1, Problem background
It's too slow to run with pywin32. I usually use docx library to process Word tables.
Note that the installation name of docx library is Python docx instead of docx. The installation method of pip is as follows:
pip install python-docx
1.1 conventional writing
The table is generally read in this way:
def ReadDocx(file):
doc = docx.Document(file)
data = []
for table in doc.tables:
data.append([])
for row in table.rows:
data[-1].append([])
for cell in row.cells:
data[-1][-1].append(cell.text)
return data
1.2 strange problems
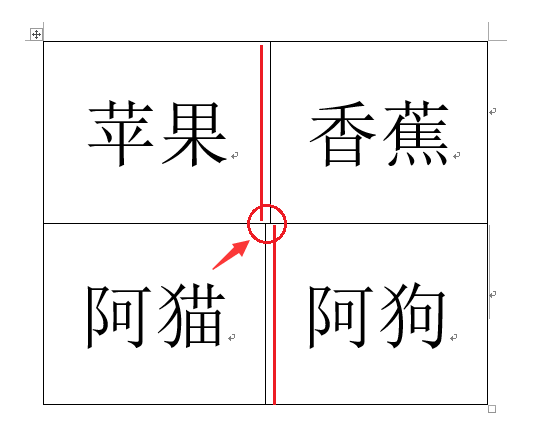
Sometimes, the table read is outrageous. For example, when the table is like this:

The read result is:
>>> data [[['Apple', 'Banana', 'Banana'], ['people of little importance', 'people of little importance', 'dog']]]
Where is the problem? The table read by docx library considers that there are merged cells in it, and regards it as 2 × Table 3.
If it is Excel, you can also get the information of merged cells while reading the table, but this method is not supported in the docx library.
In the docx library, read the text in the merged cells and get all the same content.
However, it is obviously inappropriate to judge whether to merge cells through the text of cells. Because the text can be "the same" in different cells, such judgment is not "rigorous".
2, Find clues
2.1 bright future
But in the desperate situation, I found a clue. In the merged cell, get the contents of the first row:
row = table.rows[0].cells
Judge whether the two merged cells in the table point to the same address, and the return result is True:
>>> row[0] is row[1] True
This can solve the judgment of merging cells in the same row. Similarly, use table columns[c]. Cells, you can also judge the merging of vertical cells.
2.2 road twists and turns
However, if there are cells, there are both horizontal consolidation and vertical consolidation. For example, row1 is the first row and row2 is the second row:
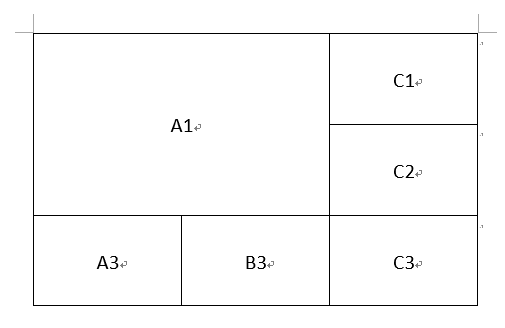
Calculate row1[0] is row2[1], but cannot get the result of True.
Similarly, if you use table Access by cell (R, c):
>>> table.cell(0, 0) is table.cell(1, 1) False
Nor can we get the expected results.
3, Follow the vine and touch the melon
So why?
View the information of row, and the output result is:
>>> row <docx.table._Row object at 0x00000000039FDF98>
3.1 find source code
Found docx Table Library_ Row class, find the corresponding source code:
class _Row(Parented):
...
@property
def cells(self):
return tuple(self.table.row_cells(self._index))
A row is called here_ Cells method, continue tracking. This method appears in docx In the Table class of Table:
class Table(Parented):
...
def row_cells(self, row_idx):
column_count = self._column_count
start = row_idx * column_count
end = start + column_count
return self._cells[start:end]
Returned a self_ Cells value and slice the array. That is, the cells address values in the first row and the cells address values in the second row cannot be mutually confirmed.

Continue to find_ The location defined by the cells value is still the return value of a @ property protected method in the Table class:
class Table(Parented):
...
@property
def _cells(self):
col_count = self._column_count
cells = []
for tc in self._tbl.iter_tcs():
for grid_span_idx in range(tc.grid_span):
if tc.vMerge == ST_Merge.CONTINUE:
cells.append(cells[-col_count])
elif grid_span_idx > 0:
cells.append(cells[-1])
else:
cells.append(_Cell(tc, self))
return cells
3.1 cause analysis
As shown in the figure, it is easy to understand why the cells in the merged cells are considered to be the same address value.
When the condition TC is satisfied vMerge == ST_ Merge. Continue and grid_ span_ When IDX > 0, the cells of the final result array are directly added with an element already contained in the original array. This leads to the return value of True when judging c1 is c2.
Read the source code and understand it better. The cells in the table are arranged from top to bottom and from left to right. When TC vMerge == ST_ Merge. During continue, the cell repeats vertically, grid_ span_ When IDX > 0, the cell repeats horizontally.
In the merged cell, all references are from the first "cell" of the merged area. Then, you can judge whether the two cells belong to the same area through c1 is c2.
3.3 obtaining the required
Accessing the variable protected by @ property actually runs the function once, so it is more efficient to assign the return value to the temporary variable and then perform subsequent operations, and the code is readable.
Get a list of all cells, table width, and number of cells:
doc = docx.Document(file)
for table in doc.tables:
cells = table._cells
cols = table._column_count
length = len(cells)
...
4, Crack method
4.1 find the "merge" cell
In the returned array cells, the first duplicate cell is the cell in the upper left corner of the merged cell range; The last duplicate cell is the cell in the lower right corner.
Reference code:
for i, cell in enumerate(cells):
if cell in cells[:i]: # Skip if the cell does not appear for the first time in the table
continue
for j in range(length - 1, 0, -1): # Reverse search
if cell is cells[j]: # Find the "same" cell. If there is no "merge" cell, you will find "yourself" in reverse order
break
if i != j: # If the index values of positive and reverse lookup are different, it indicates that the cells are merged
...
In this way, you can determine the first "grid" and the last "grid" of the "merged" cell.
4.2 converting row column information
If the number of rows is also known, it is easy to get the "merge" range of merged cells:
if i != j:
r1, c1 = divmod(i, cols) # The "start" position of the merged cell range is also the row and column coordinates of the upper left cell
r2, c2 = divmod(j, cols) # The "end" position of the merged cell range is also the row and column information of the lower right cell
merge = r1, r2, c1, c2 # Convert to xlrd style cells and merge row and column information
Finally, according to the style of xlrd library, I organize the information of merged cells into the order in xlrd library.
4.3 user defined rule consolidation
With the information of merging cells, merging cells is very simple.
As required, vertical repetition, horizontal repetition, horizontal repetition area tightening or combination can be realized:
def MergeCell(data, merge, merge_x=True, merge_y=True, strip_x=False):
data2 = []
for sheet_data, sheet_merge in zip(data, merge):
# merge cell
for r1, r2, c1, c2 in sheet_merge:
for r in range(r1, r2 + 1):
for c in range(c1, c2 + 1):
if (not merge_x and c > c1) or (not merge_y and r > r1):
sheet_data[r][c] = None if strip_x else ''
else:
sheet_data[r][c] = sheet_data[r1][c1]
# strip x
if strip_x:
sheet_data = [[cell for cell in row if cell is not None] for row in sheet_data]
data2.append(sheet_data)
return data2
Attach and read merged cells in xls file
In addition, I mentioned the xlrd library for reading Excel many times. This library runs much faster than pywin32. I also share my common reading and cleaning methods:
def ReadExcel(file):
# only ".xls" type contain merge_info
xls = xlrd.open_workbook(file, formatting_info=True)
data = []
for sheet in xls.sheets():
sheet_name = sheet.name
sheet_data = []
for row in range(sheet.nrows):
rows = sheet.row_values(row)
for c, cell in enumerate(rows):
if isinstance(cell, float):
if cell.is_integer():
rows[c] = str(int(cell))
else:
rows[c] = str(cell)
sheet_data.append(rows)
data.append(sheet_data)
merge = [sheet.merged_cells for sheet in xls.sheets()]
return data, merge
However, it should be noted that the xlrd library only reads Excel files in xls format to have the information of merging cells. If the table in xlsx format also needs to read the information of merged cells, you can convert the file to xls format before reading.