1. json JavaScript object notation
The JSON module provides an API similar to pickle, which can be represented linearly and is called JavaScript Object Notation (JSON).Unlike pickle, JSON has one advantage: it has multiple language implementations (especially JavaScript).JSON is most widely used for communication between Web servers and clients in RESTAPI, but it can also be used to meet the communication needs of other applications.
1.1 Encoding and decoding simple data types
By default, the encoder understands some of Python's built-in types (str, int, float, list, tuple, dict).
import json data = [{'a': 'A', 'b': (2, 4), 'c': 3.0}] print('DATA:', repr(data)) data_string = json.dumps(data) print('JSON:', data_string)
When encoding values, the repr() output appears to be similar to Python.
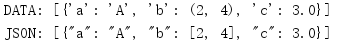
When encoding and decoding again, you may not get the exact same object type.
import json data = [{'a': 'A', 'b': (2, 4), 'c': 3.0}] print('DATA :', data) data_string = json.dumps(data) print('ENCODED:', data_string) decoded = json.loads(data_string) print('DECODED:', decoded) print('ORIGINAL:', type(data[0]['b'])) print('DECODED :', type(decoded[0]['b']))
Specifically, tuples become lists.

1.2 Human Readable and Compact Output
Another advantage of JSON over pickle is that it produces human-readable results.The dumps() function accepts multiple parameters to make the output easier to understand.For example, the sort_keys flag tells the encoder to output the keys of the dictionary in an ordered order instead of a random order.
import json data = [{'a': 'A', 'b': (2, 4), 'c': 3.0}] print('DATA:', repr(data)) unsorted = json.dumps(data) print('JSON:', json.dumps(data)) print('SORT:', json.dumps(data, sort_keys=True)) first = json.dumps(data, sort_keys=True) second = json.dumps(data, sort_keys=True) print('UNSORTED MATCH:', unsorted == first) print('SORTED MATCH :', first == second)
Sorting makes it easier to see the results and also allows you to compare JSON output in tests.
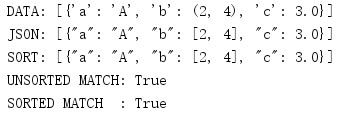
For highly nested data structures, you can also specify an indent value to produce well-formed output.
import json data = [{'a': 'A', 'b': (2, 4), 'c': 3.0}] print('DATA:', repr(data)) print('NORMAL:', json.dumps(data, sort_keys=True)) print('INDENT:', json.dumps(data, sort_keys=True, indent=2))
When indentation is a non-negative integer, the output is more like the output of pprint, with leading spaces at each level in the data structure matching the indentation level.

This verbose output increases the number of bytes required to transfer the equivalent amount of data, so it is often not used in production environments.In fact, you can adjust the settings for separating data in encoded output to make it more compact than the default format.
import json data = [{'a': 'A', 'b': (2, 4), 'c': 3.0}] print('DATA:', repr(data)) print('repr(data) :', len(repr(data))) plain_dump = json.dumps(data) print('dumps(data) :', len(plain_dump)) small_indent = json.dumps(data, indent=2) print('dumps(data, indent=2) :', len(small_indent)) with_separators = json.dumps(data, separators=(',', ':')) print('dumps(data, separators):', len(with_separators))
The separators parameter of dumps() should be a tuple that contains strings that separate items in the list and strings that separate keys and values in the dictionary.The default is (',',':').By removing whitespace, a more compact output can be generated.

1.3 Encoding Dictionary
The JSON format requires that the key of the dictionary be a string.If a dictionary has a non-string type as its key, a TypeError is generated when the dictionary is encoded.One way to get around this limitation is to use the skipkeys parameter to tell the encoder to skip keys that are not strings.
import json data = [{'a': 'A', 'b': (2, 4), 'c': 3.0, ('d',): 'D tuple'}] print('First attempt') try: print(json.dumps(data)) except TypeError as err: print('ERROR:', err) print() print('Second attempt') print(json.dumps(data, skipkeys=True))
This does not produce an exception, but ignores keys that are not strings.
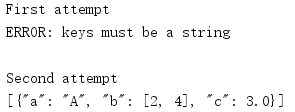
1.4 Handling custom types
So far, all examples have used Python's built-in types because they are supported by json's built-in support.Custom class coding is often required, and there are two ways to do it.Suppose the classes in the following code list need to be coded.
import json
class MyObj: def __init__(self, s): self.s = s def __repr__(self): return '<MyObj({})>'.format(self.s)
A simple way to code MyObj instances is to define a function that converts unknown types to known types.This function does not require specific coding, it simply converts one type of object to another.
import json class MyObj: def __init__(self, s): self.s = s def __repr__(self): return '<MyObj({})>'.format(self.s) obj = MyObj('instance value goes here') print('First attempt') try: print(json.dumps(obj)) except TypeError as err: print('ERROR:', err) def convert_to_builtin_type(obj): print('default(', repr(obj), ')') # Convert objects to a dictionary of their representation d = { '__class__': obj.__class__.__name__, '__module__': obj.__module__, } d.update(obj.__dict__) return d print() print('With default') print(json.dumps(obj, default=convert_to_builtin_type))
In convert_to_builtin_ type(), instances of classes that json does not recognize are converted to dictionaries that contain enough information to recreate objects if a program can access the Python module required for this processing.

