1. Data set acquisition
Data from: AI challenger 2017 image description dataset
Baidu online disk: https://pan.baidu.com/s/1g1XaPKzNvOurH9M44p1qrw Extraction code: bag3
Since the original training set is too large, only the verification set AI is used here_ challenger_ caption_ validation_ 20170910.zip, unzip it
2. Text data processing
The data of image Chinese description competition is divided into two parts, one is 30000 pictures, and the other is the corresponding description caption_validation_annotations_20170910.json, the format of each sample is as follows:
[{"url": "http://img5.cache.netease.com/photo/0005/2013-09-25/99LA1FC60B6P0005.jpg", "image_id": "3cd32bef87ed98572bac868418521852ac3f6a70.jpg", "caption": ["\u4e00\u4e2a\u53cc\u81c2\u62ac\u8d77\u7684\u8fd0\u52a8\u5458\u8dea\u5728\u7eff\u8335\u8335\u7684\u7403\u573a\u4e0a", "\u4e00\u4e2a\u62ac\u7740\u53cc\u81c2\u7684\u8fd0\u52a8\u5458\u8dea\u5728\u8db3\u7403\u573a\u4e0a", "\u4e00\u4e2a\u53cc\u624b\u63e1\u62f3\u7684\u7537\u4eba\u8dea\u5728\u7eff\u8335\u8335\u7684\u8db3\u7403\u573a\u4e0a", "\u4e00\u4e2a\u62ac\u8d77\u53cc\u624b\u7684\u7537\u4eba\u8dea\u5728\u78a7\u7eff\u7684\u7403\u573a\u4e0a", "\u4e00\u4e2a\u53cc\u624b\u63e1\u62f3\u7684\u8fd0\u52a8\u5458\u8dea\u5728\u5e73\u5766\u7684\u8fd0\u52a8\u573a\u4e0a"]}, ...

"An athlete with his arms raised knelt on the green pitch", "A player with arms raised knelt on the football field", "A man with clenched hands knelt on the green football field", "A man with his hands up knelt on the Green Court", "A boxer knelt on the flat playground"
Features described above:
- Each sentence varies in length
- The description does not involve too much additional knowledge and should be as objective as possible
- Try to point out the relationship between the characters in the picture as much as possible
here Direct download Pretreatment of manual description, including:
- Chinese jieba participle
- word2ix, filter low-frequency words
- Fill all descriptions to pad_sequence
- Using pack_padded_sequence to speed up the calculation
However, you cannot use caption PTH, because only the original verification set is used here, use the code provided in the book to deal with it:
# coding:utf8
import torch as t
import numpy as np
import json
import jieba
import tqdm
class Config:
annotation_file = r'... your path\ai_challenger_caption_validation_20170910\caption_validation_annotations_20170910.json'
unknown = '</UNKNOWN>'
end = '</EOS>'
padding = '</PAD>'
max_words = 5000
min_appear = 2
save_path = r'... your path\ai_challenger_caption_validation_20170910\caption_2.pth'
# START='</START>'
# MAX_LENS = 25,
def process(**kwargs):
opt = Config()
for k, v in kwargs.items():
setattr(opt, k, v)
with open(opt.annotation_file) as f:
data = json.load(f)
# 8f00f3d0f1008e085ab660e70dffced16a8259f6.jpg -> 0
id2ix = {item['image_id']: ix for ix, item in enumerate(data)}
# 0-> 8f00f3d0f1008e085ab660e70dffced16a8259f6.jpg
ix2id = {ix: id for id, ix in (id2ix.items())}
assert id2ix[ix2id[10]] == 10
captions = [item['caption'] for item in data]
# Word segmentation result
cut_captions = [[list(jieba.cut(ii, cut_all=False)) for ii in item] for item in tqdm.tqdm(captions)]
word_nums = {} # 'happy' - > 10000 (Times)
def update(word_nums):
def fun(word):
word_nums[word] = word_nums.get(word, 0) + 1
return None
return fun
lambda_ = update(word_nums)
_ = {lambda_(word) for sentences in cut_captions for sentence in sentences for word in sentence}
