Redis's extreme encapsulation of the underlying data structure is one of the reasons for redis's efficient operation. We analyze it in combination with redis source code.
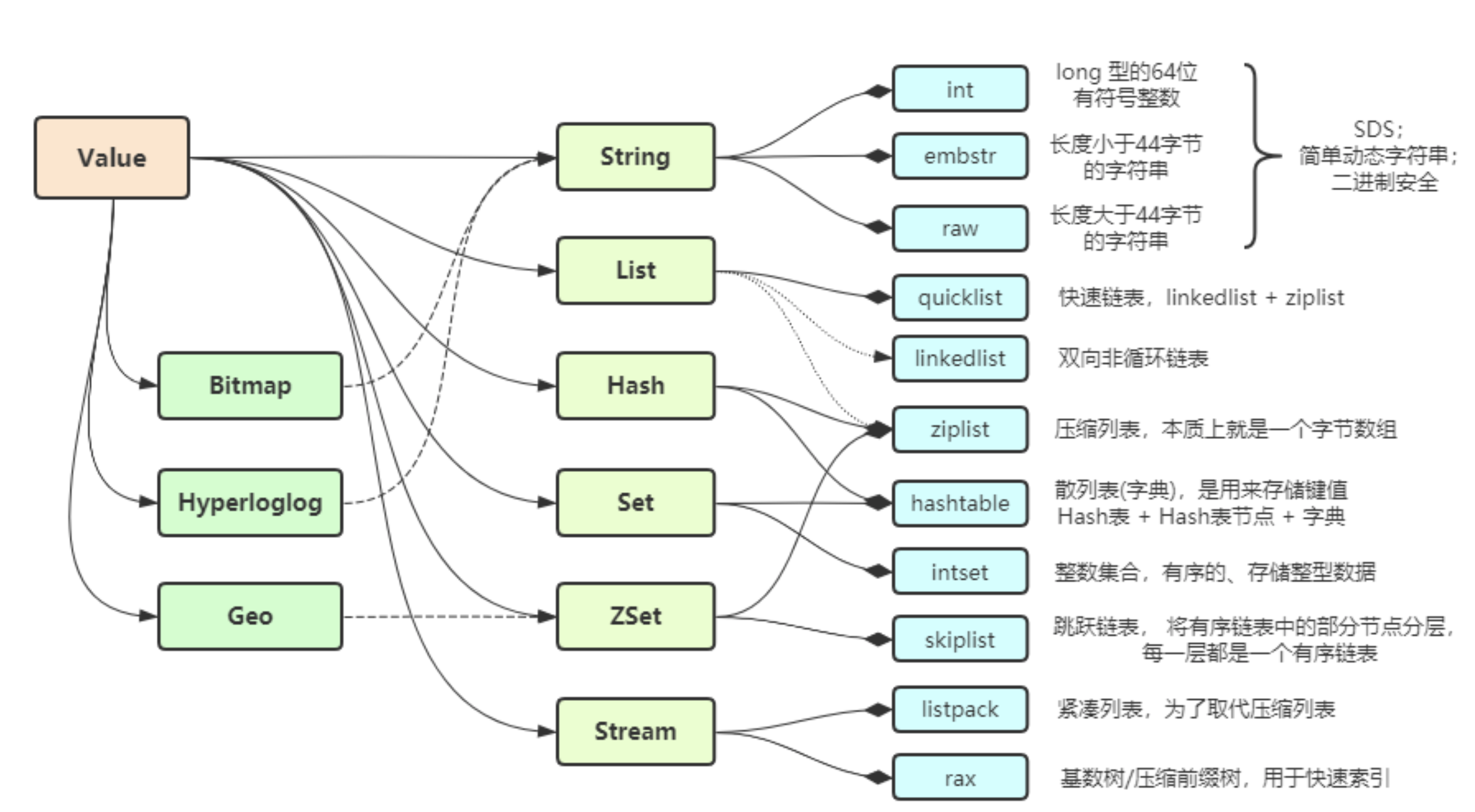
1, Data type encapsulation of Value
Object structure in Redis: redisObject structure
typedef struct redisObject {
unsigned type:4; // Type of object, string / list / set / ordered set / hash table
unsigned encoding:4; // In order to save space, Redis provides a variety of ways to save data
unsigned lru:LRU_BITS; // Cache obsolete; The elimination criteria are: oversize & overtime
int refcount; // Reference count; In order to optimize memory, digital strings are shared memory and managed by reference counting
void *ptr; // Data pointer refers to a data structure actually stored
} robj;- Type: data type
#define OBJ_STRING 0 / * string object*/ #define OBJ_LIST 1 / * list object*/ #define OBJ_SET 2 / * set object*/ #define OBJ_ZSET 3 / * ordered collection object*/ #define OBJ_HASH 4 / * hash table object*/ #define OBJ_MODULE 5 / * module object*/ #define OBJ_STREAM 6 / * stream object*/
- encoding: to optimize memory, there are at least two underlying implementations for each type
#define OBJ_ENCODING_RAW 0 /* Raw representation */ #define OBJ_ENCODING_INT 1 / * encoded as an integer*/ #define OBJ_ENCODING_HT 2 / * coded as hash table*/ #define OBJ_ENCODING_ZIPMAP 3 / * encoded as zipmap*/ #define OBJ_ENCODING_LINKEDLIST 4 / * no longer used: old list encoding*/ #define OBJ_ENCODING_ZIPLIST 5 / * encoded as a compressed list*/ #define OBJ_ENCODING_INTSET 6 / * encoded as an integer set*/ #define OBJ_ENCODING_SKIPLIST 7 / * code as skip table*/ #define OBJ_ENCODING_EMBSTR 8 / * encoded as a short string*/ #define OBJ_ENCODING_Quicklist 9 / * coded as quick linked list*/ #define OBJ_ENCODING_STREAM 10 / * cardinality tree encoded as listpacks*/
- refcount: to optimize memory, digital strings are shared in memory and managed by reference counting Note: for Redis single thread, the increase and decrease of reference count do not need to ensure atomicity
- lru: related to data obsolescence Redis's memory usage for data sets is calculated periodically. When the limit is exceeded, the timeout data will be eliminated. That is, the elimination standard is: oversize & overtime.
