Case: (bottom)
1. Dynamic programming of metadata to convert RDD into DataFrame - > RDD2 Data Frame Programmatically
2. Reflect RDD-> DataFrame-> RDD2 DataFrame by Reflecting
After RDD is converted to DataFrame, we can use Spark SQL to query any data that can be built into RDD, such as HDFS. This function is extremely powerful. In this way, the data in HDFS can be queried directly using SQL.
Spark SQL supports two ways to convert RDD to DataFrame.
The first way is to use reflection to infer the metadata of RDDs that contain specific data types. This reflection-based approach, the code is relatively concise, when you already know your RDD metadata, is a very good way.
The second way is to create a DataFrame through a programming interface. You can dynamically build a metadata while the program is running, and then apply it to existing RDDs. The code in this way is rather lengthy, but if the metadata of RDD is not known when the program is written, the metadata of RDD can only be dynamically known when the program is running, then the metadata can only be dynamically constructed through this way.
Inference of metadata using reflection
Java version: Spark SQL supports the conversion of RDD s containing JavaBeans into DataFrame s. The information of JavaBean defines metadata. Spark SQL now does not support JavaBeans that contain complex data such as nested JavaBeans or List s as metadata. Only a JavaBean containing a field of simple data types is supported.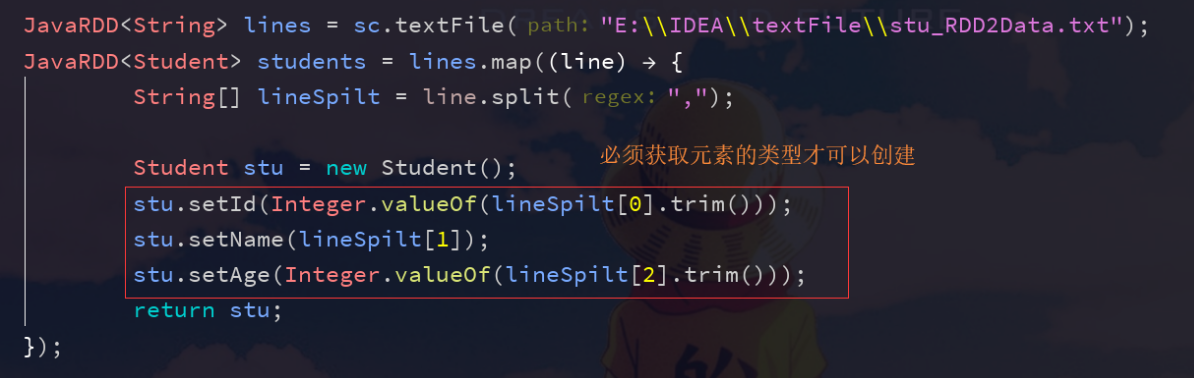
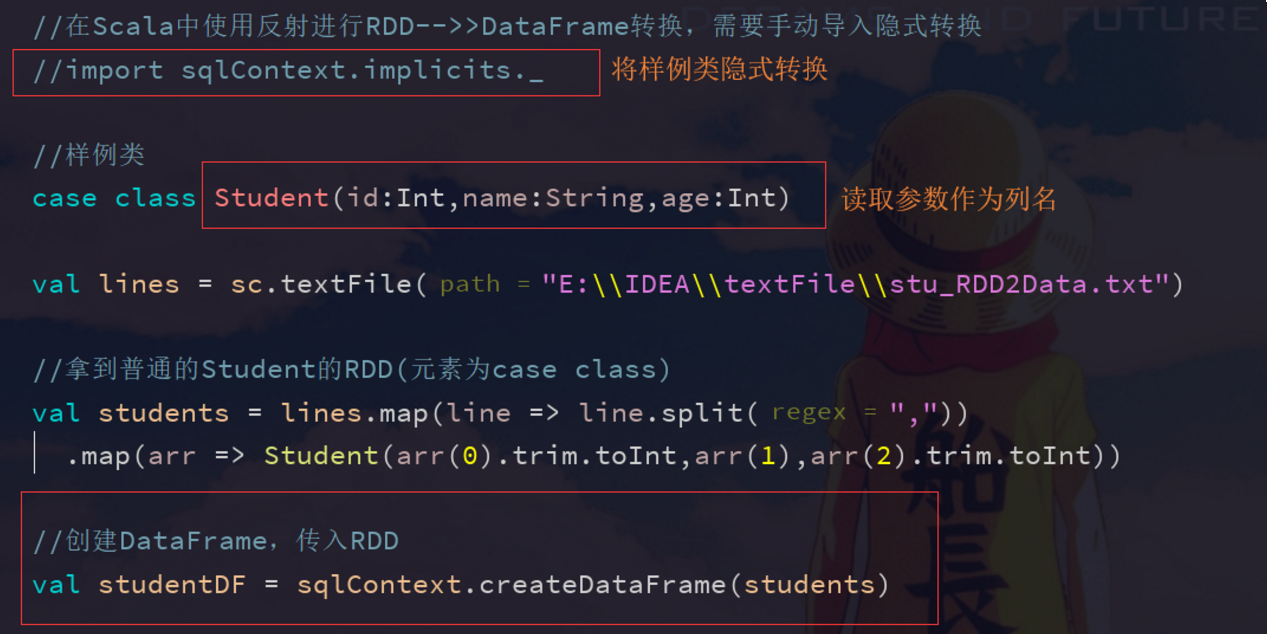
Scala Version: Because Scala has the characteristics of implicit transformation, the Scala interface of Spark SQL supports the automatic conversion of RDD containing case class to DataFrame. Case class defines metadata. Spark SQL reads the name of the parameter passed to the case class by reflection and then uses it as the column name. Unlike Java, Spark SQL supports case classes containing nested data structures as metadata, such as Array.
Specify metadata programmatically
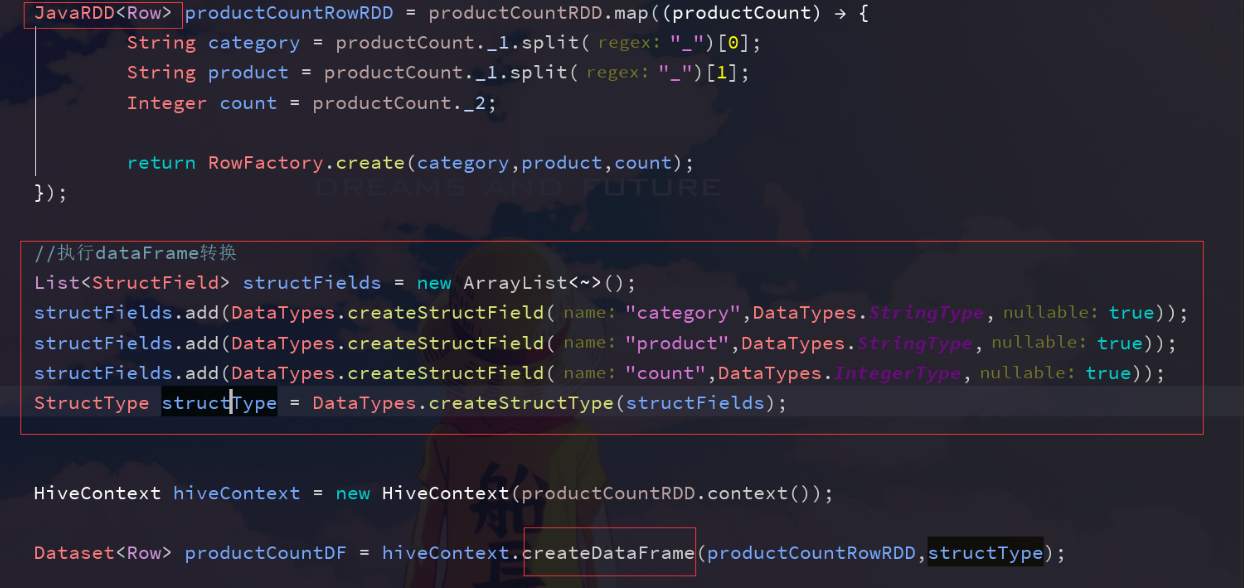
Java version: When JavaBean s cannot be predefined and known, for example, to dynamically read data structures from a file, metadata can only be dynamically specified programmatically. First, we need to create a RDD with Row element from the original RDD; secondly, we need to create a StructType to represent Row; finally, we apply the dynamically defined metadata to RDD < Row >.
