Python regular
Python regular expressions should be used in conjunction with the re module.
So after reading my article General regularity After the article, let's first touch on how regular expressions are used in Python.
We also take the three learning materials in general rules as the learning materials of this article! Practice and learn.
① Match (regular expression, string to be matched, other restrictions on matching) silly match method
The match() method is that only one match can be made from the starting position. If it doesn't match, it's over. Will definitely return you a None
give an example:
For example, if we want to match ABC through accurate search, then if you use match, it must start from a at the starting position. Then you can't match ABC all your life.
So I also call it a silly method...
However, it is still very common in some application scenarios. For example, the data you want to get is matched just from the starting position. Then this method is just right. You don't need to edit regular expressions too complicated. Maybe it matches.
import re
String to match = open('1.txt','r').read()
print(String to match)
print(re.match('ABC', String to match)) # Match at start
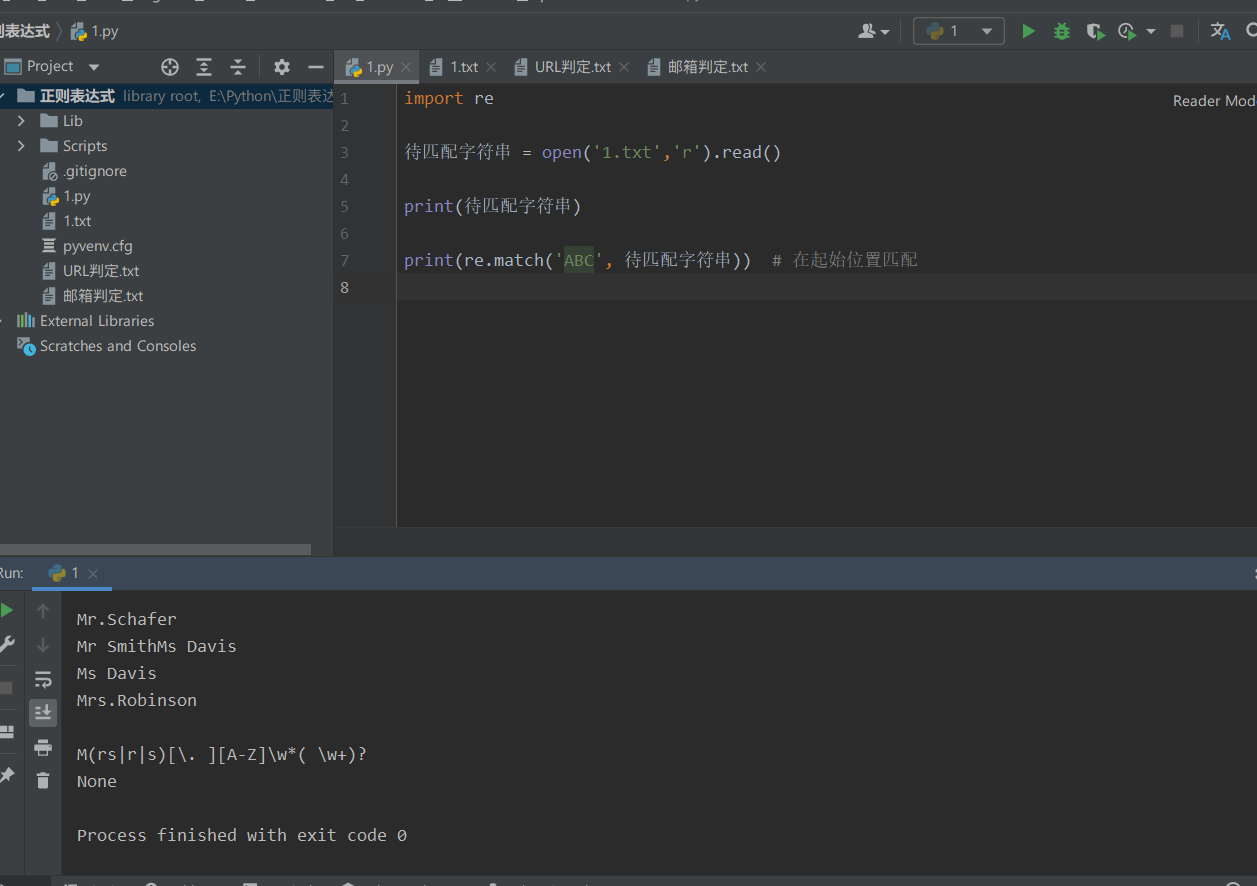
Originally, there is ABC in this string, but it just can't get it.. Because it matches from the starting position.
② Serach (regular expression, string to be matched, other restrictions on matching) is our most commonly used matching method, because our regular expression is to scan all strings.
The only drawback is that only the first matching string can be captured
import re
String to match = open('1.txt','r').read()
# Print (string to match)
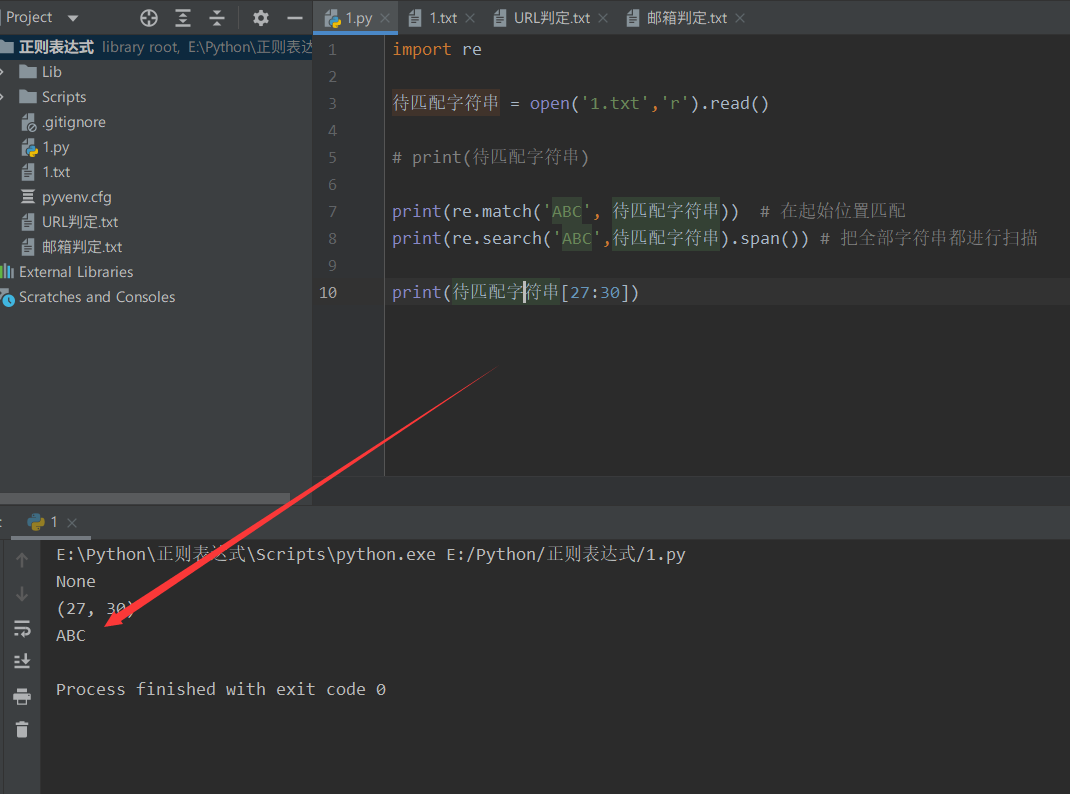
print(re.match('ABC', String to match)) # Match at start
print(re.search('ABC',String to match).span()) # Scan all strings
print(String to match[27:30])
③ searchObj.group() and searchobj Groups () the items we match can be obtained one by one through group.
This so-called matching item is a little particular.
According to pyrhon's re, anything in a regular expression: () enclosed in parentheses is a matching item.