- ptr: refers to a data structure actually stored
Encoding: the storage method of different data types in Redis
OBJECT ENCODING | Encoding constant | Underlying data structure |
|---|---|---|
int | OBJ_ENCODING_INT | integer |
embstr | OBJ_ENCODING_EMBSTR | embstr encoded simple dynamic string (SDS) |
raw | OBJ_ENCODING_RAW | Simple dynamic string (SDS) |
ht (hashtable) | OBJ_ENCODING_HT | Dictionaries |
linkedlist | OBJ_ENCODING_LINKEDLIST | Double ended linked list |
ziplist | OBJ_ENCODING_ZIPLIST | Compressed list |
intset | OBJ_ENCODING_INTSET | Integer set |
skiplist | OBJ_ENCODING_SKIPLIST | Jump tables and dictionaries |
zipmap | OBJ_ENCODING_ZIPMAP | Compression mapping table |
quicklist | OBJ_ENCODING_QUICKLIST | Quick linked list |
listpack | OBJ_ENCODING_STREAM | Compact list |
Correspondence between data type and coding object:
data type | code | Underlying data structure |
|---|---|---|
OBJ_STRING | OBJ_ENCODING_INT | String object implemented using integer values |
OBJ_STRING | OBJ_ENCODING_EMBSTR | String object implemented using simple dynamic string encoded by embstr |
OBJ_STRING | OBJ_ENCODING_RAW | String object implemented using simple dynamic string |
OBJ_LIST | OBJ_ENCODING_LINKEDLIST | List object implemented using double ended linked list |
OBJ_LIST | OBJ_ENCODING_ZIPLIST | List objects implemented using compressed lists |
OBJ_HASH | OBJ_ENCODING_ZIPLIST | Hash object implemented using compressed list |
OBJ_HASH | OBJ_ENCODING_HT | Hash object implemented using dictionary |
OBJ_SET | OBJ_ENCODING_INTSET | A collection object implemented using an integer collection |
OBJ_SET | OBJ_ENCODING_HT | Collection objects implemented using dictionaries |
OBJ_ZSET | OBJ_ENCODING_ZIPLIST | An ordered collection object implemented using a compressed list |
OBJ_ZSET | OBJ_ENCODING_SKIPLIST | Ordered collection objects implemented using jump tables and dictionaries |
OBJ_STREAM | OBJ_ENCODING_STREAM | Ordered collection objects implemented using compact lists and rax trees |
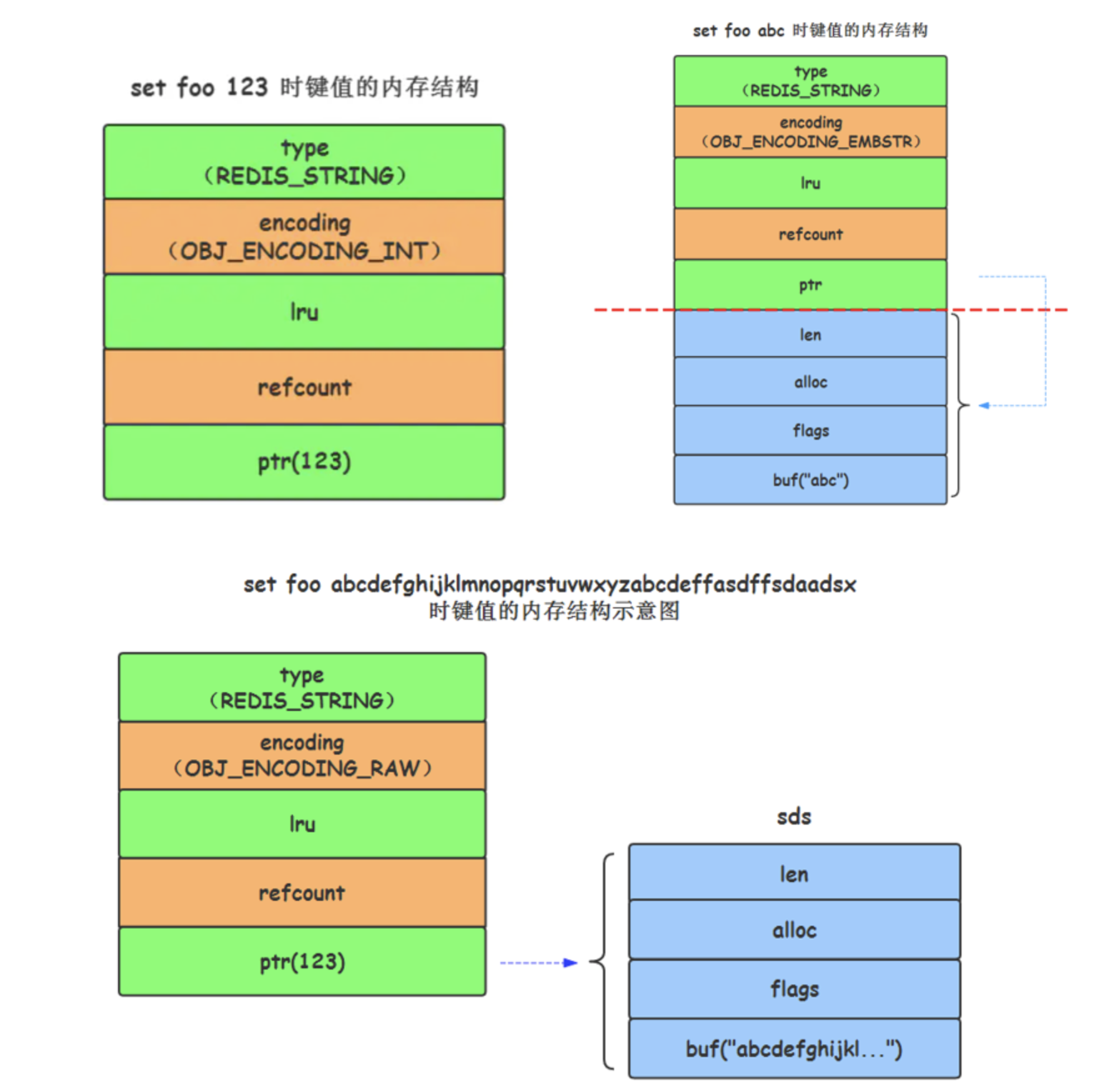
(1) String type (t_string.c)
Replace char * type in C language with SDS type:
- In order to efficiently realize addition and length calculation
- To ensure binary security
encoding:
- int Code: save 64 bit signed integer of long type; The data is stored directly in the ptr field
- embstr encoding: save string with length less than 44 bytes; Memory is allocated only once, and robj and sds are stored continuously, so as to improve the efficiency of memory allocation and data access
- raw encoding: save string with length greater than 44 bytes
Redis will use different coding formats according to different keys and values given by users, which is completely transparent to users
(2) List type (t_list.c)
- ziplist: the number of all string elements of the list object is less than 512, and the length of all elements is less than 64 bytes (before Redis 3.2)
- linkedlist: other conditions that do not meet the ziplost conditions (before Redis 3.2)
- quicklist: a combination of adlist and ziplist; A new data structure considering time efficiency and space efficiency is introduced
(3) Hash table type (t_hash.c)
- ziplist: the number of all string elements of the list object is less than 512, and the length of all elements is less than 64 bytes
- ht: other situations that do not meet the ziplost condition
(4) Set type (t_set.c)
- intset: all elements are integers, and the number of elements is less than 512
- ht: other situations that do not meet the ziplost condition
(5) Ordered set type (t_zset.c)
In Redis's configuration file, there are two configurations about the underlying implementation of ordered collection:
# When zset adopts compressed list, the maximum number of elements. The default value is 128. zset-max-ziplist-entries 128 # When zset uses a compressed list, the maximum string length of each element. The default value is 64. zset-max-ziplist-value 64
- ziplist: the number of elements is less than 128 and the length of elements is less than 64
