1. Project introduction
Q-learning: Q-learning was first proposed in 1989 and was initially based on tabular form.
DQN: DQN (deep Q network) was proposed only in 2013. It is a Q-learning algorithm based on deep neural network, and it is also the most commonly used Q-learning algorithm at present.
Objectives of the project:
The DQN algorithm is used to train an agent to obtain a higher reward value in the vehicle placement environment. For a detailed description of car swing, please refer to the blog: Introduction to the classic control environment of OpenAI Gym -- CartPole
The reference contents of this project include:
- Intensive learning 7-day punch in camp Lesson 4: solving RL based on neural network method
- Paddle's high-performance and flexible reinforcement learning framework: PARL
- Mr. Wang Shusen's Deep reinforcement learning book
2. Import dependency
import os import gym import numpy as np import paddle from collections import deque from visualdl import LogWriter import copy import time
3. Build model
3.1 DQN network structure
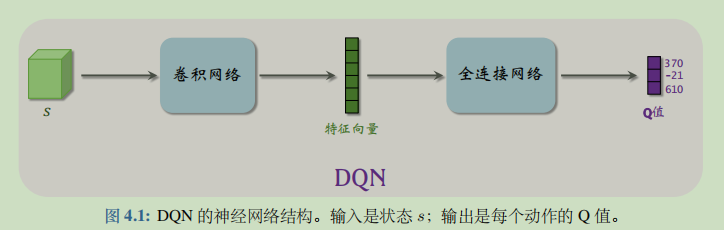
Because our state s is a one-dimensional vector, we use the full connection layer in practice
class MyDQNnetwork(paddle.nn.Layer):
# state_size: the size of the state space
# action_size: the size of the action space
def __init__(self, state_size, action_size):
super(MyDQNnetwork, self).__init__()
self.fc1 = paddle.nn.Linear(state_size, 128)
self.fc2 = paddle.nn.Linear(128, 128)
self.fc3 = paddle.nn.Linear(128, action_size)
self.relu=paddle.nn.ReLU()
def forward(self, state):
out = self.relu(self.fc1(state))
out = self.relu(self.fc2(out))
q = self.fc3(out)
return q
3.2 experience playback array
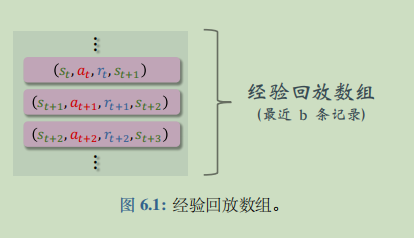
experience replay is an important skill in reinforcement learning, which can greatly improve the performance of reinforcement learning. Experience playback means to store the records of the interaction between the agent and the environment (i.e. experience) in an array, and then repeatedly use these experiences to train the agent. This array is called the replay buffer.
Advantages of experience playback:
-
Breaking the correlation of sequences: when training DQN, we update the parameters of DQN with a quadruple every time. We want two adjacent quads to be independent. However, when the agent collects experience, there is a strong correlation between the two adjacent quads (st, at, rt, st+1) and (st+1, at+1, rt+1, st+2). The effect of training DQN with these strongly correlated quads in turn is often very poor. Experience playback randomly extracts a quad from the array to update the DQN parameters. In this way, the four elements randomly selected are independent, eliminating the correlation.
-
Reuse the collected experience instead of discarding it once, so that the same performance can be achieved with fewer samples
Modification of actual operation:
-
Use deque to store experience. Deque is a Python double ended queue. When the capacity is specified, if you continue to add elements to the end of the queue, the first element of the queue will automatically leave the queue.
-
In actual use, the experience array does not necessarily store quads, but may be n tuples (this item is the five tuples used), depending on the actual situation.
class MyMemoryBuffer(object):
def __init__(self,memory_size):
self.memory_size=memory_size
self.buffer=deque(maxlen=self.memory_size)
# Experience is increased because the experience array is stored in deque, which is a double ended queue,
# Our deque specifies the size. When the deque is full and then add the element, the element at the head of the team will be automatically removed from the team
def add(self,experience):
self.buffer.append(experience)
def size(self):
return len(self.buffer)
# continuous=True indicates that batch is taken continuously_ Three experiences
def sample(self , batch_szie , continuous = True):
# Does the selected number of experiences exceed the number of experiences in the buffer
if batch_szie>len(self.buffer):
batch_szie=len(self.buffer)
# Whether experience is taken continuously
if continuous:
# random.randint(a, b) returns any integer between [a, b]
rand=np.random.randint(0,len(self.buffer)-batch_szie)
return [self.buffer[i] for i in range(rand,rand+batch_szie)]
else:
# numpy.random.choice(a, size=None, replace=True, p=None)
# A if it is an array, sample in the array; If a is an integer, it is sampled randomly from the sequence [0,a-1]
# If size is an integer, it indicates the number of samples
# If replace is True, sampling can be repeated; If it is false, it will not be repeated
# p is an array representing the sampling probability of each element in a; None means equal probability sampling
indexes=np.random.choice(np.arange(len(self.buffer)),size=batch_szie,replace=False)
return [self.buffer[i] for i in indexes]
def clear(self):
self.buffer.clear()
4. Define agent
Different strategies, behavior strategies and target strategies:
- Behavior strategy: in reinforcement learning, we let the agent interact with the environment, record the observed state, action and reward, and use these experiences to learn a strategy function. In this process, the strategy that controls the interaction between agent and environment is called behavior strategy. The function of behavioral strategy is to collect experience, that is, observed environment, action and reward.
- Target strategy: the purpose of training is to obtain a strategy function, which is used to control the agent after training; This policy function is called the target policy.
- The behavior strategy and the target strategy can be the same or different. The same strategy refers to using the same behavior strategy and target strategy; Different strategies refer to different behavior strategies and target strategies.
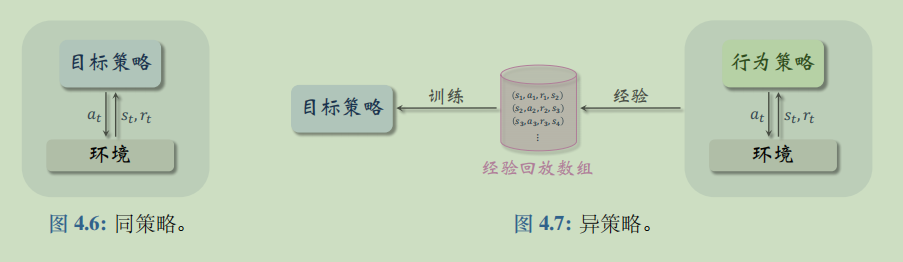
DQN is a heterogeneous strategy. In this project, the behavior strategy uses ϵ- The green strategy is commonly used and simple. The corresponding sample function in our code

The target strategy is a deterministic strategy, that is, it is predicted by DQN network and corresponds to the predict function in the code.
Target network:
Q learning algorithm has a defect: the DQN trained by Q learning will overestimate the real value and pass
It is often non-uniform. This defect leads to poor performance of DQN. Overestimation is not the defect of DQN model
It is the defect of Q learning algorithm. One reason for the overestimation of Q learning is the spread of deviation caused by bootstrap (in fact, there is more than one reason. Please refer to Mr. Wang Shusen's book).
The embodiment of bootstrap problem here is that DQN allows itself to fit its own estimation. If the estimation is high, the fitting value will be high, and then estimate and fit... It will continue to be high. One way to alleviate the bootstrap problem is to use the target network.

The training process of agent is as follows:
It is mainly reflected in the learn function
- DQN propagates forward, and the input is s_t,a_t. The output gets q_t
- The target network propagates forward, and the input is s_t+1,a_t. Output gets q '_ t
- Calculate TD target y=r_t+gamma*q’_ t
- Calculate TD error error=q_t-y
- DQN back propagation, calculate the gradient and update it
- Update the parameters of the target network (it can be executed once in multiple time steps)
# Update the operation function of the target network in mydqnagent Call in learn () function
def soft_update(target,source,tau=0):
# The zip() function takes the iteratable object as a parameter, packages the corresponding elements in the object into tuples, and then returns a list composed of these tuples.
