RabbitMQ is used as the message queue in the project. I have encountered the loss of messages. I hereby record it.
Write in front
First, let's talk about the three semantics in MQTT protocol, which is very important.
In MQTT protocol, three quality of service standards that can be provided when delivering messages are given. The three quality of service from low to high are:
- At most once: at least once. When a message is delivered, it can be delivered at most once. In other words, there is no guarantee of message reliability, and message loss is allowed.
- At least once. When a message is delivered, it will be delivered at least once. In other words, message loss is not allowed, but a small number of repeated messages are allowed.
- Exactly once: exactly once. When a message is delivered, it will only be delivered once. It is not allowed to be lost or repeated. This is the highest level. This service quality standard is applicable not only to MQTT, but also to all message queues. At least once is the quality of service provided by most commonly used message queues, including RocketMQ, RabbitMQ and Kafka. In other words, it is difficult for message queuing to ensure that messages are not repeated.
At least once + idempotent consumption = Exactly once
Idempotency will be discussed next time. This article first discusses the problem of message loss.
How to ensure 100% message loss
There are three steps for message consumption from production end to consumption end:
- The production end sends a message to RabbitMQ;
- RabbitMQ sends a message to the consumer;
- The consumer side consumes this message;
In other words, as long as the message reliability of the production end and consumption section is guaranteed, 100% of the message can not be lost in theory.
(of course, the reliability here is not necessarily 100% lost. Data loss can be caused by disk damage, computer room explosion, etc. of course, this kind of occurrence is of minimal probability. It is reliable if 99.999999% messages are not lost.)
Production end reliability delivery
Transaction message mechanism
// Set channel to start transaction
rabbitTemplate.setChannelTransacted(true);
@Bean
public RabbitTransactionManager rabbitTransactionManager(ConnectionFactory connectionFactory)
{
return new RabbitTransactionManager(connectionFactory);
}
@Transactional(rollbackFor = Exception.class,transactionManager = "rabbitTransactionManager")
public void publishMessage(String message) throws Exception {
rabbitTemplate.setMandatory(true);
rabbitTemplate.convertAndSend("javatrip",message);
}
Because the transaction message mechanism will seriously reduce the performance, this method is generally not used because it is a synchronous operation. After a message is sent, the sender will block to wait for the response of rabbitmq server, and then continue to send the next message. The throughput and performance of the producer's production messages will be greatly reduced.
confirm message confirmation mechanism
As the name suggests, once the message delivered by the production end is delivered to RabbitMQ, RabbitMQ will send a confirmation message to the production end to let the production end know that I have received the message, otherwise the message may have been lost and the production end needs to resend the message.
# Enable send confirmation spring.rabbitmq.publisher-confirm-type=correlated # Enable send failure fallback spring.rabbitmq.publisher-returns=true
@Configuration
@Slf4j
public class RabbitMQConfig {
@Autowired
private RabbitTemplate rabbitTemplate;
@PostConstruct
public void enableConfirmCallback() {
//confirm listens. When the message is successfully sent to the switch, ack = true, but not sent to the switch, ack = false
//correlationData specifies the unique id of the message when it is sent
rabbitTemplate.setConfirmCallback((correlationData, ack, cause) -> {
if(!ack){
//Record logs, send email notifications, and scan and resend scheduled tasks when the inventory is dropped
}
});
//This listening is triggered when the message is successfully sent to the switch and is not routed to the queue
rabbitTemplate.setReturnsCallback(returned -> {
//Record logs, send email notifications, and scan and resend scheduled tasks when the inventory is dropped
});
}
}
In fact, there are not many retransmissions in these two monitors, because the cost is too high. Firstly, the possibility of losing RabbitMQ itself is very low. Secondly, if you need to drop the database here and then scan retransmission with scheduled tasks, you also need to develop a pile of code, distributed scheduled tasks... And then scan with secondary scheduled tasks, which will certainly increase the message delay, which is not very necessary. The real business scenario is to record the log to facilitate the problem backtracking. By the way, send an email to relevant personnel. If it is really extremely rare that the producer loses the message, the developer can supplement the data to the database.
Message persistence
After receiving the message, RabbitMQ temporarily stores the message in memory. If RabbitMQ hangs, the data will be lost after restart. Therefore, the relevant data should be persisted to the hard disk, and exchange, queue and message should be persisted.
@Bean
public Queue TestQueue() {
// durable: whether to persist. The default value is false. Persistent queue: it will be stored on the disk. It still exists when the message agent restarts. Temporary queue: the current connection is valid
// exclusive: whether the queue is for consumption by only one consumer, whether message sharing is carried out, true can be consumed by multiple consumers, false: only - one consumer can consume
// autoDelete: whether to delete automatically. When no producer or consumer uses this queue, the queue will be deleted automatically.
return new Queue("test",true,true,false);
}
In Spring Boot, messages are persistent by default.
Message warehousing
Message warehousing, as the name suggests, is to save the message to be sent to the database.
Save the message to the database before sending the message. There is a status field status=0, which indicates that the message has been sent but has not received confirmation; After receiving the confirmation, set the status to 1 to indicate that RabbitMQ has received the message.
The production side also needs to open a timer to regularly retrieve the message table. After the status=0 and exceeds the fixed time
(it may be that the message has just been sent and has not been confirmed in time. The timer here just retrieves the message with status=0, so it is necessary to set the time)
Take out and resend the message that has not received the confirmation (message resending may cause idempotency problem, and the consumer needs to do idempotency processing here), and the resending may fail. Therefore, a maximum number of resends field retry should be added_ Count. If it exceeds, do another processing.
The production side timer can use: XXL job - distributed task scheduling platform to do this
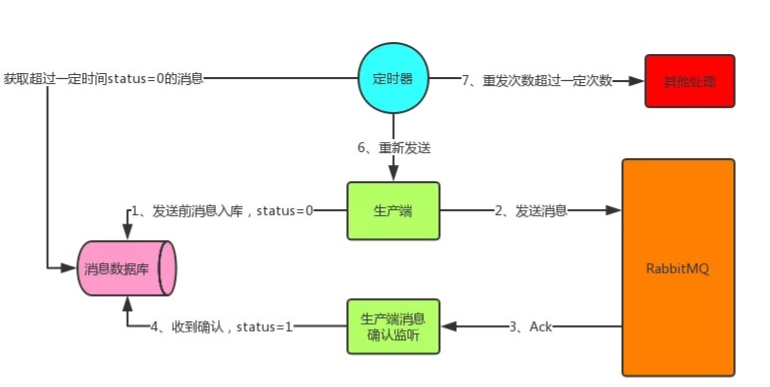
In this way, the message can ensure the reliability of the production end
Consumer reliability delivery
Change ACK mechanism to manual
RabbitMQ's automatic ack mechanism deletes the message immediately after it is sent by default, regardless of whether the consumer receives it or processes it.
We need manual consumption
#When the manual ack is enabled, the ACK confirmation must be sent when the message is consumed, otherwise the message will always be in the queue spring.rabbitmq.listener.simple.acknowledge-mode=manual


Be careful here! The third parameter of the basicNack method represents whether to return to the queue. Generally, the error reporting of the code will not be solved by retry, so this situation may be: continue to be consumed, continue to report errors, return to the queue, continue to be consumed... Dead cycle.
There must be a limit on the number of times to resend messages, or don't join the queue at all. It's OK to send it to Redis for recording.
Retry the message provided by SpringBoot
SpringBoot provides us with a retry mechanism. When the business method executed by the consumer reports an error, it will retry the execution of the consumer business method.
Enable the retry mechanism provided by SpringBoot
spring.rabbitmq.listener.simple.retry.enabled=true # retry count spring.rabbitmq.listener.simple.max-attempts=3 # Retry interval spring.rabbitmq.listener.simpleinitial-interval: 3000
Consumer code
@RabbitListener(queues = "queue")
public void listen(String object, Message message, Channel channel) throws IOException {
try {
/**
* Execute business code
* */
int i = 1 / 0; //Intentional error reporting test
} catch (Exception e) {
log.error("Sign in failed", e);
/**
* Record the log, send the email and save the message to the database. Judge before dropping the message. If the message has been dropped, it will not be saved
* */
throw new RuntimeException("Message consumption failed");
}
}
Note that you must manually throw an exception, because the spring boot trigger retry is determined based on the occurrence of an uncapped exception in the method. It is worth noting that this retry is provided by SpringBoot to re execute the consumer method instead of letting RabbitMQ re push the message.