preface
I believe that this article is not the first time for my classmates to see articles about HashMap. Most of the online HashMap articles are not suitable for me, so I decided to understand the source code from scratch. I will use the relatively simple logic to convince myself to understand the source code. If you are interested, please look down a bit
0. Know the class header of HashMap
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
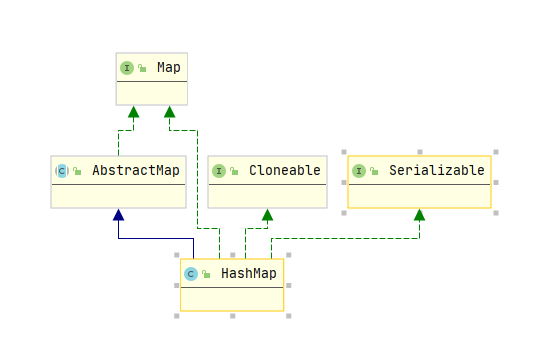
HashMap inherits abstracttmap to obtain some common map APIs, such as containsValue put set, etc
The clonable interface is just an identifier. HashMap rewrites the clone method, and the return value of the method is a copy of the HashMap instance (object). See the following for details: clone method of HashMap
The Serializable interface identifies that HashMap can be serialized and transmitted. There are two methods about Serializable. I didn't go deep into them. Students in need can study them by themselves
/**
* Save the state of the <tt>HashMap</tt> instance to a stream (i.e.,
* serialize it).
*
* @serialData The <i>capacity</i> of the HashMap (the length of the
* bucket array) is emitted (int), followed by the
* <i>size</i> (an int, the number of key-value
* mappings), followed by the key (Object) and value (Object)
* for each key-value mapping. The key-value mappings are
* emitted in no particular order.
*/
private void writeObject(java.io.ObjectOutputStream s)
throws IOException {
int buckets = capacity();
// Write out the threshold, loadfactor, and any hidden stuff
s.defaultWriteObject();
s.writeInt(buckets);
s.writeInt(size);
internalWriteEntries(s);
}
/**
* Reconstitute the {@code HashMap} instance from a stream (i.e.,
* deserialize it).
*/
private void readObject(java.io.ObjectInputStream s)
throws IOException, ClassNotFoundException {
// Read in the threshold (ignored), loadfactor, and any hidden stuff
s.defaultReadObject();
reinitialize();
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new InvalidObjectException("Illegal load factor: " +
loadFactor);
s.readInt(); // Read and ignore number of buckets
int mappings = s.readInt(); // Read number of mappings (size)
if (mappings < 0)
throw new InvalidObjectException("Illegal mappings count: " +
mappings);
else if (mappings > 0) { // (if zero, use defaults)
// Size the table using given load factor only if within
// range of 0.25...4.0
float lf = Math.min(Math.max(0.25f, loadFactor), 4.0f);
float fc = (float)mappings / lf + 1.0f;
int cap = ((fc < DEFAULT_INITIAL_CAPACITY) ?
DEFAULT_INITIAL_CAPACITY :
(fc >= MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY :
tableSizeFor((int)fc));
float ft = (float)cap * lf;
threshold = ((cap < MAXIMUM_CAPACITY && ft < MAXIMUM_CAPACITY) ?
(int)ft : Integer.MAX_VALUE);
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] tab = (Node<K,V>[])new Node[cap];
table = tab;
// Read the keys and values, and put the mappings in the HashMap
for (int i = 0; i < mappings; i++) {
@SuppressWarnings("unchecked")
K key = (K) s.readObject();
@SuppressWarnings("unchecked")
V value = (V) s.readObject();
putVal(hash(key), key, value, false, false);
}
}
}
1. Interpretation of main parameters of HashMap
First write down the function of parameters, and then look at the code to get twice the result with half the effort
/*HashMap Default maximum capacity of 1 < < 4 = = 16*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
/*Hash Map The maximum capacity of 2 ^ 30, but this is not the real maximum capacity of HashMap?*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/*The default loading factor. You can decide the size of the loading factor yourself when transferring parameters*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/*When the length of the linked list is greater than 8, it will change into a red black tree. Is it greater than or equal to*/
static final int TREEIFY_THRESHOLD = 8;
/*When the length of red black uncle is less than 6, it will degenerate into a linked list again*/
static final int UNTREEIFY_THRESHOLD = 6;
/*The minimum capacity to convert a linked list into a tree requires 64*/
static final int MIN_TREEIFY_CAPACITY = 64;
/*Record the number of elements in the HashMap*/
transient int size;
/*It is used to record the number of changes in the internal structure of HashMap*/
transient int modCount;
/*Indicates the critical value of the key value pair that can be accommodated. If it exceeds this value, hashmap will be expanded
Calculation formula = array length * loadFactor*/
int threshold;
/*The loading factor defaults to 0.75f*/
final float loadFactor;
To sum up: use a diagram to illustrate the relationship between the above parameters
2. Understanding of node class
//I think there are so many key parts
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next; //Linked list
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value;}
}
//hash algorithm
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
The incoming value of the incoming node is obtained through a disturbance of the key value of the node, but after hashing, there will be hash collision (hash collision is complex, and a separate explanation will be written). hashmap will store the conflict data in the form of array and linked list, as shown in the following figure (from the grumpy little Liu in station B)
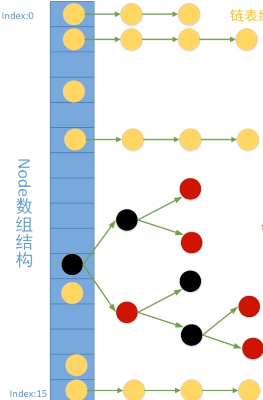
When the length of the linked list is greater than 8 and the number of nodes is greater than 64, it will be converted to Red black tree , when the number of nodes is less than 6, it will degenerate into a linked list. The reason is that the search time complexity of the linked list. When the O(n) red black tree is O(nlogn) tree, the search is faster than the linked list
Then there's a question. Why don't you use trees so fast?
I think it is because the insertion cost and deletion cost of red black tree are much higher than that of linked list, so I choose linked list plus red black tree In the final analysis, everything is to improve efficiency
Phased summary
It's really hard and painful to see the source code, but the hard code is also written by people. If they can write it, we can write it However, at present, we still need to watch the code written by the big guys, learn more and imitate more, and strive to reach the height of the big guys as soon as possible
Next goal
The next few articles should analyze the source code of the main functions of HashMap
After I sort it out, I will add a link here
I also hope that those who see this article can put forward their opinions on this article. No matter where it is unclear and where it needs to be expanded, they can tell me in the comment area to help each other and grow together
Collect and pay attention, and don't get lost next time I will keep updating Hope to see the code friend code of this article