Special meaning of punctuation
| Special characters | Value |
|---|---|
| . | (DOT) in the default mode, matches any character except line feed. If the label DOTALL is specified, it will match any character including a newline character. |
| ^ | (CARET) matches the beginning of the string, and also matches the first symbol after line feed in multi line mode. |
| $ | Matching the end of the string or the character before the newline character at the end of the string will also match the text before the newline character in multi line mode. |
| 1. | Match the regular formula in front of it for 0 to any number of repetitions, and try to match as many strings as possible. |
| + | Match the regular expression in front of it for 1 to any repetition. |
| ? | Match the regular expression in front of it for 0 to 1 repetitions. |
| *?, +?, ?? | '*', '+', and '?' Modifiers are greedy; They match as many strings as possible. |
| {m} | Specify m repetitions to match the previous regular formula; Less than m will lead to matching failure. |
| {m,n} | Match the regular Formula m to N times, and take as many as possible between m and n. |
| {m,n}? | The non greedy pattern of the previous modifier matches only as few characters as possible. |
| \ | Escaping Special Characters |
| [] | Used to represent a set of characters. |
| | | A|B, once a matches successfully, B will no longer match |
| (...) | (combination), match any regular expression in parentheses, and identify the beginning and end of the combination. |
| (?...) | This is an extended notation (a '?' followed by '(' has no meaning). '?' The following first character determines what syntax this build uses. |
| (?aiLmsux) | (one or more of 'a', 'i', 'L','m ','s',' u ',' x ') this combination matches an empty string; |
| (?:...) | Non captured version of regular parentheses. Matches any regular expression in parentheses, but the substring matched by the grouping cannot be obtained after matching or referenced in the pattern. |
| (?aiLmsux-imsx:...) | (0 or more of 'a', 'i', 'L','m ','s',' u ',' x ', followed by' - 'followed by one or more of' i ','m','s', X.) These characters set or remove the corresponding tags for part of the expression |
| (?P...) | (named combination) |
| (?P=name) | Back reference a named combination; It matches the same string found in the previous named group called name. |
| (?#...) | notes; The contents will be ignored. |
| (?=...) | Match the content of... But do not consume the content of style. For example, Isaac (?=Asimov) matches' Isaac 'only when it is followed by' Asimov '. |
| (?!...) | Match... A situation that does not match. |
| (?<=...) | Matches the current position of the string, and its front matches the contents of... To the current position. |
| (?<!...) | Match a style that was not before the current location. |
| (?(id/name)yes-pattern|no-pattern) | If the given id or name exists, it will try to match yes pattern, otherwise it will try to match no pattern. No pattern is optional or can be ignored. |
practice
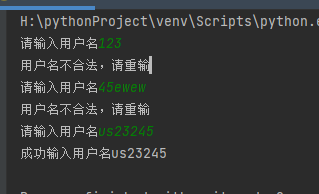
- User name matching: it is composed of numbers, letters, underscores and horizontal lines. It is 4 to 14 digits long and cannot start with a number.
import re
while True:
user_name = input('enter one user name')
x = re.compile(r'^[a-zA-Z_-][\w-]{3,13}$')
if x.match(user_name):
print('User name entered successfully{}'.format(user_name))
break
else:
print('The user name is illegal, please re-enter')
- Matching mailbox
r'^[\w.-]+@[\w.-]\.[a-zA-z]{2,4}$' - Match mobile number
r'^1\d{10}$'
Regular substitution
a = 'ad234ds3dsf2'
print(re.sub(r'\d+', '0', a)) # Replace the number with 0
# Double the number by function replacement
def Doub(x):
data = x.group()
return str(int(data) * 2)
print(re.sub(r'\d+', Doub, a))
# Or use lambda expressions
print(re.sub(r'\d+', lambda x: str(int(x.group()) * 2), a))
Greedy model
a = 'ad234acv234dsf2345' result = re.match(r'ad(.+)(\d+)', a) print(result.group(1)) result1 = re.match(r'ad(.+)(.+)', a) print(result1.group(1)) result2 = re.match(r'ad(\d+)(.+)', a) print(result2.group(1))
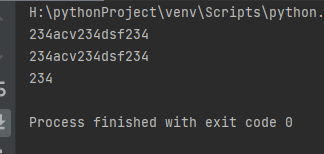
python regular expressions default greedy pattern (as many matches as possible)
Non greedy model
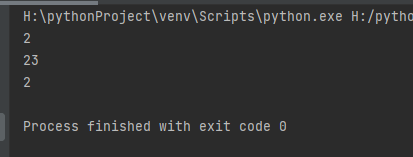
a = 'ad234acv234dsf2345'
result = re.match(r'ad(.+?)(\d+)', a)
print(result.group(1))
result1 = re.match(r'ad(.{2,5}?)(.+)', a)
print(result1.group(1))
result2 = re.match(r'ad(\d+?)(.+)', a)
print(result2.group(1))
task
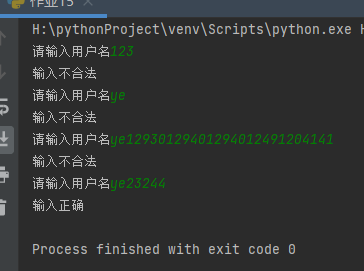
- User name matching, requirements:
- The user name can only contain numbers, letters, underscores
- Cannot start with a number
- The length is in the range of 6 to 16 bits
import re
def user_name():
while True:
name = input('enter one user name')
if re.match(r'^[a-zA-z_]\w{5,15}$', name):
print('Correct input')
break
else:
print('Illegal input')
user_name()
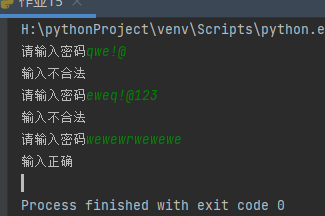
- Password matching, requirements:
- Cannot contain@# ¥% ^ & * these special symbols
- Must start with a letter
- The length is 6 to 12 bits
import re
def pass_word():
while True:
p_word = input('Please input a password')
if re.fullmatch(r'[a-zA-z][^!@#¥%^&*]{5,11}', p_word):
print('Correct input')
break
else:
print('Illegal input')
pass_word()
- Known file test Txt is as follows:
Chen XX Caoyan 6895 13811661805 caoyan@baidu.com often XX Yu Cao 8366 13911404565 caoyu@baidu.com firewood XX Shirley Cao 6519 13683604090 caoyue@baidu.com Cao XX Cao Zheng 8290 13718160690 caozheng@baidu.com check XX Zha Lingli 6259 13552551952 zhalingli@baidu.com check XX Zha Shan 8580 13811691291 zhanshan@baidu.com check XX Rachel 8825 13341012971 zhanyu@baidu.com
Extract all mobile phone numbers and mailboxes in the file
import re
file_name = r'H:\pythonProject\test'
# Define mobile number extraction rules
get_tel = re.compile(r'\d{11}')
# Define mailbox extraction rules
get_mail = re.compile(r'\w+@baidu\.com')
# read file
with open(file_name, encoding='utf-8') as f:
list1 = f.readlines()
str_l = ' '.join(list1)
print('All phone numbers are{}'.format(get_tel.findall(str_l)))
print('All mailboxes are{}'.format(get_mail.findall(str_l)))