Scala version: Scala is implemented in the same way as Java.
Data Frame to RDD:
DataFrame.javaRDD() or DataFrame.RDD()
Case 1:
java version:
package Spark_SQL;
import org.apache.spark.SparkConf;
import org.apache.spark.SparkContext;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SQLContext;
import java.util.List;
/**
* @Date: 2019/3/12 14:36
* @Author Angle
*/
/*
* RDD-> DataFrame with Reflection
*
* */
public class RDD2DataFrameReflect {
public static void main(String[] args){
//Create a plain RDD
SparkConf conf = new SparkConf().setAppName("RDD2DataFramReflect").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(sc);
JavaRDD<String> lines = sc.textFile("E:\\IDEA\\textFile\\stu_RDD2Data.txt");
JavaRDD<Student> students = lines.map(new Function<String, Student>() {
@Override
public Student call(String line) throws Exception {
String[] lineSpilt = line.split(",");
Student stu = new Student();
stu.setId(Integer.valueOf(lineSpilt[0].trim()));
stu.setName(lineSpilt[1]);
stu.setAge(Integer.valueOf(lineSpilt[2].trim()));
return stu;
}
});
//Using Reflection to Convert RDD into DataFrame
//To import Student.class is to take advantage of reflection, which is an application of reflection.
//The bottom layer reflects through Student Class to get its field
Dataset<Row> studentDF = sqlContext.createDataFrame(students, Student.class);
//Once you get the DataFrame table, register it as a temporary table for SQL against its data
//JavaBean is required to implement serialized interface Serializable
studentDF.registerTempTable("student");
//For temporary table operation, the query age of SQL - > is less than 18
Dataset<Row> teenagerDF = sqlContext.sql("select * from student where age<=18");
//Discovered DataFrame, converted to RDD
JavaRDD<Row> teenagerRDD = teenagerDF.javaRDD();
//Mapping RDD data to Student
JavaRDD<Student> teeStudentRDD = teenagerRDD.map(new Function<Row, Student>() {
@Override
public Student call(Row row) throws Exception {
//The order of data in row may differ from expectation
Student stu = new Student();
stu.setAge(row.getInt(0));
stu.setId(row.getInt(1));
stu.setName(row.getString(2));
return stu;
}
});
//collect the data back and print it out
List<Student> studentList = teeStudentRDD.collect();
for (Student stu:studentList){
System.out.println(stu);
}
}
}
scala version:
package SparkSQL_Scala
import org.apache.spark.sql.SQLContext
import org.apache.spark.{SparkConf, SparkContext}
/**
* @Date: 2019/3/12 16:48
* @Author Angle
*/
/*
* To develop Spark program with scala
*In order to realize the conversion from reflective RDD to DataFrame, the object extends App mode must be used.
* It can't be run in def main() mode, otherwise it will make an error: no typetag for class.
*
* */
object RDD2DataFrameReflect_s extends App {
val conf = new SparkConf().setAppName("RDD2DataFrameReflect_S").setMaster("local")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
//Using reflection for RDD - > DataFrame transformation in Scala requires manual import of implicit transformation
//import sqlContext.implicits._
//case class
case class Student(id:Int,name:String,age:Int)
val lines = sc.textFile("E:\\IDEA\\textFile\\stu_RDD2Data.txt")
//Get the normal Student's RDD (the element is case class)
val students = lines.map(line => line.split(","))
.map(arr => Student(arr(0).trim.toInt,arr(1),arr(2).trim.toInt))
//Create a DataFrame and pass it in to RDD
val studentDF = sqlContext.createDataFrame(students)
//Temporary Register Form
studentDF.registerTempTable("students");
val teenagerDF = sqlContext.sql("select * from students where age<=18")
//Convert to RDD
val teenagerRDD = teenagerDF.rdd
//Order - > age-name-id
//In scala, the order of data in row is sorted according to our expectations, which is different from that in java.