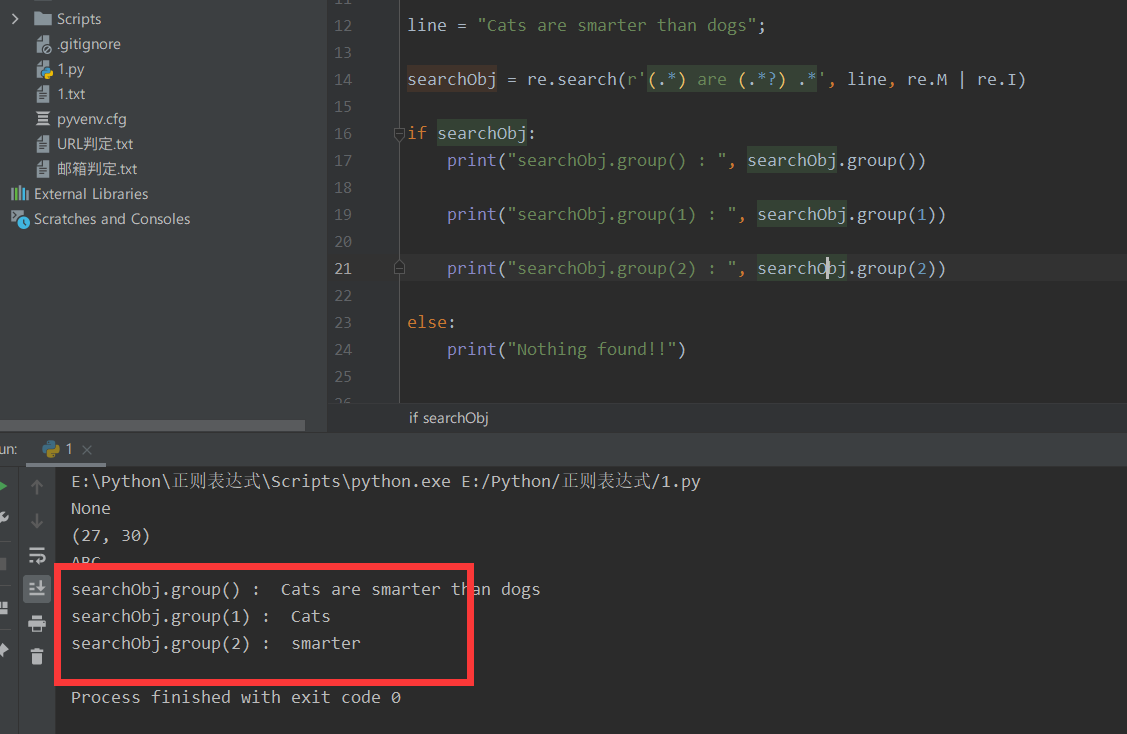
line = "Cats are smarter than dogs";
searchObj = re.search(r'(.*) are (.*?) .*', line, re.M | re.I)
if searchObj:
print("searchObj.group() : ", searchObj.group())
print("searchObj.group(1) : ", searchObj.group(1))
print("searchObj.group(2) : ", searchObj.group(2))
else:
print("Nothing found!!")
We can see that (. *) matches any character from 0 to infinite, which has been enclosed in parentheses! So this is also a matching item.
④ (? P < groupkey > regular expression) it means that we specify a Key to match the keywords of the items that can be matched. Then you can get this item directly through group(Key).
The purpose of this is to facilitate us to find the items we need. Instead of using numbers without real meaning such as 1, 2 and 3 as keywords.
