
preface
I'm going to open a new series, which is a new field I haven't touched much before, called performance tuning.
When I read the word "performance tuning" when I was brushing my blog, I was stunned and felt that time had stagnated.
I found that I didn't know the performance level of the project code I wrote. Even if it was bad, I didn't know how bad it was. I use middleware and don't know their performance.
This is not good.
This series is based on the third edition of high performance MySQL and is my study notes.
MySQL architecture and history
MySQL s Logical Architecture

The second layer architecture is an interesting part of MySQL. Most of the core service functions of MySQL are in this layer, including addition, deletion, query, modification and all built-in functions.
All functions across storage engines are implemented in this layer, including stored procedures, triggers, views, etc.
The third layer contains the storage engine, which is responsible for the storage and extraction of data in MySQL. Each storage engine has its own advantages and disadvantages. The server communicates with the storage engine through API. These interfaces mask the differences between different storage engines, making these differences transparent to the upper layer operation. The storage engine will not parse SQL(InnoDB is an exception because the MySQL server itself does not implement this function). Different storage engines will not communicate with each other, but simply respond to the requests of the upper server.
Connection management
Each client will have a thread in the server process. The query of this connection will only be executed in this separate thread. This thread can only run in a CPU core or CPU in turn.
Server thread pool. Therefore, there is no need to create or destroy threads for each new connection.
Optimization and execution
MySQL parses the query, creates an internal data structure (parse tree), and then optimizes it, including rewriting the query, determining the reading order of the table, and selecting the appropriate index. Users can prompt the optimizer through special keywords to affect its decision-making process. You can also request the optimizer to explain various factors in the optimization process, so that users can know how the server makes optimization decisions, and provide a reference standard for users to reconstruct queries and schema s, modify relevant configurations, and make the application run as efficiently as possible.
For the SELECT statement, the server will check the query cache before parsing the query. If the corresponding query can be found in it, the server does not have to perform the whole process of query parsing, optimization and execution.
concurrency control
Read locks: sharing
Write lock: exclusive
In fact, I really don't know what the meaning of this read lock is and whether it needs to be implemented.
Lock granularity
One way to improve the concurrency of shared resources is to make locking objects more selective. Try to lock only part of the data that needs to be modified, not all resources. A more ideal way is to precisely lock only the data slices that will be modified.
The problem is that managing locks also requires system overhead. The so-called lock strategy is to find a balance between lock overhead and data security.
Watch lock
Table locking is the most basic locking strategy in MySQL and the least expensive strategy. It locks the entire table.
Row level lock
Row level locks can support concurrent processing to the greatest extent (and also bring the largest lock overhead)
affair
A transaction is a set of atomic SQL queries. All statements in the transaction are either executed successfully or rolled back.
ACID:
Atomicity: a transaction must be regarded as an indivisible minimum unit of work. Consistency: rollback. Isolation: changes made by a transaction are invisible to other transactions before they are committed. Persistence: once a transaction is committed, its changes will be permanently saved to the database.
Isolation level
Isolation is actually more complex than thought. The following is a brief introduction to the four isolation levels.
Uncommitted read: the performance consumption is large and useless. Don't look unless you really have a necessary reason.
Submit read: it is the above definition. It can only be read after submitting, so it is called submit read.
Repeatable reading: it solves the problem of dirty reading, but it can't solve the problem of phantom reading. The so-called phantom reading means that when a certain thing is reading a record in a certain range, another transaction inserts a new record in the range. When the previous transaction reads the record in the range again, a phantom line will be generated. InnoDB and XtraDB storage engines solve the problem of unreal reading through multi version concurrency control.
Repeatability is the default transaction isolation level of MySQL.
Serializability: This is the highest isolation level. It avoids the unreal reading problem mentioned above by forcing transactions to execute serially. However, the consumption is too large, so only when it is very necessary to ensure data consistency and acceptable that there is no concurrency, consider using this level.
Transaction log
Transaction log can effectively improve the efficiency of transactions, that is, pre realistic log.
Using the transaction log, when the storage engine modifies the data of the table, it only needs to modify its memory copy, and then record the modification behavior in the transaction log persistent on the hard disk, instead of persisting the modified data itself to the disk every time. The transaction log is appended, so the log writing operation is sequential I/O in a small area on the disk, rather than random I/O, which requires moving heads in multiple places on the disk.
Therefore, the transaction log method is relatively much faster. After the transaction log is persistent, the modified data in memory can be slowly brushed back to disk in the background.
If the data modification has been recorded in the transaction log and persisted, when the data itself has not been written back to the disk, the system crashes, and the storage engine can automatically reply to the modified data when it is restarted.
(refer to AOF)
Introduction to performance optimization
Performance: performance is the corresponding time, which is a very important principle. We measure performance by tasks and time, not resources.
The purpose of the database server is to execute SQL statements, so it focuses on queries or statements (query = = instructions sent to the server).
Optimization: we assume that optimization is to minimize the response time of the server under a certain workload.
Here comes the second principle: if you can't measure, you can't effectively optimize, so the first step should be to measure where the time is spent.
There are two situations that can lead to inappropriate measurements:
Start and stop the measurement at the wrong time It measures the aggregated information, not the target activity itself
The time required to complete a task can be divided into two parts: execution time and waiting time. If you need to optimize the execution time of a task, the best way is to measure and locate the time spent on different subtasks, and then optimize and remove some subtasks, reduce the execution frequency of subtasks, or improve the efficiency of subtasks. The waiting time of optimization tasks is relatively complex.
So how to confirm which subtasks are the optimization objectives? At this time, performance analysis can come in handy.
Optimized by performance profiling
Performance analysis generally has two steps: measuring the time spent on the task; Then sort the results and rank the important tasks first.
We will actually discuss two types of performance profiling: execution time based analysis and wait based analysis.
Time based analysis studies what tasks take the longest to execute, while wait based analysis determines where tasks are blocked the longest.
(I suddenly feel a little depressed. I can't read this chapter all the time. It's said to use explain outside, but I always think there is a more core problem. Can it be slow query log?)
Later, we will talk about a performance testing tool: Pt qurey digest. Let's look at it first.
Understanding performance profiling
1. Value optimized query
Performance profiling does not automatically give which queries are worth the time to optimize.
Optimize a query that accounts for no more than 5% of the total response time. No matter how hard you try, the revenue will not exceed 5%. Second, if you spend $1000 to optimize a task, but the business revenue does not increase, it can be said that it leads to the inverse optimization of the business. If the cost of optimization is greater than the benefit, optimization should be stopped.
2. Abnormal optimization
Some tasks need to be optimized even if they do not appear in front of the performance analysis output. For example, some tasks are executed very few times, but each execution is very slow, which seriously affects the user experience. Because of its low execution frequency, the proportion of total response time is not prominent.
3. Unknown unknown
You know, tools always have limitations.
Parsing MySQL queries
In the current version of MySQL, slow query log is a tool to measure query time with the lowest cost and the highest accuracy. The I/O cost caused by slow query log is negligible. What needs to be worried is that the log may consume a lot of disk space. If the slow query log is enabled for a long time, pay attention to deploying the log rotation tool. Or don't start the slow query log for a long time, just start it during the period when you need to collect load samples.
Slow query log
MySQL slow query log is an important function for troubleshooting SQL statements and checking the current MySQL performance.
- Check whether the slow query function is enabled:
mysql> show variables like 'slow_query%'; +---------------------+-----------------------------------+ | Variable_name | Value | +---------------------+-----------------------------------+ | slow_query_log | OFF | | slow_query_log_file | /var/lib/mysql/localhost-slow.log | +---------------------+-----------------------------------+
mysql> show variables like 'long_query_time'; +-----------------+-----------+ | Variable_name | Value | +-----------------+-----------+ | long_query_time | 10.000000 | +-----------------+-----------+
slow_query_log slow query on status
slow_query_log_file slow query log storage location (this directory needs the writable permission of MySQL running account, which is generally set as the data storage directory of MySQL)
long_ query_ How many seconds does the time query take to record
By default, slow query logging is not enabled. It is temporarily enabled by command:
set global slow_query_log='ON'; set global slow_query_log_file='/var/lib/mysql/instance-1-slow.log'; set global long_query_time=2;
Permanent configuration: (take it yourself, I won't be permanent)
Modify the configuration file to reach the permanent configuration state: /etc/mysql/conf.d/mysql.cnf [mysqld] slow_query_log = ON slow_query_log_file = /var/lib/mysql/instance-1-slow.log long_query_time = 2 After configuration, restart MySQL Just. test The problem is reached by running the following command SQL Statement execution: mysql> select sleep(2); +----------+ | sleep(2) | +----------+ | 0 | +----------+ 1 row in set (2.00 sec) Then view the contents of the slow query log: $ cat /var/lib/mysql/instance-1-slow.log
Do not directly open the whole slow query log for analysis, which will only waste time and money.
It is recommended to use Pt query digest to generate an analysis report. If necessary, you can view the parts that need attention in the log.
pt-query-digest
PT query digest is a tool for analyzing MySQL slow queries. It can analyze binlog, General log, slowlog, SHOWPROCESSLIST or MySQL protocol data captured through tcpdump. The analysis results can be output to the file. The analysis process is to parameterize the conditions of the query statement first, and then group and count the parameterized queries to calculate the execution time, times and proportion of each query. With the help of the analysis results, problems can be found and optimized.
Download:
wget https://www.percona.com/downloads/percona-toolkit/3.2.1/binary/redhat/7/x86_64/percona-toolkit-3.2.1-1.el7.x86_64.rpm
ls | grep percona-toolkit-3.2.1-1.el7.x86_64.rpm
PT tools are written and executed in Perl language, so a Perl environment is required in the system. Install related dependent packages,
[root@xxx ~]# yum install perl-DBI.x86_64 [root@xxx ~]# yum install perl-DBD-MySQL.x86_64 [root@xxx ~]# yum install perl-IO-Socket-SSL.noarch [root@xxx ~]# yum install perl-Digest-MD5.x86_64 [root@xxx ~]# yum install perl-TermReadKey.x86_64
To install the Percona Toolkit:
rpm -iv percona-toolkit-3.2.1-1.el7.x86_64.rpm
rpm -qa | grep percona
Tool directory installation path: / usr/bin
The download is as slow as the tortoise. I'll take some ready-made ones first. The acceleration package can't be parsed again..
Parse slow query log:
pt-query-digest /var/lib/mysql/VM_0_9_centos-slow.log > slow_report.log
The output results are divided into three parts:
Summary information
[root@VM_0_9_centos ~]# more slow_report.log # 230ms user time, 20ms system time, 26.35M rss, 220.76M vsz # CPU and memory usage information # Current date: Wed Aug 26 15:44:46 2020 # current time # Hostname: VM_0_9_centos # host name # Files: /var/lib/mysql/VM_0_9_centos-slow.log # Slow log path entered ## Summary information of the whole analysis results # Overall: 258 total, 37 unique, 0.02 QPS, 0.00x concurrency _____________ # Time range: 2020-08-26T11:20:16 to 2020-08-26T15:44:11 # Attribute total min max avg 95% stddev median # ============ ======= ======= ======= ======= ======= ======= ======= # Exec time 7s 249us 5s 26ms 4ms 311ms 657us # Lock time 349ms 0 152ms 1ms 348us 12ms 194us # Rows sent 33.01k 0 9.77k 131.03 755.64 742.92 0.99 # Rows examine 93.32k 0 9.77k 370.38 874.75 775.00 54.21 # Query size 51.71k 15 7.23k 205.23 223.14 615.30 143.84
Overall: How many queries are there in total? There are 2 queries in this example.58k(2580)Queries. Time range: Query execution time range. be careful, MySQL5.7 The time format in the version is different from the previous version. Unique: Unique query quantity, that is, the total number of different queries after parameterization of query criteria. This example is 10. Attribute: As shown in the above code snippet, indicates Attribute Column description Exec time,Lock time And other attribute names. total: express Attribute Column description Exec time,Lock time And other attributes. min: express Attribute Column description Exec time,Lock time The minimum value of the property. max: express Attribute Column description Exec time,Lock time The maximum value of the property. avg: express Attribute Column description Exec time,Lock time The average value of such attributes. 95%: express Attribute Column description Exec time,Lock time All values of attributes such as are arranged from small to large, and then take the value at 95%The value of the position (you need to focus on this value). stddev: Standard deviation, used for distribution statistics of values. median: express Attribute Column description Exec time,Lock time The median of such attributes, that is, arrange all values from small to large, and take the value in the middle
Part II:
Parameterize and group queries, and then analyze the execution of various queries. The results are arranged from large to small according to the total execution time
# Profile # Rank Query ID Response time Calls R/Call V/M It # ==== =============================== ============= ===== ====== ===== == # 1 0x59A74D08D407B5EDF9A57DD5A4... 5.0003 73.7% 1 5.0003 0.00 SELECT # 2 0x64EF0EA126730002088884A136... 0.9650 14.2% 2 0.4825 0.01 # 3 0x5E1B3DE19F673369DCF52FE6A5... 0.3174 4.7% 2 0.1587 0.00 INSERT data_million_a # 4 0x3992A499999D8F9E3ACC220E0F... 0.1334 2.0% 1 0.1334 0.00 ALTER TABLE dtb_table_size `dtb_table_size` # 5 0x66CAA645BA3ED5433EADC39CCA... 0.0991 1.5% 2 0.0495 0.08 SELECT data_million_a # MISC 0xMISC 0.2735 4.0% 250 0.0011 0.0 <32 ITEMS>
Rank: The number generated for the query indicates the ranking of the classification statement in the whole analysis result set. Query ID: Random string generated for query ID(Generated from fingerprint statement checksum Random string). Response time: The total response time of the query and the percentage of the total response time of all queries. Calls: The execution times of this query, that is, how many query statements of this type are there in this analysis. R/Call: The average response time for each execution of the query. V/M: The ratio of variance to mean of response time. Item: Specific query statement object (statement form of standardized format conversion: remove the specific select Field and table names where Conditions, etc.)
Part III:
Print the relevant statistics of each statement from the largest to the smallest according to the total execution time of the statement
# Query 1: 0 QPS, 0x concurrency, ID 0x59A74D08D407B5EDF9A57DD5A41825CA at byte 0 # Scores: V/M = 0.00 # Time range: all events occurred at 2020-08-26T11:20:16 # Attribute pct total min max avg 95% stddev median # ============ === ======= ======= ======= ======= ======= ======= ======= # Count 0 1 # Exec time 73 5s 5s 5s 5s 5s 0 5s # Lock time 0 0 0 0 0 0 0 0 # Rows sent 0 1 1 1 1 1 0 1 # Rows examine 0 0 0 0 0 0 0 0 # Query size 0 15 15 15 15 15 0 15 # String: # Hosts localhost # Users root # Query_time distribution # 1us # 10us # 100us # 1ms # 10ms # 100ms # 1s ################################################################ # 10s+ # EXPLAIN /*!50100 PARTITIONS*/ select sleep(5)\G
Time range: Query execution time range. be careful, MySQL5.7 The time format in the version is different from the previous version. Attribute: As shown in the above code snippet, indicates Attribute Column description Count,Exec time,Lock time And other attribute names. pct: Indicates the grouping statement (here refers to the above code segment)“ Query 1"Represents the grouping statements. The specific statement samples are shown in EXPLAIN ...There is output under the keyword. In addition, in the above code segment, such as total,min Equal calculated value All are grouped for this statement, which will not be described in detail below) total The ratio of the value (the statistical value of the grouping statement) to the total statistical value of all statements in the statistical sample. total: express Attribute Column description Count,Exec time,Lock time Statistics of attributes such as. min: express Attribute Column description Exec time,Lock time The minimum value of the property. max: express Attribute Column description Exec time,Lock time The maximum value of the property. avg: express Attribute Column description Exec time,Lock time The average value of such attributes. 95%: Indicates the corresponding of the statement Exec time,Lock time After the attribute values are sorted from large to small, they are at 95%The value of the position (you need to focus on this value). stddev: Standard deviation, used for distribution statistics of values. median: Represents the median of the corresponding attribute value. Arrange all values from small to large, and take the value in the middle. Databases: Library name. Users: The number of times (percentage) executed by each user. Query_time distribution: Query time distribution, by“#”The length of character representation reflects the proportion interval of statement execution time. As can be seen from the above code segment, most queries take about 1s to execute. Tables: Generated using the tables involved in the query statement to query table statistics and table structure SQL Statement text. EXPLAIN: Represents a sample of a query statement (it is convenient to copy it to view the execution plan. Note that the statement is not randomly generated, but the worst query in the grouped statements SQL Statement)
Excellent information
Reference source: Deep positioning analysis of Mysql performance bottleneck
During the performance test, we often encounter the performance bottleneck of Mysql. For the database, the so-called performance bottleneck is nothing more than slow SQL, high CPU, high IO and high memory. The first three examples are used for performance analysis. Finally, high memory is just a description of the method (not encountered in the actual test project):
First of all, we should ensure that there are no performance problems in database configuration. After all, we should roll out some basic configurations before performance test to avoid making low-level errors.
Slow SQL location analysis
First of all, the slow business system must be reflected in the response time. Therefore, in the performance test, if it is found to be slow, we will split it from the response time, and finally split it to MySQL, which is to analyze the slow SQL. Similarly, if it is found that the MySQL process occupies a high CPU in high concurrency, we will give priority to analyzing whether there is slow SQL, and it is relatively simple to judge the slow SQL, For MySQL, it is to look at the slow log query.
To obtain slow SQL, of course, you need to actually verify how slow it is and whether the index is configured. Take an actual SQL statement of the test project for analysis:
explain SELECT count(c.id)
FROM administrative_check_content c
LEFT JOIN administrative_check_report_enforcers e ON c.report_id=e.report_id
LEFT JOIN administrative_check_report r ON c.report_id = r.id
WHERE e.enforcer_id= 'ec66d95c8c6d437b9e3a460f93f1a592';
According to the analysis of this statement, 86% of the time is spent Sending data (the so-called "Sending data" does not simply send data, but includes "collect [retrieve] + send data"):
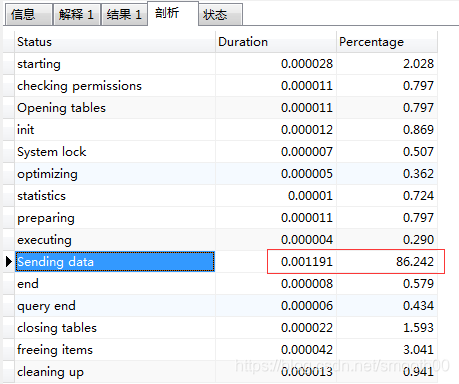
sql analysis with show profile:
It is also easy to start analysis. You can use temporary start to execute set profiling=1 (this function will cache the analysis statements of the latest query, 15 by default and 100 at most. It is suitable for sql analysis after the pressure test, and then set it to 0 to close after use), as follows:
#Displays whether Profiling is enabled and the maximum number of profiles stored show variables like '%profil%'; #Enable Profiling set profiling=1; #Execute your SQL #Here, we mainly execute the slow SQL found earlier #View analysis show profiles;
Through show profiles, we can see the SQL executed above (Query_ID=18. In order to monitor the latest data, Query_ID should preferably be 25)
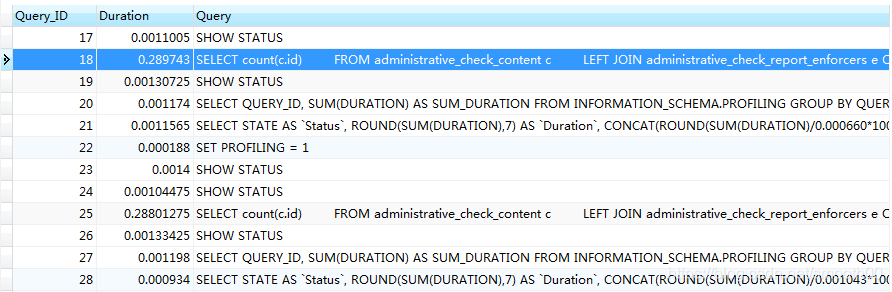
Execution: show profile cpu,memory,block io for query 18;
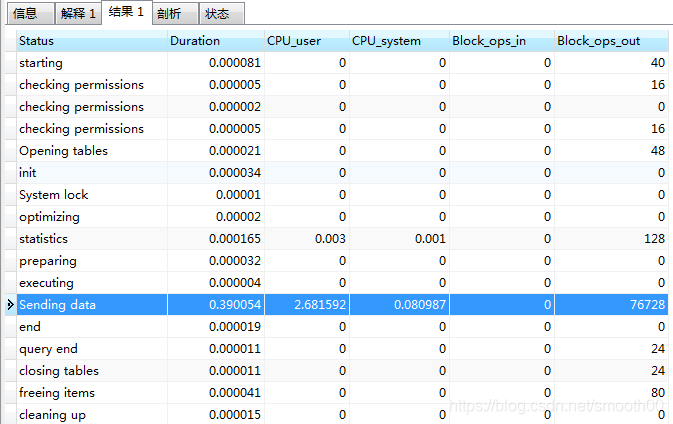
It can be seen that Sending data also consumes a total of 0.39 seconds, including CPU_ The user time is high (even if a simple SQL statement consumes a lot of time), and the IO cost of this SQL statement can be seen (because queries are output from ops out blocks)
You can also view the above records through SQL table lookup:
select QUERY_ID,SEQ,STATE,DURATION,CPU_USER,CPU_SYSTEM,BLOCK_OPS_IN,BLOCK_OPS_OUT from information_schema.PROFILING where QUERY_ID = 18
In addition, explain the show profile statement:
show profile cpu, block io, memory,swaps,context switches,source for query [Query_ID]; # Some parameters after Show profile: # -All: displays all overhead information # -cpu: displays cpu related overhead # -Block io: displays the Block io related overhead # -Context switches: context switching related costs # -Memory: displays memory related overhead # -Source: display and source_function,source_file,source_line related overhead information
Select optimized data type
MySQL supports many data types. Choosing the right data type is very important for high performance.
Here are some simple principles to help you make better choices:
Smaller ones are usually better Just be simple avoid NULL
The default storage engine in this article is InnoDB
Integer type
There are two types of numbers: integer and real.
If you store integers, you can use these integer types: TINYINT, SMALLINT, MEDIUMINT, INT, BIGINT. Use 8, 16, 24, 32 and 64 bit storage space respectively. They can store from - 2^(N-1) to 2^(N-1)-1.
The integer type has an optional UNSIGNED attribute, indicating that negative values are not allowed, which can roughly double the upper limit of the integer. Signed and UNSIGNED types use the same storage space and have the same performance, so you can choose the appropriate type according to the actual situation.
In real numbers, DECIMAL.
String type
VARCHAR and CHAR are the main string types.
VARCHAR:
It is usually used to store variable length strings and is the most common string data type. It saves more space than the fixed length type because it uses only the necessary space.
VARCHAR will use one or two bytes to store the size of the space. However, since the lines become longer, it is more troublesome when updating. If the space occupied by a row increases, but there is no more space available for this page, InnoDB will need to split the page so that the row can be placed in the page.
VARCHAR is suitable in this case:
The maximum length of the string column is much larger than the average length;
Columns are rarely updated, so fragmentation is not a problem;
Using a complex character set like UTF-8, each character is stored in a different number of bytes.
CHAR:
CHAR type is fixed length. When storing CHAR value, MySQL will delete all last spaces. CHAR values are filled in with spaces as needed to facilitate comparison.
CHAR is suitable for storing very short strings, or all values are close to a length. For frequently changing values, CHAR is also better than VARCHAR because fixed length CHAR types are not prone to fragmentation. For very short columns, CHAR is also more efficient than VARCHAR. For example, when saving a character, VARCHAR also has a byte to record the length.
Again, how data is stored depends on the storage engine. In this article, we only talk about InnoDB
BLOG and TEXT types
BLOG and TEXT are string data types designed to store large data, which are stored in binary and string respectively.
They belong to two different data type families:
TINYTEXT,SMALLTEXT,TEXT,MEDIUMTEXT,LONGTEXT
TINYBLOG,SMALLBLOG,BLOG,MEDIUMBLOG,LONGBLOG
Use ENUM instead of string
Sometimes you can use enumerated columns instead of common string types.
Enumeration columns can store some non repeating strings into a predefined collection. MySQL is very compact when storing enumerations. It will be compressed into one or two bytes according to the number of list values. MySQL will internally save the position of each value in the list as an integer and display it in the table A lookup table that stores the number string mapping relationship in the frm file.
There is a chestnut below:

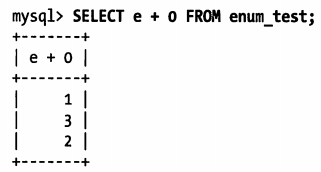
Try to avoid using numbers as ENUM enumeration constants.
Problems in MySQL schema design
Although there are some good or alternative design principles, there are also some problems caused by the implementation mechanism of MySQL, which means that it is possible to make some specific errors that only occur under mysql.
1. Too many columns
The operation cost of converting encoded columns from row buffer to data structure is very high.
If you plan to use thousands of fields, you must be aware that there will be some differences in the performance and operating characteristics of the server.
2. Too many associations
If you want the query to execute quickly and have good concurrency, it is best to associate a single query within 12 tables.
3. Omnipotent enumeration
Overuse of enumerations should be avoided.
! [insert picture description here]( https://img-blog.csdnimg.cn/20210223103030