for target_param,param in zip(target.parameters(),source.parameters()):
target_param.set_value(target_param*tau+param*(1.0-tau))
class MyDQNAgent():
def __init__(self, model, action_size,gamma=None, lr=None, e_greed=0.1, e_greed_decrement=0):
self.action_size = action_size
self.global_step = 0
self.update_target_steps = 200 # The parameters of the target network are updated every 200 time steps
self.e_greed = e_greed # ϵ- In green ϵ
self.e_greed_decrement = e_greed_decrement # ϵ Dynamic update factor
self.model = model
self.target_model = copy.deepcopy(model)
self.gamma = gamma # Return discount factor
self.lr = lr
self.mse_loss = paddle.nn.MSELoss(reduction='mean')
self.optimizer = paddle.optimizer.Adam(learning_rate=lr, parameters=self.model.parameters())
# Generate actions using behavior policies
def sample(self, state):
sample = np.random.random() # [0.0, 1.0)
if sample < self.e_greed:
act = np.random.randint(self.action_size) # Returns an integer of [0, action_size), here is 0 or 1
else:
if np.random.random() < 0.01:
act = np.random.randint(self.action_size)
else:
act = self.predict(state)
# Dynamic change e_ Green, but not less than 0.01
self.e_greed = max(0.01, self.e_greed - self.e_greed_decrement)
return act
# DQN network prediction
def predict(self, state):
state = paddle.to_tensor(state, dtype='float32')
# DQN network prediction
pred_q = self.model(state)
# Select the action with the highest probability value
act = pred_q.argmax().numpy()[0]
return act
# Update DQN network
def learn(self, state, action, reward, next_state, terminal):
"""Update model with an episode data
Args:
state(np.float32): shape of (batch_size, state_size)
act(np.int32): shape of (batch_size)
reward(np.float32): shape of (batch_size)
next_state(np.float32): shape of (batch_size, state_size)
terminal(np.float32): shape of (batch_size)
Returns:
loss(float)
"""
if self.global_step % self.update_target_steps == 0:
# 6. Update target network
soft_update(self.target_model,self.model)
self.global_step += 1
action = np.expand_dims(action, axis=-1)
reward = np.expand_dims(reward, axis=-1)
terminal = np.expand_dims(terminal, axis=-1)
state = paddle.to_tensor(state, dtype='float32')
action = paddle.to_tensor(action, dtype='int32')
reward = paddle.to_tensor(reward, dtype='float32')
next_state = paddle.to_tensor(next_state, dtype='float32')
terminal = paddle.to_tensor(terminal, dtype='float32')
# 1. DQN network does forward propagation
pred_values = self.model(state)
# Dimension of action: 2
action_dim = pred_values.shape[-1]
# Delete the dimension with dimension 1 in the Shape of the input action
action = paddle.squeeze(action, axis=-1)
# onhot encoding of action
action_onehot = paddle.nn.functional.one_hot(action, num_classes=action_dim)
pred_value = paddle.multiply(pred_values, action_onehot)
pred_value = paddle.sum(pred_value, axis=1, keepdim=True)
# target Q
with paddle.no_grad():
# 2. Forward propagation of target network
max_v = self.target_model(next_state).max(1, keepdim=True)
# 3. TD objectives
target = reward + (1 - terminal) * self.gamma * max_v
# 4. TD error
loss = self.mse_loss(pred_value, target)
# 5. Update the parameters of DQN
# Gradient clearing
self.optimizer.clear_grad()
# Reverse calculation gradient
loss.backward()
# Gradient update
self.optimizer.step()
return loss.numpy()[0]
5. Training
5.1 define visualization file path
writer=LogWriter('./logs')
5.2 training
LEARN_FREQ = 5 # The frequency of training,
MEMORY_SIZE = 200000 # Empirical array size
MEMORY_WARMUP_SIZE = 200 # Threshold number of experiences to start training
BATCH_SIZE = 32
LEARNING_RATE = 0.0005
GAMMA = 0.99
# Enable the environment for training. If done=1, the training will be ended and the reward value will be returned
def run_train_episode(agent, env, rpmemory):
total_reward = 0
state = env.reset()
step = 0
while True:
step += 1
# Agent sampling action
action = agent.sample(state)
next_state, reward, done, _ = env.step(action)
rpmemory.add((state, action, reward, next_state, done))
# When the number of experiences in the experience playback array is enough (greater than the given threshold, set manually), train once every 5 time steps
if (rpmemory.size() > MEMORY_WARMUP_SIZE) and (step % LEARN_FREQ == 0):
# s,a,r,s',done
experiences=rpmemory.sample(BATCH_SIZE)
batch_state, batch_action, batch_reward, batch_next_state,batch_done = zip(*experiences)
