PyTorch multi card distributed training DistributedDataParallel
catalogue
PyTorch multi card distributed training DistributedDataParallel
(1) Single process multi GPU training mode: DP mode
(2) Multi process multi GPU training mode: DDP mode
2. Pytoch distributed training method
3. Python base trainer (PBT) distributed training tool
4.Example: build your own classification Pipeline
1.DP mode and DP mode
There are two ways of multi card training for Pytorch, one is single process multi GPUs, the other is multi processes multi GPUs
(1) Single process multi GPU training mode: DP mode
Pytoch passed NN Dataparallel can realize the multi card training model (DP mode for short), which is the multi card parallel mechanism of single process multi GPUs. In this parallel mode, parallel multi cards are controlled by one process. Its disadvantages are as follows:
- Although DataLoader can specify num_worker, increase the number of threads responsible for loading data, but the resources of threads are limited by the parent process, and due to the GIL mechanism of python, it can not take advantage of the parallelism of many cores
- The initialization and broadcast process of the model in gpu group depends on the serial operation of a single process
- DP mode is equivalent to combining multiple GPU cards into one card for training
Although DataParallel is easier to use (simply wrapping a single GPU model), since a process is used to calculate the model weight and then distribute it to each GPU during each batch, communication quickly becomes a bottleneck and GPU utilization is usually low. And, NN DataParallel requires all GPUs to be on the same node (distributed is not supported).
(2) Multi process multi GPU training mode: DDP mode
Pytoch passed NN parallel. Distributeddataparallel can realize multi process and multi card training model (also known as DDP mode). The characteristics / advantages of this multi card parallel mechanism are as follows:
- One GPU per process (of course, you can let each process control multiple GPUs, but this is obviously slower than having one GPU per process)
- Make full use of the advantages of multi-core parallelism to load data
- The initialization process of the model in the gpu group is scheduled by their own processes
- The code can seamlessly switch between single machine multi card and multi machine multi card training, because at this time, single machine single card has become a special case of single machine multi card / multi machine multi card parallel
- GPUs can all be on the same node or distributed on multiple nodes. Each process performs the same task, and each process communicates with all other processes. Processes or GPUs only transfer gradients, so network communication is no longer a bottleneck.
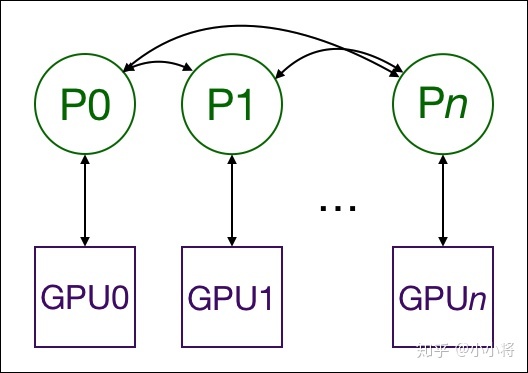
During the training, each process loads batch data from disk and transfers them to its GPU. Each GPU has its own forward process, and then gradient all reduce between GPUs. The gradient of each layer does not depend on the previous layer, so the all reduce and backward processes of the gradient are calculated at the same time to further alleviate the network bottleneck. At the end of the backward process, each node obtains the average gradient, so that the model parameters remain synchronized.
This requires multiple processes, even multiple processes on multiple nodes to achieve synchronization and communication. Pytoch through distributed init_ process_ Group function to achieve this. He needs to know the location of process 0 so that all processes can be synchronized and the expected total number of processes. Each process needs to know the total number of processes, their order in the process, and which GPU to use. The total number of processes is usually called world_size.
Pytorch provides NN utils. data. Distributedsampler to segment data for each process to ensure that the training data does not overlap.
nn.DataParallel and NN The main differences of distributedataparallel can be summarized as follows:
- Distributed DataParallel supports model parallelism, but DataParallel does not, which means that if the model is too large and the single card video memory is insufficient, the former can only be used;
- DataParallel is single process and multi-threaded, which is only used for single machine, while distributed DataParallel is multi process, which is suitable for single machine and multi machine, and truly realizes distributed training;
- The training of distributed DataParallel is more efficient, because each process is an independent Python interpreter to avoid GIL problems, and the communication cost is low, and its training speed is faster. Basically, DataParallel has been abandoned;
- It must be noted that each process in the distributed dataparallel has an independent optimizer to execute its own update process, but the gradient is transmitted to each process through communication, and all execution contents are the same;
In addition to the implementation of distributed training framework, tornet should not only support the speed of tornow, but also support the implementation of distributed training framework.