teenagerRDD.map(row => Student(row(0).toString.toInt,row(1).toString,row(2).toString.toInt))
.collect()
.foreach(stu => println(stu.id + ":" + stu.name + ":" + stu.age))
//The use of row in scala is richer than that in java
//The getAs() method of row can be used in scala to obtain columns with specified column names.
teenagerRDD.map(row => Student(
row.getAs[Int]("id"), row.getAs[String]("name"),row.getAs[Int]("age")))
.collect()
.foreach(stu => println(stu.id + ":" + stu.name + ":" +stu.age))
//The getValuesMap() method of row can be used to get the values of the specified columns, and a map is returned.
teenagerRDD.map(row => {
val map = row.getValuesMap[Any](Array("id","name","age"))
Student(map("id").toString.toInt,map("name").toString,map("age").toString.toInt)
})
.collect()
.foreach(stu => println(stu.id + ":" + stu.name + ":" + stu.age))
}
Case two:
Java version:
package Spark_SQL;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.types.DataType;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
import java.lang.reflect.Array;
import java.util.ArrayList;
import java.util.List;
/**
* @Date: 2019/3/13 18:59
* @Author Angle
*/
/*
* Programmatically specify metadata dynamically and convert RDD to DataFrame
*
* */
public class RDD2DataFrameProgrammatically {
public static void main(String[] args){
SparkConf conf = new SparkConf().setAppName("RDD2DataFrameProgrammatically").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(sc);
//1. Create a normal RDD, but convert it to RDD < row> format
JavaRDD<String> linesRDD = sc.textFile("E:\\IDEA\\textFile\\stu_RDD2Data.txt");
//When you plug data into Row, you should pay attention to: type!!
JavaRDD<Row> studentRDD = linesRDD.map(new Function<String, Row>() {
@Override
public Row call(String line) throws Exception {
String[] lineSpilt = line.split(",");
//Integer type is used later, so String type should be converted to Integer
return RowFactory.create(Integer.valueOf(lineSpilt[0]),lineSpilt[1],Integer.valueOf(lineSpilt[2]));
}
});
//II. Dynamic Construction of Metadata
//Types such as id, name, etc., which may be loaded from mysql or configuration files during program running are not fixed - > suitable for this dynamic construction
ArrayList<StructField> structFields = new ArrayList<StructField>();
structFields.add(DataTypes.createStructField("id",DataTypes.IntegerType,true));
structFields.add(DataTypes.createStructField("name",DataTypes.StringType,true));
structFields.add(DataTypes.createStructField("age",DataTypes.IntegerType,true));
StructType structType = DataTypes.createStructType(structFields);
//3. Converting RDD into DataFrame
Dataset<Row> stuDF= sqlContext.createDataFrame(studentRDD,structType);
//Register as student_s table
stuDF.registerTempTable("student_s");
Dataset<Row> teenagerDF = sqlContext.sql("select * from student_s where age<=18");
//Data pull to local
List<Row> rows = teenagerDF.javaRDD().collect();
for (Row row:rows){
System.out.println(row);
}
}
}
scala version:
package SparkSQL_Scala
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SQLContext}
import org.apache.spark.{SparkConf, SparkContext}
/**
* @Date: 2019/3/13 20:22
* @Author Angle
*/
object RDD2DataFrameProgrammatically_s {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("RDD2DataFrameProgrammatically_s").setMaster("local")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
//I. Common RDD with Row as the Constructing Element
val lines = sc.textFile("E:\\IDEA\\textFile\\stu_RDD2Data.txt",1)
.map{line => Row(line.split(",")(0).toInt,line.split(",")(1),line.split(",")(2).toInt)}
//2. Dynamic Construction of Metadata by Programming Method
val structType = StructType(Array(
StructField("id",IntegerType,true),
StructField("name",StringType,true),
StructField("age",IntegerType,true)))
//Conversion from RDD to DataFrame
val studentDF = sqlContext.createDataFrame(lines,structType)
//register
studentDF.registerTempTable("student_s")
val teenagerDF = sqlContext.sql("select * from student_s where age<=19")
val teenagerRDD = teenagerDF.rdd.collect()
.foreach(row => println("id:" + row.get(0) + " name:" + row.get(1) + " age:" +row.get(2)))
}
}
Next, we will update Spark knowledge slowly. If you have any questions, please correct them.