- skiplist: other situations that do not meet the ziplist condition
(6) Data stream type (t_stream.c)
The underlying implementation of Redis Stream mainly uses listpack and Rax tree
- listpack: used to store specific messages
- Rax tree: for quick indexing
It consists of message, producer, consumer and consumer group
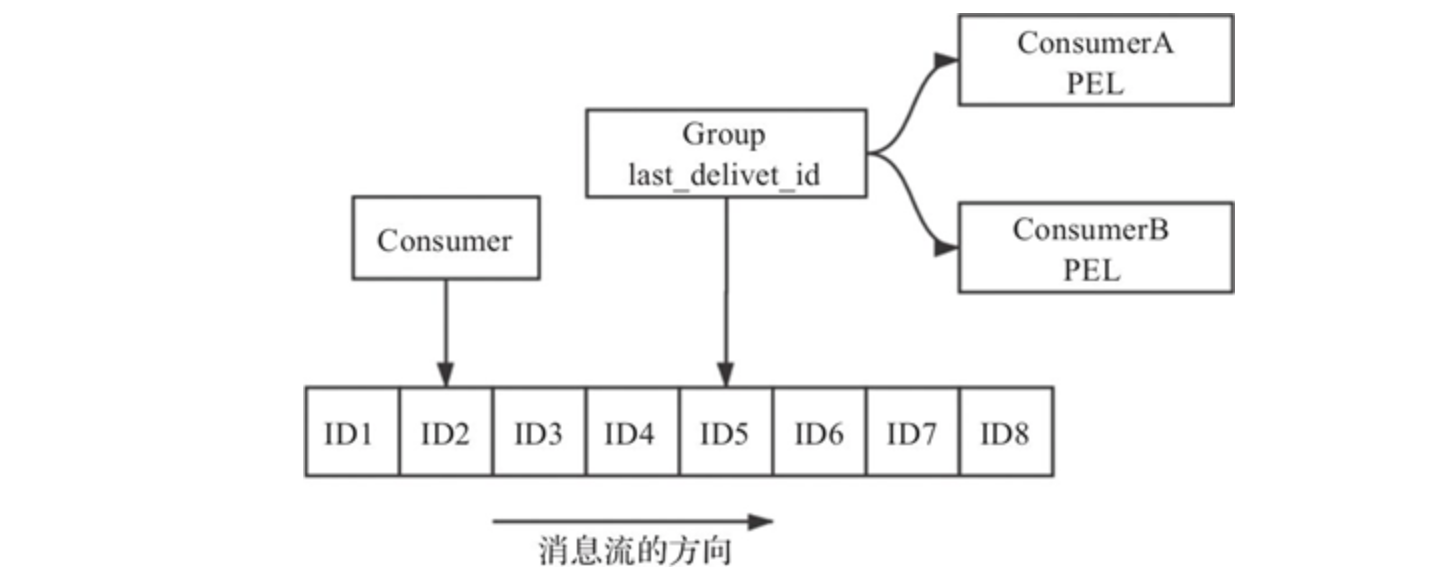
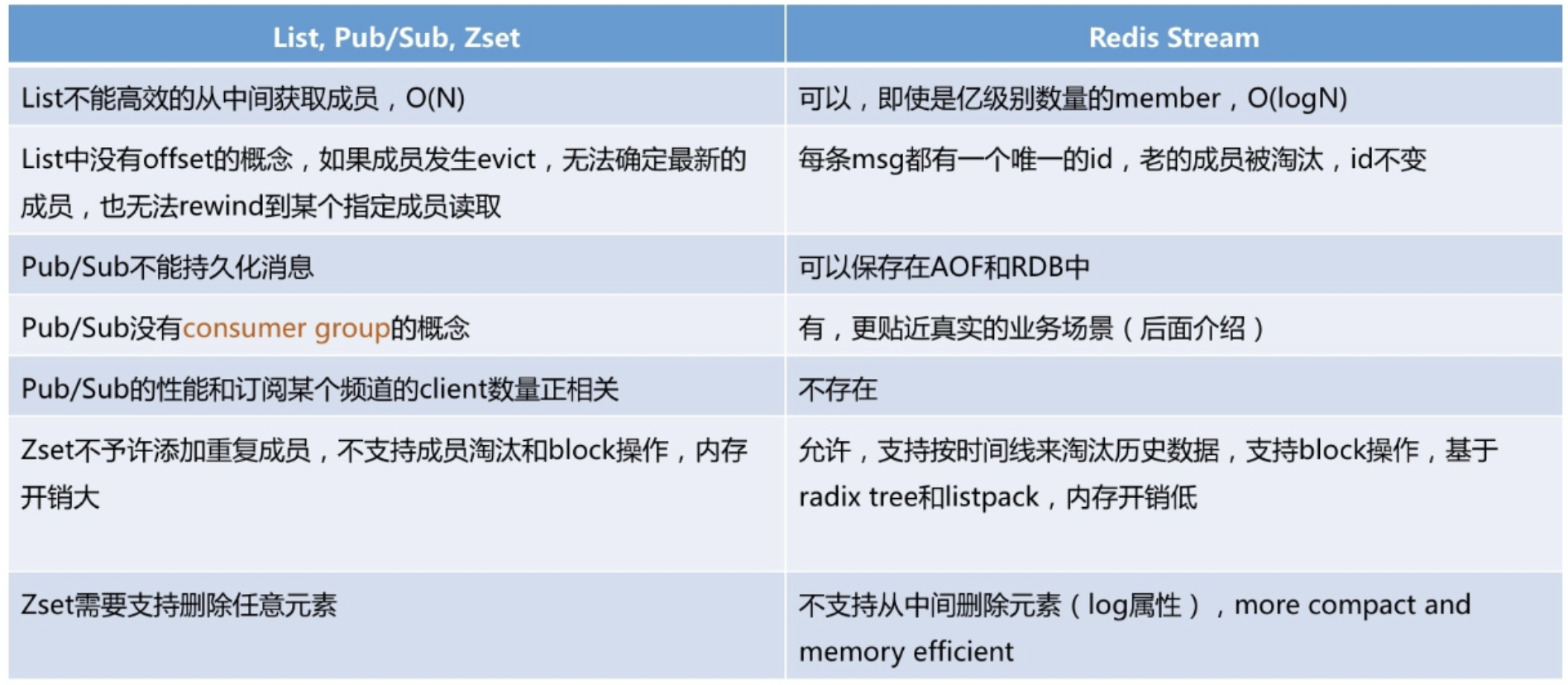
Redis Stream is essentially a message publishing and subscribing function component implemented on redis kernel. Compared with the existing PUB/SUB and BLOCKED LIST, although they can also be used as message queues in simple scenarios, Redis Stream is undoubtedly much more perfect. Redis Stream provides message persistence and active / standby replication functions, a new RadixTree data structure to support more efficient memory usage and message reading, and even a Consumer Group function similar to Kafka.
2, Underlying data structure
(1) Simple dynamic string (sds.c)
SDS structure (5 types, different field data types, with the exception of sdshdr5), take sdshdr8 as an example:
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; // Actual used length of string
uint8_t alloc; // Total length; Before 5.0, free was used to identify the number of available bytes remaining in the buff
unsigned char flags; // Flag bit, the lower three bits indicate the type, and the other five bits are not used
char buf[]; // Character array, flexible array, storing the actual content
};Flexible array members, also known as scalable array members, can only be placed at the end of the structure. The structure containing flexible array member s dynamically allocates memory for the flexible array through malloc function. The reason why the flexible array is used to store the string is that the address and structure of the flexible array are continuous, which makes it faster to find the memory (because there is no need to find the position of the string through the pointer); The first address of the structure can be easily obtained by the first address offset of the flexible array, and then the other variables can be easily obtained.
What SDS returns to the upper layer is not the first address of the structure, but the buf pointer to the content. Therefore, the upper layer can read the content of SDS like reading C string, which is compatible with various functions of C language to process string.
Due to the existence of the length statistical variable len, the "\ 0" terminator is not relied on when reading and writing strings, ensuring binary security.
After Redis 3.2, the number of SDS structures has increased from 1 to 5, and for sdshdr5 type, it will be forcibly converted to sdshdr8 when creating an empty string. The reason may be that after creating an empty string, its content may be updated frequently and cause capacity expansion, so it is directly created as sdshdr8.
Basic operation:
Function name | explain |
|---|---|
sdsnewlen | When creating a string, the appropriate type will be selected according to the length of the string |
sdsfree/sdsclear | Directly release the string; The memory is not directly released, and the purpose of emptying is achieved by resetting the statistical value |
sdscatsds | Splicing strings may lead to capacity expansion |
sdsnew | Create SDS based on the given C string |
sdssplitlen | The SDS is segmented according to the specified separator |
Splicing strings may lead to capacity expansion. Capacity expansion strategy:
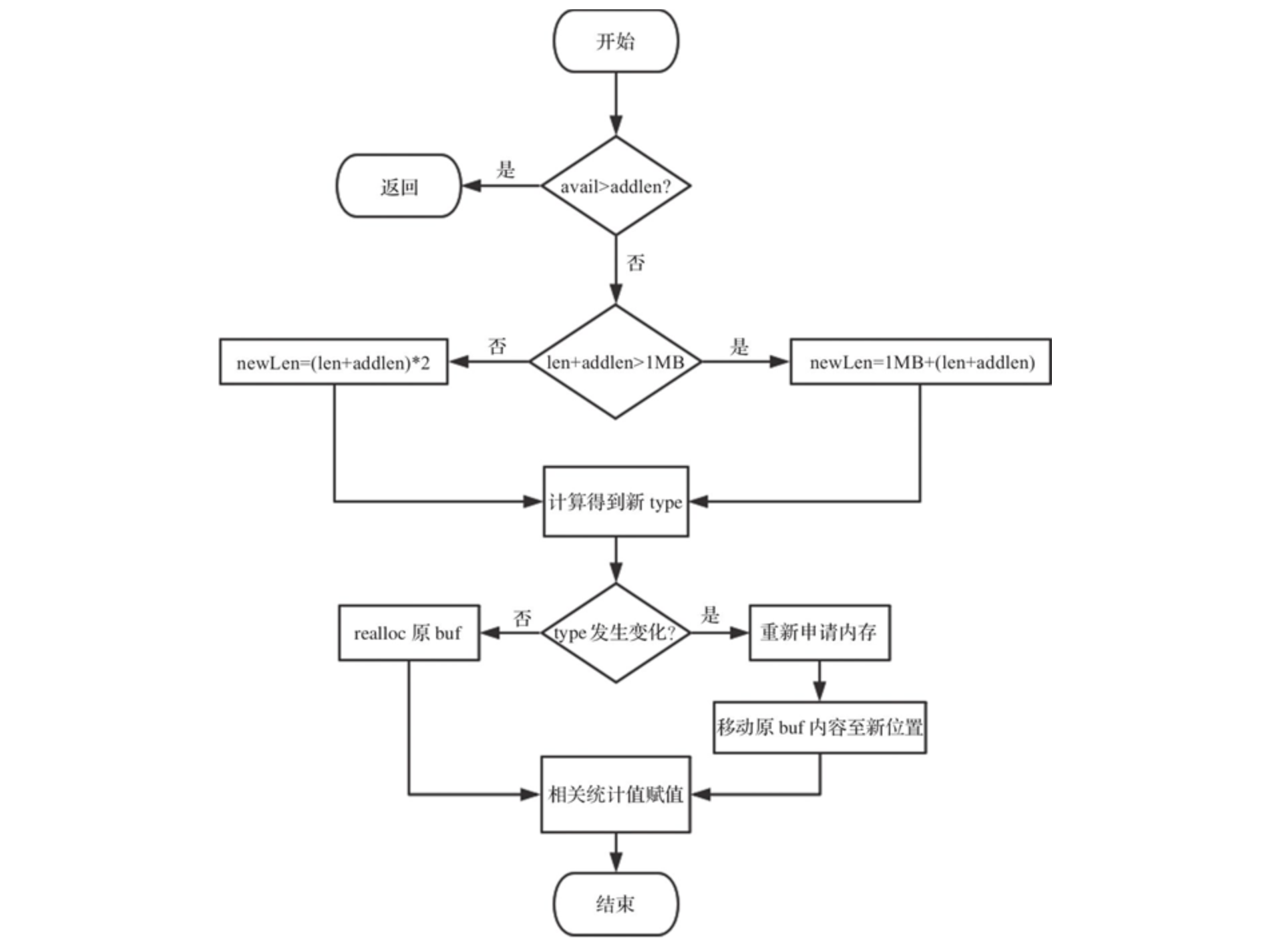
1) If the remaining free length avail able in the sds is greater than the length addlen of the new content, it can be directly added at the end of the flexible array buf without capacity expansion.