# Agent updating value network
train_loss = agent.learn(batch_state, batch_action, batch_reward,batch_next_state, batch_done)
total_reward += reward
state = next_state
if done:
break
return total_reward
# Verify the environment for 5 times and take the average reward value
def run_evaluate_episodes(agent, env, eval_episodes=5, render=False):
eval_reward = []
for i in range(eval_episodes):
state = env.reset()
episode_reward = 0
while True:
# Agent selection action execution
action = agent.predict(state)
state, reward, done, _ = env.step(action)
episode_reward += reward
# render is not supported on AI studio platform and can be started on your own computer
if render:
env.render()
if done:
break
eval_reward.append(episode_reward)
return np.mean(eval_reward)
def main():
# Loading environment
env = gym.make('CartPole-v0')
state_size = env.observation_space.shape[0] # 4
action_size = env.action_space.n # 2
# Initialize experience array
rpm = MyMemoryBuffer(MEMORY_SIZE)
# build an agent
model = MyDQNnetwork(state_size, action_size)
agent = MyDQNAgent(model, action_size,gamma=GAMMA, lr=LEARNING_RATE, e_greed=0.1, e_greed_decrement=1e-6)
max_episode = 1200
# start training
start_time=time.time()
episode = 0
while episode < max_episode:
# train part
for i in range(50):
total_reward = run_train_episode(agent, env, rpm)
episode += 1
# test part
eval_reward= run_evaluate_episodes(agent, env, render=False)
writer.add_scalar('eval reward',eval_reward,episode)
if episode%50==0:
print('episode:{} e_greed:{} Test reward:{}'.format(episode, agent.e_greed, eval_reward))
print('all used time {:.2}s = {:.2}h'.format(time.time()-start_time,(time.time()-start_time)/3600))
if __name__ == '__main__':
main()
W1227 16:36:14.529779 4613 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.0, Runtime API Version: 10.1 W1227 16:36:14.534389 4613 device_context.cc:465] device: 0, cuDNN Version: 7.6. /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/tensor/creation.py:130: DeprecationWarning: `np.object` is a deprecated alias for the builtin `object`. To silence this warning, use `object` by itself. Doing this will not modify any behavior and is safe. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations if data.dtype == np.object: episode:50 e_greed:0.09952399999999953 Test reward:8.8 episode:100 e_greed:0.09902599999999903 Test reward:8.6 episode:150 e_greed:0.09853399999999854 Test reward:9.6 episode:200 e_greed:0.09804899999999805 Test reward:9.6 episode:250 e_greed:0.09756399999999757 Test reward:9.8 episode:300 e_greed:0.09706799999999707 Test reward:9.6 episode:350 e_greed:0.09656799999999657 Test reward:9.4 episode:400 e_greed:0.09608299999999609 Test reward:9.6 episode:450 e_greed:0.0955879999999956 Test reward:9.6 episode:500 e_greed:0.0950979999999951 Test reward:9.8 episode:550 e_greed:0.09447199999999448 Test reward:15.8 episode:600 e_greed:0.09283599999999284 Test reward:53.0 episode:650 e_greed:0.08931699999998932 Test reward:52.4 episode:700 e_greed:0.08250499999998251 Test reward:145.8 episode:750 e_greed:0.07330899999997331 Test reward:200.0 episode:800 e_greed:0.06380499999996381 Test reward:200.0 episode:850 e_greed:0.054163999999954165 Test reward:193.2 episode:900 e_greed:0.044443999999944445 Test reward:164.8 episode:950 e_greed:0.03524099999993524 Test reward:139.8 episode:1000 e_greed:0.026618999999926618 Test reward:157.4 episode:1050 e_greed:0.01726199999991726 Test reward:194.4 episode:1100 e_greed:0.01 Test reward:200.0 episode:1150 e_greed:0.01 Test reward:154.2 episode:1200 e_greed:0.01 Test reward:195.0 all used time 1.3e+02s = 0.036h
5.3 result display
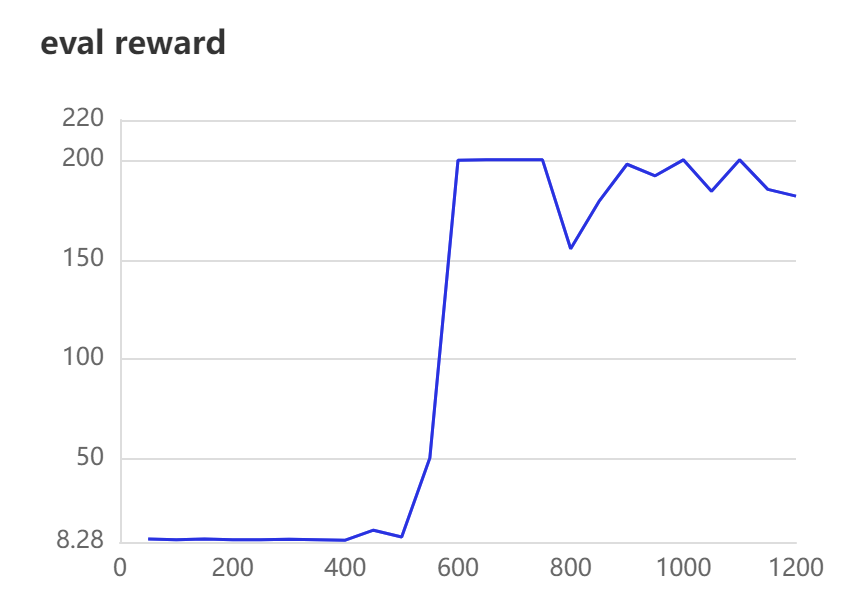
The reward value at the beginning is not high because there is not enough experience in the experience array. As the number of iterations increases, the reward value starts to jump when the experience in the experience array reaches a certain number.
6. Project summary
This project is the construction of DQN from 0. Personally, I think it is more detailed. Because I have been reading books before, only theoretical knowledge, and now I start to practice. I feel that it is still difficult from theory to practice, but there are many examples to refer to, which can speed up the pace of learning.
I am a shallow learner and have just started intensive learning. There are many deficiencies. Please criticize and correct!!