A what day
January 1, 2000 is the first day of that year.
So, May 4, 2000, is the first day of that year?
Note: what needs to be submitted is an integer. Do not fill in any redundant content.
Answer: 125
31+29+31+30+4=125
B clear code
The font of Chinese characters exists in the font library. Even today, the 16 dot matrix font library is still widely used.
The 16 dot matrix font regards each Chinese character as 16x16 pixel information. And record this information in bytes.
One byte can store 8 bits of information, and 32 bytes can store the font of a Chinese character.
Convert each byte to binary representation, 1 for ink and 0 for background color. 2 bytes per line,
There are 16 lines in total. The layout is:
1st byte, 2nd byte
3rd byte, 4th byte
...
31st byte, 32nd byte
This topic is to give you a piece of information composed of multiple Chinese characters. Each Chinese character is represented by 32 bytes. Here is the value of bytes as a signed integer.
The requirements of the topic are hidden in this information. Your task is to restore the glyphs of these Chinese characters, see the requirements of the questions, and fill in the answers according to the requirements.
This message is (10 Chinese characters in total):
4 0 4 0 4 0 4 32 -1 -16 4 32 4 32 4 32 4 32 4 32 8 32 8 32 16 34 16 34 32 30 -64 0 16 64 16 64 34 68 127 126 66 -124 67 4 66 4 66 -124 126 100 66 36 66 4 66 4 66 4 126 4 66 40 0 16 4 0 4 0 4 0 4 32 -1 -16 4 32 4 32 4 32 4 32 4 32 8 32 8 32 16 34 16 34 32 30 -64 0 0 -128 64 -128 48 -128 17 8 1 -4 2 8 8 80 16 64 32 64 -32 64 32 -96 32 -96 33 16 34 8 36 14 40 4 4 0 3 0 1 0 0 4 -1 -2 4 0 4 16 7 -8 4 16 4 16 4 16 8 16 8 16 16 16 32 -96 64 64 16 64 20 72 62 -4 73 32 5 16 1 0 63 -8 1 0 -1 -2 0 64 0 80 63 -8 8 64 4 64 1 64 0 -128 0 16 63 -8 1 0 1 0 1 0 1 4 -1 -2 1 0 1 0 1 0 1 0 1 0 1 0 1 0 5 0 2 0 2 0 2 0 7 -16 8 32 24 64 37 -128 2 -128 12 -128 113 -4 2 8 12 16 18 32 33 -64 1 0 14 0 112 0 1 0 1 0 1 0 9 32 9 16 17 12 17 4 33 16 65 16 1 32 1 64 0 -128 1 0 2 0 12 0 112 0 0 0 0 0 7 -16 24 24 48 12 56 12 0 56 0 -32 0 -64 0 -128 0 0 0 0 1 -128 3 -64 1 -128 0 0
Text: what is the power of nine
Answer: 387420489
from math import *
raw=["4 0 4 0 4 0 4 32 -1 -16 4 32 4 32 4 32 4 32 4 32 8 32 8 32 16 34 16 34 32 30 -64 0",
'16 64 16 64 34 68 127 126 66 -124 67 4 66 4 66 -124 126 100 66 36 66 4 66 4 66 4 126 4 66 40 0 16',
'4 0 4 0 4 0 4 32 -1 -16 4 32 4 32 4 32 4 32 4 32 8 32 8 32 16 34 16 34 32 30 -64 0',
'0 -128 64 -128 48 -128 17 8 1 -4 2 8 8 80 16 64 32 64 -32 64 32 -96 32 -96 33 16 34 8 36 14 40 4',
'4 0 3 0 1 0 0 4 -1 -2 4 0 4 16 7 -8 4 16 4 16 4 16 8 16 8 16 16 16 32 -96 64 64',
'16 64 20 72 62 -4 73 32 5 16 1 0 63 -8 1 0 -1 -2 0 64 0 80 63 -8 8 64 4 64 1 64 0 -128',
'0 16 63 -8 1 0 1 0 1 0 1 4 -1 -2 1 0 1 0 1 0 1 0 1 0 1 0 1 0 5 0 2 0',
'2 0 2 0 7 -16 8 32 24 64 37 -128 2 -128 12 -128 113 -4 2 8 12 16 18 32 33 -64 1 0 14 0 112 0',
'1 0 1 0 1 0 9 32 9 16 17 12 17 4 33 16 65 16 1 32 1 64 0 -128 1 0 2 0 12 0 112 0',
'0 0 0 0 7 -16 24 24 48 12 56 12 0 56 0 -32 0 -64 0 -128 0 0 0 0 1 -128 3 -64 1 -128 0 0']
words=[]
for i in raw:
words.append(list(map(int,i.split())))
for line in words:
for j in range(len(line)):
if line[j]==-128:
print("10000000",end="")
elif line[j]>=0:
print("{:0>8b}".format(line[j]),end="")
else:
print("1{:1>7b}".format(abs(line[j])),end="")
if j%2==1:
print()
print()
C product tail zero
For the following 10 rows of data, each row has 10 integers. Please find out how many zeros are at the end of their product?