# [(10000,u 'happy'), (9999,u 'happy')...]
word_nums_list = sorted([(num, word) for word, num in word_nums.items()], reverse=True)
#### The above operations are lossless and reversible###############################
# **********Some information will be deleted below******************
# 1. Discard words with insufficient word frequency
# 2. ~ ~ discard words with too long length~~
words = [word[1] for word in word_nums_list[:opt.max_words] if word[0] >= opt.min_appear]
words = [opt.unknown, opt.padding, opt.end] + words
word2ix = {word: ix for ix, word in enumerate(words)}
ix2word = {ix: word for word, ix in word2ix.items()}
assert word2ix[ix2word[123]] == 123
ix_captions = [[[word2ix.get(word, word2ix.get(opt.unknown)) for word in sentence]
for sentence in item]
for item in cut_captions]
readme = u"""
word: Words
ix:index
id:Picture name
caption: Description after participle, through ix2word Original Chinese words can be obtained
"""
results = {
'caption': ix_captions,
'word2ix': word2ix,
'ix2word': ix2word,
'ix2id': ix2id,
'id2ix': id2ix,
'padding': '</PAD>',
'end': '</EOS>',
'readme': readme
}
t.save(results, opt.save_path)
print('save file in %s' % opt.save_path)
def test(ix, ix2=4):
results = t.load(opt.save_path)
ix2word = results['ix2word']
examples = results['caption'][ix][4]
sentences_p = (''.join([ix2word[ii] for ii in examples]))
sentences_r = data[ix]['caption'][ix2]
assert sentences_p == sentences_r, 'test failed'
test(1000)
print('test success')
if __name__ == '__main__':
process()
Got a caption_2.pth file, an example:
import torch data = torch.load(r'... your path\ai_challenger_caption_validation_20170910\caption_2.pth') ix2word = data['ix2word'] ix2id = data['ix2id'] caption = data['caption'] img_ix = 0 img_caption = caption[img_ix] print(ix2id[img_ix]) print(img_caption) sen = img_caption[0] sen = [ix2word[_] for _ in sen] str = ''.join(sen) print(str)
3cd32bef87ed98572bac868418521852ac3f6a70.jpg [[4, 178, 79, 3, 47, 159, 5, 112, 3, 20], [4, 176, 178, 3, 47, 159, 5, 64, 6], [4, 19, 361, 3, 7, 159, 5, 112, 3, 64, 6], [4, 79, 19, 3, 7, 159, 5, 124, 3, 20], [4, 19, 361, 3, 47, 159, 5, 65, 3, 26, 6]] An athlete with his arms raised knelt on the green pitch
3. Image data processing
Using the output of ResNet in the pool layer and the input of the full connection layer, the source code of ResNet is copied and modified here. It is output and returned in the penultimate layer. After modifying ResNet, the characteristics of 30000 pictures are extracted. The code is as follows:
from torchvision.models import resnet50
def new_forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
# x = self.fc(x)
return x
model = resnet50(pretrained=True)
model.forward = lambda x:new_forward(model, x)
model = model.cuda()
import torchvision as tv # General image conversion operation class
from PIL import Image # Pilot library, PIL reads pictures