reference material: PyTorch distributed training concise tutorial - Zhihu
2. Pytoch distributed training method
Distributed training is generally divided into data parallel and model parallel. The implementation steps of Pytorch distributed training can be briefly described as follows:
- First in NN Dataparallel (i.e. under DP mode) realizes multi card loading data, trains the model and debugs successfully; This step is to ensure that your training process is normal and BUG free. Then you can start magic change
- The data of the distributed sampler is parallel_ utils. distributed. DistributedSampler
- Model parallelism (distributed): torch nn. parallel. Distributeddataparallel replaces torch nn. DataParallel
- In order to use distributed dataparallel, you need to initialize the inter process communication environment first, torch distributed. init_ process_ group()
- In order to solve the problem of example overlap between sub Mini batch loaded into each worker/gpu in parallel training, you can also cooperate with {torch utils. data. distributed. Using distributedsampler
- In order to match the process with gpu one by one, we use torch at the beginning of the program cuda. set_ Device set target device
- (optional) in order to make each worker/gpu have a consistent initial value, use torch. At the beginning of the program manual_ Seed and torch cuda. manual_ Seed to initialize random number seeds
Therefore, the code structure is as follows:
# filename: distributed_example.py
# import some module
...
...
parser = argparse.Argument()
parser.add_argument('--init_method', defalut='env://', type=str)
parser.add_argument('--local_rank', type=int, default=0)
args = parser.parse()
import os
# Set master information and NIC
# NIC for communication
os.environ['NCCL_SOCKET_IFNAME'] = 'xxxx'
# set master node address
# recommend setting to ib NIC to gain bigger communication bandwidth
os.environ['MASTER_ADDR'] = '192.168.xx.xx'
# set master node port
# **caution**: avoid port conflict
os.environ['MASTER_PORT'] = '1234'
def main():
# step 1
# set random seed
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
# step 2
# set target device
torch.cuda.set_device(args.local_rank)
# step 3
# initialize process group
# use nccl backend to speedup gpu communication
torch.distributed.init_process_group(backend='nccl', init_method=args.init_method)
...
...
# step 4
# set distributed sampler
# the same, you can set distributed sampler for validation set
train_sampler = torch.utils.data.distributed.DistributedSampler(
dataset_train)
train_loader = torch.utils.data.DataLoader(
dataset_train, batch_size=BATCH_SIZE, sampler=train_sampler, pin_memory=PIN_MEMORY,
num_workers=NUM_WORKERS
)
...
...
# step 5
# initialize model
model = resnet50()
model.cuda()
# step 6
# wrap model with distributeddataparallel
# map device with model process, and we bind process n with gpu n(n=0,1,2,3...) by default.
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank], output_device=args.local_rank)
...
...
for epoch in range(epochs):
# step 7
# update sampler with epoch
train_sampler.set_epoch(epoch)
# then do whatever you want to do, just like a single device/gpu training program
...
...be careful:
Because the program starts with torch cuda. set_ Device () specifies the target device, so if any subsequent operation involves moving the data and model to the gpu, it needs to be changed to model cuda(),inputs.cuda(), which will correctly copy the object to the corresponding CUDA device.
If you insist on using the to operation, make sure XX cuda:n in to ('cuda:n ') matches the target device.
Start the training script in multi process mode
Of course you can use python distributed_example.py to start the training script, but it can't trigger multiple processes. pytorch provides a launch tool for multi process startup scripts, so the correct startup method is:
python -m torch.distributed.launch --nnodes=<nodes> --nproc_per_node=<process per node> --node_rank=<rank of current node>\
distributed_example.py --arg1 --arg2 and all other arguments of your trainning scriptParameter Description:
- nnodes: Specifies the number of nodes involved in the calculation. The default value is 1. It can not be specified in single machine multi card training
- nproc_per_node: Specifies the number of processes to be started in each node. Since processes correspond to GPUs one by one, the value here cannot be greater than the number of GPUs that can be used in the system
- node_rank: Specifies the serial number of the current node in the whole system, increasing from 0. It should be noted that in multi machine and multi card training, node_ The node with rank = = 0 represents the master, so the node_ The node with rank = = 0 must be master_ The node where addr is located, otherwise the communication between multiple cards cannot establish the connection correctly.