5650 4542 3554 473 946 4114 3871 9073 90 4329 2758 7949 6113 5659 5245 7432 3051 4434 6704 3594 9937 1173 6866 3397 4759 7557 3070 2287 1453 9899 1486 5722 3135 1170 4014 5510 5120 729 2880 9019 2049 698 4582 4346 4427 646 9742 7340 1230 7683 5693 7015 6887 7381 4172 4341 2909 2027 7355 5649 6701 6645 1671 5978 2704 9926 295 3125 3878 6785 2066 4247 4800 1578 6652 4616 1113 6205 3264 2915 3966 5291 2904 1285 2193 1428 2265 8730 9436 7074 689 5510 8243 6114 337 4096 8199 7313 3685 211
Answer: 31
num=[5650, 4542, 3554, 473, 946, 4114, 3871, 9073, 90, 4329,
2758, 7949, 6113,5659, 5245, 7432, 3051, 4434, 6704, 3594,
9937, 1173, 6866, 3397, 4759, 7557, 3070, 2287, 1453, 9899,
1486, 5722, 3135, 1170, 4014, 5510, 5120, 729, 2880, 9019,
2049, 698, 4582, 4346, 4427, 646, 9742, 7340, 1230, 7683,
5693, 7015, 6887, 7381, 4172, 4341, 2909, 2027, 7355, 5649,
6701, 6645, 1671, 5978, 2704, 9926, 295, 3125, 3878, 6785,
2066, 4247, 4800, 1578, 6652, 4616, 1113, 6205, 3264, 2915,
3966, 5291, 2904, 1285, 2193, 1428, 2265, 8730, 9436, 7074,
689, 5510, 8243, 6114, 337, 4096, 8199, 7313, 3685, 211]
cnt=0
res=1
for i in num:
res*=i
while res%10==0:
res//=10
cnt+=1
print(cnt)
#31
D number of tests
The residents of Planet x have a bad temper, but fortunately, when they are angry, the only unusual behavior is to drop their mobile phones.
Major manufacturers have also launched a variety of fall resistant mobile phones. The Quality Supervision Bureau of Planet x stipulates that mobile phones must pass the fall resistance test and evaluate a fall resistance index before they are allowed to be listed and circulated.
Planet x has many towering towers, which can be used for fall resistance test. The height of each floor of the tower is the same. Slightly different from the earth, their first floor is not the ground, but equivalent to our second floor.
If the mobile phone is not broken when dropped from the 7th floor, but the 8th floor is broken, the falling resistance index of the mobile phone = 7.
In particular, if the mobile phone is broken when dropped from the first floor, the fall resistance index = 0.
If the n-th floor at the top of the tower is not damaged, the falling resistance index = n
In order to reduce the number of tests, three mobile phones were sampled from each manufacturer to participate in the test.
The tower height of a test is 1000 floors. If we always adopt the best strategy, how many times do we need to test at most under the worst luck to determine the fall resistance index of the mobile phone?
Please fill in the maximum number of tests.
Note: what needs to be filled in is an integer. Do not fill in any redundant content.
E quick sort
The following code can find the k-th smallest element from the array a [].
It uses a divide and conquer algorithm similar to that in quick sort, and the expected time complexity is O(N).
Please read the analysis source code carefully and fill in the missing content in the underlined part.