import numpy as np
import torch
from torch.utils import data
import os
IMAGENET_MEAN = [0.485, 0.456, 0.406]
IMAGENET_STD = [0.229, 0.224, 0.225]
normalize = tv.transforms.Normalize(mean=IMAGENET_MEAN, std=IMAGENET_STD)
transforms = tv.transforms.Compose([
tv.transforms.Resize(256),
tv.transforms.CenterCrop(256),
tv.transforms.ToTensor(),
normalize
])
class Dataset(data.Dataset):
def __init__(self, caption_data_path):
data = torch.load(
'/mnt/Data1/ysc/ai_challenger_caption_validation_20170910/caption_2.pth')
self.ix2id = data['ix2id']
self.imgs = [os.path.join(caption_data_path, self.ix2id[_]) for _ in range(len(self.ix2id))]
def __getitem__(self, item):
x = Image.open(self.imgs[item]).convert('RGB')
x = transforms(x) # ([3, 256, 256])
return x, item
def __len__(self):
return len(self.imgs)
batch_size = 32
dataset = Dataset(
'/mnt/Data1/ysc/ai_challenger_caption_validation_20170910/caption_validation_images_20170910')
dataloader = data.DataLoader(dataset, batch_size=batch_size, shuffle=False)
results = torch.Tensor(len(dataloader.dataset), 2048).fill_(0)
for ii, (imgs, indexs) in enumerate(dataloader):
assert indexs[0] == batch_size * ii
imgs = imgs.cuda()
features = model(imgs)
results[ii * batch_size:(ii + 1) * batch_size] = features.data.cpu()
print(ii * batch_size)
torch.save(results, '/mnt/Data1/ysc/ai_challenger_caption_validation_20170910/results_2048.pth')
Here we get the 1000 dimensional eigenvector results of the original ResNet PTH and modify 2048 dimensional vector results of the last linear layer_ 2048.pth(torch.Size([30000, 2048]))
4. Training
About NP random. Choice function:
np.random.choice(5, 3) >> array([0, 3, 4]) # random
About pack_padded_sequence visible this
The code of beam search can be found in the book Official website
The maximum number of iterations is 5. Check the results every 100 generations:
'One man by one </EOS>' 'A man dressed in </EOS>' 'A man in a shirt is on the playground </EOS>' 'A man in a shirt is on the playground </EOS>' 'A man in a football shirt is playing football on the playground </EOS>' 'Two men in jerseys are playing football on the pitch </EOS>' 'Two men in sportswear are playing football on the field </EOS>' 'A man with a microphone in his right hand performed on the stage </EOS>' 'A man in a hat is performing on the stage </EOS>' 'A man in a hat is singing on the stage </EOS>' 'A man in a hat and a man in a hat stood on the stage </EOS>' 'A man in a hat is performing on the stage </EOS>' 'A woman in a hat is performing on the stage </EOS>' 'A woman in a hat is performing on the stage </EOS>' 'A man in a hat is performing on the stage </EOS>' 'A man in a hat is singing on the stage </EOS>' 'A man in a hat and a man in a hat are standing on the grass </EOS>' 'A man in a hat and a man in a hat performed on the stage </EOS>' 'A man in a hat and a man in a hat are standing on the grass </EOS>' 'A man in a hat and a man in a hat were standing on the road </EOS>' ...