2) If the remaining free length avail able in the sds is less than or equal to the length addlen of the new content, it will be discussed according to the situation: if the total length len + addlen after the new content is less than 1MB, the capacity will be expanded by twice the new length; If the added total length len + addlen > 1MB, the capacity shall be expanded according to the new length plus 1MB.
3) Finally, re select the storage type according to the new length and allocate space. If there is no need to change the type here, you can expand the flexible array through realloc; Otherwise, you need to reopen the memory and move the buf content of the original string to a new location.
(2) Dictionary (dict.c)
Dictionary, also known as hash table, is a data structure used to store key value pairs.
Any operation of adding, deleting, modifying and querying Redis database is actually the operation of adding, deleting, modifying and querying the data in the dictionary.
Dictionary essence: array + Hash function + Hash conflict
Data structure: Hash table (dictht), Hash table node (dictEntry), Dictionary (dict)
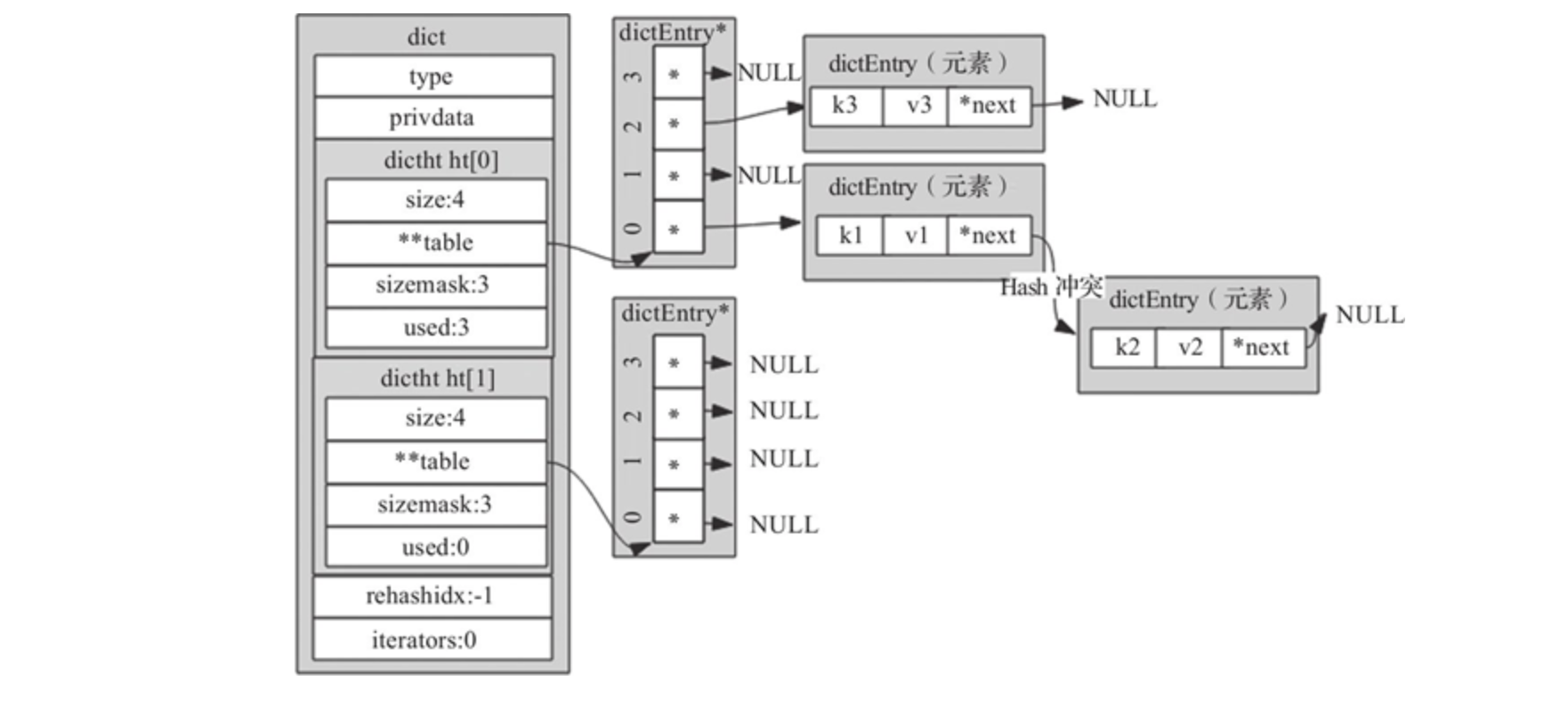
A. Hash table - structure:
typedef struct dictht {
dictEntry **table; // Pointer array. The elements in the array point to the structure of dictEntry
unsigned long size; // Size of table array
unsigned long sizemask; // Mask = size - 1
unsigned long used; // The number of saved elements in the table array contains the data of the next single linked table
} dictht;The sizemask field is used to calculate the index value of the key. The sizemask value is equal to size – 1.
Index value = Hash value & mask value. The corresponding Redis source code is:
idx = hash & d->ht[table].sizemask;
The calculation result is equivalent to the Hash value and Hash table capacity remainder, and the bit operation of the computer is much faster than the remainder operation.
B. Hash table node structure:
The elements in the Hash table are encapsulated by the dictEntry structure, which is mainly used to store key value pairs
typedef struct dictEntry {
void *key; // Storage key
union {
void *val; // db. val in Dict
uint64_t u64;
int64_t s64; // db. Store expiration time in expires*/
double d;
} v; // value is a consortium; Use different fields in different scenarios
struct dictEntry *next; // When Hash conflicts, it points to the conflicting elements to form a single linked list
} dictEntry;
C. Dictionary structure:
The outermost layer encapsulates a data structure called dictionary, which is mainly used to encapsulate the Hash table dictht
typedef struct dict {
dictType *type; // The specific operation function corresponding to the dictionary
void *privdata; // Data on which the dictionary depends
dictht ht[2]; // Hash table, where key value pairs are stored
long rehashidx; // Rehash ID, the default value is - 1, which means that rehash operation is not performed
// Otherwise, the value indicates which index value the rehash operation of the Hash table ht[0] has reached
unsigned long iterators; // The number of currently running security iterators. When a security iterator is bound to the dictionary, rehash will be suspended
} dict;- type: refers to the dictType structure, a group of operation functions abstracted to implement various forms of dictionaries
- privdata: private data, used together with the function pointed to by the type field
- ht: it is an array of size 2. The element type stored in this array is dictht. Although there are two elements, ht[0] will only be used in general. ht[1] will only be used when rehash is required for the expansion and reduction of the dictionary
- rehashidx: used to mark whether the dictionary is rehashing. When rehashing is not performed, the value is - 1. Otherwise, this value is used to indicate which element the Hash table ht[0] rehashing to, and record the array subscript value of this element
- Iterators: used to record the number of currently running security iterators. When a security iterator is bound to the dictionary, the rehash operation will be suspended
Basic operation:
Function name | explain |
|---|---|
dictCreate | Initialize an empty dictionary |
dictAdd | Add elements; First find out whether the key exists. If it exists, modify it. Otherwise, add a key value pair |
dictFind | Find element |
dbOverwrite | Modify elements; Modify the value in the node key value pair to a new value to free the memory of the old value |
tryResizeHashTables | Delete element; Release the key and value corresponding to the node and the memory occupied by the node itself |
Adding elements may lead to capacity expansion:
Insufficient available space leads to capacity expansion. During capacity expansion, the space size is the current capacity * 2, i.e. D - > HT [0] used*2
Deleting elements may cause shrinkage:
When the usage is less than 10% of the total space, the volume shall be reduced; When shrinking, the space size can contain D - > HT [0] Used is a 2^N power integer of nodes, and the field rehashidx in the dictionary is identified as 0
1) Dictionary initialization: dictCreate
/* Create a new Hash table */
dict *dictCreate(dictType *type, void *privDataPtr){
dict *d = zmalloc(sizeof(*d)); //96 bytes
_dictInit(d,type,privDataPtr); //Structure initialization value
return d;
}
/* Initialize the hash table */
int _ dictInit (dict *d, dictType *type, void *privDataPtr){
_dictReset(&d->ht[0]);
_dictReset(&d->ht[1]);
d->type = type;
d->privdata = privDataPtr;
d->rehashidx = -1;
d->iterators = 0;
return DICT_OK;
}The main steps are: applying for space and calling_ dictInit function, which assigns initial values to each field of the dictionary.
2) Add element: dictAdd
After receiving the command, the Server side will execute the setKey(redisDbdb,robjkey,robj*val) function
Step 1: call the dictFind function to query whether the key exists. If yes, call the dbOverwrite function to modify the key value pair. Otherwise, call the dbAdd function to add elements;
Step 2: dbAdd finally calls the dictAdd function in the dict.h file to insert the key value pair.
/*Before calling, it will check whether the key exists or not. If it does not exist, it will call the dictAdd function*/
int dictAdd(dict *d, void *key, void *val){
dictEntry *entry = dictAddRaw(d,key,NULL); /*When adding a key, NULL will be returned if the key in the dictionary already exists. Otherwise, when adding a key to a new node, a new node will be returned*/
if (!entry) return DICT_ERR; /*If the key exists, an error is returned*/
dictSetVal(d, entry, val); /*Set value*/
return DICT_OK;
}dictAddRaw adds a key and a search key. If the addition is successful, a new node will be returned. If the search is successful, NULL will be returned, and the old node will be stored in the existing field:
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing)/*Input dictionary, key, Hash table node address*/
{
if (dictIsRehashing(d)) _dictRehashStep(d); /*Whether the dictionary is in rehash operation. If yes, rehash is executed once*/
if ((index = _dictKeyIndex(d, key, dictHashKey(d,key), existing)) == -1)
/*Search key. If it is found, it will directly return - 1 and store the old node in the existing field. Otherwise, it will return the index value of the new node. If the capacity of the Hash table is insufficient, expand it*/
return NULL;
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0]; /*Whether to perform rehash operation. If yes, insert it into hash table ht[1]. Otherwise, insert hash table ht[0] */
/*Apply for new node memory, insert it into the hash table, and store key information for the new node*/
entry = zmalloc(sizeof(*entry));
entry->next = ht->table[index];
ht->table[index] = entry;
ht->used++;
dictSetKey(d, entry, key);
return entry;
}_ dictKeyIndex function: get the index value of the key.
dictHashKey(d,key) //Step 1: call the Hash function of the dictionary to get the Hash value of the key idx = hash & d->ht[table].sizemask; //Step 2: use the Hash value of the key and the dictionary mask to get the index value
3) Capacity expansion: dictExpand
int dictExpand(dict *d, unsigned long size){//Pass in size = D - > HT [0] used*2
dictht n;
unsigned long realsize = _dictNextPower(size); /*Recalculate the value after capacity expansion, which must be the N-th power of 2*/
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
d->ht[1] = n; /*Put the expanded new memory into ht[1]*/
d->rehashidx = 0; /*Non default - 1 indicates that rehash is required*/
return DICT_OK;
}rehash will be triggered not only during capacity expansion, but also during capacity reduction.
During capacity expansion, the space size is the current capacity * 2, i.e. D - > HT [0] used*2; When the usage is less than 10% of the total space, the volume shall be reduced; When shrinking, the space size can contain D - > HT [0] Used is a 2^N power integer of nodes, and the field rehashidx in the dictionary is identified as 0.
When the number of key value pairs in the database reaches the level of one million, ten million and one hundred million, the whole rehash process will be very slow. Redis uses the idea of divide and rule to rehash
Before performing insert, delete, search, modify and other operations, judge whether the current dictionary rehash operation is in progress. If it is in progress, call the dictRehashStep function to rehash the operation (rehash only one node at a time, which is executed once in total).
When the service is idle, if the current dictionary also needs to rehash, it will call the incrementallyRehash function to perform batch rehash operations (rehash 100 nodes each time, for a total of 1 ms).
After N rehash operations, the entire data of ht[0] will be migrated to ht[1]. The advantage of this is that the time that should be centralized processing is scattered to millions, tens of millions and hundreds of millions of operations, so the time-consuming is negligible.
4) Find element: dictFind
dictEntry *dictFind(dict *d, const void *key){
// ...
h = dictHashKey(ht, key) & ht->sizemask; //Get the corresponding index value according to the Hash value
he = ht->table[h];
while(he) { //If there is a value, traverse the single linked list in the value
if (dictCompareHashKeys(ht, key, he->key))
return he; //Find a value equal to the key and return the node
he = he->next;
}
// ...
}5) Modify element: dbOverwrite
void dbOverwrite(redisDb *db, robj *key, robj *val) {
dictEntry *de = dictFind(db->dict,key->ptr); //Find whether the key exists or not, and return the existing node
serverAssertWithInfo(NULL,key,de != NULL); //If it does not exist, the execution is interrupted
dictEntry auxentry = *de;
robj *old = dictGetVal(de); //Get the val field value of the old node
dictSetVal(db->dict, de, val); //Set a new value for the node
dictFreeVal(db->dict, &auxentry); //Free old val memory in node
}6) Delete element: dictDelete function
Note: traversal in dictionary
- Full traversal: traversing the entire database in one command execution (it takes a long time, which will make Redis unavailable for a short time)
- Intermittent traversal: only partial data is taken for each command execution, and traversal is performed several times (added after version 2.8.0)
(3) Linked list (adlist.h)
Bidirectional acyclic list:
typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;
typedef struct list {
// Header pointer
listNode *head;
// Footer pointer
listNode *tail;
// Copy function
void *(*dup)(void *ptr);
// Release function
void (*free)(void *ptr);
// Comparison function
int (*match)(void *ptr, void *key);
// Number of nodes
unsigned long len;
} list;(4) Jump table (server.h/skiplist)
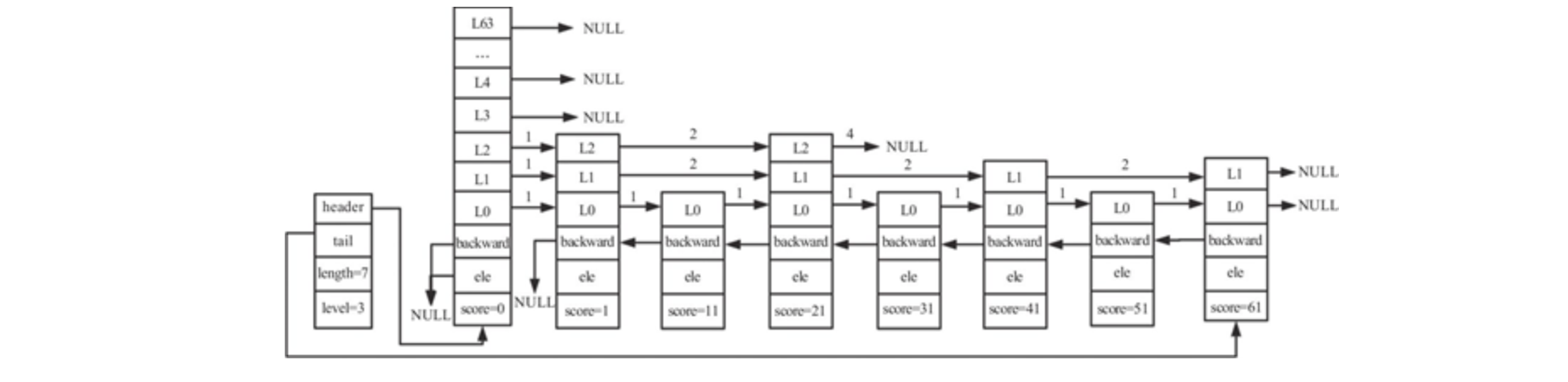
The skip list is improved based on the ordered linked list. skiplist layers some nodes in the ordered linked list, and each layer is an ordered linked list.
As can be seen from this figure, skiplist is composed of multiple nodes, each node is composed of many layers, and each layer has a pointer to the next node of this layer.
A. Jump table - structure:
typedef struct zskiplist {
struct zskiplistNode *header, *tail; // Head and tail nodes of jump table
unsigned long length; // Jump table length (excluding header node)
int level; // Height of jump table
} zskiplist;The number of level array elements of the header node is 64, forward points to NULL, and span values are 0. In the ordered set, the ele value is NULL and the score value is 0; It is also not included in the total length of the jump table.
When searching, it is preferred to start backward from the top layer. When reaching a node, if the value of the next node is greater than the value to be searched or the next pointer points to NULL, it will descend one layer from the current node to continue backward searching
Each node of the jump table maintains multiple pointers to other nodes. You can skip some nodes and quickly find the nodes needed for operation. In the final analysis, the jump table achieves the purpose of fast search by sacrificing space.
B. Jump table node - structure:
typedef struct zskiplistNode {
sds ele; // Used to store string type data
double score; // Used to store sorting scores
struct zskiplistNode *backward; // The backward pointer can only point to the previous node at the bottom of the current node
struct zskiplistLevel {
struct zskiplistNode *forward; // Point to the next node in this layer
unsigned long span; // The number of elements between the node pointed to by forward and this node
} level[]; // When generating jump table nodes, randomly generate a value of 1 ~ 64
} zskiplistNode;- ele: used to store string type data
- Score: used to store the score of sorting
- Backward: backward pointer, which can only point to the previous node at the bottom of the current node; The head node and the first node point to NULL, which is used when traversing the jump table from back to front
- level: is a flexible array. The array length of each node is different. When generating jump table nodes, a value of 1 ~ 64 is randomly generated. The greater the value, the lower the probability of occurrence.
- Forward: points to the next node in this layer, and the forward of the tail node points to NULL
- Span: the number of elements between the node pointed to by forward and this node. The larger the span value, the more nodes will be skipped.
In zset, ele stores the member value of zset member, and score stores the score value of zset
Basic operation:
Function name | explain |
|---|---|
zslCreateNode | Create node |
zslCreate | Create jump table |
zslInsert | Insert node |
zslDeleteNode, zslDelete, zslDeleteByScore, zslDeleteByRank | Delete node |
zslFree | Delete jump table |
1) Create jump table
① Create jump table structure object zsl; ② Point the head node pointer of zsl to the newly created head node; ③ The jump surface height is initialized to 1, the length is initialized to 0, and the tail node points to NULL.
Insert node:
① Find the location to insert; ② Adjust the height of the jump meter; ③ Insert node; ④ Adjust backward
Delete node
① Find the node to be updated; ② Set span and forward.
2) Delete jump table
After obtaining the jump table object, start from the zero layer of the node and traverse backward step by step through the forward pointer. Each node will free its memory. When the memory of all nodes is released, the jump table object is released, that is, the deletion of the jump table is completed.
(5) Integer set (intset.h)
An integer set is an ordered (from small to large) structure that stores integer data.
Structure:
typedef struct intset {
uint32_t encoding; //The encoding type determines how many bytes each element occupies
uint32_t length; //Number of elements
int8_t contents[]; //Flexible array to store specific elements; According to the encoding field, several bytes represent an element
} intset;However, in two cases, the underlying coding will be converted.
- When the number of integer elements exceeds a certain number (the default value is 512), the encoding is converted to hashtable
- When adding non integer variables, for example, after adding element 'a' in the set, the underlying code of testSet is converted from intset to hashtable

Basic operation:
Function name | explain |
|---|---|
intsetFind | Query elements; After defensive judgment, use dichotomy to find elements |
intsetAdd, intsetUpgradeAndAdd | Add elements; Decide whether to insert directly or upgrade according to the code type of the insertion value |
intsetRemove | Delete element; The element is directly overwritten by moving the memory address |
intsetNew | Initialize an intset; The code is INTSET_ENC_INT16, length 0, content unallocated space |
intsetRandom | Returns an element at random |
1) Query element
a. First, judge the encoding format of the value to be searched. If the encoding is greater than the encoding of the intset, the value certainly does not exist and returns directly. Otherwise, call the intsetSearch function;
b. In the intsetsearch function, first judge whether there is a value in the intset. If there is no value, it will directly return 0; If there is a value, judge whether the value to be inserted is between the maximum value and the minimum value of this intset. If it is not within this range, it also returns 0.
c. Use the binary search method to find the value (intset is an ordered array), and return 1 if found and 0 if not found.
2) Add element
intset *intsetAdd(intset *is, int64_t value, uint8_t *success) {
uint8_t valenc = _intsetValueEncoding(value); //Gets the encoded value of the added element
uint32_t pos;
if (success) *success = 1;
if (valenc > intrev32ifbe(is->encoding)) { //If it is greater than the current intset code, it indicates that it needs to be upgraded
return intsetUpgradeAndAdd(is,value); //Call intsetUpgradeAndAdd to add after upgrade
} else {
if (intsetSearch(is,value,&pos)) { //Otherwise, double check is performed first. If the element already exists, it is returned directly
if (success) *success = 0;
return is;
}
//If the element does not exist, the element is added
is = intsetResize(is,intrev32ifbe(is->length)+1); //First, expand the memory occupied by intset
//If the inserted element is in the middle of intset, call intsetMoveTail to make room for the element
if (pos < intrev32ifbe(is->length)) intsetMoveTail(is,pos,pos+1);
}
_intsetSet(is,pos,value); //Save element
is->length = intrev32ifbe(intrev32ifbe(is->length)+1); //Modify the length of intset and add 1
return is;
}The process of intsetUpgradeAndAdd is as follows:
a. Call intsetResize to re apply for space according to the new coding method;
b. Move and expand the original elements;
c. Inserts the value into the corresponding position according to whether the newly inserted value is positive or negative.
3) Delete element
intset \*intsetRemove(intset \*is, int64_t value, int *success)
1) First, judge whether the code is less than or equal to the current code. If not, return directly.
2) Call intsetSearch to find out whether the value exists. If it does not exist, it will be returned directly; If it exists, get the position where the value is located.
3) If the data to be deleted is not the last value of the intset, the value of position position is overwritten by moving the data of position+1 and subsequent positions to position.
When the collection elements are all integers and there are few elements, use intset to save. And the elements are saved in descending order.
(6) Compressed list (ziplist.c)
The zip List is essentially an array of bytes. ZSet, Hash and List of Redis all use compressed lists directly or indirectly.
When the number of elements in ZSet or Hash is relatively small and the elements are short strings, Redis uses the compressed list as its underlying data storage structure.
Structure diagram (byte array, no specific structure):

//zl points to the zlbytes field #define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl))) //zl+4 points to the zltail field #define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t)))) //zl+zltail points to the first address of the tail element; intrev32ifbe makes the data access uniformly adopt the small end method #define ZIPLIST_ENTRY_TAIL(zl) ((zl)+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))) //zl+8 points to the zllen field #define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2))) //The last byte of the compressed list is the zlend field #define ZIPLIST_ENTRY_END(zl) ((zl)+intrev32ifbe(ZIPLIST_BYTES(zl))-1)
Coding structure of compressed list entry:

- previous_entry_length: represents the byte length of the previous element, accounting for 1 or 5 bytes. When the length of the current element is less than 254 bytes, it is represented by 1 byte; When the length of the current element is greater than or equal to 254 bytes, it is represented by 5 bytes.
- Encoding: indicates the encoding of the current element, that is, the data type (integer or byte array) stored in the content field. The data content is stored in the content field.