#include <stdio.h>
int quick_select(int a[], int l, int r, int k) {
int p = rand() % (r - l + 1) + l;
int x = a[p];
{int t = a[p]; a[p] = a[r]; a[r] = t;}
int i = l, j = r;
while(i < j) {
while(i < j && a[i] < x) i++;
if(i < j) {
a[j] = a[i];
j--;
}
while(i < j && a[j] > x) j--;
if(i < j) {
a[i] = a[j];
i++;
}
}
a[i] = x;
p = i;
if(i - l + 1 == k) return a[i];
if(i - l + 1 < k) return quick_select( _____________________________ ); //Fill in the blanks
else return quick_select(a, l, i - 1, k);
}
int main()
{
int a[] = {1, 4, 2, 8, 5, 7, 23, 58, 16, 27, 55, 13, 26, 24, 12};
printf("%d\n", quick_select(a, 0, 14, 5));
return 0;
}
Note: only fill in the missing code in the underlined part, and do not copy the existing code or symbol.
Answer: a,i+1,r,k-(i-l+1)
F increment triplet
Given three integer arrays
A = [A1, A2, ... AN],
B = [B1, B2, ... BN],
C = [C1, C2, ... CN],
Please count how many triples (i, j, k) satisfy:
- 1 <= i, j, k <= N
- Ai < Bj < Ck
[input format]
The first line contains an integer N.
The second line contains N integers A1, A2,... AN.
The third row of integers, B N, B2.
The fourth line contains N integers C1, C2,... CN.
For 30% data, 1 < = n < = 100
For 60% of data, 1 < = n < = 1000
For 100% data, 1 < = n < = 100000, 0 < = AI, Bi, CI < = 100000
[output format]
An integer represents the answer
[sample input]
3
1 1 1
2 2 2
3 3 3
[sample output]
27
Idea:
Traverse the numbers of array b, and then find how many in array a are smaller than him and how many in array c are larger than him. Multiply and accumulate is the answer
n=int(input())
a=list(map(int,input().split()))
b=list(map(int,input().split()))
c=list(map(int,input().split()))
a.sort()
b.sort()
c.sort()
res=0
for i in range(n):
cnt1=cnt2=0
for j in range(n):
if a[j]<b[i]:
cnt1+=1
else:
break
for j in range(n-1,-1,-1):
if c[j]>b[i]:
cnt2+=1
else:
break
res+=cnt1*cnt2
print(res)
#python can pass 75%, and c + + should pass all
G-helix
As shown in Figure P1 The spiral polyline shown in PNG passes through all integral points on the plane exactly once.
For the whole point (X, Y), we define its distance from the origin. dis(X, Y) is the length of the spiral line segment from the origin to (X, Y).
For example, dis(0, 1)=3, dis(-2, -1)=9
Given the coordinates of the whole point (X, Y), can you calculate dis(X, Y)?
[input format]
X and Y
For 40% data, - 1000 < = x, y < = 1000
For 70% of data, - 100000 < = x, y < = 100000
For 100% data, - 1000000000 < = x, y < = 1000000000
[output format]
Output dis(X, Y)
[sample input]
0 1
[sample output]
3
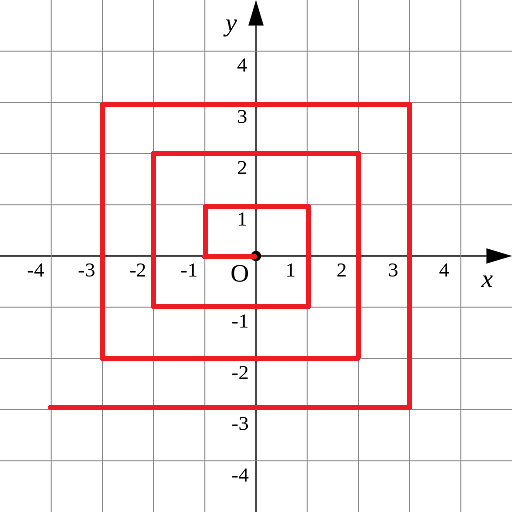
Idea:
Pay attention to the data scale. The order of one billion is certainly beyond the simulation. Therefore, to find the law, you can pass with constant time complexity.
