Chapter 3 enterprise development cases
3.1 official case of monitoring port data
- Case requirements: first, Flume monitors port 44444 of the machine, then sends a message to port 44444 of the machine through telnet tool, and finally Flume displays the monitored data on the console in real time.
- Demand analysis:
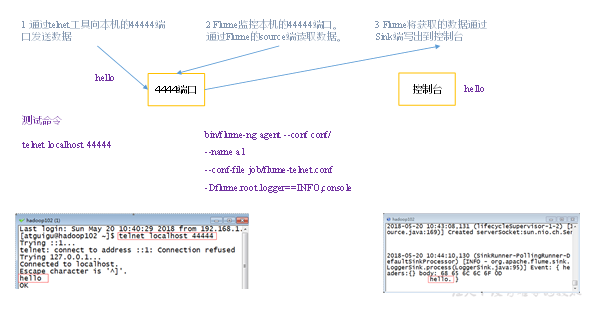
- Implementation steps:
1. Install telnet tools
Copy the RPM package (xinetd-2.3.14-40.el6.x86_.rpm, telnet-0.17-48.el6.x86_.rpm and telnet-server-0.17-48.el6.x86_. RPM) into the / opt/software folder. Execute the RPM package installation command:
[atguigu@hadoop102 software]$ sudo rpm -ivh xinetd-2.3.14-40.el6.x86_64.rpm [atguigu@hadoop102 software]$ sudo rpm -ivh telnet-0.17-48.el6.x86_64.rpm [atguigu@hadoop102 software]$ sudo rpm -ivh telnet-server-0.17-48.el6.x86_64.rpm
- Judge whether port 44444 is occupied
[atguigu@hadoop102 flume-telnet]$ sudo netstat -tunlp | grep 44444
Function Description: netstat command is a very useful tool for monitoring TCP/IP network. It can display routing table, actual network connection and status information of each network interface device.
Basic syntax: netstat [options] Option parameters: -t or -- TCP: display the connection status of TCP transmission protocol; -u or -- UDP: display the connection status of UDP transmission protocol; -n or -- numeric: use ip address directly instead of domain name server; -l or -- listening: displays the Socket of the server in monitoring; -p or -- programs: displays the program ID and program name of the Socket being used;
- Create Flume Agent configuration file flume-telnet-logger.conf create the job folder in the flume directory and enter the job folder.
[atguigu@hadoop102 flume]$ mkdir job [atguigu@hadoop102 flume]$ cd job/
Create the Flume Agent configuration file flume-telnet-logger.conf in the job folder.
[atguigu@hadoop102 job]$ touch flume-telnet-logger.conf
Add the following to the flume-telnet-logger.conf file.
[atguigu@hadoop102 job]$ vim flume-telnet-logger.conf
Add the following:
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
Note: the configuration file is from the official manual http://flume.apache.org/FlumeUserGuide.html
- Open the flume listening port first
[atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a1 --conf-file job/flume-telnet-logger.conf -Dflume.root.logger=INFO,console
Parameter Description:
– conf conf /: indicates that the configuration file is stored in the conf / directory
– name a1: indicates that the agent is named a1
– conf file job / flume telnet.conf: the configuration file that flume started to read this time is the flume-telnet.conf file under the job folder.
-Dflume.root.logger==INFO,console: - D means to dynamically modify the attribute value of flume.root.logger when flume is running, and set the console log printing level to info level. The log level includes log, info, warn and error.
