
Most students have heard of the famous Bert algorithm. It is a "King bomb" pre training model in the NLP field launched by Google. It has refreshed a number of records in NLP tasks and achieved the result of state of the art.
However, many novices of in-depth learning find that BERT model is not easy to build and it is very difficult to get started. Ordinary people may have to study for a few days to build a model.
It doesn't matter. The module we introduced today allows you to build a Q & a search engine based on BERT algorithm in 3 minutes. It is the "BERT as service" project. This open source project enables you to quickly build BERT services based on multiple GPU machines (support fine-tuning model) and allow multiple clients to use them concurrently.
1. Preparation
Before you start, make sure that Python and pip have been successfully installed on your computer. If not, install them.
(optional 1) if you use Python for data analysis, you can directly install Anacond
(optional 2) in addition, it is recommended that you use the VSCode editor, which has many advantages.
Please choose one of the following ways to enter the command to install dependencies: 1. Open Cmd (start run CMD) in Windows environment. 2. Open terminal in MacOS environment (Command + space, enter Terminal). 3. If you use the VSCode editor or pychart, you can directly use the Terminal at the bottom of the interface
pip install bert-serving-server # Server pip install bert-serving-client # client
Please note that the server version requirements: Python > = 3.5, tensorflow > = 1.10.
In addition, download the pre trained BERT model and https://github.com/hanxiao/bert-as-service#install It can be downloaded from.
You can also download these pre trained models in the Python practical dictionary background {Bert as service.
After downloading, unzip the zip file into a folder, such as / tmp/english_L-12_H-768_A-12/
2. Basic use of Bert as service
After installation, enter the following command to start the BERT service:
bert-serving-start -model_dir /tmp/english_L-12_H-768_A-12/ -num_worker=4
-num_worker=4 means that this will start a service with four workers, which means that it can handle up to four concurrent requests. More than four other concurrent requests will be queued in the load balancer for processing.
The following shows what the server looks like when it starts correctly:
Use the client to get the encoding of the statement
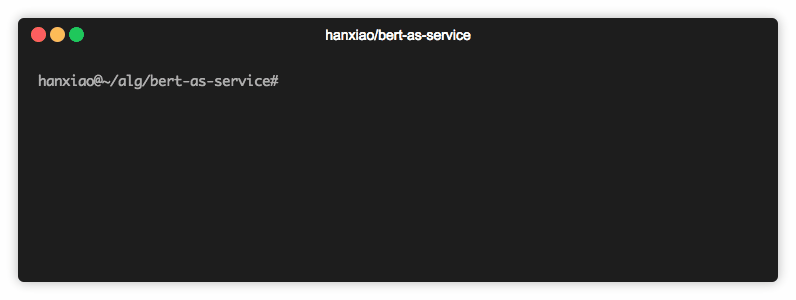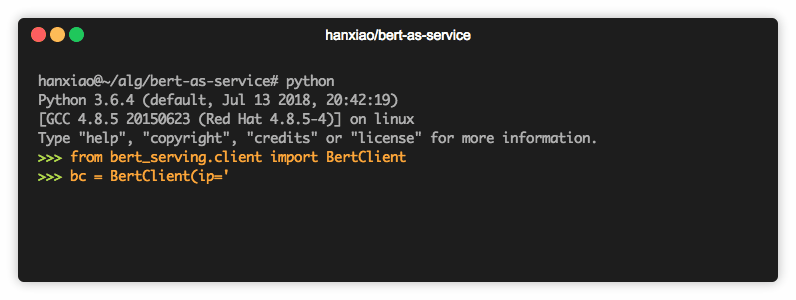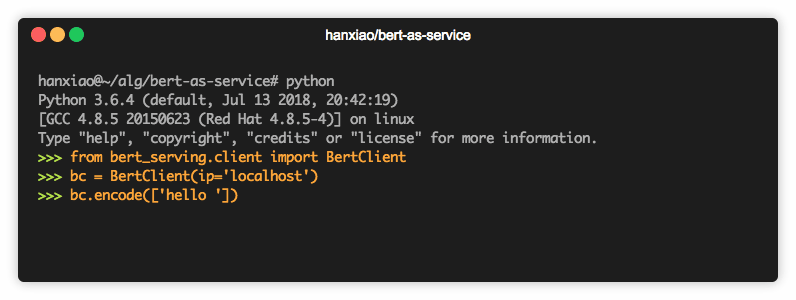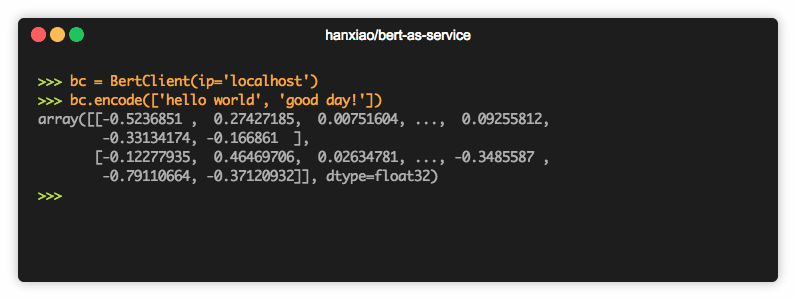
Now you can simply code the sentence as follows:
from bert_serving.client import BertClient bc = BertClient() bc.encode(['First do it', 'then do it right', 'then do it better'])
As a feature of BERT, you can get a pair of sentence codes by connecting them with | (there are spaces before and after), for example
bc.encode(['First do it ||| then do it right'])

Remote use of BERT services
You can also start the service on one (GPU) machine and call it from another (CPU) machine, as follows:
# on another CPU machine from bert_serving.client import BertClient bc = BertClient(ip='xx.xx.xx.xx') # ip address of the GPU machine bc.encode(['First do it', 'then do it right', 'then do it better'])
3. Build a Q & a search engine
We will find the question most similar to the question entered by the user from the FAQ list through Bert as service, and return the corresponding answer.
You can also download the FAQ list in the Python practical dictionary background reply "Bert as service".
First, load all questions and display statistics:
prefix_q = '##### **Q:** '
with open('README.md') as fp:
questions = [v.replace(prefix_q, '').strip() for v in fp if v.strip() and v.startswith(prefix_q)]
print('%d questions loaded, avg. len of %d' % (len(questions), np.mean([len(d.split()) for d in questions])))
# 33 questions loaded, avg. len of 9A total of 33 questions were loaded, with an average length of 9
Then use the pre trained model: uncased_L-12_H-768_A-12 # start a Bert service:
bert-serving-start -num_worker=1 -model_dir=/data/cips/data/lab/data/model/uncased_L-12_H-768_A-12
Next, code our question as a vector:
bc = BertClient(port=4000, port_out=4001) doc_vecs = bc.encode(questions)
Finally, we are ready to receive user queries and perform a simple "fuzzy" search on existing problems.
Therefore, every time a new query arrives, we encode it into a vector and calculate its dot product doc_vecs then sorts the results in descending order and returns the first N similar questions:
while True:
query = input('your question: ')
query_vec = bc.encode([query])[0]
# compute normalized dot product as score
score = np.sum(query_vec * doc_vecs, axis=1) / np.linalg.norm(doc_vecs, axis=1)
topk_idx = np.argsort(score)[::-1][:topk]
for idx in topk_idx:
print('> %s\t%s' % (score[idx], questions[idx]))Done! Now run the code and enter your query to see how the search engine handles fuzzy matching:
The complete code is as follows, with a total of 23 lines of code (you can also download by replying to keywords in the background):
Slide up to see the complete code
import numpy as np
from bert_serving.client import BertClient
from termcolor import colored
prefix_q = '##### **Q:** '
topk = 5
with open('README.md') as fp:
questions = [v.replace(prefix_q, '').strip() for v in fp if v.strip() and v.startswith(prefix_q)]
print('%d questions loaded, avg. len of %d' % (len(questions), np.mean([len(d.split()) for d in questions])))
with BertClient(port=4000, port_out=4001) as bc:
doc_vecs = bc.encode(questions)
while True:
query = input(colored('your question: ', 'green'))
query_vec = bc.encode([query])[0]
# compute normalized dot product as score
score = np.sum(query_vec * doc_vecs, axis=1) / np.linalg.norm(doc_vecs, axis=1)
topk_idx = np.argsort(score)[::-1][:topk]
print('top %d questions similar to "%s"' % (topk, colored(query, 'green')))
for idx in topk_idx:
print('> %s\t%s' % (colored('%.1f' % score[idx], 'cyan'), colored(questions[idx], 'yellow')))Is it simple enough? Of course, this is a simple QA search model based on pre trained Bert model.
You can also fine tune the model to make the overall performance of the model more perfect. You can put your data in a directory and then execute run_classifier.py fine tune the model