Make some changes to the figure, as shown in the following figure:
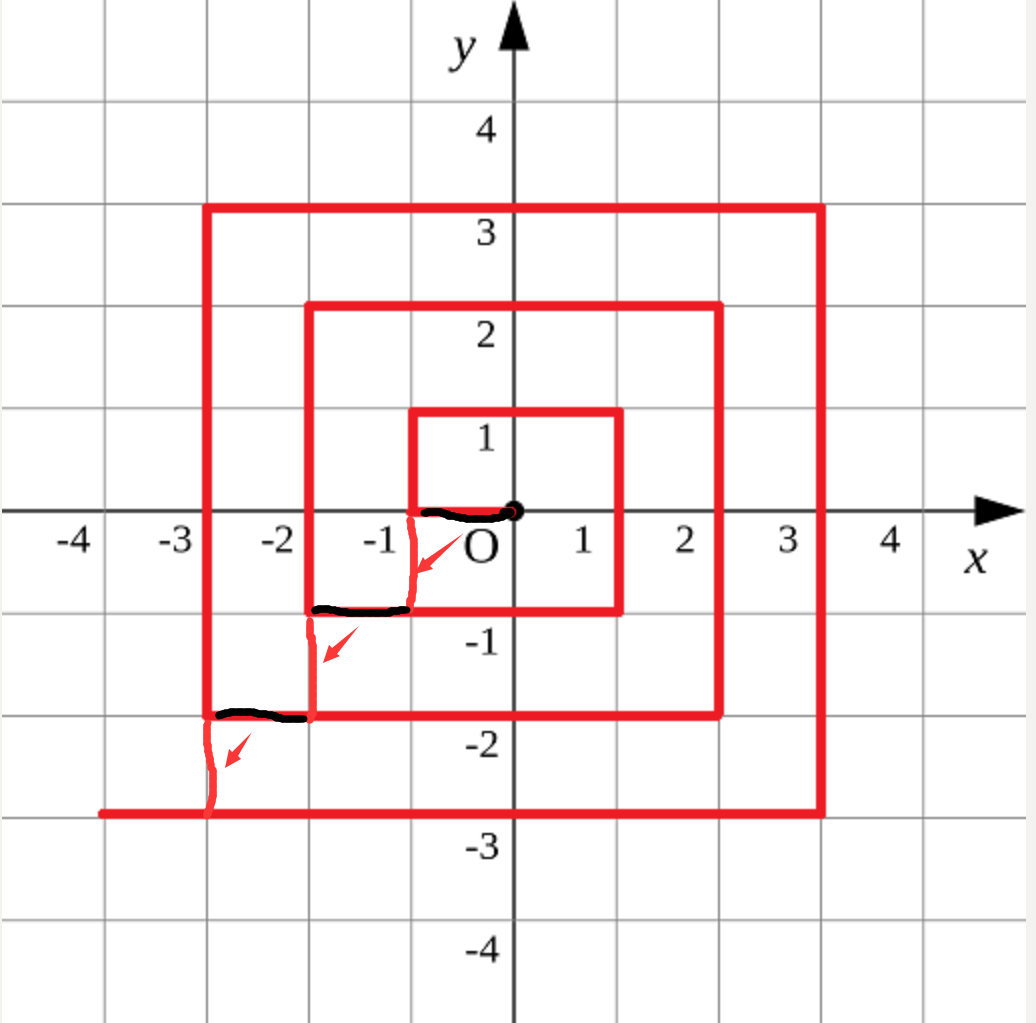
i rotate the black line in the picture clockwise by 90 degrees, and the spiral broken line becomes a zigzag. It's better to set the innermost layer as the first layer, with its side length of 2, then the second layer, with side length of 4,..., and so on. The side length of layer i is 2i and the perimeter is 4*2i. This is an arithmetic sequence, so the total length of N layers from the inside to the outside is 4n(n+1).
If we continue to observe, we will find that the number of layers of any point in the coordinate system is the larger one in the absolute value of the abscissa and ordinate. So we can first calculate a value slightly larger than the real length according to the number of layers, and then go back. The starting point of the backward is the lowest vertex of each square after rotation. Then we can classify and discuss according to the position of the points, subtract the redundant part paragraph by paragraph, and finally get the result.
The code is as follows:
from math import *
x,y=map(int,input().split())
ceng=max(abs(x),abs(y))
res=4*ceng*(ceng+1)
if x>=0:
res-=ceng
if y<0:
if abs(y)==ceng:
res-=x
else:
res-=ceng
res-=ceng-abs(y)
else:
res-=ceng*2
if x==ceng:
res-=y
else:
res-=ceng
res-=ceng-x
else:
res-=ceng*5
if y>0:
if y==ceng:
res-=abs(x)
else:
res-=ceng
res-=ceng-y
else:
res-=ceng*2
if abs(x)==ceng:
res-=abs(y)
else:
res-=ceng-1
res-=ceng-abs(x)
print(res)
#100% pass
H log statistics
Xiao Ming maintains a programmer forum. Now he has collected a "like" log with N lines. The format of each line is:
ts id
Indicates that the post with id number at ts time receives a "like".
Now Xiao Ming wants to count which posts used to be "hot posts". If a post has received no less than K likes in any time period with a length of D, Xiaoming thinks that the post was once a "hot post".
Specifically, if there is a certain time when t satisfies that the post receives no less than K likes during the period of [T, T+D) (note that the left closed and right open interval), the post was once a "hot post".
Given the log, please help Xiao Ming count all the post numbers that were once "hot posts".
[input format]
The first line contains three integers N, D, and K.
Each of the following N lines contains two integers ts and id.
For 50% of the data, 1 < = k < = n < = 1000
For 100% data, 1 < = k < = n < = 100000 0 < = TS < = 100000 0 < = ID < = 100000
[output format]
Output the hot post id from small to large. One line per id.
[sample input]
7 10 2
0 1
0 10
10 10
10 1
9 1
100 3
100 3
[output example]
1
3
Idea: use a data structure to store the input time and ID. take id as the key and a list organized by time as the value. The key value is in ascending order to the key, and the time of each ID is also in ascending order. Traverse the time list of each ID, and output the ID if there are qualified ones.
n,d,k=map(int,input().split())
good={}
for i in range(n):
ts,id=map(int,input().split())
if id in good:
good.get(id).append(ts)
else:
good[id]=[ts]
good=list(good.items())
good.sort(key=lambda x:x[0])
for index,li in good:
li.sort()
maxn=li[-1]-d+2
if maxn<=li[0]:
maxn=li[0]+1
for t in range(li[0],maxn):
cnt=0
for i in li:
if t<=i<t+d:
cnt+=1
elif i>=t+d:
break
if cnt >=k:
print(index)
break
#75%
I global warming
You have a picture of NxN pixels of a certain sea area, "." represents the ocean, "#" represents the land, as shown below:
...
.##...
.##...
...##.
...####.
...###.
...
Among them, a piece of land connected in the four directions of "up, down, left and right" forms an island. For example, there are two islands in the above picture.
As the sea level rises due to global warming, scientists predict that a pixel of the edge of the island will be submerged by the sea in the coming decades. Specifically, if a land pixel is adjacent to the ocean (there is an ocean in the four adjacent pixels above, below, left and right), it will be submerged.
For example, the sea area in the above figure will look like the following in the future:
...
...
...
...
...#...
...
...
Please calculate: according to the prediction of scientists, how many islands in the picture will be completely submerged.
[input format]
The first line contains an integer n. (1 <= N <= 1000)
The following n rows and N columns represent a sea area photo.
The picture ensures that the pixels in row 1, column 1, row N and column n are oceans.
[output format]
An integer represents the answer.
[sample input]
7
...
.##...
.##...
...##.
...####.
...###.
...
[output example]
1
Maximum product of J
Give N integers A1, A2,... AN. Please choose K numbers from them to maximize their product.
Please find the maximum product. Since the product may exceed the integer range, you only need to output the remainder of the product divided by 100000009.
Note that if x < 0, we define that the remainder of X divided by 100000009 is the remainder of negative (- X) divided by 100000009.
Namely: 0 - ((0-x)% 100000009)
[input format]
The first line contains two integers N and K.
The following N lines each contain an integer Ai.
For 40% of the data, 1 < = k < = n < = 100
For 60% of data, 1 < = k < = 1000
For 100% data, 1 < = k < = n < = 100000 - 100000 < = AI < = 100000
[output format]
An integer representing the answer.
[sample input]
5 3
-100000
-10000
2
100000
10000
[output example]
999100009
Another example:
[sample input]
5 3
-100000
-100000
-2
-100000
-100000
[output example]
-999999829