Random forest
-
Random forest is a supervised learning algorithm, which is an integrated learning algorithm based on decision tree. Random forest is very simple, easy to implement, and the computational cost is very small. It shows amazing performance in classification and regression. Therefore, random forest is known as "a method representing the level of integrated learning technology"
-
The randomness of random forest
- Random selection of data sets
- Sampling bagging with return is adopted from the original data set to construct the sub data set. The data volume of the sub data set is the same as that of the original data set. The elements of different sub data sets can be repeated, and the elements of the same sub data set can also be repeated
- Random selection of features to be selected
- Each splitting process of the subtree in the random forest does not use all the features to be selected, but selects a certain feature randomly from all the features to be selected, and then selects the best feature from the randomly selected features
- Random selection of data sets
-
The important role of random forest
- It can be used for classification problems and regression problems
- It can solve the problem of model over fitting. If there are enough trees in the random forest, the classifier will not have over fitting
- The importance of features can be detected and good features can be selected
-
Construction process of random forest
- 1. Randomly put back samples from the original data set, take M samples and generate m training sets
- 2. Train m decision tree models for M training sets
- 3. For a single decision tree model, assuming that the number of features of the training sample is n, the best feature is selected for splitting according to the information gain / information gain ratio / Gini coefficient
- The final classification result of multiple decision trees will be generated randomly according to the decision tree of the classifier; For the regression problem, the final prediction result is determined by the mean value of the predicted values of multiple trees
-
advantage
- The integrated algorithm is adopted, and its accuracy is higher than that of most single algorithms
- Two randomness are introduced, so that the random forest is not easy to fall into over fitting (random samples and random characteristics)
- The introduction of two randomness makes the random forest have certain anti noise ability, which has certain advantages compared with other algorithms
- It can process data with high dimensions (many features) and make feature selection differently, so it has strong adaptability to the data set: it can process both discrete data and continuous data
- In the training process, the interaction between features can be detected, and the importance of features can be obtained, which has a certain reference significance
-
shortcoming
- When there are many decision trees in the random forest, the space and time required for training will be large
Implementation of classified random forest
-
classification
- from sklearn.ensemble import RandomForestClassifier
-
parameter

- n_estimators: the number of trees, that is, the number of base evaluators. The influence of this parameter on the accuracy of random forest model is monotonous, n_ The larger the estimators, the better the effect of the model. However, any model has a decision boundary, n_ After the estimators reach a certain degree, the accuracy of random forest often does not rise or begin to fluctuate, and n_ The larger the estimators, the larger the amount of computation and memory required, and the longer the training time. For this parameter, we hope to strike a balance between the difficulty of training and the effect of the model; The default value is 10 in the existing version of sklearn, but in the upcoming version of 0.22, this default value will be revised to 100
- random_state: control the mode of forest generation, which is used to fix the randomness of trees in the forest_ When the state is fixed, a set of fixed trees are generated in the random forest
- bootstrap: control sampling technology parameter. bootstrap is TRUE by default, which means random sampling technology with return is adopted
- oob_score: samples that are ignored or not collected at one time are called obb out of bag data; That is, when using random forest, the test set and training set can not be divided, and the data outside the bag can be used to test; Will oob_score=True. After training, you can use obb_score_ View the test results on the data outside the bag
Examples
-
Effect comparison between random forest and decision tree
from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import RandomForestClassifier from sklearn.datasets import load_wine from sklearn.model_selection import train_test_split wine=load_wine() #Comparison between random forest and decision tree x_train,x_test,y_train,y_test=train_test_split(wine.data,wine.target,test_size=0.3) clf=DecisionTreeClassifier(random_state=0) rfc=RandomForestClassifier(random_state=0) clf=clf.fit(x_train,y_train) rfc=rfc.fit(x_train,y_train) score_c=clf.score(x_test,y_test) score_r=rfc.score(x_test,y_test) print(score_c,score_r) #0.8518518518518519 0.9629629629629629
-
Comparison between random forest and decision tree under a set of cross validation
from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import RandomForestClassifier from sklearn.datasets import load_wine from sklearn.model_selection import cross_val_score import matplotlib.pyplot as plt %matplotlib inline wine=load_wine() rfc=RandomForestClassifier(n_estimators=25) rfc_s=cross_val_score(rfc,wine.data,wine.target,cv=10) clf=DecisionTreeClassifier() clf_s=cross_val_score(clf,wine.data,wine.target,cv=10) plt.plot(range(1,11),rfc_s,label='RandomForest') plt.plot(range(1,11),clf_s,label='DecisionTree') plt.legend() plt.show()
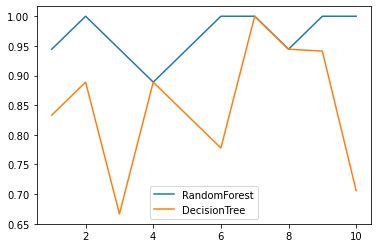
-
Comparison between random forest and decision tree under ten groups of cross validation
from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import RandomForestClassifier from sklearn.datasets import load_wine from sklearn.model_selection import cross_val_score import matplotlib.pyplot as plt %matplotlib inline wine=load_wine() rfc_l=[] clf_l=[] for i in range(10): rfc=RandomForestClassifier(n_estimators=25) rfc_s=cross_val_score(rfc,wine.data,wine.target,cv=10).mean() rfc_l.append(rfc_s) clf=DecisionTreeClassifier() clf_s=cross_val_score(clf,wine.data,wine.target,cv=10).mean() clf_l.append(clf_s) plt.plot(range(1,11),rfc_l,label="RangeForest") plt.plot(range(1,11),clf_l,label='DecisionTree') plt.legend() plt.show()
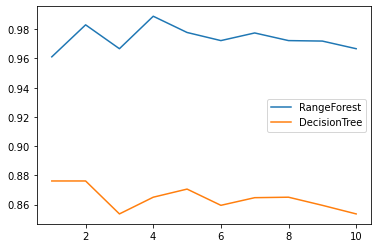
-
obb_score_ Important parameters
from sklearn.ensemble import RandomForestClassifier from sklearn.datasets import load_wine wine=load_wine() rfc=RandomForestClassifier(n_estimators=25,oob_score=True) rfc=rfc.fit(wine.data,wine.target) rfc.oob_score_ #0.9606741573033708
Realization of returning to the forest
- regression
- from sklearn.ensemble import RandomForestRegression
- All parameters, attributes and interfaces are consistent with the random classifier. The only difference is that the regression tree is different from the classification tree, and the impure index and parameter Criterion are inconsistent
- Criterion parameter
- Regression tree is an indicator to measure branch quality. There are three standards supported:
- mse: using the mean square error (mse), the difference between the mean square error between the parent node and the child node will be used as the standard of feature selection. This method minimizes L2 loss by using the mean value of leaf nodes
- friedman_mse: use Feldman mean square error. This index uses Feldman's improved mean square error for problems in potential branches
- mae: use mean absolute error, which uses the median of leaf nodes to minimize L1 loss
- Regression tree is an indicator to measure branch quality. There are three standards supported: