rabbitMQ learning (II) advanced features and clusters
When we study middleware, it is often easy to get started (just be able to use API), but to achieve high availability and high performance of MQ, we still need to know some of its advanced features.
Advanced features of rabbitMQ
Ensure the reliability of MQ
Students who have studied TCP protocol know that TCP protocol ensures the reliability of data transmission through confirmation mechanism, retransmission mechanism and so on.
The moves are the same. rabbitMQ also provides similar mechanisms to ensure that our producer's messages are received and used normally by consumers.
Let's first review the sending process of rabbitMQ message (consider the simplest version first):
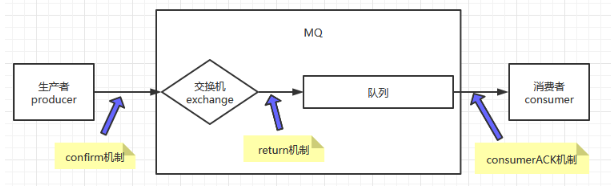
It can be seen that our transmission is mainly composed of three parts, and there are three corresponding mechanisms to ensure the reliability of these three parts.
confirm mechanism
The message sent by the producer can reach the reliability of the switch, which is guaranteed by the confirm mechanism.
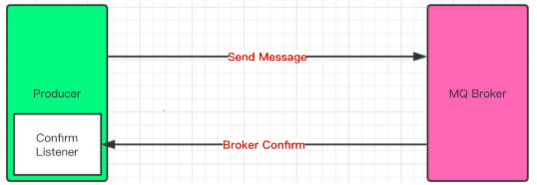
For each message sent, MQ will return a flag indicating whether it has arrived at the switch successfully. After that, we can choose different processing methods.
This mechanism is implemented by callback:
channel.confirmSelect(); // This code indicates that the confirmation mode is selected
channel.addConfirmListener(new ConfirmListener() {
public void handleAck(long l, boolean b) throws IOException { // success
System.out.println(b);
System.out.println(l);
System.out.println("chenggong");
}
public void handleNack(long l, boolean b) throws IOException { // fail
System.out.println(b);
System.out.println(l);
System.out.println("shibai");
}
});
return mechanism
We use the return mechanism to ensure whether the switch can find the corresponding routing queue for message storage.
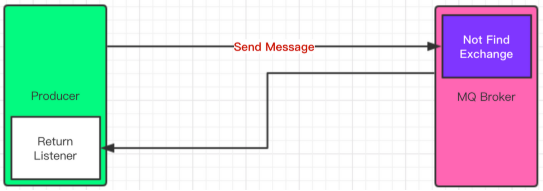
For every message that does not find a route, we can get the information of the message through callback, so as to make different choices.
channel.addReturnListener(new ReturnCallback() {
public void handle(Return aReturn) {
System.out.println(new String(aReturn.getBody())); // Get the message class content
System.out.println(aReturn.getExchange()); // Switch to get message
System.out.println(aReturn.getRoutingKey()); // Get the routing information of the message
}
});
Consumer ack mechanism
For whether our messages are processed normally, MQ provides a ConsumerACK mechanism to put the messages back into the queue:
channel.basicConsume("test", false, new DefaultConsumer(channel){ // Note: the second parameter (automatic reply) needs to be set to false, otherwise it will not take effect
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
System.out.println(new String(body));
channel.basicNack(envelope.getDeliveryTag(), false, true); // basicNack indicates that the message processing fails and the message is put back into the queue
//channel.basicAck(envelope.getDeliveryTag(), false); // Indicates that the message was processed successfully
}
});
Message management
Current limiting
rabbitMQ provides us with a flow limiting mechanism to prevent the consumer from crashing due to excessive message stacking.
Just one line of code:
channel.basicQos(0, 3, false); // The first parameter indicates the message size limit (0 means no limit). The second parameter indicates the number of messages consumed at one time. The third parameter indicates whether we apply this setting to channel
TTL
At the same time, in order to solve the problem of too many message stacks, MQ also supports the setting of message expiration time.
MQ supports two ways to set the expiration time. The first is that each message can set a separate expiration time through the parameter setting during sending:
AMQP.BasicProperties properties = new AMQP.BasicProperties().builder()
.deliveryMode(2)
.contentEncoding("UTF-8")
.expiration("100000") // Expiration time of 100s
.headers(headers)
.build();
String msg = "test message";
channel.basicPublish("", queueName, properties, msg.getBytes());
The second is to set the expiration time for the queue. All messages in the queue will be deleted after the expiration time.
Dead letter queue
In the previous section, we said that the message will be deleted after the expiration time. Is this really safe? Our approach should be to put the message into another queue for consumption. This is the dead letter queue.
Dead letter queue: a queue in which messages that have not been consumed in time are stored.
Are those messages not even consumed?
- Expired messages mentioned above
- Messages after reaching the maximum queue length
- The message was rejected and redelivery was not set
Delay queue
The delay queue can realize the delayed sending of messages, that is, the consumer will read after N long time.
For example, in the order payment scenario, we need to judge whether to pay 15 minutes after the order is created, which can be realized by using the delay queue.
rabbitMQ does not directly implement the function of delay queue, but combined with our above knowledge, we find that delay queue can be implemented through dead letter queue and TTL.
That is, set the expiration time for a queue. When the expiration time expires, it will be sent to a dead letter queue for processing.
colony
In order to ensure high availability of MQ, rabbitMQ also supports cluster mode.
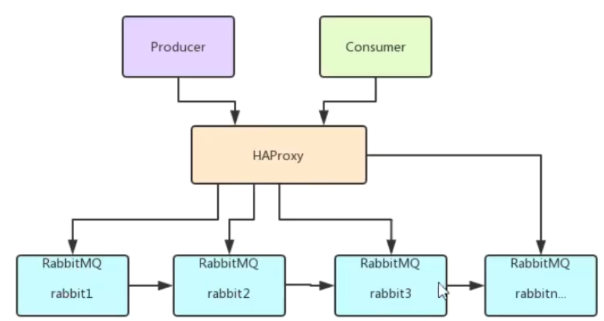
As shown in the figure, rabbitMQ uses a mirror queue to ensure that the entire MQ is unavailable after a node crashes.
Each MQ node will actively synchronize, but this method will also greatly consume the internal bandwidth of the system.