To learn any programming technology, you should be tight and free. Today's blog is time to relax. Let's learn how to download pictures with scratch.
Target site description
The site to be collected this time is Sogou image channel, and the channel data is directly returned by the interface. The interface is as follows:
https://pic.sogou.com/napi/pc/recommend?key=homeFeedData&category=feed&start=10&len=10 https://pic.sogou.com/napi/pc/recommend?key=homeFeedData&category=feed&start=20&len=10
Only the start parameter is changing, so the implementation is relatively simple.
Write core crawler file
import scrapy
class SgSpider(scrapy.Spider):
name = 'sg'
allowed_domains = ['pic.sogou.com']
base_url = "https://pic.sogou.com/napi/pc/recommend?key=homeFeedData&category=feed&start={}&len=10"
start_urls = [base_url.format(0)]
def parse(self, response):
json_data = response.json()
if json_data is not None:
img_list = json_data["data"]["list"]
for img in img_list:
yield {'image_urls': [_["originImage"] for _ in img[0]["picList"]]}
else:
return None
The above code directly calls the interface data of the first page, and the subsequent codes are extracting the picture address in the JSON data.
The most important line of code is as follows:
yield {'image_urls': [_["originImage"] for _ in img[0]["picList"]]}
Image here_ URLs is to call the built-in picture download middleware of graph with fixed parameters.
settings.py
The document also needs to be modified. The details are as follows:
# User agent settings
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# The download interval is set to 3 seconds
DOWNLOAD_DELAY = 3
# Default request header
DEFAULT_REQUEST_HEADERS = {
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'HOST': 'pic.sogou.com',
}
# Open the imagespipline image saving pipeline
ITEM_PIPELINES = {
'scrapy.pipelines.images.ImagesPipeline': 1,
}
# Picture storage folder
IMAGES_STORE = "images"
The running code images will be automatically downloaded and saved in the images directory. After downloading, the following information will be output. This time, only the first page of data will be collected and 40 images will be obtained.
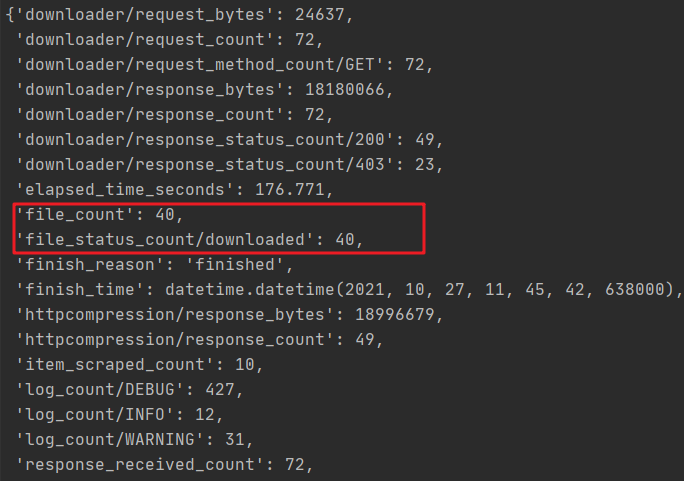
If you don't download the target image after running the code, please make sure whether the following BUG appears.
ImagesPipeline requires installing Pillow 4.0.0
The solution is very simple. Just install the pilot library.
Another problem is that the file name is dynamic and looks a little messy.
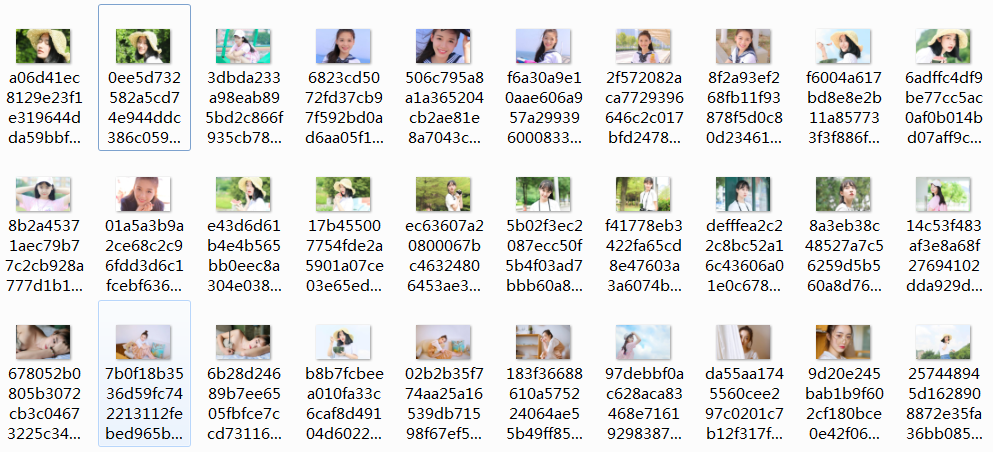
Add a data pipeline with user-defined file name in the pipelines.py file.
class SogouImgPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
name = item["name"]
for index, url in enumerate(item["image_urls"]):
yield Request(url, meta={'name': name, 'index': index})
def file_path(self, request, response=None, info=None):
# name
name = request.meta['name']
# Indexes
index = request.meta['index']
filename = u'{0}_{1}.jpg'.format(name, index)
print(filename)
return filename
The main function of the above code is to rename the image file name. Next, synchronously modify the relevant code in the SgSpider class.
def parse(self, response):
json_data = response.json()
if json_data is not None:
img_list = json_data["data"]["list"]
for img in img_list:
yield {
'name': img[0]['title'],
'image_urls': [_["originImage"] for _ in img[0]["picList"]],
}
else:
return None
Run the code again. After the image is saved, the file name becomes much easier to identify.
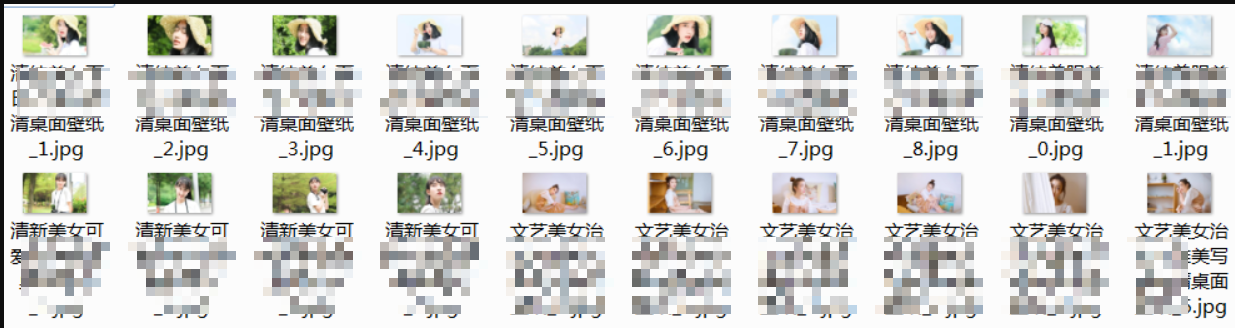
Finally, complete the logic on the next page to realize this case. This step is left to you.
Write it at the back
Today is the 258th / 365 day of continuous writing.
Look forward to attention, praise, comment and collection.
More wonderful
"100 crawlers, column sales, you can learn a series of columns after buying"
