catalogue
1, process_request(self, request, spider)
2, process_response(self, request, response, spider)
3, Random request header Middleware
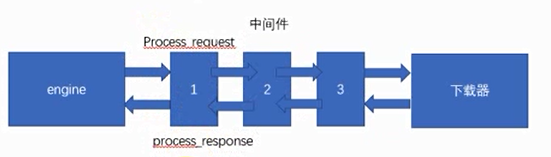
Downloader Middleware
Downloader middleware is the middleware for communication between engine and downloader. In this middleware, we can set up agents and change request headers to achieve the purpose of anti crawler. To write downloader middleware, you can implement two methods in downloader. One is process_request(self, request, spider), which is executed before the request is sent, and process_response(self, request, response, spider). This method is executed before the data is downloaded to the engine.
1, process_request(self, request, spider)
This method is executed by the downloader before sending the request. Generally, random proxy ip can be set in this method
1. Parameters:
Request: the request object that sends the request
Spider: the spider object that sends the request
2. Return value:
Return Node: if return None, scripy will continue to process the request and execute the corresponding methods in other middleware until the appropriate downloader processing function is called.
Return the response object: Scrapy will not call any other process_ The request method will directly return the response object. The process of the activated Middleware_ The response () method will be called when each response returns.
Return request object: no longer use the previous request object to download data, but return data according to the returned request object.
If an exception is thrown in this method, process is called_ Exception method.
2, process_response(self, request, response, spider)
This is the method that the data downloaded by the downloader will be executed in the middle of the engine.
1. Parameters:
Request: request object
Response: the response object to be processed
Spider: spider object
2. Return value:
Return the response object: the new response object will be passed to other middleware and finally to the crawler.
Return request object: the link of the Downloader is cut off, and the returned request will be scheduled by the downloader again.
If an exception is thrown, the errback method of request will be called. If this method is not specified, an exception will be thrown
3, Random request header Middleware
When a crawler frequently visits a page, if the request header remains consistent, it is easy to be found by the server, thus prohibiting the access of the request header. So should we randomly change the request header before visiting this page, so as to avoid the crawler being caught.
Changing the request header randomly can be implemented in the download middleware. Select a request header randomly before sending the request to the server. In this way, you can avoid always using one request header.
The example code is as follows:
setting.py
Open middleware
DOWNLOADER_MIDDLEWARES = {
'useragent.middlewares.UseragentDownloaderMiddleware': 543,
}middlewares.py
Random selection request header
class UseragentDownloaderMiddleware:
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
USER_AGENT = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.101 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.98 Safari/537.36 LBBROWSER",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:82.0) Gecko/20100101 Firefox/82.0",
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko",
]
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
user_agent = random.choice(self.USER_AGENT)
request.headers["User-Agent"] = user_agent
return Nonehttpbin.py
Get the results and print them
import scrapy
class HttpbinSpider(scrapy.Spider):
name = 'httpbin'
allowed_domains = ['httpbin.org']
start_urls = ['http://httpbin.org/user-agent']
def parse(self, response):
ua = response.json()
print("*" * 30)
print(ua)
print("*" * 30)
return scrapy.Request(self.start_urls[0], dont_filter=True)4, ip proxy pool Middleware
1. Purchasing agent
1. Sesame agent https://zhimahttp.com/
2. Sun agency http://http.taiyangruanjian.com/
3. Express agent https://www.kuaidaili.com/
4. Information Agency https://jahttp.zhimaruanjian.com/
Wait
2. Using ip proxy pool
setting.py
Open middleware
ITEM_PIPELINES = {
'useragent.pipelines.UseragentPipeline': 300,
}middlewares.py
Random selection request header
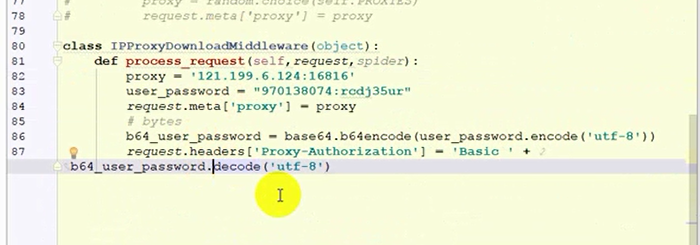
class IpPorxyDownloaderMiddleware(object):
IPPROXY = [
"http://101.18.121.42:9999",
"http://175.44.108.56:9999",
"http://218.88.205.161:3256",
"http://114.99.9.251:1133",
]
def process_request(self, request, spider):
proxy = random.choice(self.IPPROXY)
request.meta['proxy'] = proxyipproxy.py
Get the results and print them
import scrapy
class IpproxySpider(scrapy.Spider):
name = 'ipproxy'
allowed_domains = ['httpbin.org']
start_urls = ['http://httpbin.org/ip']
def parse(self, response):
ua = response.json()
print("*" * 30)
print(ua)
print("*" * 30)
return scrapy.Request(self.start_urls[0], dont_filter=True)
# The free agent is used, which is not very stable and can not get the results3. Exclusive agent pool
Tests using fast agents