To decode the result and create a MyObj() instance, you can associate the decoder with the objecthook parameter of loads(), which allows you to import this class from a module and use it to create an instance.For each dictionary decoded from the incoming data stream, object_hook is called, which provides an opportunity to convert the dictionary to another type of object.The hook function returns the object to be received by the calling application rather than a dictionary.
import json def dict_to_object(d): if '__class__' in d: class_name = d.pop('__class__') module_name = d.pop('__module__') module = __import__(module_name) print('MODULE:', module.__name__) class_ = getattr(module, class_name) print('CLASS:', class_) args = { key: value for key, value in d.items() } print('INSTANCE ARGS:', args) inst = class_(**args) else: inst = d return inst encoded_object = ''' [{"s": "instance value goes here", "__module__": "json_myobj", "__class__": "MyObj"}] ''' myobj_instance = json.loads( encoded_object, object_hook=dict_to_object, ) print(myobj_instance)
Because json converts string values to Unicode objects, they need to be re-encoded as ASCII strings before they can be used as keyword parameters for class constructors.

Built-in types also have similar hook s, such as integers (parse_int), floating-point numbers (parse_float), and constants (parse_constant).
1.5 Encoder and Decoder Classes
In addition to the convenience functions described earlier, the json module also provides classes to complete encoding and decoding.These classes can be used directly to access additional API s to customize their behavior.(
JSONEncoder generates coded data "blocks" using an iterable interface, making it easier to write them to a file or a network socket without having to represent the complete data structure in memory.
import json encoder = json.JSONEncoder() data = [{'a': 'A', 'b': (2, 4), 'c': 3.0}] for part in encoder.iterencode(data): print('PART:', part)
Output is output by logical unit, not by a size value.

The encode() method is essentially equivalent to''.join(encoder.iterencode()) except that additional error checks were made earlier.
To encode any object, you need to override the default() method with an implementation similar to that in convert_to_builtin_type().
import json class MyObj: def __init__(self, s): self.s = s def __repr__(self): return '<MyObj({})>'.format(self.s) class MyEncoder(json.JSONEncoder): def default(self, obj): print('default(', repr(obj), ')') # Convert objects to a dictionary of their representation d = { '__class__': obj.__class__.__name__, '__module__': obj.__module__, } d.update(obj.__dict__) return d obj = MyObj('internal data') print(obj) print(MyEncoder().encode(obj))
The output is the same as that of the previous implementation.
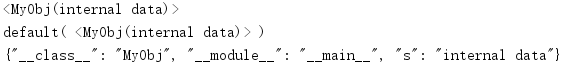
This decodes the text and then converts the dictionary into an object, which requires a little more work, but not much, than the previous implementation.
import json class MyDecoder(json.JSONDecoder): def __init__(self): json.JSONDecoder.__init__( self, object_hook=self.dict_to_object, ) def dict_to_object(self, d): if '__class__' in d: class_name = d.pop('__class__') module_name = d.pop('__module__') module = __import__(module_name) print('MODULE:', module.__name__) class_ = getattr(module, class_name) print('CLASS:', class_) args = { key: value for key, value in d.items() } print('INSTANCE ARGS:', args) inst = class_(**args) else: inst = d return inst encoded_object = ''' [{"s": "instance value goes here", "__module__": "json_myobj", "__class__": "MyObj"}] ''' myobj_instance = MyDecoder().decode(encoded_object) print(myobj_instance)
The output is the same as the previous example.

1.6 Processing streams and files
So far, all examples assume that the coded version of the entire data structure can be completely in memory at once.For large data structures, it may be more appropriate to write the encoding directly to a file-like object.The convenience functions load() and dump() receive a reference similar to a file object for reading and writing.
import io import json data = [{'a': 'A', 'b': (2, 4), 'c': 3.0}] f = io.StringIO() json.dump(data, f) print(f.getvalue())
Similar to the StringIO buffer used in this example, sockets or regular file handles can also be used.
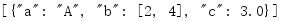
Although not optimized, that is, only a portion of the data is read at a time, the load() function also provides the benefit of encapsulating the logic of generating objects from stream input.
import io import json f = io.StringIO('[{"a": "A", "c": 3.0, "b": [2, 4]}]') print(json.load(f))
Like dump(), any file-like object can be passed to load().
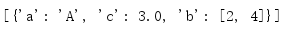
1.7 Mixed Data Stream
JS0NDecoder contains a raw_decode() method that can be used to complete decoding if a data structure is followed by more data, such as JSON data with trailing text.The return value is the object created by decoding the input data and an index of the data indicating where to end the decoding.
import json decoder = json.JSONDecoder() def get_decoded_and_remainder(input_data): obj, end = decoder.raw_decode(input_data) remaining = input_data[end:] return (obj, end, remaining) encoded_object = '[{"a": "A", "c": 3.0, "b": [2, 4]}]' extra_text = 'This text is not JSON.' print('JSON first:') data = ' '.join([encoded_object, extra_text]) obj, end, remaining = get_decoded_and_remainder(data) print('Object :', obj) print('End of parsed input :', end) print('Remaining text :', repr(remaining)) print() print('JSON embedded:') try: data = ' '.join([extra_text, encoded_object, extra_text]) obj, end, remaining = get_decoded_and_remainder(data) except ValueError as err: print('ERROR:', err)
Unfortunately, this only applies when the object appears at the start of the input.

Processing JSON on the 1.8 command line
The json.tool module implements a command line program to reformat JSON data to make it easier to read.
[{"a": "A", "c": 3.0, "b": [2, 4]}]
The input file example.json contains a map with keys in alphabetical order.The first example shows the data reformatted in order, and the second example uses --sort-keys to sort the mapping keys before printing out.
[ { "a": "A", "c": 3.0, "b": [ 2, 4 ] } ]
[ { "a": "A", "b": [ 2, 4 ], "c": 3.0 } ]