Regular expression is a very general set of rules, and this paper is based on the implementation of python re model to explain the syntax of regular expression. The common regular expressions are as follows:
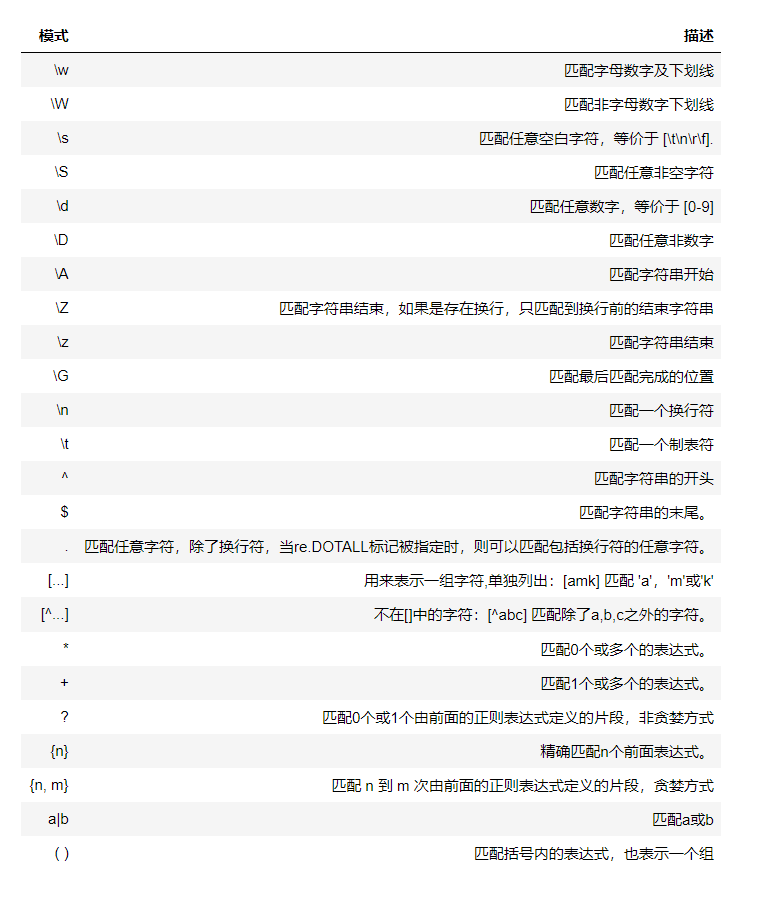
Let's talk about the common methods of re module in python.
1. re.match() (in fact, it is better to use re.search(), which can completely replace re.match())
The re.match() method attempts to match a model from the first starting position. If it is not successful, it returns none
1.1 general matching
content = 'Hello 123 4567 World_This is a Regex Demo' result = re.match('^Hello\s\d\d\d\s\d{4}\s\w{10}.*Demo$', content) print(result) print(result.group()) #group() method returns a string
1.2 universal matching
content = 'Hello 123 4567 World_This is a Regex Demo' result = re.match('^Hello.*Demo$$', content) print(result.group())
1.3 matching objectives
content = 'Hello 123 4567 World_This is a Regex Demo' result = re.match('.*(\d{3}\s\d{4}).*', content) #Parentheses () indicate the target to return print(result.group(1))
1.4 greedy matching, matching as many characters as possible
content = 'Hello 1234567 World_This is a Regex Demo' result = re.match('^He.*(\d+).*$', content) print(result.group(1))
1.5. Non greedy matching. Match as few characters as possible. For example, if you see the rule of matching numbers after it, stop the previous matching
content = 'Hello 1234567 World_This is a Regex Demo' result = re.match('^He.*?(\d+).*$', content) print(result.group(1))
1.6 matching mode
content = '''Hello 1234567 World_This is a Regex Demo ''' #If not used re.S Parameter, only match within each line. If one line does not have one, change to the next line#New start, not across lines. While using re.S After the parameter, the regular expression takes this string as an integer#Body, add "\ n" as a normal character to this string, and match in the whole. result = re.match('^He.*?(\d+).*?Demo$', content, re.S) print(result.group(1)) ''' ####1.7. Escape ```python #Try to use universal matching, use parentheses to get matching target, try to use non greedy model, and have line break is re.S content = 'price is $5.00' result = re.match('price is \$5\.00', content) print(result)
2,re.search()
re.search() scans the entire string and returns the first successful match. search can be used without match.