To be honest, the [method of upgrading from DP mode to DDP] looks simple and has few steps, but there are still many areas that need to be optimized to run;
In this multi process training method, each process needs to be assigned a card for training, which makes it complicated for you to save the model, print the Log and test data. For example, multiple processes will print the same Log; It is generally recommended that you define a main process and print logs, save models, test data and other operations in the main process, so as to avoid the above problems.
Is there a simple way to quickly realize the distributed training of Pytorch
Yes, today I will introduce a distributed training tool of pytoch integrated by myself: pytoch base trainer. Based on this tool, you can simply configure it to realize DP or DDP mode training without paying attention to various complex processes such as inter process communication and port setting.
3. Python base trainer (PBT) distributed training tool
(1) Tool introduction
Considering that the deep learning training process has a set of agreed and popular processes, I have developed a set of basic training library: pytoch base trainer (PBT) with reference to Keras; This is a basic training library developed based on pytoch, which supports the following features:
- Support multi card training (DP mode) and distributed multi card training (DDP mode). Refer to build_model_parallel
- Support argparse command line to specify parameters and config Yaml profile
- Support optimal model saving ModelCheckpoint
- Support custom Callback function Callback
- Support NNI model pruning (L1 / L2 pruner, fpgm pruner, slim pruner)_ pruning
- Very light and easy to install
Blog introduction:
 https://panjinquan.blog.csdn.net/article/details/122662902
https://panjinquan.blog.csdn.net/article/details/122662902 https://github.com/PanJinquan/Pytorch-Base-Trainer
https://github.com/PanJinquan/Pytorch-Base-Trainer(2) Installation
- Source installation
git clone https://github.com/PanJinquan/Pytorch-Base-Trainer cd Pytorch-Base-Trainer bash setup.sh #pip install dist/basetrainer-*.*.*.tar.gz
- pip installation
pip install basetrainer
# Linux or macOS python3 -m pip install --upgrade nni # Windows python -m pip install --upgrade nni
(3) Method of use
You can refer to the usage method of basetrainer example.py , build your own trainer through the following steps:
- Step 1: create a new class ClassificationTrainer and inherit the trainer EngineTrainer
- Step 2: implementation interface
def build_train_loader(self, cfg, **kwargs):
"""Define training data"""
raise NotImplementedError("build_train_loader not implemented!")
def build_test_loader(self, cfg, **kwargs):
"""Define test data"""
raise NotImplementedError("build_test_loader not implemented!")
def build_model(self, cfg, **kwargs):
"""Scheduled training model"""
raise NotImplementedError("build_model not implemented!")
def build_optimizer(self, cfg, **kwargs):
"""Optimizer definition"""
raise NotImplementedError("build_optimizer not implemented!")
def build_criterion(self, cfg, **kwargs):
"""Define loss function"""
raise NotImplementedError("build_criterion not implemented!")
def build_callbacks(self, cfg, **kwargs):
"""Define callback function"""
raise NotImplementedError("build_callbacks not implemented!")
step3: Call in initialization build
def __init__(self, cfg):
super(ClassificationTrainer, self).__init__(cfg)
...
self.build(cfg)
...
step4: instantiation ClassificationTrainer,And use launch Start distributed training
def main(cfg):
t = ClassificationTrainer(cfg)
return t.run()
if __name__ == "__main__":
parser = get_parser()
args = parser.parse_args()
cfg = setup_config.parser_config(args)
launch(main,
num_gpus_per_machine=len(cfg.gpu_id),
dist_url="tcp://127.0.0.1:28661",
num_machines=1,
machine_rank=0,
distributed=cfg.distributed,
args=(cfg,))4.Example: build your own classification Pipeline
- You can refer to the usage method of basetrainer example.py
# Single process multi card training python example.py --gpu_id 0 1 # Use command line arguments python example.py --config_file configs/config.yaml # Using yaml profiles # Multi process multi card training (distributed training) python example.py --config_file configs/config.yaml --distributed # Using yaml profiles
- The backbone s supported by the target are: RESNET [18,34,50101], mobilenet_ V2, etc., see backbone Other backbone s can be customized and added
- Training parameters can be specified in two ways: (1) through argparse command line (2) through config.yaml Configuration file. When there are parameters with the same name, the configuration file is the default value
| parameter | type | reference value | explain |
|---|---|---|---|
| train_data | str, list | - | Training data file, which can support multiple files |
| test_data | str, list | - | Test data file, which can support multiple files |
| work_dir | str | work_space | Training output workspace |
| net_type | str | resnet18 | backbone type, {resnet,resnest,mobilenet_v2,...} |
| input_size | list | [128,128] | Model input size [W,H] |
| batch_size | int | 32 | batch size |
| lr | float | 0.1 | Initial learning rate |
| optim_type | str | SGD | Optimizer, {SGD,Adam} |
| loss_type | str | CELoss | loss function |
| scheduler | str | multi-step | Learning rate adjustment strategy, {multi step, cosine} |
| milestones | list | [30,80,100] | For nodes with reduced learning rate, only scheduler = multi step is effective |
| momentum | float | 0.9 | SGD momentum factor |
| num_epochs | int | 120 | Number of cycle training |
| num_warn_up | int | 3 | warn_ Times of up |
| num_workers | int | 12 | Number of DataLoader open threads |
| weight_decay | float | 5e-4 | Weight attenuation coefficient |
| gpu_id | list | [ 0 ] | Specify the GPU card number of training, and you can specify multiple |
| log_freq | in | 20 | Frequency of displaying LOG information |
| finetune | str | model.pth | finetune's model |
| use_prune | bool | True | Model pruning |
| progress | bool | True | Show progress bar |
| distributed | bool | False | Use distributed training |
A simple classification example is as follows:
# -*-coding: utf-8 -*-
"""
@Author : panjq
@E-mail : pan_jinquan@163.com
@Date : 2021-07-28 22:09:32
"""
import os
import sys
sys.path.append(os.getcwd())
import argparse
import basetrainer
from torchvision import transforms
from torchvision.datasets import ImageFolder
from basetrainer.engine import trainer
from basetrainer.engine.launch import launch
from basetrainer.criterion.criterion import get_criterion
from basetrainer.metric import accuracy_recorder
from basetrainer.callbacks import log_history, model_checkpoint, losses_recorder, multi_losses_recorder
from basetrainer.scheduler import build_scheduler
from basetrainer.optimizer.build_optimizer import get_optimizer
from basetrainer.utils import log, file_utils, setup_config, torch_tools
from basetrainer.models import build_models
print(basetrainer.__version__)
class ClassificationTrainer(trainer.EngineTrainer):
""" Training Pipeline """
def __init__(self, cfg):
super(ClassificationTrainer, self).__init__(cfg)
torch_tools.set_env_random_seed()
cfg.model_root = os.path.join(cfg.work_dir, "model")
cfg.log_root = os.path.join(cfg.work_dir, "log")
if self.is_main_process:
file_utils.create_dir(cfg.work_dir)
file_utils.create_dir(cfg.model_root)
file_utils.create_dir(cfg.log_root)
file_utils.copy_file_to_dir(cfg.config_file, cfg.work_dir)
setup_config.save_config(cfg, os.path.join(cfg.work_dir, "setup_config.yaml"))
self.logger = log.set_logger(level="debug",
logfile=os.path.join(cfg.log_root, "train.log"),
