preface:
from torch.utils.data import Dataset from torch.utils.data import DataLoader import torchvision.transforms as transforms
1. Dataset in torch utils. data
2. It is required for loading text or image data sets, custom data sets, special formats or official data sets. DataLoader in
3,torch.utils.data uses this package for both text and images. For image preprocessing, torchvision Transforms package.
Data preprocessing:
- Data enhancement: the transforms module in torchvision has its own function, which is more practical
- Data preprocessing: transforms in torchvision can also be implemented for us, which can be called directly
data_transforms = {
'train': transforms.Compose([transforms.RandomRotation(45),#Random rotation, random selection between - 45 and 45 degrees
transforms.CenterCrop(224),#Crop from center
transforms.RandomHorizontalFlip(p=0.5),#Random horizontal flip selects a probability
transforms.RandomVerticalFlip(p=0.5),#Random vertical flip
transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1),#Parameter 1 is brightness, parameter 2 is contrast, parameter 3 is saturation and parameter 4 is hue
transforms.RandomGrayscale(p=0.025),#The probability is converted into gray rate, and the three channels are R=G=B
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])#Mean, standard deviation
]),
'valid': transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
Image dataset loading part:
- The difference between several data set loading methods lies in the contents of the file and the location of the label.
- To enable PyTorch to read our own data, we must first understand the mechanism and process of pytroch reading pictures, and then write code according to the process.
Dataset class
PyTorch reads pictures mainly through the dataset class, so let's have a brief look at the dataset class first. Dataset class exists as the base class of all datasets. All datasets need to inherit it, which is similar to the virtual base class in C + +.
The source code is as follows:
class Dataset(object):
"""An abstract class representing a Dataset.
All other datasets should subclass it. All subclasses should override
``__len__``, that provides the size of the dataset, and ``__getitem__``,
supporting integer indexing in range from 0 to len(self) exclusive.
"""
def __getitem__(self, index):
raise NotImplementedError
def __len__(self):
raise NotImplementedError
def __add__(self, other):
return ConcatDataset([self, other])
Here we focus on the getitem function. Getitem receives an index and then returns a batch size image data and label. The index is a list, which is generated by the sampler in the dataloader. Interested parties can learn more about here Loading principle of Dataset and DataLoader.
Such as bitch_ The value of size is 16, which is expressed in pycharm as:
Index={list}<class 'list'>: [4, 135, 113, 34, 47, 140, 87, 0, 59, 33,144, 43, 83, 133, 1, 78]
self={_SingleProcessDataLoaderlter}<torch.utils.data.dataloader._SingleProcessDataLoaderIter object at 0x000001F11BF6A7C8>
1, Custom Dataset loading
To enable PyTorch to read its own data set, it only needs two steps:
- Index image data
- Build Dataset subclass
However, how to make this list? The usual method is to store the path and label information of the picture in a TXT, and then read it from the txt.
The basic process of reading your own data is:
- Make a txt that stores the path and label information of the picture
- Convert this information into a list, and each element of the list corresponds to a sample
- Through the getitem function, read the data and labels, and return the data and labels.
First, index the image data
Is to read the image path, label and save it to txt file.
1) A bunch of pictures of the same category are already in a folder. You can use the following method to generate a txt file.
reference resources: How to generate with picture name and label in python txt file (code)
2) Labels and picture labels are in csv files. You can use the following methods.
pytorch custom dataset loading (label in csv file)
Then build a Dataset subclass
from PIL import Image
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self, txt_path, transform = None, target_transform = None):
fh = open(txt_path, 'r') #Read the image path and label of the produced txt file to imgs
imgs = []
for line in fh:
line = line.rstrip()
words = line.split()
imgs.append((words[0], int(words[1])))
self.imgs = imgs
self.transform = transform
self.target_transform = target_transform
def __getitem__(self, index):
fn, label = self.imgs[index] #self.imgs is a list, self An element of IMGs is a str, which contains the image path and image label. These information are read from the txt file in the init function
# fn is a picture path
img = Image.open(fn).convert('RGB') #Using Image Open reads the picture, img type is Image, mode = "RGB"
if self.transform is not None:
img = self.transform(img)
return img, label
def __len__(self):
return len(self.imgs)
- Note that the initialization in the Dataset class will also initialize transform. Transform is a composite type, and there is a list in it. In the list, various operations for image processing will be defined. Operations such as subtracting mean value, dividing standard deviation, random clipping, rotation, flip, affine transformation and so on can be set.
- Here we need to know that after a picture is read in, it will go through data processing (data enhancement) and finally become the input data of the model. Here is one thing as like as two peas. It is important to note that PyTorch's data enhancement is to process the original image and not generate a new picture, but to "cover" the original image. When using randomcrop and other random operations, each epoch input image will hardly be the same as the original image, which achieves the function of sample diversity.
Finally, the data loader can be loaded
- When the custom Dataset is built, the rest of the operation is left to the DataLoader. In the DataLoader, the getiterm function in Mydataset will be triggered to read the data and labels of a batch size picture and return it. (see the clear underlying logic) The blog )As the real input of the model.
- Finally, like the following, after handling the above two steps, it is very simple to get the data and hand it over to the DataLoader.
train_data = MyDataset(txt='../gender/train1.txt',type = "train", transform=transform_train) train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, sampler=train_sampler)
2, Loading of image classification data set with ImageFolder in torchvision
1,data_ All image preprocessing operations are specified in transforms
2. ImageFolder assumes that all files are saved in folders. Pictures of the same category are stored under each folder. The name of the folder is the name of the category.
Still make the data source first
For example, do another project, flower category classification. His data set is shown in the figure below. That is, the same flower is in a folder, and the name of the folder is the label category.

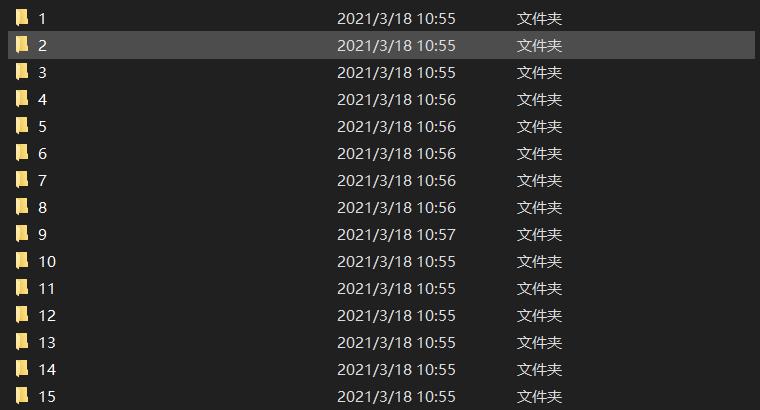
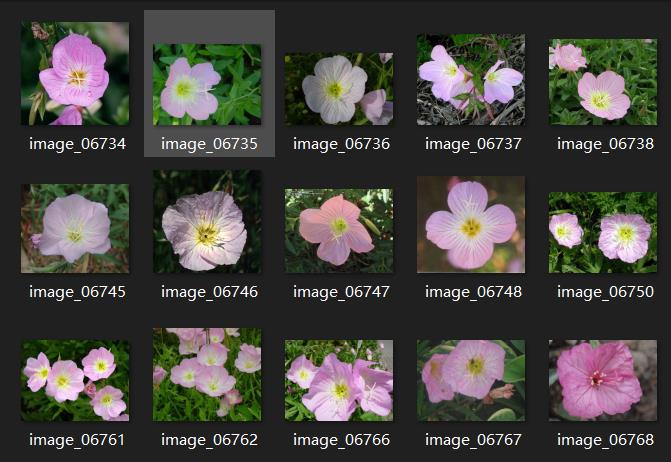
Then use the ImageFolder class in torchvision
As shown in the following code, ImageFolder has written datasets. Like handwritten digital datasets, the init, getitem and len magic functions in the datasets have been implemented. As long as the format of the saved dataset meets the requirements, it can be used directly.
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in ['train', 'valid']}
The above code is the train and valid data sets of flower classification items
The official answer to datasets is:
All datasets are subclasses of torch.utils.data.Dataset i.e, they have getitem and len methods implemented Hence, they can all be passed to a torch.utils.data.DataLoader which can load multiple samples in parallel using torch.multiprocessing workers.
There are many more All datasets here, such as ImageNet, which can be viewed on the official website of pytorch.
Finally, load the data loader
Use the following.
imagenet_data = torchvision.datasets.ImageNet('path/to/imagenet_root/')
data_loader = torch.utils.data.DataLoader(imagenet_data,
batch_size=4,
shuffle=True,
num_workers=args.nThreads)
3, Processing and loading of torch's own image classification data set
For example, handwritten digits, you can check the specific data sets on the official website, and all of them have their own corresponding data sets.
import torch
from torchvision import datasets, transforms
import helper
import matplotlib.pyplot as plt
import numpy
# Define a transform to normalize the data
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))],)
# Download and load the training data
trainset = datasets.FashionMNIST('F_MNIST_data/', download=True, train=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
# Download and load the test data
testset = datasets.FashionMNIST('F_MNIST_data/', download=True, train=False, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=True)