#Try to use universal matching, use parentheses to get matching target, try to use non greedy model, and have line break is re.S content = 'Hello 1234567 World_This is a Regex Demo' result = re.match('Hello.*?(\d+).*', content) print(result.group(1)) html = '''<div id="songs-list"> <h2 class="title">Classic old songs</h2> <p class="introduction"> //List of classic songs </p> <ul id="list" class="list-group"> <li data-view="2">Simon Birch</li> <li data-view="7"> <a href="/2.mp3" singer="Richie Ren">A smile from the sea</a> </li> <li data-view="4" class="active"> <a href="/3.mp3" singer="Chyi Chin">Past wind</a> </li> <li data-view="6"><a href="/4.mp3" singer="beyond">Glorious years</a></li> <li data-view="5"><a href="/5.mp3" singer="Kelly Chan">Notepad</a></li> <li data-view="5"> <a href="/6.mp3" singer="Teresa Teng"><i class="fa fa-user"></i>May we all be blessed with longevity</a> </li> </ul> </div>''' result = re.search('<li.*?singer="(.*?)">(.*?)</a>', html, re.S) if result: print(result.group(1), result.group(2))
3,re.findall()
re.findall() returns all matching substrings in the form of a list
results = re.findall('<a.*?href="(.*?)".*?singer="(.*?)">(.*?)</a>', html, re.S) print(results)
4,re.sub()
re.sub() replaces each matching substring in the string and returns the replaced string
content = 'Hello 1234567 World_This is a Regex Demo' content = re.sub('\d+', 'replacement', content) print(content)
5,re.compile()
re.compile() compiles regular strings into regular expression objects to facilitate reuse of the matching pattern
content = 'Hello 1234567 World_This is a Regex Demo' pattern = re.compile('Hello.*Demo') result = re.match(pattern, content) print(result) #Here is an example of taking the whole text as a paragraph content = '''<div id="songs-list"> <h2 class="title">Classic old songs</h2> <p class="introduction"> //List of classic songs </p> <ul id="list" class="list-group"> <li data-view="2">Simon Birch</li> <li data-view="7"> <a href="/2.mp3" singer="Richie Ren">A smile from the sea</a> </li> <li data-view="4" class="active"> <a href="/3.mp3" singer="Chyi Chin">Past wind</a> </li> <li data-view="6"><a href="/4.mp3" singer="beyond">Glorious years</a></li> <li data-view="5"><a href="/5.mp3" singer="Kelly Chan">Notepad</a></li> <li data-view="5"> <a href="/6.mp3" singer="Teresa Teng"><i class="fa fa-user"></i>May we all be blessed with longevity</a> </li> </ul> </div>''' result = re.search('<ul.*?</ul>', content, re.S) print(result.group())
6. Practice
import requests import re content = requests.get('https://book.douban.com/').text #Why to cut out some of them first, because if the whole pattern matching is too slow.. content = re.search('<ul class="list-col list-col5 list-express slide-item">.*?</ul>', content, re.S).group() pattern = re.compile('<li.*?cover.*?href="(.*?)".*?title="(.*?)".*?more-meta.*?author">(.*?)</span>.*?year">(.*?)</span>.*?</li>', re.S) results = re.findall(pattern, content) for result in results: url, name, author, date = result author = re.sub('\s', '', author) date = re.sub('\s', '', date) print(url, name, author, date)
The results are as follows:
