Series articles
Python learning 01 - Fundamentals of Python
Python third party Library -- urllib learning
Python learning 02 - Python crawler
Python third party Library -- urllib learning
The urllib library is mainly used to manipulate web page URL s and crawl web page contents. It is usually used by crawlers in Python. Some functions are briefly described here for later crawlers.
1. Import urllib Library
# Since our crawler does not need to use the whole urllib, we only import some of the required import urllib.request # Used to initiate a request import urllib.parse # Used to parse URLs import urllib.error # Import exceptions that may be thrown to catch # The current version requires a security certificate for https, so you need to import ssl and execute the following statement import ssl ssl._create_default_https_context = ssl._create_unverified_context
2. get mode access
# Use urlopen() to return an HTML by default using the get request
response = urllib.request.urlopen("http://www.baidu.com")
# read() reads the entire HTML. In addition, readline() reads one line, and readlines() reads all and returns the list
# decode() decodes the content to utf-8
print(response.read().decode("utf-8"))
Running result: Baidu home page HTML source code
3. post access
# A post request can carry form data
# The data needs to be parsed. First use parse's urlencode to encode it, and then use bytes to convert it into utf-8 byte stream.
data = bytes(urllib.parse.urlencode({"username": "Xiaobai", "password": "123456"}), encoding="utf-8")
# http://httpbin.org/post Is an HTTP test website
response = urllib.request.urlopen("http://httpbin.org/post", data=data)
print(response.read().decode("utf-8"))
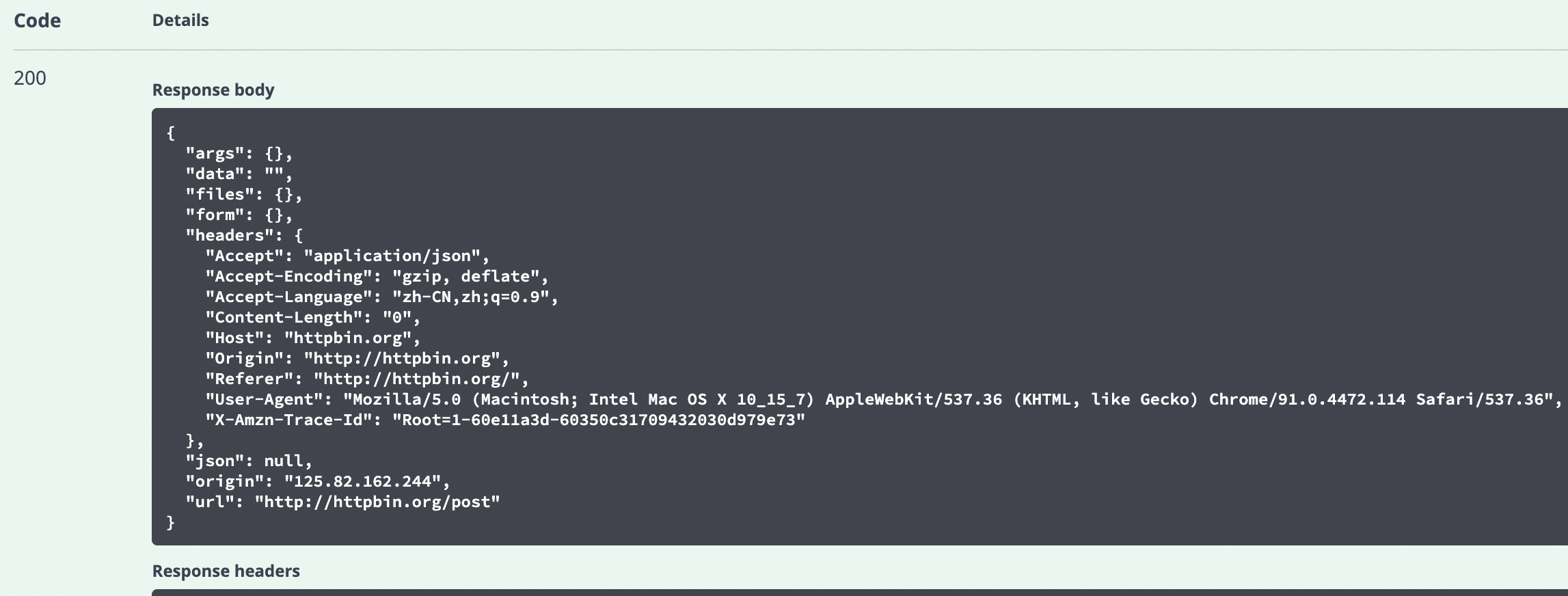
Operation results:
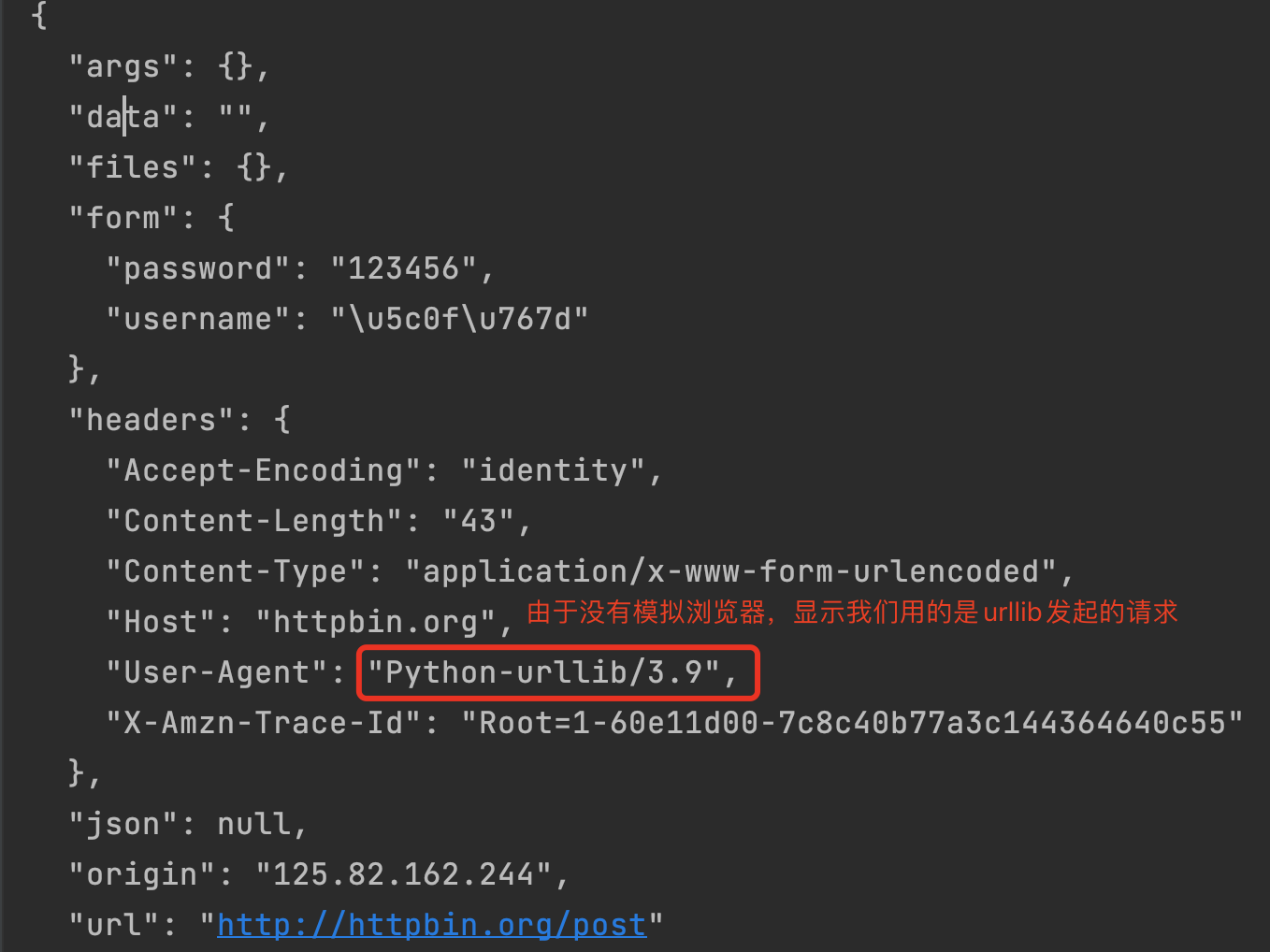
Explain:
The web address used here is http://httpbin.org/post , which is the test URL provided by httpbin.
We can use the methods provided in it to test our request. For example, the post request provided by it is used here.
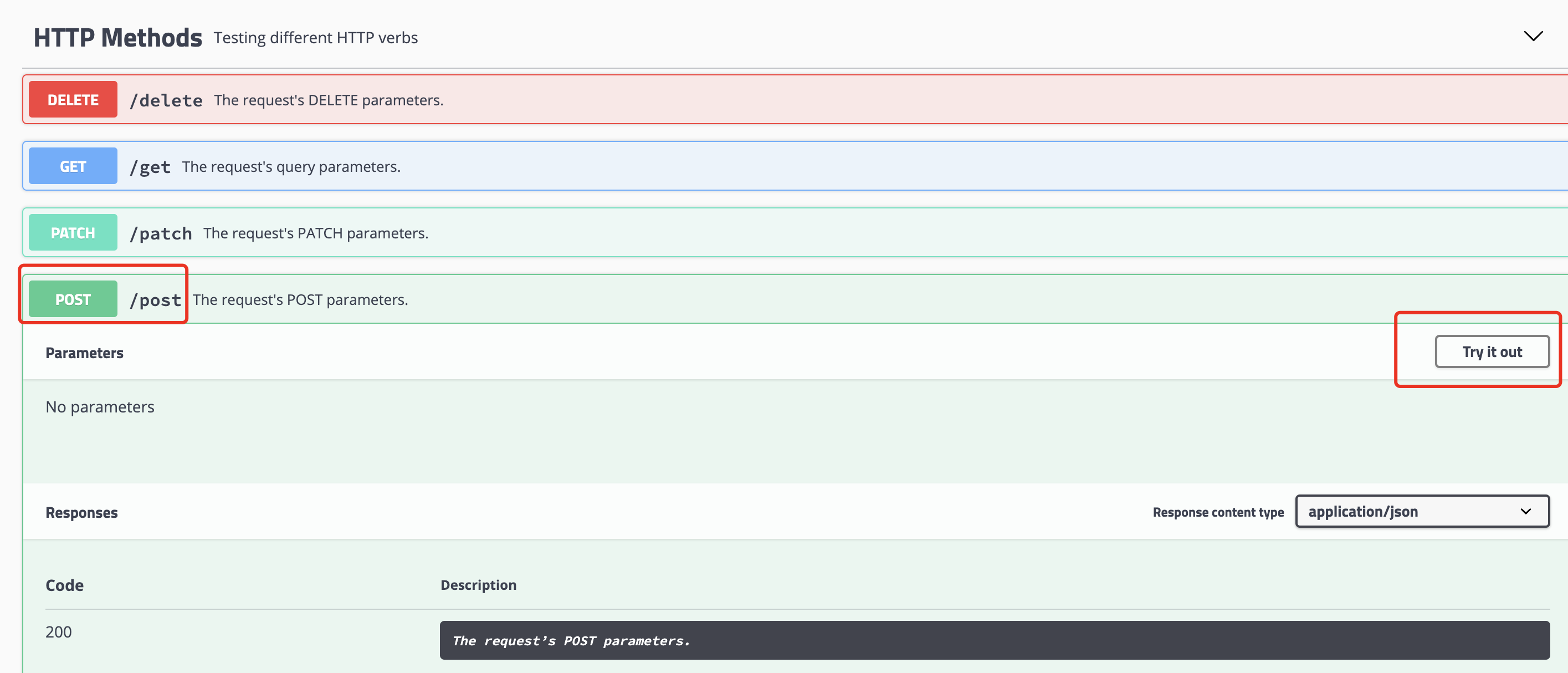
When we click Try it out and then click excess, it is actually the browser's response to the link http://httpbin.org/post A POST request is made, and the following Response body is the response from the server to our browser.
4. Timeout processing
In reality, crawlers may be slow due to unexpected situations such as network fluctuations or blocked by websites. Therefore, limit the request time. When it exceeds a certain time, skip the current crawl first. You only need to add one parameter.
# Timeout processing (using get test): set the timeout parameter to 0.01 seconds timeout, and the URLError exception will be thrown when timeout occurs.
try:
response = urllib.request.urlopen("http://httpbin.org/get", timeout=0.01)
print(response.read().decode("utf-8"))
except urllib.error.URLError as e:
print("overtime")
5. Web page related information
For each request, the server will have the status code and response header of the response, which can be read directly from the return value.
# Get web page information
response = urllib.request.urlopen("http://baidu.com")
print(response.status) # Status code 200 indicates success, 404 indicates that the web page cannot be found, and 418 indicates that the crawler is rejected
print(response.getheaders()) # Get response header
print(response.getheader("Server")) # Get a parameter in the response header
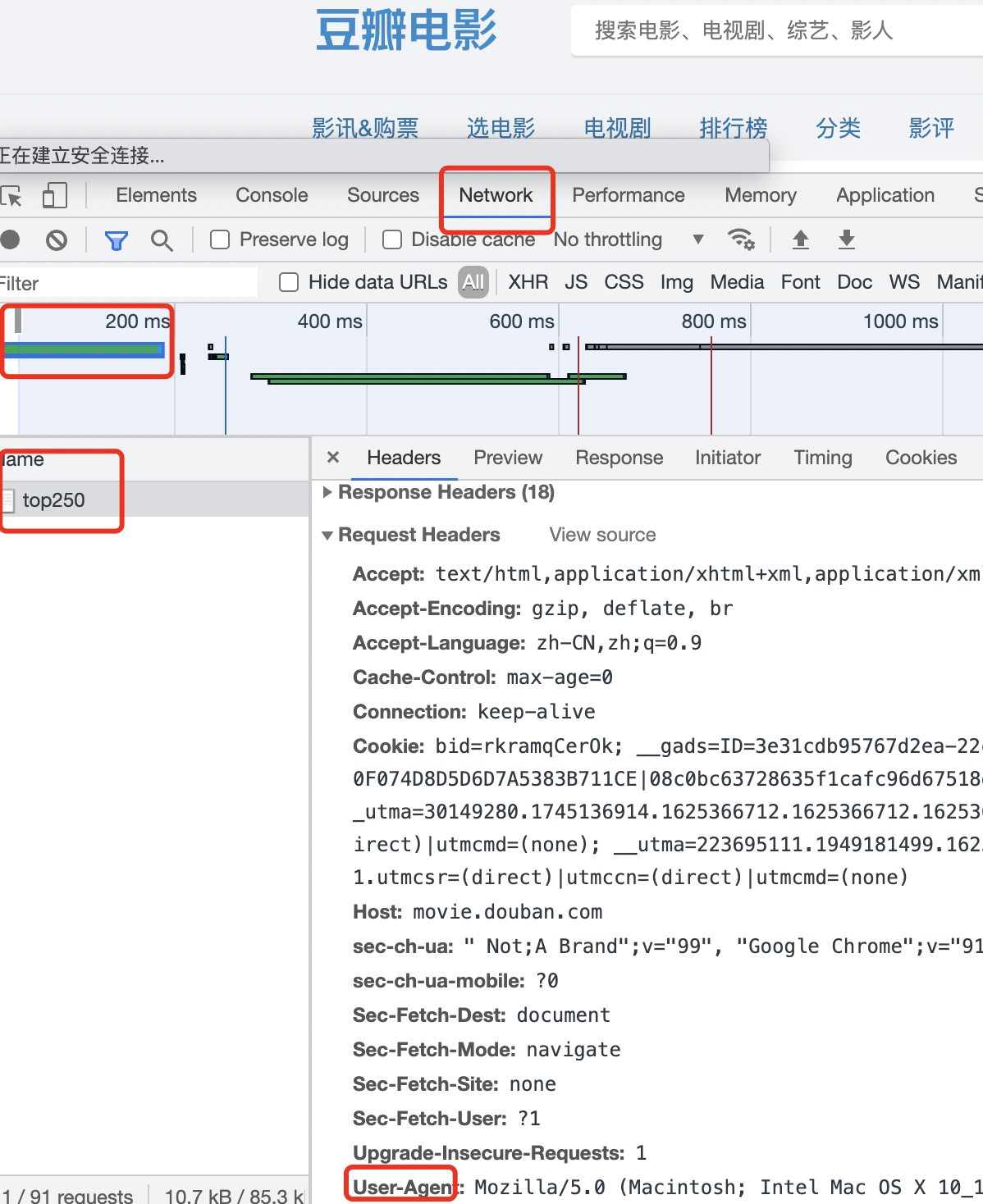
6. Simulation browser
# Simulation browser
url = "https://www.douban.com"
# This is to add a request header to simulate the browser
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36"
}
# Douban is the Get mode
# Using post is like this: urllib request. Request(url=url, data=data, headers=headers, method="POST")
req = urllib.request.Request(url=url, headers=headers) # The default is Get
response = urllib.request.urlopen(req)
print(response.read().decode("utf-8"))
Note: HTTPS requests need to import the SSL module and execute SSL_ create_ default_ https_ context = ssl._ create_ unverified_ context
Explain:
The request header contains the information provided by our request for the target URL. The user agent represents the user agent, that is, what we use to access. If we do not add the user agent of headers, we will be exposed as a python urlib 3.9 crawler.