params = {"wd": "Here's a blank page for you-Blog Garden", "ie": "utf-8"}
# The value of user agent is browser type
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36"
}
res = requests.get(url=url, params=params, headers=headers)
print(res.text)
print(res.status_code)
print(res.headers)
print(res.encoding)
print(res.cookies)
The results are as follows:
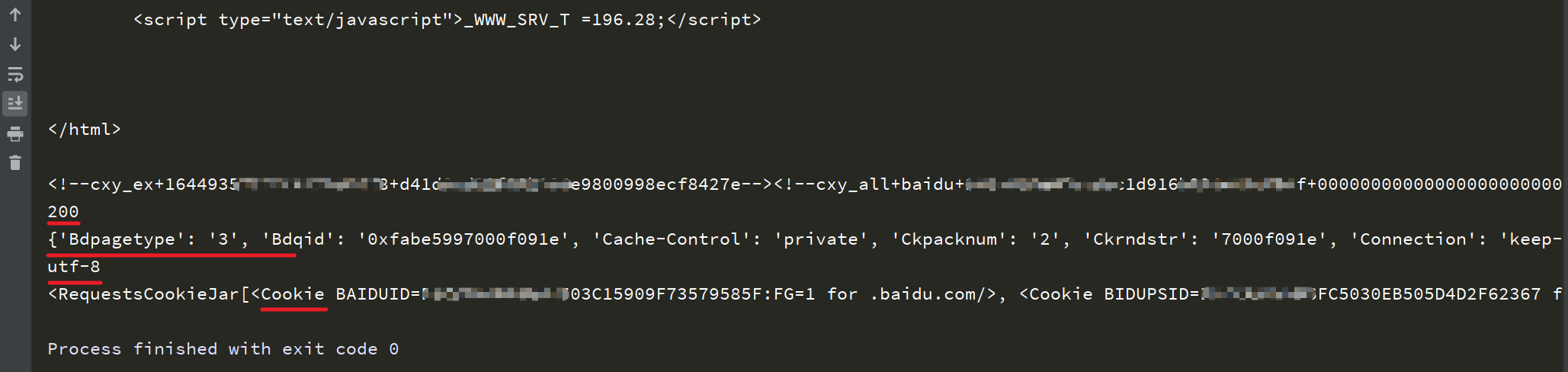
The result corresponds to the response content of print in the code from top to bottom.