is_main_process=self.is_main_process)
# build project
self.build(cfg)
self.logger.info("=" * 60)
self.logger.info("work_dir :{}".format(cfg.work_dir))
self.logger.info("config_file :{}".format(cfg.config_file))
self.logger.info("gpu_id :{}".format(cfg.gpu_id))
self.logger.info("main device :{}".format(self.device))
self.logger.info("num_samples(train):{}".format(self.num_samples))
self.logger.info("num_classes :{}".format(cfg.num_classes))
self.logger.info("mean_num :{}".format(self.num_samples / cfg.num_classes))
self.logger.info("=" * 60)
def build_optimizer(self, cfg, **kwargs):
"""build_optimizer"""
self.logger.info("build_optimizer")
self.logger.info("optim_type:{},init_lr:{},weight_decay:{}".format(cfg.optim_type, cfg.lr, cfg.weight_decay))
optimizer = get_optimizer(self.model,
optim_type=cfg.optim_type,
lr=cfg.lr,
momentum=cfg.momentum,
weight_decay=cfg.weight_decay)
return optimizer
def build_criterion(self, cfg, **kwargs):
"""build_criterion"""
self.logger.info("build_criterion,loss_type:{},num_classes:{}".format(cfg.loss_type, cfg.num_classes))
criterion = get_criterion(cfg.loss_type, cfg.num_classes, device=self.device)
return criterion
def build_train_loader(self, cfg, **kwargs):
"""build_train_loader"""
self.logger.info("build_train_loader,input_size:{}".format(cfg.input_size))
transform = transforms.Compose([
transforms.Resize([int(128 * cfg.input_size[1] / 112), int(128 * cfg.input_size[0] / 112)]),
transforms.RandomHorizontalFlip(),
transforms.RandomCrop([cfg.input_size[1], cfg.input_size[0]]),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
])
dataset = ImageFolder(root=cfg.train_data, transform=transform)
cfg.num_classes = len(dataset.classes)
cfg.classes = dataset.classes
loader = self.build_dataloader(dataset, cfg.batch_size, cfg.num_workers, phase="train",
shuffle=True, pin_memory=False, drop_last=True, distributed=cfg.distributed)
return loader
def build_test_loader(self, cfg, **kwargs):
"""build_test_loader"""
self.logger.info("build_test_loader,input_size:{}".format(cfg.input_size))
transform = transforms.Compose([
transforms.Resize([int(128 * cfg.input_size[1] / 112), int(128 * cfg.input_size[0] / 112)]),
transforms.CenterCrop([cfg.input_size[1], cfg.input_size[0]]),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
])
dataset = ImageFolder(root=cfg.train_data, transform=transform)
loader = self.build_dataloader(dataset, cfg.batch_size, cfg.num_workers, phase="test",
shuffle=False, pin_memory=False, drop_last=False, distributed=False)
return loader
def build_model(self, cfg, **kwargs):
"""build_model"""
self.logger.info("build_model,net_type:{}".format(cfg.net_type))
model = build_models.get_models(net_type=cfg.net_type, input_size=cfg.input_size,
num_classes=cfg.num_classes, pretrained=True)
if cfg.finetune:
self.logger.info("finetune:{}".format(cfg.finetune))
state_dict = torch_tools.load_state_dict(cfg.finetune)
model.load_state_dict(state_dict)
if cfg.use_prune:
from basetrainer.pruning import nni_pruning
sparsity = 0.2
self.logger.info("use_prune:{},sparsity:{}".format(cfg.use_prune, sparsity))
model = nni_pruning.model_pruning(model,
input_size=[1, 3, cfg.input_size[1], cfg.input_size[0]],
sparsity=sparsity,
reuse=False,
output_prune=os.path.join(cfg.work_dir, "prune"))
model = self.build_model_parallel(model, cfg.gpu_id, distributed=cfg.distributed)
return model
def build_callbacks(self, cfg, **kwargs):
"""Define callback function"""
self.logger.info("build_callbacks")
# Accuracy record callback function
acc_record = accuracy_recorder.AccuracyRecorder(target_names=cfg.classes,
indicator="Accuracy")
# loss record callback function
loss_record = losses_recorder.LossesRecorder(indicator="loss")
# Tensorboard Log and other history callback functions
history = log_history.LogHistory(log_dir=cfg.log_root,
log_freq=cfg.log_freq,
logger=self.logger,