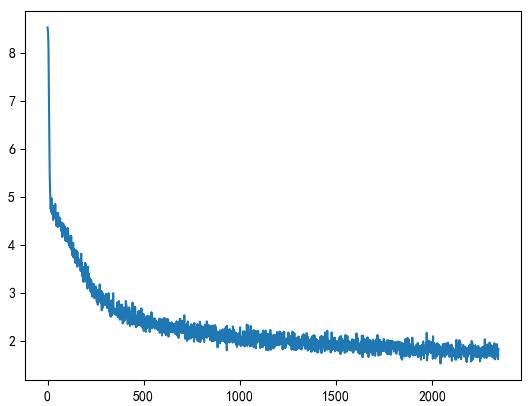
Here, the model is saved for each iteration, and the names are model_0.pth to model_4.pth
Find your own photos here to test:

'A man in a football shirt is playing football on the court </EOS>' 'A man in a black coat and a man in a hat were standing on the road </EOS>' 'A man in a hat is performing on the stage </EOS>' 'A man in a hat and a man in a hat are walking on the road </EOS>' 'A man with a microphone in his right hand was singing on the stage </EOS>'
There is a bug in the result. Modify the maximum number of iterations to 100:
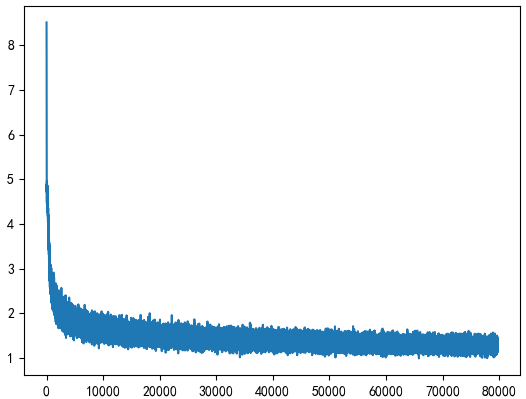
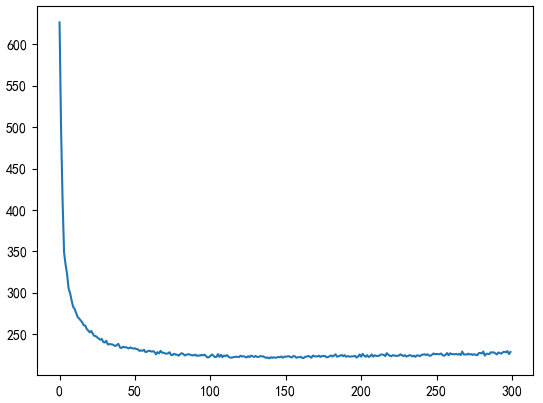
And how to modify the number and number of hidden layers, the results are not very good. It is speculated that the possible reason is that the Beam Search search and its own data set are dirty
The maximum number of iterations is 50:
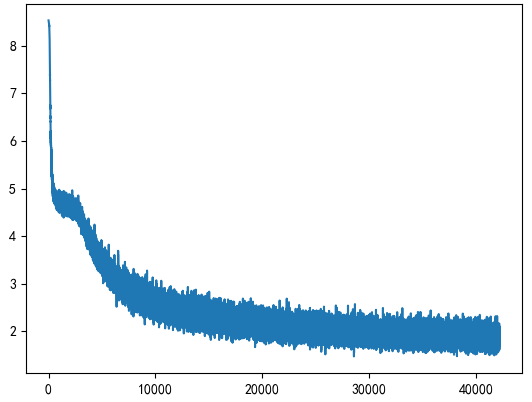

5. All codes
import torch
from torch.utils import data
import numpy as np
import tqdm
from torch.nn.utils.rnn import pack_padded_sequence
from beam_search import CaptionGenerator
from PIL import Image
import torchvision as tv
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
from torchvision.models import resnet50
from torch.utils.data.dataset import random_split
def new_forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
# x = self.fc(x)
return x
model_feature = resnet50(pretrained=True)
model_feature.forward = lambda x:new_forward(model_feature, x)
model_feature = model_feature.cuda()
IMAGENET_MEAN = [0.485, 0.456, 0.406]
IMAGENET_STD = [0.229, 0.224, 0.225]
normalize = tv.transforms.Normalize(mean=IMAGENET_MEAN, std=IMAGENET_STD)
transforms = tv.transforms.Compose([
tv.transforms.Resize(256),
tv.transforms.CenterCrop(256),
tv.transforms.ToTensor(),
normalize
])
class CaptionDataset(data.Dataset):
def __init__(self):
data = torch.load('/mnt/Data1/ysc/ai_challenger_caption_validation_20170910/caption_2.pth')
# ix2word = data['ix2word']
self.ix2id = data['ix2id']
self.caption = data['caption']
word2ix = data['word2ix']
self.padding = word2ix.get(data.get('padding'))
self.end = word2ix.get(data.get('end'))
self.feature = torch.load('/mnt/Data1/ysc/ai_challenger_caption_validation_20170910/results_2048.pth')
def __getitem__(self, item):
img = self.feature[item]
caption = self.caption[item]
rdn_index = np.random.choice(len(caption), 1)[0] # Choose one of the five descriptions at random
caption = caption[rdn_index]
return img, torch.LongTensor(caption), item
def __len__(self):
return len(self.ix2id)
def create_collate_fn(padding, eos, max_length=50):
def collate_fn(img_cap):
"""
Splice multiple samples together to form one batch
Input: list of data,Shape such as
[(img1, cap1, index1), (img2, cap2, index2) ....]