- Use telnet tool to send content to port 44444 of this computer
[atguigu@hadoop102 ~]$ telnet localhost 44444
- Observe the received data on the Flume monitoring page

3.2 real time read local file to HDFS case
-
Case requirements: monitor Hive logs in real time and upload them to HDFS
-
Demand analysis:
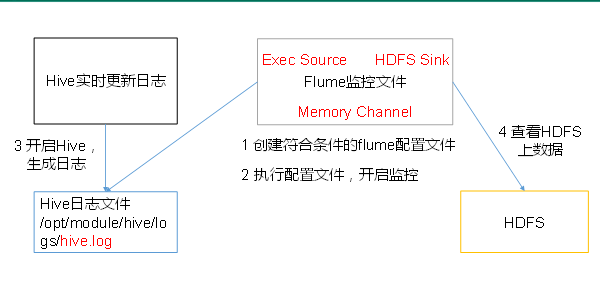
-
Implementation steps:
-
Flume must have Hadoop related jar package to output data to HDFS
Put commons-configuration-1.6.jar
hadoop-auth-2.7.2.jar,
hadoop-common-2.7.2.jar,
hadoop-hdfs-2.7.2.jar,
commons-io-2.4.jar,
htrace-core-3.1.0-incubating.jar
Copy to the folder / opt/module/flume/lib. -
Create flume-file-hdfs.conf file
create a file
[atguigu@hadoop102 job]$ touch flume-file-hdfs.conf
Note: to read files in a Linux system, execute the command according to the rules of the Linux command. Because Hive log is in Linux system, the type of read file is selected: exec means execute. Represents executing a Linux command to read a file.
-
[atguigu@hadoop102 job]$ vim flume-file-hdfs.conf
Add the following
# Name the components on this agent a2.sources = r2 a2.sinks = k2 a2.channels = c2 # Describe/configure the source a2.sources.r2.type = exec a2.sources.r2.command = tail -F /opt/module/hive/logs/hive.log a2.sources.r2.shell = /bin/bash -c # Describe the sink a2.sinks.k2.type = hdfs a2.sinks.k2.hdfs.path = hdfs://hadoop102:9000/flume/%Y%m%d/%H #Prefix of uploaded file a2.sinks.k2.hdfs.filePrefix = logs- #Scroll folders by time a2.sinks.k2.hdfs.round = true #How many time units to create a new folder a2.sinks.k2.hdfs.roundValue = 1 #Redefining time units a2.sinks.k2.hdfs.roundUnit = hour #Use local time stamp or not a2.sinks.k2.hdfs.useLocalTimeStamp = true #How many events are accumulated before flush to HDFS once a2.sinks.k2.hdfs.batchSize = 1000 #Set file type to support compression a2.sinks.k2.hdfs.fileType = DataStream #How often to generate a new file a2.sinks.k2.hdfs.rollInterval = 600 #Set the scroll size for each file a2.sinks.k2.hdfs.rollSize = 134217700 #Scrolling of files is independent of the number of events a2.sinks.k2.hdfs.rollCount = 0 #Minimum redundancy a2.sinks.k2.hdfs.minBlockReplicas = 1 # Use a channel which buffers events in memory a2.channels.c2.type = memory a2.channels.c2.capacity = 1000 a2.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a2.sources.r2.channels = c2 a2.sinks.k2.channel = c2

- Perform monitoring configuration
[atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a2 --conf-file job/flume-file-hdfs.conf - Open Hadoop and Hive and operate Hive to generate logs
[atguigu@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh [atguigu@hadoop103 hadoop-2.7.2]$ sbin/start-yarn.sh [atguigu@hadoop102 hive]$ bin/hive hive (default)>
- View files on HDFS.
