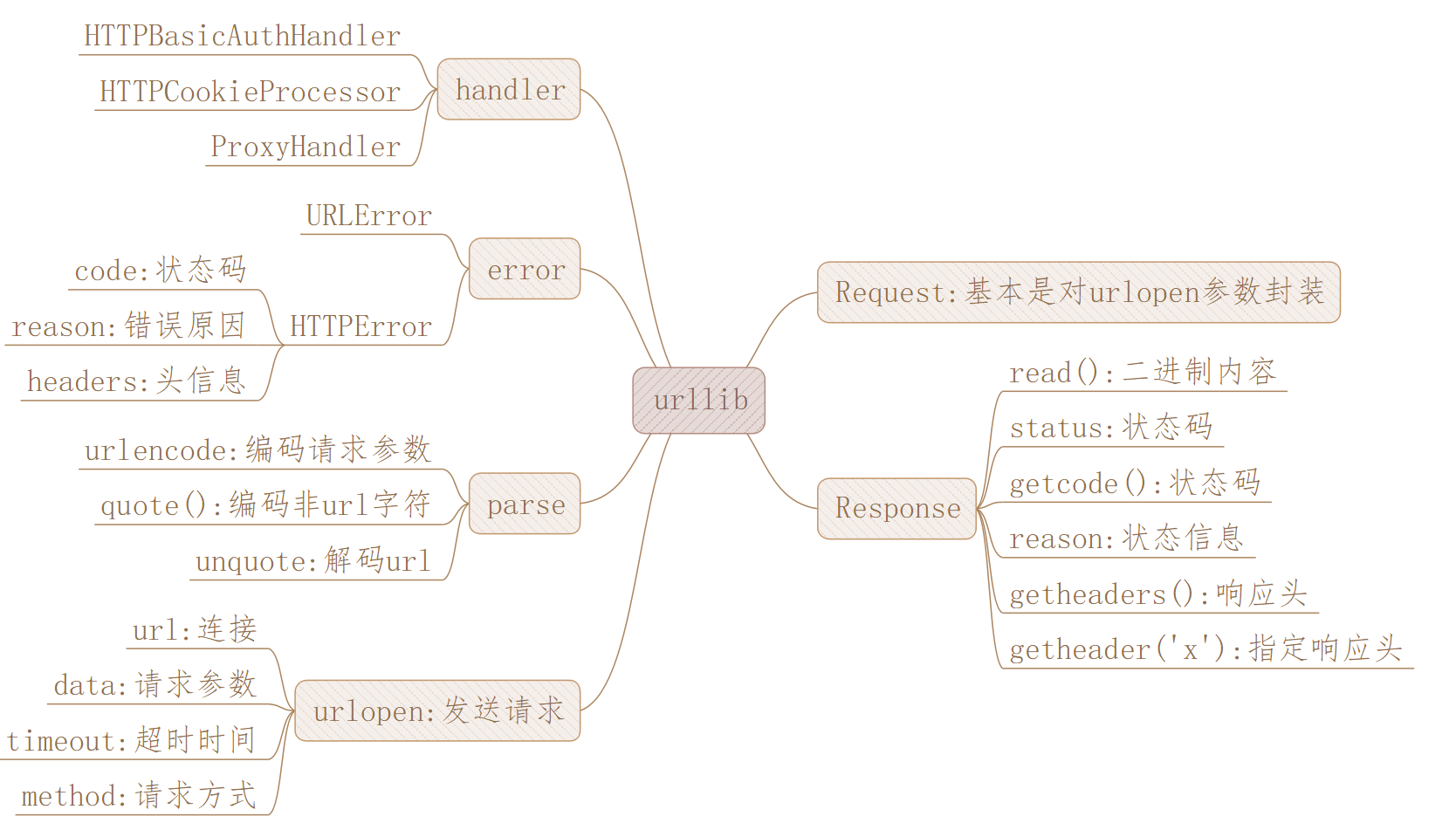
I. urllib, urllib2, urllib3, requests
In the python 2 of the urlib2 room, python 3 merges urllib and urllib2 into the urllib directory, so Python 3 directly uses urllib.
urllib3 is a tripartite library, which provides functions such as connection pool, client SSL/TLS authentication, file code upload, HTTP redirection, gzip and deflate compression coding, HTTP and SOCKS proxy, etc.
Requests is also a three-party library. It relies on urllib3 and makes some encapsulation, so requests are usually used more often.
II. urlopen
from urllib import request,parse response = request.urlopen(r'http://www.baidu.com', timeout=3000) # <class 'http.client.HTTPResponse'> print(type(response)) content = response.read() # <class 'bytes'> print(type(content)) print(content.decode('utf-8')) # Transfer parameters param = parse.urlencode({'id': '2'}) data = bytes(param, encoding='utf8') response = request.urlopen(r'http://www.baidu.com', data=data)
The timeout of urlopen can be set, and the parameter of data can be set.
urlencode is to code parameters as url parameters:
param = parse.urlencode({'id': '2', 'name': 'Chinese'}, encoding='utf-8') # id=2&name=%E4%B8%AD%E6%96%87 print(param) # %E4%B8%AD%E6%96%87 print(parse.quote("Chinese")) print(parse.unquote("%E4%B8%AD%E6%96%87"))
III. Response
| Method or property | Explain |
|---|---|
| read() | Get web content |
| status | HTTP status code, 200 indicates success |
| getcode() | HTTP status code, same as status |
| reason | Status information, ok for success |
| msg | Success is ok |
| getheader('header_name') | Get the specified header |
| getheaders() | Get all header s, tuple list |
| version | Get version information |
| debuglevel | Get debug level |
| closed | Gets whether the object closes the Boolean value |
| geturl() | Get request URL |
| info() | Other corresponding information |
import urllib.request response = urllib.request.urlopen('http://www.baidu.com', timeout=3000) # Get web content print(response.read().decode('utf-8')) # Get the specified header print(response.getheader('Content-Type')) # Get header information by tuple list print(response.getheaders()) # Get version information print(response.version) # Get status code print(response.status) # Get debug level print(response.debuglevel) # Gets whether the object closes the Boolean value print(response.closed) # Get URL print(response.geturl()) # Get HTTP status code print(response.getcode()) # Get msg print(response.msg) # Get status information print(response.reason) # Get additional information print(response.info())
IV. Request
from urllib import request, parse url = 'http://127.0.0.1:8080/test/user' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:70.0) Gecko/20100101 Firefox/70.0' } data = {'id': '1', 'name': 'tim'} params = parse.urlencode(data) byte_params = bytes(params, encoding='utf-8') rst = request.Request(url=url, data=byte_params, headers=headers, method='POST') rst.add_header('Accept', 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8') rst.add_header('Accept-Encoding', 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2') rst.add_header('Accept-Language', 'gzip, deflate, br') response = request.urlopen(rst) print(response.read().decode('utf-8'))
Five, abnormal
The error module of URLError in the urllib library inherits the OSError class. Exceptions generated by the request module can be handled by catching this class. URLError contains an attribute reason to indicate the cause of the error.
HTTPError is a subclass of URLError, which has three attributes: Code for HTTP status code, reason for error reason, and headers for return header information.
from urllib import request,error url = 'http://127.0.0.1:8080/test/user' try: response = request.urlopen(url, timeout=1) except error.HTTPError as e: print(e.reason, e.code, e.headers) print("HTTPError:" + str(type(e))) except error.URLError as e: print(e.reason) print("URLError:" + str(type(e))) else: print('success')
Vi. processing flow of urlib handler
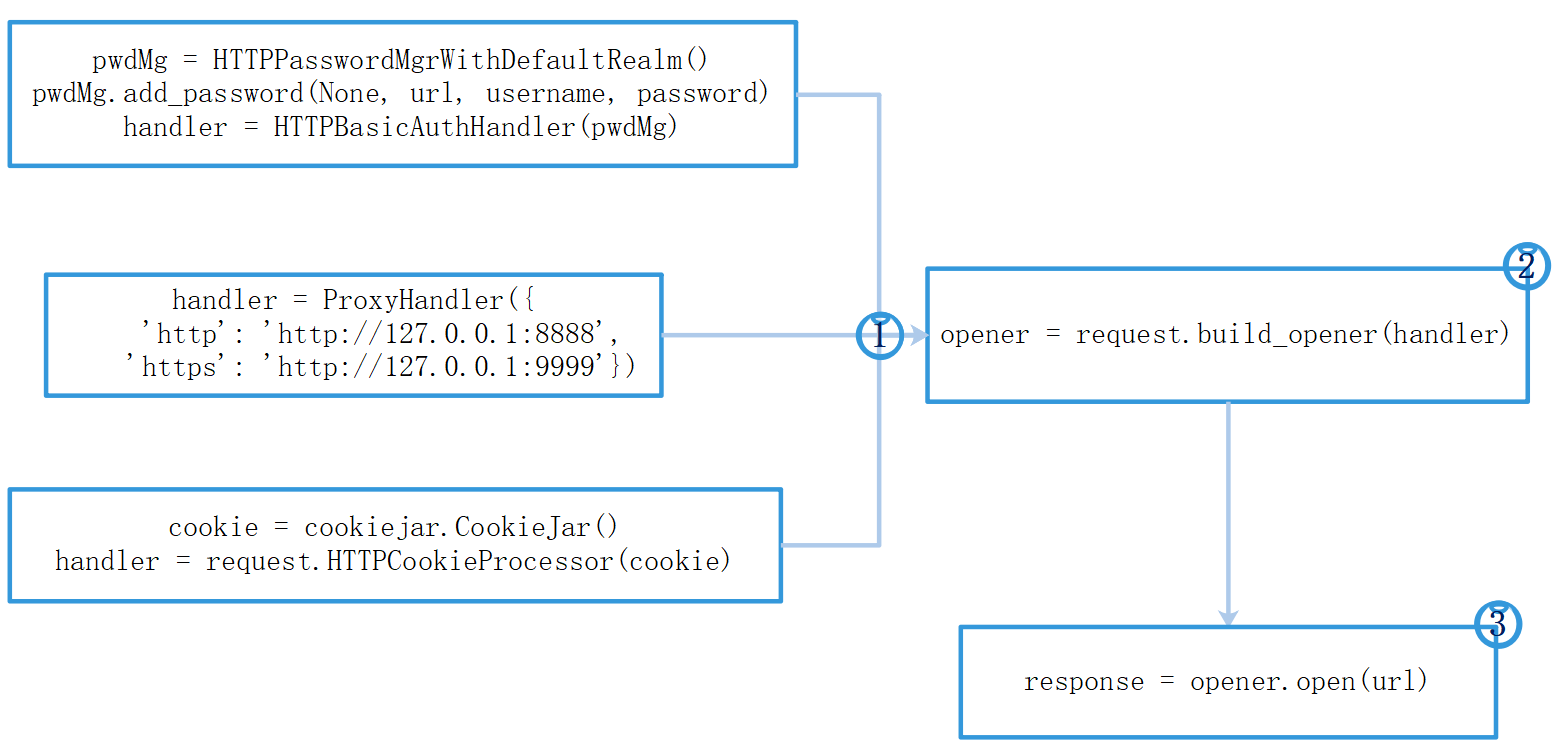
Seven, cookie
7.1 obtaining cookie s