The decoded compressed list elements are represented by the structure zlentry.
zlentry structure:
typedef struct zlentry {
unsigned int prevrawlensize; // previous_ entry_ The length of the length field
unsigned int prevrawlen; // previous_ entry_ What is stored in the length field
unsigned int lensize; // Length of encoding field
unsigned int len; // Length of element data content
unsigned int headersize; // The header length of the current element
unsigned char encoding; // data type
unsigned char *p; // First address of current element
} zlentry;Basic operation:
Function name | explain |
|---|---|
ziplistNew | Create compressed list |
ziplistInsert | Insert elements; Encoding - > reallocate space - > copy data |
ziplistDelete | Delete element; Calculate the total len gt h of the element to be deleted - > data copy - > reallocate space |
ziplistNext, ziplistPrev | Traverse the compressed list, which can be traversed backward or forward |
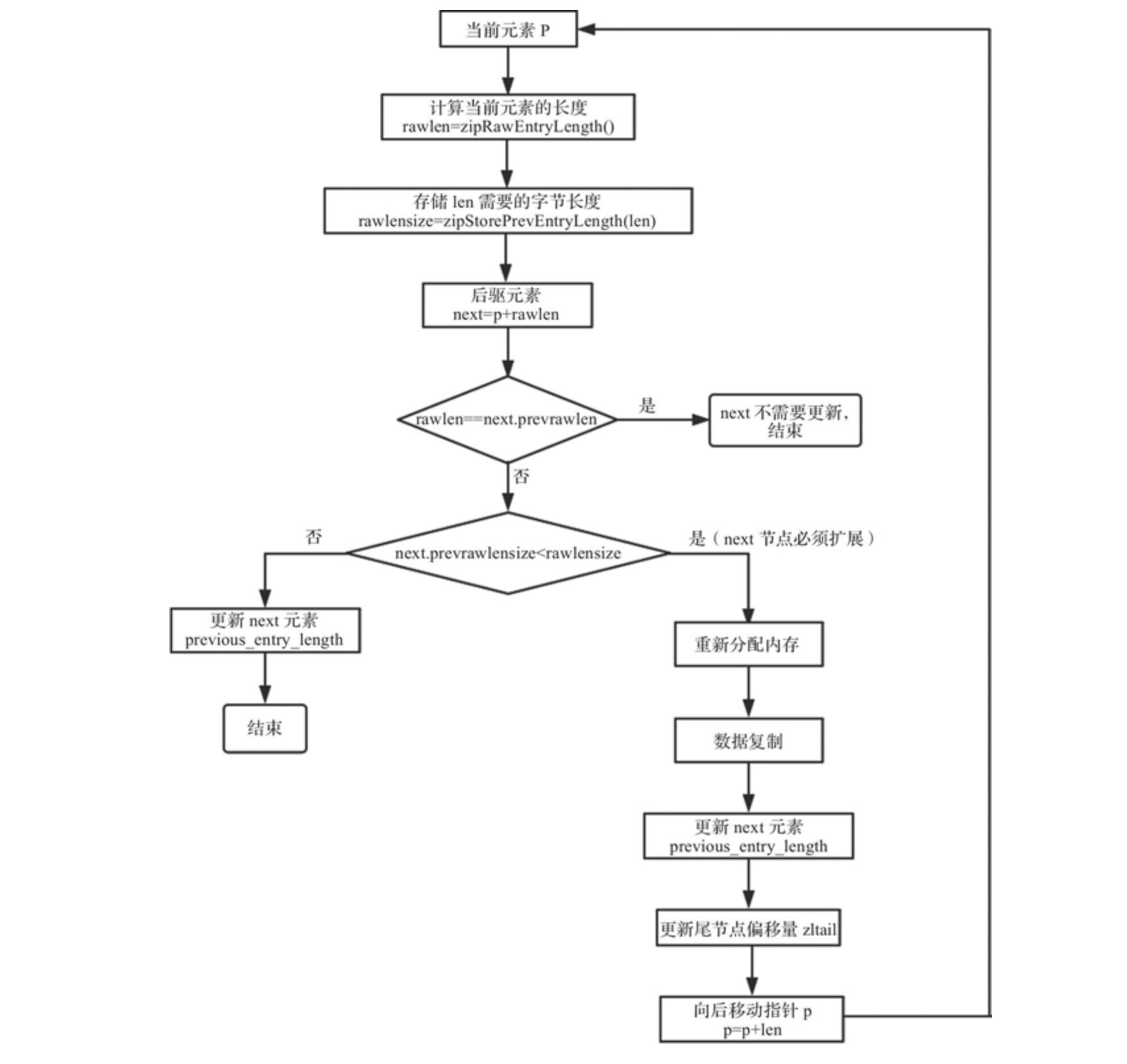
When deleting and inserting elements, the required storage length of elements may change, resulting in length expansion. Each expansion will reallocate memory and data replication, which is very inefficient. This is the problem of chain update.
1) Create compressed list
unsigned char *ziplistNew(void);
You only need to allocate 11 (4 + 4 + 2 + 1) bytes of initial storage space and initialize the zlbytes, zltail, zllen and zlend fields
2) Insert element
unsigned char *ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen);
zl: the first address of the compressed list; p: Point to the element insertion position; s: Data content; slen: data length
The return parameter is the first address of the compressed list
Steps: ① encode the element content; ② Reallocation of space; ③ Copy data.
3) Delete element
unsigned char *ziplistDelete(unsigned char *zl, unsigned char **p);
- zl: point to the first address of the compressed list;
- *p: Point to the first address of the element to be deleted (parameter P can also be used as an output parameter);
The return parameter is the first address of the compressed list.
Steps: ① calculate the total length of the elements to be deleted; ② Data replication; ③ Reallocate space.
4) Traverse compressed list
Each element in the compressed list is accessed from beginning to end (backward traversal) or from end to end (forward traversal).
//Backward traversal unsigned char *ziplistNext(unsigned char *zl, unsigned char *p); //Forward Traversal unsigned char *ziplistPrev(unsigned char *zl, unsigned char *p);
Chain update will appear, and the implementation logic of chain update is as follows:
(7) Quick linked list (quicklist.c)
Before Redis 3.2, Redis used compressed List (ziplost) and two-way linked List (adlist) as the underlying implementation of List. When the number of elements is small and the length of elements is small, Redis uses ziplost as its underlying storage; When any condition is not satisfied, Redis adopts adlist as the underlying storage structure.
quicklist is introduced in Redis 3.2 as the underlying storage structure of List, which is a combination of adlist and ziplist.
quicklist is a two-way linked list. Each node in the linked list is a ziplost structure.
quicklist structure:
typedef struct quicklist {
quicklistNode *head; // Point to the header node of quicklist
quicklistNode *tail; // Point to the tail node of quicklist
unsigned long count; // Total number of elements
unsigned long len; // Number of nodes
int fill : 16; // Length of ziplist in each quicklistNode
unsigned int compress : 16; // There are compress nodes at both ends, which are not compressed
} quicklist;- Compress: when there are a large number of quicklistNode nodes, but the data at both ends often needs to be accessed. In order to further save space, Redis allows compression of the intermediate quicklistNode nodes. By modifying the compress parameter, you can specify that compress nodes at both ends are not compressed, that is, the middle (len compress) nodes will be compressed.
quicklistNode - structure:
typedef struct quicklistNode {
struct quicklistNode *prev; // Point to previous node
struct quicklistNode *next; // Point to the next node
unsigned char *zl; // ziplist structure corresponding to this node
unsigned int sz; // Size of ziplost structure
unsigned int count : 16; // Element size of ziplost
unsigned int encoding : 2; // Coding method adopted
unsigned int container : 2; // The type of container zl points to: 1 for none, 2 for storing data using ziplist
unsigned int recompress : 1; // Represents whether this node is a compressed node before
unsigned int attempted_compress : 1; // Used during testing
unsigned int extra : 10; // reserve
} quicklistNode;In order to further reduce the space occupied by the ziplist, Redis allows further compression of the ziplist. The compression algorithm adopted by Redis is LZF. The compressed data can be divided into multiple fragments, each fragment has two parts: one part is the interpretation field, and the other part is the storage of specific data fields.

The basic idea of LZF data compression is to record the repeated position and length of the data that is repeated with the previous data, otherwise directly record the content of the original data.
However, the data needs to be decompressed when using.