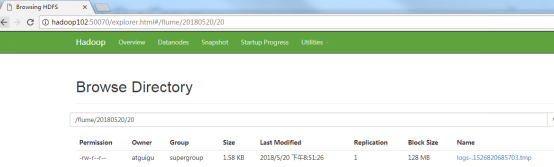
3.3 real time reading of directory file to HDFS case
- Case requirement: use Flume to monitor files in the entire directory
- Demand analysis:
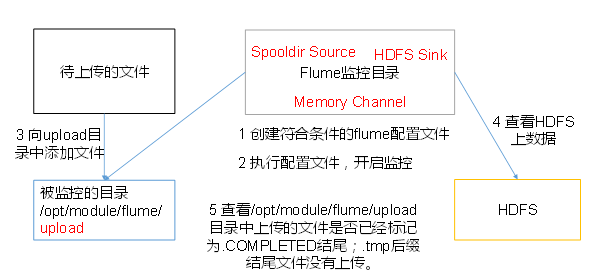
- Implementation steps:
- Create the configuration file flume-dir-hdfs.conf
Create a file [atguigu@hadoop102 job]$ touch flume-dir-hdfs.conf //Open file [atguigu@hadoop102 job]$ vim flume-dir-hdfs.conf //Add the following a3.sources = r3 a3.sinks = k3 a3.channels = c3 # Describe/configure the source a3.sources.r3.type = spooldir a3.sources.r3.spoolDir = /opt/module/flume/upload a3.sources.r3.fileSuffix = .COMPLETED a3.sources.r3.fileHeader = true #Ignore all files ending in. tmp, do not upload a3.sources.r3.ignorePattern = ([^ ]*\.tmp) # Describe the sink a3.sinks.k3.type = hdfs a3.sinks.k3.hdfs.path = hdfs://hadoop102:9000/flume/upload/%Y%m%d/%H #Prefix of uploaded file a3.sinks.k3.hdfs.filePrefix = upload- #Scroll folders by time a3.sinks.k3.hdfs.round = true #How many time units to create a new folder a3.sinks.k3.hdfs.roundValue = 1 #Redefining time units a3.sinks.k3.hdfs.roundUnit = hour #Use local time stamp or not a3.sinks.k3.hdfs.useLocalTimeStamp = true #How many events are accumulated before flush to HDFS once a3.sinks.k3.hdfs.batchSize = 100 #Set file type to support compression a3.sinks.k3.hdfs.fileType = DataStream #How often to generate a new file a3.sinks.k3.hdfs.rollInterval = 600 #Set the scrolling size of each file to about 128M a3.sinks.k3.hdfs.rollSize = 134217700 #Scrolling of files is independent of the number of events a3.sinks.k3.hdfs.rollCount = 0 #Minimum redundancy a3.sinks.k3.hdfs.minBlockReplicas = 1 # Use a channel which buffers events in memory a3.channels.c3.type = memory a3.channels.c3.capacity = 1000 a3.channels.c3.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r3.channels = c3 a3.sinks.k3.channel = c3

-
Start monitoring folder command
[atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a3 --conf-file job/flume-dir-hdfs.conf
Note: when using Spooling Directory Source- Do not create and continuously modify files in the monitoring directory
- The uploaded file will end in. COMPLETED
- File changes are scanned every 500 milliseconds for monitored folders
-
Add files to the upload folder
Create the upload folder in the directory / opt/module/flume
[atguigu@hadoop102 flume]$ mkdir upload
Add files to the upload folder
[atguigu@hadoop102 upload]$ touch atguigu.txt [atguigu@hadoop102 upload]$ touch atguigu.tmp [atguigu@hadoop102 upload]$ touch atguigu.log
- Viewing data on HDFS
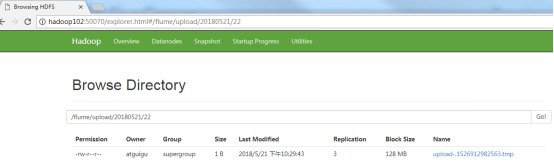
- Wait for 1s and query the upload folder again
[atguigu@hadoop102 upload]$ ll //Total dosage 0 -rw-rw-r--. 1 atguigu atguigu 0 5 Month 2022:31 atguigu.log.COMPLETED -rw-rw-r--. 1 atguigu atguigu 0 5 Month 2022:31 atguigu.tmp -rw-rw-r--. 1 atguigu atguigu 0 5 Month 2022:31 atguigu.txt.COMPLETED
3.4 single data source multi export case (selector)
Single Source, multi-Channel and Sink are shown in Figure 7-2.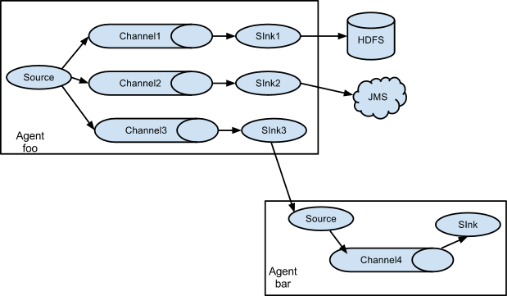
- Case requirements: flume-1 is used to monitor file changes. Flume-1 transmits the changes to Flume-2, which is responsible for storing them in HDFS. At the same time, flume-1 passes the changed content to Flume-3, which is responsible for outputting to the local file system.