The splicing strategy is as follows:
- batch The description length of each sample is changing, and no word is discarded\
Select the sentence with the longest length and add all sentences pad As long as
- Not long enough</PAD>At the end PAD
- No, START identifier
- If the length is exactly the same as the word, then there is No</EOS>
return:
- imgs(Tensor): batch_sie*2048
- cap_tensor(Tensor): batch_size*max_length (I think it is wrong!)
- lengths(list of int): Count Reg batch_size
- index(list of int): Count Reg batch_size
"""
img_cap.sort(key=lambda p: len(p[1]), reverse=True)
imgs, caps, indexs = zip(*img_cap)
imgs = torch.cat([img.unsqueeze(0) for img in imgs], 0) # batch * 2048
lengths = [min(len(c) + 1, max_length) for c in caps]
batch_length = max(lengths)
cap_tensor = torch.LongTensor(batch_length, len(caps)).fill_(padding)
for i, c in enumerate(caps):
end_cap = lengths[i] - 1
if end_cap < batch_length:
cap_tensor[end_cap, i] = eos
cap_tensor[:end_cap, i].copy_(c[:end_cap])
return (imgs, (cap_tensor, lengths), indexs) # batch * 2048, (max_len * batch, ...), ...
return collate_fn
batch_size = 32
max_epoch = 50
embedding_dim = 64
hidden_size = 64
lr = 1e-4
num_layers = 2
def get_dataloader():
dataset = CaptionDataset()
n_train = int(len(dataset) * 0.9)
split_train, split_valid = random_split(dataset=dataset, lengths=[n_train, len(dataset) - n_train])
train_dataloader = data.DataLoader(split_train, batch_size=batch_size, shuffle=True, num_workers=4,
collate_fn=create_collate_fn(dataset.padding, dataset.end))
valid_dataloader = data.DataLoader(split_valid, batch_size=batch_size, shuffle=True, num_workers=4,
collate_fn=create_collate_fn(dataset.padding, dataset.end))
return train_dataloader, valid_dataloader
class Net(torch.nn.Module):
def __init__(self, word2ix, ix2word):
super(Net,self).__init__()
self.ix2word = ix2word
self.word2ix = word2ix
self.embedding = torch.nn.Embedding(len(word2ix), embedding_dim)
self.fc = torch.nn.Linear(2048, hidden_size)
self.rnn = torch.nn.LSTM(embedding_dim, hidden_size, num_layers=num_layers)
self.classifier = torch.nn.Linear(hidden_size, len(word2ix))
def forward(self, img_feats, captions, lengths):
embeddings = self.embedding(captions) # seq_len * batch * embedding
img_feats = self.fc(img_feats).unsqueeze(0) # img_feats is a 2048 dimensional vector, which is transformed into a 256 dimensional vector through the full connection layer. Like word vectors, 1 * batch * hidden_size
embeddings = torch.cat([img_feats, embeddings], 0) # img_feats is regarded as the word vector of the first word, (1+seq_len) * batch * hidden_size
packed_embeddings = pack_padded_sequence(embeddings, lengths) # Packedsequence, lengths - the effective length of each seq in the batch
outputs, state = self.rnn(packed_embeddings) # seq_ len * batch * (1*256), (1*2) * batch * hidden_ Size, the output of LSTM is used as a feature to classify and predict the sequence number of the next word. Because the input is PackedSequence, the output is also PackedSequence. The first element of PackedSequence is Variable and the second element is batch_sizes, that is, the length of each sample in the batch*
pred = self.classifier(outputs[0])
return pred, state
def generate(self, img, eos_token='</EOS>', beam_size=3, max_caption_length=30, length_normalization_factor=0.0): # The description is generated according to the picture, mainly using the beam search algorithm to get a better description