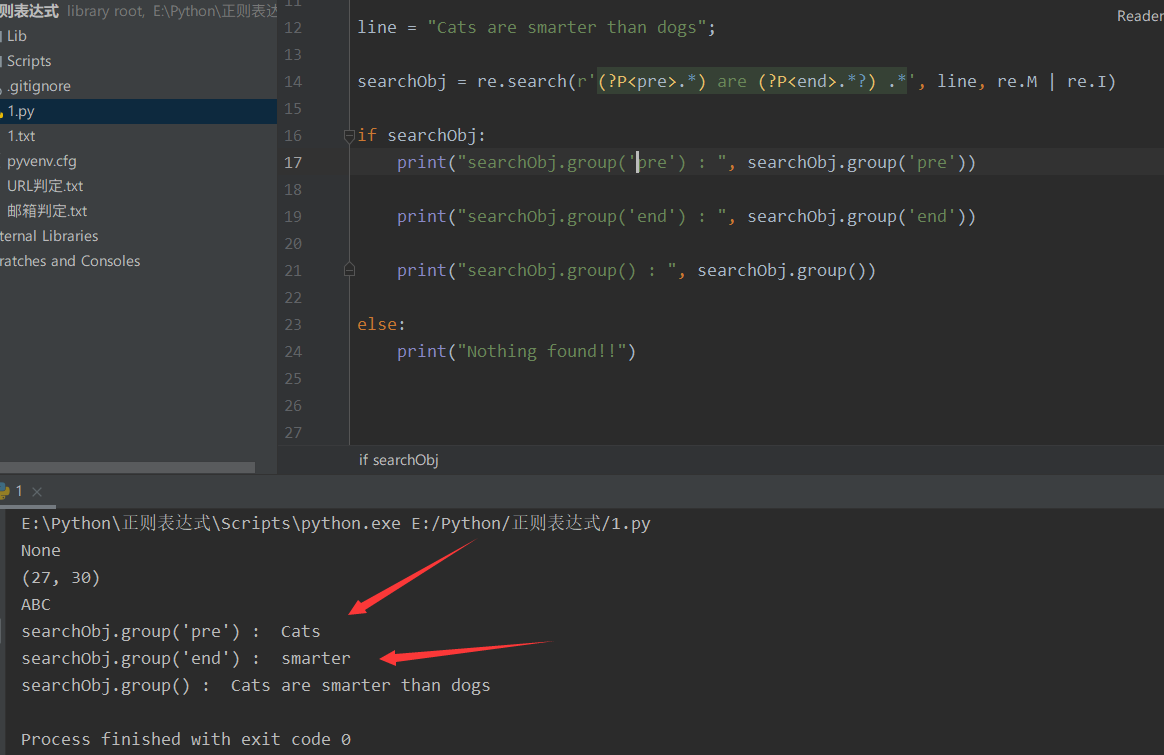
line = "Cats are smarter than dogs";
searchObj = re.search(r'(?P<pre>.*) are (?P<end>.*?) .*', line, re.M | re.I)
if searchObj:
print("searchObj.group('pre') : ", searchObj.group('pre'))
print("searchObj.group('end') : ", searchObj.group('end'))
print("searchObj.group() : ", searchObj.group())
else:
print("Nothing found!!")
⑤ re.sub('regular expression ',' replaced string ', string to be matched, count = matching times) the matching string will be replaced with the replaced string you provide. If count is empty, it will scan all matching strings from beginning to end, and then replace them one by one.
The string to be matched can also be written as a function, and the parameter is an iterator that automatically provides you with a matching result. It works group() to get the value of the match
# Multiply the matching number by 2
def double(matched):
value = int(matched.group('value'))
return str(value * 2)
s = 'A23G4HFD567'
searchObj = re.search('(\d+)',s)
findallObj = re.findall('(\d+)',s)
print(findallObj)
print(re.sub('(?P<value>\d+)', double, s))
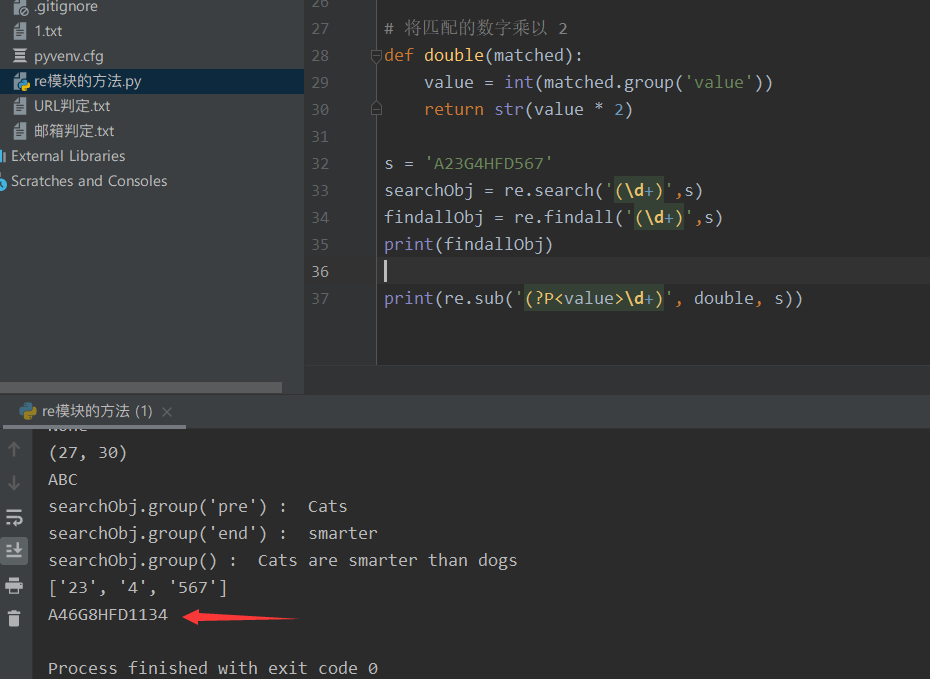
⑥ findall('regular expression ', string to be matched, some other restrictions) can match all strings that match the regular expression. Not just one. We use this most! Because our crawlers often use regular rules to get rough data. After taking it down, we all use the string method for secondary processing. This is the most efficient, convenient and easy.