- Demand analysis:
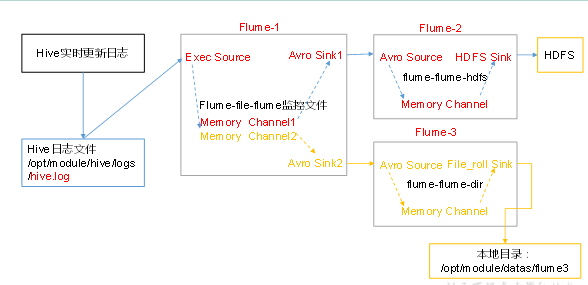
- Implementation steps:
- Preparation
Create group1 folder in / opt/module/flume/job directory
[atguigu@hadoop102 job]$ cd group1/
Create flume3 folder in / opt / module / data /
[atguigu@hadoop102 datas]$ mkdir flume3 - Create flume-file-flume.conf
Configure one source, two channel s and two sink to receive log files, and send them to flume flume HDFS and flume flume dir respectively.
Create profile and open
- Preparation
[atguigu@hadoop102 group1]$ touch flume-file-flume.conf [atguigu@hadoop102 group1]$ vim flume-file-flume.conf
Add the following
# Name the components on this agent a1.sources = r1 a1.sinks = k1 k2 a1.channels = c1 c2 # Copy data flow to all channel s a1.sources.r1.selector.type = replicating # Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.command = tail -F /opt/module/hive/logs/hive.log a1.sources.r1.shell = /bin/bash -c # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = hadoop102 a1.sinks.k1.port = 4141 a1.sinks.k2.type = avro a1.sinks.k2.hostname = hadoop102 a1.sinks.k2.port = 4142 # Describe the channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.channels.c2.type = memory a1.channels.c2.capacity = 1000 a1.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 c2 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c2
Note: Avro is a language independent data serialization and RPC framework created by Doug Cutting, founder of Hadoop.
Note: RPC (Remote Procedure Call) - Remote Procedure Call, which is a protocol to request services from remote computer programs through the network without understanding the underlying network technology.
- Create flume-flume-hdfs.conf
Configure superior Flume Output Source,Output is to HDFS Of Sink. //Create profile and open [atguigu@hadoop102 group1]$ touch flume-flume-hdfs.conf [atguigu@hadoop102 group1]$ vim flume-flume-hdfs.conf //Add the following # Name the components on this agent a2.sources = r1 a2.sinks = k1 a2.channels = c1 # Describe/configure the source a2.sources.r1.type = avro a2.sources.r1.bind = hadoop102 a2.sources.r1.port = 4141 # Describe the sink a2.sinks.k1.type = hdfs a2.sinks.k1.hdfs.path = hdfs://hadoop102:9000/flume2/%Y%m%d/%H #Prefix of uploaded file a2.sinks.k1.hdfs.filePrefix = flume2- #Scroll folders by time a2.sinks.k1.hdfs.round = true #How many time units to create a new folder a2.sinks.k1.hdfs.roundValue = 1 #Redefining time units a2.sinks.k1.hdfs.roundUnit = hour #Use local time stamp or not a2.sinks.k1.hdfs.useLocalTimeStamp = true #How many events are accumulated before flush to HDFS once a2.sinks.k1.hdfs.batchSize = 100 #Set file type to support compression a2.sinks.k1.hdfs.fileType = DataStream #How often to generate a new file a2.sinks.k1.hdfs.rollInterval = 600 #Set the scrolling size of each file to about 128M a2.sinks.k1.hdfs.rollSize = 134217700 #Scrolling of files is independent of the number of events a2.sinks.k1.hdfs.rollCount = 0 #Minimum redundancy a2.sinks.k1.hdfs.minBlockReplicas = 1 # Describe the channel a2.channels.c1.type = memory a2.channels.c1.capacity = 1000 a2.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1
- Create flume-flume-dir.conf
Configure superior Flume Output Source,Output to local directory Sink. //Create profile and open [atguigu@hadoop102 group1]$ touch flume-flume-dir.conf [atguigu@hadoop102 group1]$ vim flume-flume-dir.conf //Add the following # Name the components on this agent a3.sources = r1 a3.sinks = k1 a3.channels = c2 # Describe/configure the source a3.sources.r1.type = avro a3.sources.r1.bind = hadoop102 a3.sources.r1.port = 4142 # Describe the sink a3.sinks.k1.type = file_roll a3.sinks.k1.sink.directory = /opt/module/datas/flume3 # Describe the channel a3.channels.c2.type = memory a3.channels.c2.capacity = 1000 a3.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r1.channels = c2 a3.sinks.k1.channel = c2 //Tip: the output local directory must be an existing directory. If the directory does not exist, a new directory will not be created.
- Execute profile
Open corresponding configuration files respectively: flume-flume-dir,flume-flume-hdfs,flume-file-flume. [atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a3 --conf-file job/group1/flume-flume-dir.conf [atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a2 --conf-file job/group1/flume-flume-hdfs.conf [atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a1 --conf-file job/group1/flume-file-flume.conf
- Start Hadoop and Hive
[atguigu@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh [atguigu@hadoop103 hadoop-2.7.2]$ sbin/start-yarn.sh [atguigu@hadoop102 hive]$ bin/hive hive (default)>
- Check data on HDFS
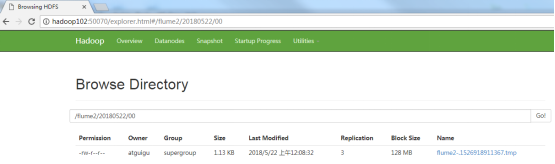
- Check the data in the / opt / module / data / flume3 directory
[atguigu@hadoop102 flume3]$ ll //Total dosage 8 -rw-rw-r--. 1 atguigu atguigu 5942 5 Month 2200:09 1526918887550-3
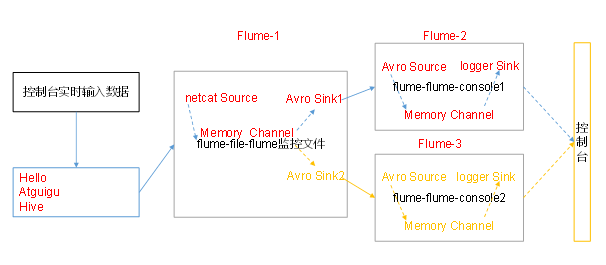
3.5 single data source multi export case (Sink group)
Single Source, Channel and multiple sink (load balancing) are shown in Figure 7-3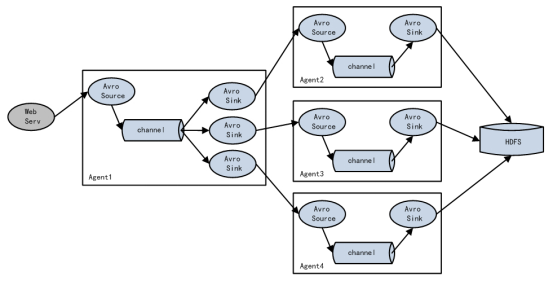
- Case requirements: flume-1 is used to monitor file changes. Flume-1 transmits the changes to Flume-2, which is responsible for storing them in HDFS. At the same time, flume-1 transfers the changes to Flume-3, which is also responsible for storing them in HDFS
- Demand analysis:
- Implementation steps:
- Preparation
Create group2 folder in / opt/module/flume/job directory
[atguigu@hadoop102 job]$ cd group2/ - Create flume-netcat-flume.conf
- Preparation
Configure 1 source And 1. channel,Two sink,Separately delivered to flume-flume-console1 and flume-flume-console2. //Create profile and open [atguigu@hadoop102 group2]$ touch flume-netcat-flume.conf [atguigu@hadoop102 group2]$ vim flume-netcat-flume.conf //Add the following # Name the components on this agent a1.sources = r1 a1.channels = c1 a1.sinkgroups = g1 a1.sinks = k1 k2 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 a1.sinkgroups.g1.processor.type = load_balance a1.sinkgroups.g1.processor.backoff = true a1.sinkgroups.g1.processor.selector = round_robin a1.sinkgroups.g1.processor.selector.maxTimeOut=10000 # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = hadoop102 a1.sinks.k1.port = 4141 a1.sinks.k2.type = avro a1.sinks.k2.hostname = hadoop102 a1.sinks.k2.port = 4142 # Describe the channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinkgroups.g1.sinks = k1 k2 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c1 //Note: Avro is a language independent data serialization and RPC framework created by Doug Cutting, founder of Hadoop. //Note: RPC (Remote Procedure Call) - Remote Procedure Call, which is a protocol to request services from remote computer programs through the network without understanding the underlying network technology.