indicators=["loss", "Accuracy"],
is_main_process=self.is_main_process)
# Model save callback function
checkpointer = model_checkpoint.ModelCheckpoint(model=self.model,
optimizer=self.optimizer,
moder_dir=cfg.model_root,
epochs=cfg.num_epochs,
start_save=-1,
indicator="Accuracy",
logger=self.logger)
# Learning rate adjustment policy callback function
lr_scheduler = build_scheduler.get_scheduler(cfg.scheduler,
optimizer=self.optimizer,
lr_init=cfg.lr,
num_epochs=cfg.num_epochs,
num_steps=self.num_steps,
milestones=cfg.milestones,
num_warn_up=cfg.num_warn_up)
callbacks = [acc_record,
loss_record,
lr_scheduler,
history,
checkpointer]
return callbacks
def run(self, logs: dict = {}):
self.logger.info("start train")
super().run(logs)
def main(cfg):
t = ClassificationTrainer(cfg)
return t.run()
def get_parser():
parser = argparse.ArgumentParser(description="Training Pipeline")
parser.add_argument("-c", "--config_file", help="configs file", default="configs/config.yaml", type=str)
# parser.add_argument("-c", "--config_file", help="configs file", default=None, type=str)
parser.add_argument("--train_data", help="train data", default="./data/dataset/train", type=str)
parser.add_argument("--test_data", help="test data", default="./data/dataset/val", type=str)
parser.add_argument("--work_dir", help="work_dir", default="output", type=str)
parser.add_argument("--input_size", help="input size", nargs="+", default=[224, 224], type=int)
parser.add_argument("--batch_size", help="batch_size", default=32, type=int)
parser.add_argument("--gpu_id", help="specify your GPU ids", nargs="+", default=[0], type=int)
parser.add_argument("--num_workers", help="num_workers", default=0, type=int)
parser.add_argument("--num_epochs", help="total epoch number", default=50, type=int)
parser.add_argument("--scheduler", help=" learning scheduler: multi-step,cosine", default="multi-step", type=str)
parser.add_argument("--milestones", help="epoch stages to decay learning rate", nargs="+",
default=[10, 20, 40], type=int)
parser.add_argument("--num_warn_up", help="num_warn_up", default=3, type=int)
parser.add_argument("--net_type", help="net_type", default="mobilenet_v2", type=str)
parser.add_argument("--finetune", help="finetune model file", default=None, type=str)
parser.add_argument("--loss_type", help="loss_type", default="CELoss", type=str)
parser.add_argument("--optim_type", help="optim_type", default="SGD", type=str)
parser.add_argument("--lr", help="learning rate", default=0.1, type=float)
parser.add_argument("--weight_decay", help="weight_decay", default=0.0005, type=float)
parser.add_argument("--momentum", help="momentum", default=0.9, type=float)
parser.add_argument("--log_freq", help="log_freq", default=10, type=int)
parser.add_argument('--use_prune', action='store_true', help='use prune', default=False)
parser.add_argument('--progress', action='store_true', help='display progress bar', default=True)
parser.add_argument('--distributed', action='store_true', help='use distributed training', default=False)
parser.add_argument('--polyaxon', action='store_true', help='polyaxon', default=False)
return parser
if __name__ == "__main__":
parser = get_parser()
cfg = setup_config.parser_config(parser.parse_args(), cfg_updata=True)
launch(main,
num_gpus_per_machine=len(cfg.gpu_id),
dist_url="tcp://127.0.0.1:28661",
num_machines=1,
machine_rank=0,
distributed=cfg.distributed,
args=(cfg,))
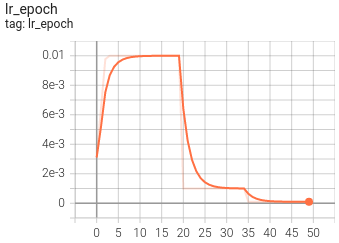
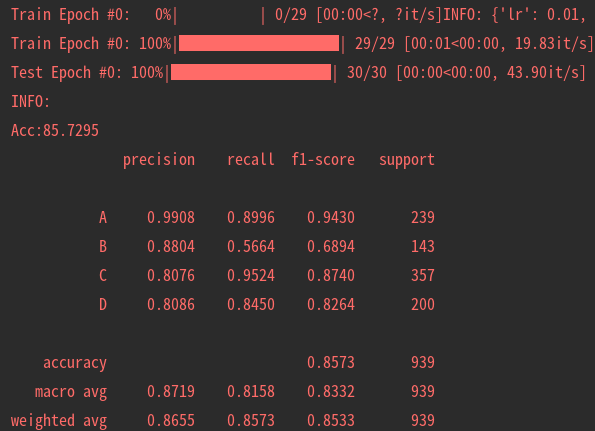
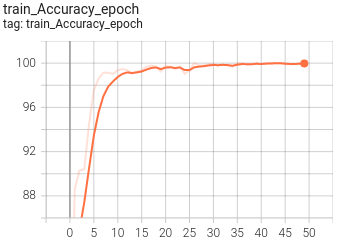
5. Visualization
At present, Tensorboard is used as the visualization tool of training process. The application method is as follows:
tensorboard --logdir=path/to/log/
 |  |
|---|---|
 | 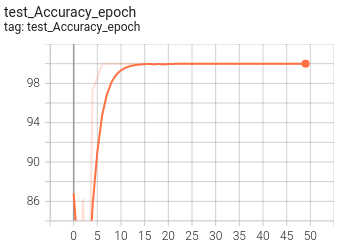 |
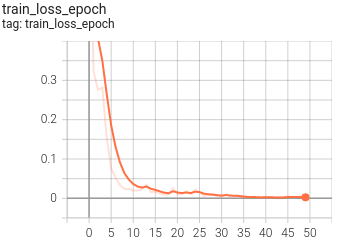 | 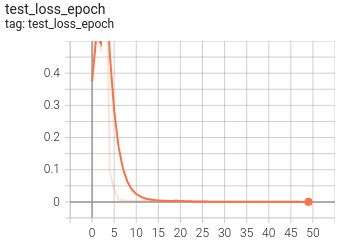 |