print(re.findall('\d+', s))
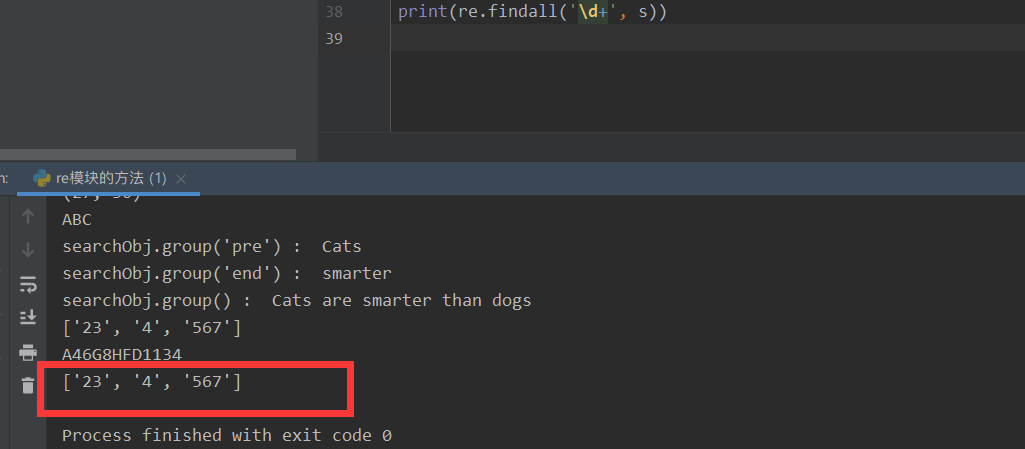
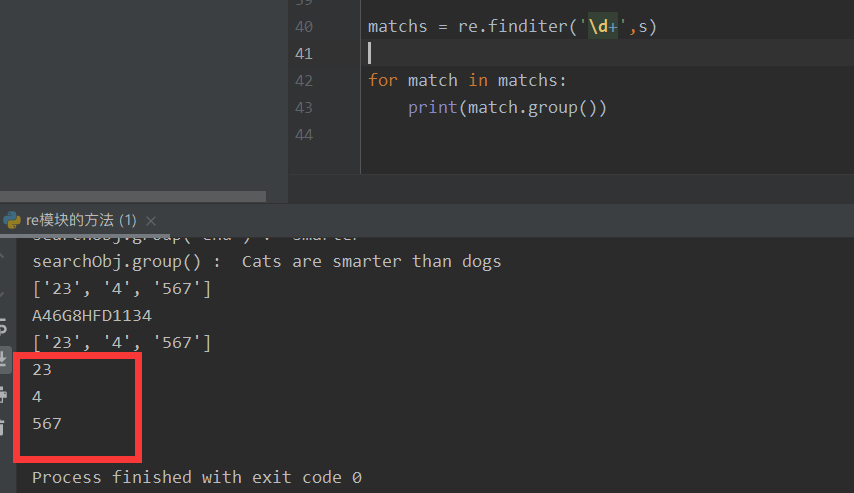
⑦ The finder ('regular expression ', string to be matched, and some other restrictions) can also match all regular strings, but it returns an iterator. In other words, we have to go through a for loop, and then we have to go through group() to get the value of the matching item.
matchs = re.finditer('\d+',s)
for match in matchs:
print(match.group())
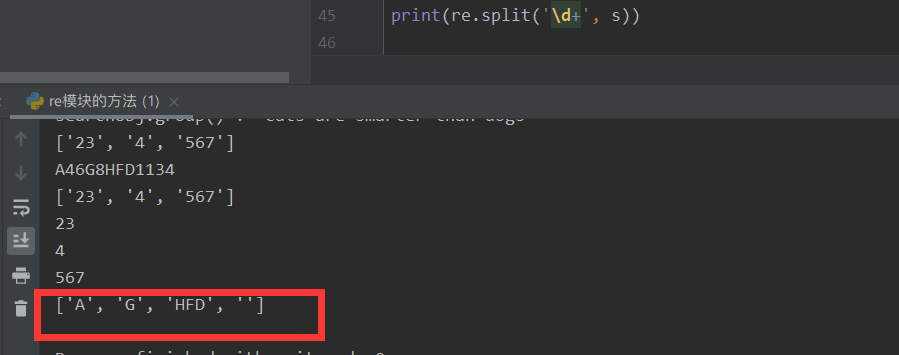
⑧ split('regular expression ',' string to be matched ', some other restrictions) is to use the matched string as a separator, then split the string, and finally return a list. This is very practical in some special scenes! We also call this regular split as the advanced segmentation of strings! Of course, the string split also seems to support regular expressions, ha ha ~~
print(re.split('\d+', s)) # For example, it is easy to use these numbers in the middle as separators.
⑨ re. Compile (regular expression) is very important. If we want to use the regular matching function of re module normally. You must first use this method to compile regular expressions and generate a regular expression (Pattern) object.
We can implement many regular methods through the Pattern object, and these methods may be more direct than you XXX has some more functions.
For example, our match() matches from the beginning. However, the match() method of the Pattern object compiled by our compile() method can limit the start and end positions. That is, the matching range of the scan.
pattern = re.compile('ABC')
print(pattern.match(String to match, 27, 30).span())
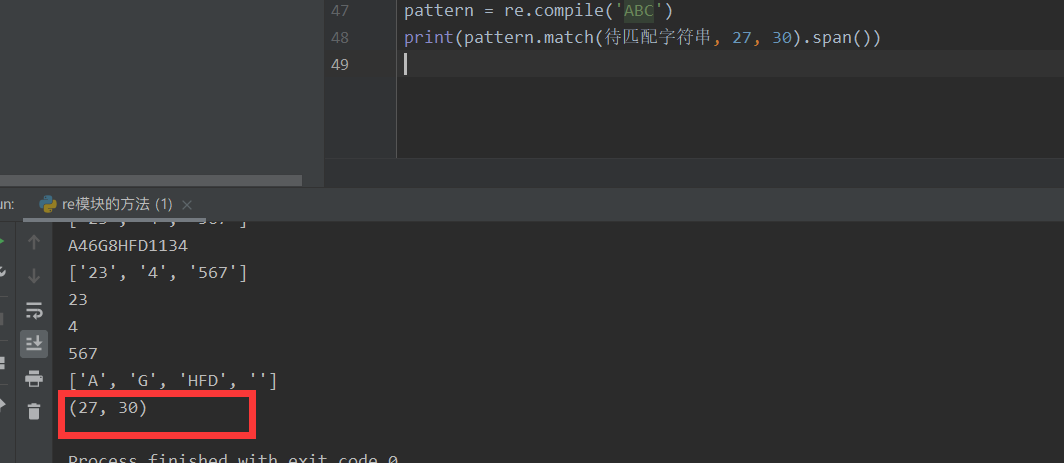
So we can match! That's strong.
PS: how useful is this? When I first learned reptiles, sometimes some elements were too similar. So a positioning is needed. If it can be located, then matching in that range can only match the data I want to match. It saves a lot of trouble.