- Create flume-flume-console1.conf
Configure superior Flume Output Source,The output is to the local console. //Create profile and open [atguigu@hadoop102 group2]$ touch flume-flume-console1.conf [atguigu@hadoop102 group2]$ vim flume-flume-console1.conf //Add the following # Name the components on this agent a2.sources = r1 a2.sinks = k1 a2.channels = c1 # Describe/configure the source a2.sources.r1.type = avro a2.sources.r1.bind = hadoop102 a2.sources.r1.port = 4141 # Describe the sink a2.sinks.k1.type = logger # Describe the channel a2.channels.c1.type = memory a2.channels.c1.capacity = 1000 a2.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1
- Create flume-flume-console2.conf
Configure superior Flume Output Source,The output is to the local console. //Create profile and open [atguigu@hadoop102 group2]$ touch flume-flume-console2.conf [atguigu@hadoop102 group2]$ vim flume-flume-console2.conf //Add the following # Name the components on this agent a3.sources = r1 a3.sinks = k1 a3.channels = c2 # Describe/configure the source a3.sources.r1.type = avro a3.sources.r1.bind = hadoop102 a3.sources.r1.port = 4142 # Describe the sink a3.sinks.k1.type = logger # Describe the channel a3.channels.c2.type = memory a3.channels.c2.capacity = 1000 a3.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r1.channels = c2 a3.sinks.k1.channel = c2
- Execute profile
Open corresponding configuration files respectively: flume-flume-console2,flume-flume-console1,flume-netcat-flume. [atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a3 --conf-file job/group2/flume-flume-console2.conf -Dflume.root.logger=INFO,console [atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a2 --conf-file job/group2/flume-flume-console1.conf -Dflume.root.logger=INFO,console [atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a1 --conf-file job/group2/flume-netcat-flume.conf
- Use telnet tool to send content to port 44444 of this computer
$ telnet localhost 44444
- View the console print logs of Flume2 and Flume3
3.6 multi data source summary cases
Figure 7-4 shows the summary of data from multiple sources to a single Flume.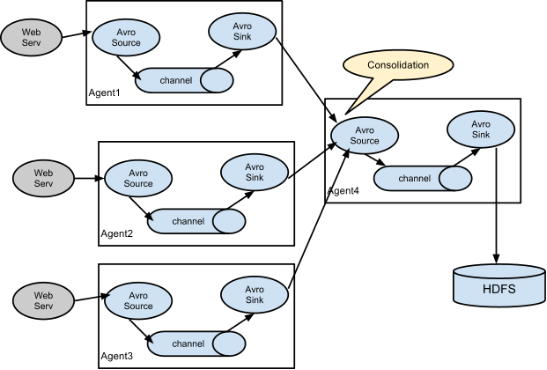
-
Case requirements:
Flume-1 monitoring file / opt/module/group.log on Hadoop 103,
Flume-2 on Hadoop 102 monitors the data flow of a certain port,
Flume-1 and Flume-2 send data to Flume-3 on Hadoop 104, and Flume-3 prints the final data to the console. -
Demand analysis:
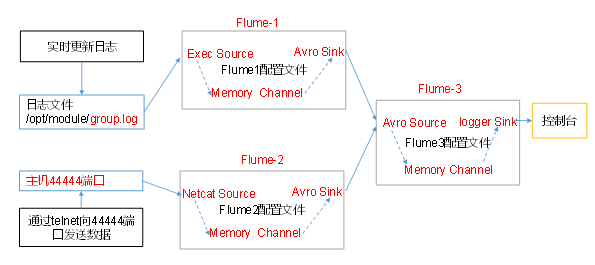
-
Implementation steps:
0. Preparations
Distribute Flume
[atguigu@hadoop102 module]$ xsync flume
Create a group3 folder in the / opt/module/flume/job directory of Hadoop 102, Hadoop 103, and Hadoop 104.
