python regular expression learning
I haven't used Python to write regular expressions for a long time. Some of them are abandoned and many of them have forgotten. I've seen python programming books these days. It's a small dish to review the old and learn the new. Regular expressions have many practical uses, but sometimes they are very complex. They are very useful when writing crawlers in Python. If they are used well, they can get twice the result with half the effort, Briefly review some simple uses of Python regular expressions.
Create regular expression object
All regular expression functions in Python are in the re module.
Regular expressions first need a matching pattern, that is, the string form you want to match. For a brief introduction, take matching phone numbers as an example.
The following string: 'My number is 415-555-4242.'
We want to match the phone number: "415-555-4242“
First, create a matching pattern by passing a string into the re.compile() function. The string represents the target string you want to match, and then compile returns a Rege object
The search() method of the Regex object finds the incoming string and all matches of the regular expression. For example
If the regular expression pattern is not found in the string, the search() method returns None. If the pattern is found,
The search() method will return a Match object. The Match object has a group() method that returns the searched word
Actual matching text in string
import re
#Pass in a string value to re.compile to represent a regular expression and return a Regex pattern object
phoneNumberRegex = re.compile(r'\d\d\d-\d\d\d-\d\d\d\d')
# The search method of the Regex object looks up the incoming string. If the pattern is found, it returns a Match object
# There is a group method in the Match object, which will return the actual matching text in the searched string
s = "My number is 415-555-4242"
mo = phoneNumberRegex.search(s)
print("phone number found: "+mo.group())
Operation results:

Bracket grouping
You can add parentheses to the matching pattern to represent groups, such as (\ d\d\d)-(\d\d\d-\d\d\d\d), and then use the group() matching object method. Here, a parenthesis is a group, such as group(1) to take out the first group.
Note that the difference from the python list habit here is that the grouping starts from 1 instead of 0. group(1) represents the first group, group(0) is equivalent to not passing in parameters, and the whole matching text is returned.
You can also return all matched groups through groups() (plural)
phoneNumberRegex_1 = re.compile(r'(\d\d\d)-(\d\d\d)-(\d\d\d\d)')
mo = phoneNumberRegex_1.search(s)
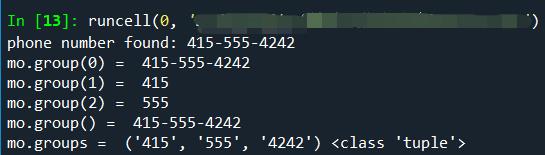
print("mo.group(0) = ",mo.group(0))
print("mo.group(1) = ",mo.group(1))
print("mo.group(2) = ",mo.group(2))
print("mo.group() = ",mo.group())
# If you want to get all the groups at once, use the groups() method and pay attention to the plural form of the function name.
#groups returns a tuple data
print("mo.groups = ",mo.groups(),type(mo.groups()))
Operation results:
The pipeline method matches multiple groups
The character "|" represents pipeline and selection. For example, if the mode "A|B", then both A and B can be matched, but if both A and B are in the text, the first one will be returned.
s1 = "Batman and Tina Fey is a filmaly.."
s2 = "Tina Fey and Batman is a filmaly.."
heroRegex = re.compile(r'Batman|Tina Fey')
mo1 = heroRegex.search(s1)
print("mo1.group = ",mo1.group())
# If Batman and Tina Fey both appear in the searched string, the matching text appears for the first time,
# Returns as a Match object.
mo2 = heroRegex.search(s2)
print("mo2.group = ", mo2.group())
Operation results:

Select Match
Sometimes we are not sure whether the matched text will appear, may or may not appear. You can use "?" to realize optional matching.
The character? Indicates that the previous group appears 0 or once in this mode.
# Optional matching with question marks
# The character? Indicates that the grouping before it is optional in this mode
#Note that the brackets here are also a group, which can be output in groups
batRegex = re.compile(r"Bat(wo)?man")
mo3 = batRegex.search("The Adventures of Batman")
print(mo3.group())#Operation result: Batman
mo4 = batRegex.search("The Adventures of Batwoman")
print(mo4.group())#Operation result: batoman
print(mo4.group(1))#Operation result: wo
Multiple matches
Similar to the matching of the symbol?, the asterisk * indicates 0 or more times of matching, which is unlimited,
The plus sign + matches one or more times, similar to the asterisk *, but matches at least once
batRegex1 = re.compile(r'Bat(wo)*man')
mo5 = batRegex1.search("The Advanture of Batman")
print(mo5.group())
mo6 = batRegex1.search("The Advanture of Batwoman")
print(mo6.group(),mo6.groups())
mo7 = batRegex1.search("The Advanture of Batwowowoman")
print(mo7.group(),mo7.groups())
Operation results:

The preceding asterisk and plus sign can give us multiple matches, but cannot control the number of matches. You need to specify the number of matches or control the number of matches within a certain range. You can use curly braces {}
Curly braces can be used in two ways:
1. Specify the number of matches. You only need to pass in a specified number of matches. For example, (Ha) {3} means that "Ha" repeats 3 times, matches "Ha ha", but does not match "Ha", or "Ha ha", etc
2. Specify the matching range, similar to the interval. For example, (Ha) {3, 5}, then "Ha" repeats 3 to 5 times, then "Ha ha", "Ha ha Ha", "Ha ha Ha" can be matched.
Note that Python's regular expressions are "greedy" by default, which means that in case of ambiguity, they will match the longest string as far as possible. The "non greedy" version of curly braces matches the shortest string as far as possible, that is, the ending curly braces are followed by a question mark.
greedRegex = re.compile(r'(Ha){3,5}')#Greedy matching
mo8 = greedRegex.search("HaHaHaHaHaHaHa")
print(mo8.group())#Operation result: hahaha
nongreedRegex = re.compile(r'(Ha){3,5}?')#Non greedy matching
mo9 = nongreedRegex.search("HaHaHaHaHaHaHa")
print(mo9.group())#Operation result: ha ha
findall method
Unlike the search method, the search method returns only the match object that matches for the first time, while the findall method returns a list of strings, each of which is a piece of text to be found.
phoneNumberRegex1 = re.compile(r"\d\d\d-\d\d\d-\d\d\d\d")
mo10 = phoneNumberRegex1.search('Cell: 415-555-9999 Work: 212-555-0000')
print(mo10.group())
# Instead of returning a Match object, findall() returns a list of strings
print(phoneNumberRegex1.findall('Cell: 415-555-9999 Work: 212-555-0000'))
phoneRegex2 = re.compile(r'(\d\d\d)-(\d\d\d)-(\d\d\d\d)')
print(phoneRegex2.findall('Cell: 415-555-9999 Work: 212-555-0000'))
Operation results:
415-555-9999
['415-555-9999', '212-555-0000']
[('415', '555', '9999'), ('212', '555', '0000')]
wildcard
Symbol. It is called a wildcard and matches all characters except line breaks. However, you can also match all characters, including line breaks, by passing in the re.DOTALL parameter during compile.
#Wildcard. Matches all characters except the newline character
atRegex = re.compile(r'.at')
print(atRegex.findall('The cat in the hat sat on the flat mat.'))
# Dot star will match all characters except line feed. Pass in re.DOTALL as the second character of re.compile()
# The second parameter allows the period character to match all characters, including newline characters.
s = 'Serve the public trust.\nProtect the innocent. \nUphold the law.'
print(s)
nonewLineRegex = re.compile('.*')
print("nonlineRegex = \n",nonewLineRegex.search(s).group())
newLineRegex = re.compile('.*',re.DOTALL)
print("newlineRegex = \n",newLineRegex.search(s).group())
Operation results:
['cat', 'hat', 'sat', 'lat', 'mat'] Serve the public trust. Protect the innocent. Uphold the law. nonlineRegex = Serve the public trust. newlineRegex = Serve the public trust. Protect the innocent. Uphold the law.
The above is a simple summary of regular expressions. If there are errors and omissions, please correct them.
reference resources:
"Getting started with ython programming quickly - automating cumbersome work", by Al Sweigart