cap_gen = CaptionGenerator(embedder=self.embedding,
rnn=self.rnn,
classifier=self.classifier,
eos_id=self.word2ix[eos_token],
beam_size=beam_size,
max_caption_length=max_caption_length,
length_normalization_factor=length_normalization_factor)
if next(self.parameters()).is_cuda:
img = img.cuda()
img = img.unsqueeze(0)
img = self.fc(img).unsqueeze(0)
sentences, score = cap_gen.beam_search(img)
sentences = [' '.join([self.ix2word[idx.item()] for idx in sent])
for sent in sentences]
return sentences
def evaluate(dataloader):
model.eval()
total_loss = 0
with torch.no_grad():
for ii, (imgs, (captions, lengths), indexes) in enumerate(dataloader):
imgs = imgs.to(device)
captions = captions.to(device)
input_captions = captions[:-1]
target_captions = pack_padded_sequence(captions, lengths)[0]
score, _ = model(imgs, input_captions, lengths)
loss = criterion(score, target_captions)
total_loss += loss.item()
model.train()
return total_loss
if __name__ == '__main__':
train_dataloader, valid_dataloader = get_dataloader()
_data = torch.load('/mnt/Data1/ysc/ai_challenger_caption_validation_20170910/caption_2.pth')
word2ix, ix2word = _data['word2ix'], _data['ix2word']
# max_loss = float('inf') # 221
max_loss = 263
device = torch.device('cuda')
model = Net(word2ix, ix2word)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
criterion = torch.nn.CrossEntropyLoss()
model.to(device)
losses = []
valid_losses = []
img_path = '/mnt/Data1/ysc/ai_challenger_caption_validation_20170910/123.jpg'
raw_img = Image.open(img_path).convert('RGB')
raw_img = transforms(raw_img) # 3*256*256
img_feature = model_feature(raw_img.cuda().unsqueeze(0))
print(img_feature)
for epoch in range(max_epoch):
for ii, (imgs, (captions, lengths), indexes) in tqdm.tqdm(enumerate(train_dataloader)):
optimizer.zero_grad()
imgs = imgs.to(device)
captions = captions.to(device)
input_captions = captions[:-1]
target_captions = pack_padded_sequence(captions, lengths)[0]
score, _ = model(imgs, input_captions, lengths)
loss = criterion(score, target_captions)
loss.backward()
optimizer.step()
losses.append(loss.item())
if (ii + 1) % 20 == 0: # visualization
# Visual original picture + visual manual description statement
# raw_img = _data['ix2id'][indexes[0]]
# img_path = '/mnt/Data1/ysc/ai_challenger_caption_validation_20170910/caption_validation_images_20170910/' + raw_img
# raw_img = Image.open(img_path).convert('RGB')
# raw_img = tv.transforms.ToTensor()(raw_img)
#
# raw_caption = captions.data[:, 0]
# raw_caption = ''.join([_data['ix2word'][ii.item()] for ii in raw_caption])
#
# results = model.generate(imgs.data[0])
#
# print(img_path, raw_caption, results)
#
#
# print(model.generate(img_feature.squeeze(0)))
tmp = evaluate(valid_dataloader)
valid_losses.append(tmp)
if tmp < max_loss:
max_loss = tmp
torch.save(model.state_dict(),
'/mnt/Data1/ysc/ai_challenger_caption_validation_20170910/model_best.pth')
print(max_loss) # 190 111
plt.figure(1)
plt.plot(losses)
plt.figure(2)
plt.plot(valid_losses)
plt.show()
# model.load_state_dict(torch.load('/mnt/Data1/ysc/ai_challenger_caption_validation_20170910/model_best.pth'))
# print(model.generate(img_feature.squeeze(0)))
6. Summary
The final effect is not very good. It seems that every time I deal with the image, the effect is not very ideal