1. Purpose of using data loader in the model
In the previous linear regression model, we use very little data, so we directly put all the data into the model. However, in deep learning, the amount of data is usually very large. With such a large amount of data, it is impossible to carry out forward calculation and back propagation in the model at one time. Often, we will randomly disrupt the order of the whole data, process the data into batch es, and preprocess the data at the same time.
Therefore, the next step is to introduce the data loading method in pytorch.
2. Dataset class
2.1 introduction to dataset base class:
The base class of data set torch. Is provided in torch utils. data. Dataset, which inherits this base class, enables us to load data very quickly.
torch. utils. data. The source code of dataset is as follows:
from torch.utils.data import Dataset class Dataset(object): def __getitem__(self, index): raise NotImplementedError def __len__(se1f): raise NotImp lementedError def __add__(se1f, other): return ConcatDataset([self, other])
It can be seen that we need to inherit the Dataset class in the custom Dataset class, and we also need to implement two methods:
- __ 1en__ Method, which can obtain the number of elements through the global len() method;
- __ getitem__ Method, which can obtain data by passing in the index, for example, obtain the second index through dataset[i] i i i pieces of data.
2.2 data loading cases:
Here is an example to see how to use Dataset to load data:
Data source: my data is the temperature data of Gansu Province, which is text data. You can find the data at will and practice.
Read the data using pandas, and then implement the custom dataset class, which is actually the implementation of the above__ 1en__ Methods and__ getitem__ Method, the following is the code:
from torch.utils.data import Dataset, DataLoader
import torch
import pandas as pd
data_path = r"./data/wendu_8_4_9_2.csv"
# Complete dataset class
class MyDataset(Dataset):
def __init__(self):
self.data = pd.read_csv(data_path).values # DataFrame type, which is converted into numpy type through values
def __getitem__(self, index):
"""
Must be achieved, the role is:Get a piece of data corresponding to the index
:param index:
:return:
"""
return MyDataset.to_tensor(self.data[index])
def __len__(self):
"""
It must be implemented to get the size of the data set
:return:
"""
return len(self.data)
@staticmethod
def to_tensor(data):
"""
take ndarray convert to tensor
:param data:
:return:
"""
return torch.from_numpy(data)
if __name__ == "__main__":
data = MyDataset() # Instantiate object
print(data[0]) # Take the first data
print(len(data)) # Get length
3. Iterative data set
The above method can be used to read data, but there are still many contents that have not been realized:
- Batching the data
- Shuffling the data
- Loading data in parallel using multithreading and multiprocessing
In PyTorch, torch utils. data. Dataloader provides all of the above methods
DataLoader usage example:
from torch.utils.data import DataLoader
import torch
import pandas as pd
data = MyDataset() # Instantiate the object and the previously customized dataset class
# DataLoader is in this line. In fact, it can be called directly
data_loader = DataLoader(dataset=data, batch_size=2, shuffle=True, num_workers=2)
if __name__ == "__main__":
for i in data_loader: # Can iterate
print(i)
print('*'*50)
The meaning of parameters:
- 1. Dataset: an instance of a dataset defined in advance;
- 2,batch_size: the batch size of the incoming data, usually 32, 64, 128, 256 '
- 3. shuffle: bool type, indicating whether to disrupt the data in advance each time data is obtained;
- 4,num_workers: the number of threads that load data.
- 5,drop_last: bool type. If it is true, it means that the last data is less than a batch and is deleted
The results returned by the data iterator are as follows:
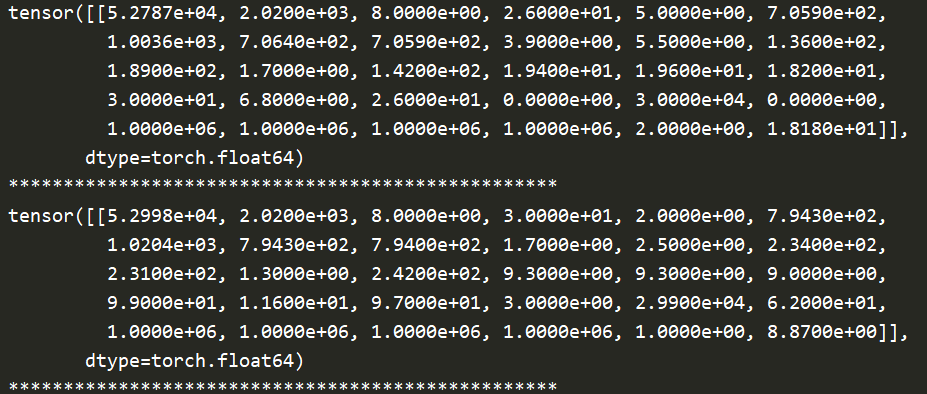
One thing to note here is that if we get the length of our custom dataset class MyDataset object data and DataLoader object data at the same time_ According to the length of the loader, we will find:
data_ The length of loader is the length of data divided by batch_size. As shown below, I will batch_ If size is set to 2, it is as follows:
print(len(data)) print(len(data_loader)) # Output: 53280 26640
At the same time, it should be noted that if the division is not complete, it will be rounded up, that is, if our batch_zize=16, but there is only one piece of data in the end. This one is regarded as a batch, which is the output of len(data_loader).
Then we can feed the data into our model.
If useful, welcome to praise, if there is any mistake, please correct, thank you!!!