[atguigu@hadoop102 job]$ mkdir group3
[atguigu@hadoop103 job]$ mkdir group3
[atguigu@hadoop104 job]$ mkdir group3 -
Create flume1-logger-flume.conf
To configure Source Used for monitoring hive.log Files, configuring Sink Output data to next level Flume. //Create a profile on Hadoop 103 and open it [atguigu@hadoop103 group3]$ touch flume1-logger-flume.conf [atguigu@hadoop103 group3]$ vim flume1-logger-flume.conf //Add the following # Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.command = tail -F /opt/module/group.log a1.sources.r1.shell = /bin/bash -c # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = hadoop104 a1.sinks.k1.port = 4141 # Describe the channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
- Create flume2-netcat-flume.conf
To configure Source Monitoring port 44444 data flow, configuration Sink Data to next level Flume: //Create a profile on Hadoop 102 and open it [atguigu@hadoop102 group3]$ touch flume2-netcat-flume.conf [atguigu@hadoop102 group3]$ vim flume2-netcat-flume.conf //Add the following # Name the components on this agent a2.sources = r1 a2.sinks = k1 a2.channels = c1 # Describe/configure the source a2.sources.r1.type = netcat a2.sources.r1.bind = hadoop102 a2.sources.r1.port = 44444 # Describe the sink a2.sinks.k1.type = avro a2.sinks.k1.hostname = hadoop104 a2.sinks.k1.port = 4141 # Use a channel which buffers events in memory a2.channels.c1.type = memory a2.channels.c1.capacity = 1000 a2.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1
- Create flume3-flume-logger.conf
To configure source For reception flume1 And flume2 Data flow sent, after final merging sink To the console. //Create a profile on Hadoop 104 and open it [atguigu@hadoop104 group3]$ touch flume3-flume-logger.conf [atguigu@hadoop104 group3]$ vim flume3-flume-logger.conf //Add the following # Name the components on this agent a3.sources = r1 a3.sinks = k1 a3.channels = c1 # Describe/configure the source a3.sources.r1.type = avro a3.sources.r1.bind = hadoop104 a3.sources.r1.port = 4141 # Describe the sink # Describe the sink a3.sinks.k1.type = logger # Describe the channel a3.channels.c1.type = memory a3.channels.c1.capacity = 1000 a3.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r1.channels = c1 a3.sinks.k1.channel = c1
- Execute profile
Open corresponding configuration files respectively: flume3-flume-logger.conf,flume2-netcat-flume.conf,flume1-logger-flume.conf. [atguigu@hadoop104 flume]$ bin/flume-ng agent --conf conf/ --name a3 --conf-file job/group3/flume3-flume-logger.conf -Dflume.root.logger=INFO,console [atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a2 --conf-file job/group3/flume2-netcat-flume.conf [atguigu@hadoop103 flume]$ bin/flume-ng agent --conf conf/ --name a1 --conf-file job/group3/flume1-logger-flume.conf
- Append content to group.log under / opt/module directory on Hadoop 103
[atguigu@hadoop103 module]$ echo 'hello' > group.log
- Send data to port 44444 on Hadoop 102
[atguigu@hadoop102 flume]$ telnet hadoop102 44444
- Check the data on Hadoop 104