from http import cookiejar from urllib import request url = 'http://127.0.0.1:8080/test/cookie' cookie = cookiejar.CookieJar() handler = request.HTTPCookieProcessor(cookie) opener = request.build_opener(handler) response = opener.open(url) print(response.read().decode('utf-8')) for ck in cookie: print(ck.name + ":" + ck.value)
7.2 cookie storage and reuse
from http import cookiejar from urllib import request url = 'http://127.0.0.1:8080/test/cookie' fielname = r'F:\tmp\cookies.txt' # cookie = cookiejar.MozillaCookieJar(filename=fielname) cookie = cookiejar.LWPCookieJar(filename=fielname) handler = request.HTTPCookieProcessor(cookie) opener = request.build_opener(handler) response = opener.open(url) print(response.read().decode('utf-8')) cookie.save(ignore_discard=True, ignore_expires=True) # cookie = cookiejar.MozillaCookieJar() cookie = cookiejar.LWPCookieJar() cookie.load(fielname, ignore_discard=True, ignore_expires=True) handler = request.HTTPCookieProcessor(cookie) opener = request.build_opener(handler) response = opener.open(url) print(response.read().decode('utf-8'))
7.3 server code
@RequestMapping("/cookie") public String cookie(HttpServletRequest request, HttpServletResponse response, @CookieValue(value = "pyck", required = false,defaultValue = "dfck") String pyck ){ Cookie[] cookies = request.getCookies(); if(cookies != null){ for(Cookie cookie : cookies){ System.out.println(cookie.getName() + " " + cookie.getValue()); } } Cookie cookie=new Cookie("pyck","happy"); response.addCookie(cookie); System.out.println("pyck:" + pyck); return pyck; }
Eight, agent
from urllib.error import URLError from urllib.request import ProxyHandler, build_opener proxy = ProxyHandler({ 'http': 'http://127.0.0.1:7777', 'https': 'http://127.0.0.1:8888' }) opener = build_opener(proxy) try: response=opener.open('https://www.baidu.com') print(response.read().decode('utf-8')) except URLError as e: print(e.reason)
Nine, Auth
auth here refers to HTTPBasicAuth, which is generally implemented by the server. The user password and permission configured directly are not our common login, because we usually log in by ourselves.
However, it is necessary for us to understand http basicauth. Many monitoring components will not log in and register themselves, and will simply use HTTP basicauth provided by the server, such as Tomcat monitoring.
Here's how to use HTTP basicauth in python. First download tomcat, then add tomcat-users.xml in the conf directory under the Tomcat root directory and add it under the Tomcat users node:
<role rolename="admin-gui"/> <role rolename="manager-gui"/> <role rolename="manager-jmx"/> <role rolename="manager-script"/> <role rolename="manager-status"/> <user username="tim" password="123456" roles="admin-gui,manager-gui,manager-jmx,manager-script,manager-status"/>
Execute the startup script in the bin directory of tomcat to start
from urllib.request import HTTPPasswordMgrWithDefaultRealm from urllib.request import HTTPBasicAuthHandler from urllib.request import build_opener from urllib import request, error username = 'tim' password = '123456' url = 'http://localhost:8080/manager/status' pwdMg = HTTPPasswordMgrWithDefaultRealm() pwdMg.add_password(None, url, username, password) auth_handler = HTTPBasicAuthHandler(pwdMg) opener = build_opener(auth_handler) try: response = opener.open(url) html = response.read().decode('utf8') print(html) except error.URLError as e: print(e.reason) # No auth, 401 try: response = request.urlopen(url) except error.HTTPError as e: print(e.reason, e.code, e.headers) else: print('success')
Ten, summary