Basic operation:
Function name | explain |
|---|---|
quicklistCreate | initialization |
quicklistPushHead, quicklistPushTail | Insert at the head or tail |
quicklistDelIndex, quicklistDelRange | Delete the elements in the specified position and interval |
quicklistReplaceAtIndex | Change elements; Delete the original element first, and then insert a new element |
quicklistIndex, quicklistGetIteratorAtIdx | Find the element at the specified location; Iterator traversal lookup |
1) Initialize
Initialization is the first step in building the quicklist structure, which is completed by the quicklistCreate function. The main function of this function is to initialize the quicklist structure
quicklist *quicklistCreate(void) {
struct quicklist *quicklist; //Declare quicklist variables
quicklist = zmalloc(sizeof(*quicklist)); //Request space for quicklist
quicklist->head = quicklist->tail = NULL; //Initialize quicklist structure variable
quicklist->len = 0;
quicklist->count = 0;
quicklist->compress = 0;
quicklist->fill = -2; //As can be seen from table 7-1, the size limit of ziplost is 8KB
return quicklist;
}2) Add element
Adding elements is the first step in data structure operations. quicklist provides push operation. The external interface is quicklistPush, which can be inserted in the head or tail. The specific operation functions are quicklistPushHead and quicklistPushTail.
3) Delete element
For element deletion, quicklist provides two schemes: deleting a single element and deleting interval elements.
For deleting a single element, we can use the external interface quicklistDelEntry of quicklist, or pop up the head or tail element through quicklistPop.
For deleting interval elements, quicklist provides the quicklistDelRange interface, which can delete a specified number of elements from a specified location.
4) Change element
The change element of quicklist is based on index, and the main processing function is quicklistreplaceindex. The basic idea is to delete the original element first, and then insert a new element. quicklist is not suitable for directly changing the original elements, mainly because it has a ziplost structure inside. Ziplost is continuously stored in memory. Changing one of the elements may affect subsequent elements. Therefore, quicklist adopts the scheme of deleting first and then inserting.
5) Find element
The quicklist search element is mainly for index, that is, to find the corresponding element through the subscript of the element in the linked list. The basic idea is to first find the quicklistNode node of the index corresponding data, then call the ziplist interface function ziplistGet to get the data corresponding to index.
(8) Compact list (listpack.c)
Redis designed listpack to replace ziplist. Because ziplist may have cascading updates with a very small probability, when continuous large-scale cascading updates occur, it will have a great impact on the performance of redis.
Structure diagram (byte array, no specific structure):

- Total Bytes: the space size of the whole listpack, which takes up 4 bytes. Each listpack takes up a maximum of 4294967295Bytes.
- Num element: the number of elements in listpack, that is, the number of entries, which takes up 2 bytes.
- End is listpack: end flag. It takes 1 byte and the content is 0xFF.
- Entry: each specific element.
// Total Bytes, the space size of the whole listpack #define LP_HDR_SIZE 6 // Num element, number of elements in listpack #define LP_HDR_NUMELE_UNKNOWN UINT16_MAX // Flag in Entry #define LP_MAX_INT_ENCODING_LEN 9 #define LP_MAX_BACKLEN_SIZE 5 #define LP_MAX_ENTRY_BACKLEN 34359738367ULL #define LP_ENCODING_INT 0 ... // End, end flag #define LP_EOF 0xFF
Compared with the definition of ziplist, it has two changes:
- The length of the record is no longer the length of the previous node, but its own length.
- Put the length of the record itself at the end of the node.
advantage:
- Zltail is no longer needed_ The offset attribute can also quickly locate the last node. Use the total length of listpac - the length of the last node
- Each node records its own length. When the value of this node changes, you only need to change its own length. There is no need to change the attributes of other nodes, which completely solves the problem of cascading updates.
Listpack was introduced in version 5.0, but there are some compatibility problems due to the wide use of ziplost in Reids. However, listpack is used instead of ziplost in the Stream data structure introduced in version 5.0.
Although this structure has low query efficiency and is only suitable for adding and deleting at the end, it is usually only necessary to add messages to the end of the message flow, so this structure can be adopted.
Basic operation:
Function name | explain |
|---|---|
lpNew | initialization |
lpInsert | Addition, deletion and modification; Add - insert at any position; Delete - empty element replacement; Change replace operation |
lpFirst, lpLast, lpNext, lpPrev | Traversal related operations |
lpGet | Read element |
(8) Cardinality tree (rax.c)
Radix tree (also known as radix tree or compressed prefix tree) is a kind of data structure, which is more space-saving Trie (prefix tree).
Rax is an implementation of cardinality tree. In rax, you can not only store a string, but also set a value for the string, that is, key value.
If an intermediate node has multiple child nodes, the routing key is only one character. If there is only one child node, the routing key is a string. The latter is the so-called "compressed" form, a string of multiple characters pressed together.
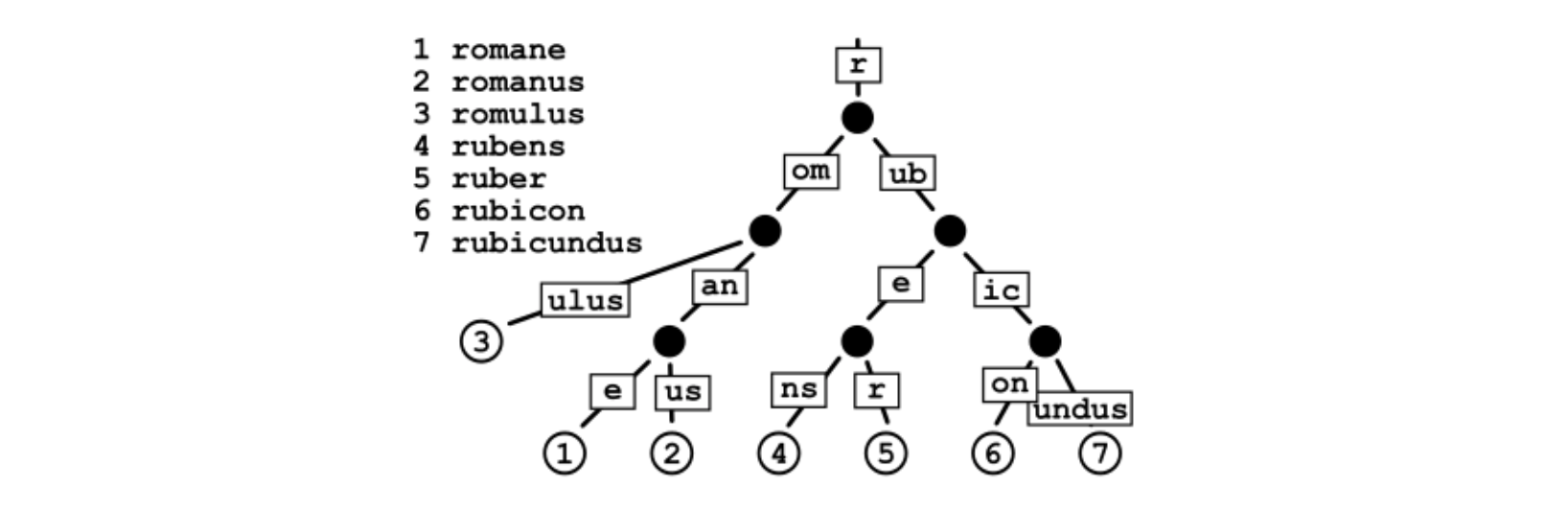
A. Rax tree - structure:
typedef struct rax {
raxNode *head;
uint64_t numele;
uint64_t numnodes;
} rax;B. raxNode - structure:
typedef struct raxNode {
uint32_t iskey:1; // Does the node contain a key
uint32_t isnull:1; // Store value
uint32_t iscompr:1; // Whether to compress
uint32_t size:29; // The number of child nodes, or the length of the compressed string
unsigned char data[];
} raxNode;Basic operation:
Function name | explain |
|---|---|
raxNew | initialization |
raxFind | Find the value corresponding to the string s(key) with length len |
raxInsert, raxTryInsert | Insert a key value pair into rax to overwrite or not overwrite the original value |
raxRemove, raxFree, raxFreeWithCallback | To delete a key in the rax or release the whole rax, you can set the release callback |
raxStart, raxSeek, raxNext, raxPrev, raxStop, raxEOF | Traversal related operations |
Initialization: raxNew
rax *raxNew(void) {
rax *rax = rax_malloc(sizeof(*rax)); //Application space
rax->numele = 0; //The current number of elements is 0
rax->numnodes = 1; //The current number of nodes is 1
rax->head = raxNewNode(0,0); //Construction head node
return rax;
}