DWM layer and DWS layer
1, Design
Design ideas
We previously split the data into independent Kafka topics through shunting at the DWD layer. Then, how to process the data next, we need to think about which index items we want to calculate in real time.
Because real-time computing is different from offline computing, the development, operation and maintenance costs of real-time computing are very high. It is necessary to consider whether it is necessary to build a large and comprehensive middle layer like offline data warehouse in combination with the actual situation.
If it is not necessary to be large and comprehensive, you need to roughly plan the index requirements to be calculated in real time. Outputting these indicators in the form of topic wide table is our DWS layer.
Requirements combing
| Statistical topics | Demand index | Output mode | Calculation source | Source hierarchy |
|---|---|---|---|---|
| visitor | pv | Visual large screen | page_log directly differentiable | dwd |
| uv | Visual large screen | Page is required_ Log filter de duplication | dwm | |
| Jump out rate | Visual large screen | Page is required_ Log behavior judgment | dwm | |
| Number of pages entered | Visual large screen | Need to identify start access ID | dwd | |
| Continuous access duration | Visual large screen | page_log directly differentiable | dwd | |
| commodity | click | Multidimensional analysis | page_log directly differentiable | dwd |
| Collection | Multidimensional analysis | Collection table | dwd | |
| add to cart | Multidimensional analysis | Shopping cart table | dwd | |
| place an order | Visual large screen | Order width table | dwm | |
| payment | Multidimensional analysis | Payment width table | dwm | |
| refund | Multidimensional analysis | Refund form | dwd | |
| comment | Multidimensional analysis | Comment form | dwd | |
| region | pv | Multidimensional analysis | page_log directly differentiable | dwd |
| uv | Multidimensional analysis | Page is required_ Log filter de duplication | dwm | |
| place an order | Visual large screen | Order width table | dwm | |
| key word | Search keywords | Visual large screen | Page access logs are directly available | dwd |
| Click commodity keywords | Visual large screen | Re aggregation of product subject orders | dws | |
| Keywords of ordered goods | Visual large screen | Re aggregation of product subject orders | dws |
There will be more actual requirements. Here, real-time calculation is mainly carried out for the purpose of large visual screen.
What is the positioning of DWM layer? DWM layer mainly serves DWS, because some requirements directly from DWD layer to DWS layer will have a certain amount of calculation, and the results of this calculation are likely to be reused by multiple DWS layer topics. Therefore, some DWD layers will form a layer of DWM, which is mainly related to business
- Accessing UV calculations
- Jump out of detail calculation
- Order width table
- Payment width table
2, DWM visitor UV calculation
Demand analysis and ideas
uv, the full name is Unique Visitor, that is, independent visitor. For real-time calculation, it can also be called DAU(Daily Active User), that is, daily active user, because uv in real-time calculation usually refers to the number of visitors on that day.
So how to identify the visitors of the day from the user behavior log, there are two points:
- First, identify the first page opened by the visitor, indicating that the visitor begins to enter our application
- Second, since visitors can enter the application many times a day, we need to de duplicate it within a day
code
package com.atguigu.app.dwm;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.atguigu.utils.MyKafkaUtil;
import org.apache.flink.api.common.functions.RichFilterFunction;
import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import java.text.SimpleDateFormat;
/*
Data flow:
web/app -> nginx -> springboot -> Kafka -> FlinkApp(LogBaseApp) -> Kafka
FlinkApp(DauApp) -> Kafka
Service: Nginx Logger zookeeper Kafka LogbaseApp DauApp consumer (dwm_unique_visit) MockLog
*/
public class DauApp {
public static void main(String[] args) throws Exception {
//1. Obtain execution environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// //1.1 setting status
// env.setStateBackend(new FsStateBackend("hdfs://hadoop102:9000/gmall/dwd_log/ck"));
//1.2 open CK
// env.enableCheckpointing(10000L, CheckpointingMode.EXACTLY_ONCE);
// env.getCheckpointConfig().setCheckpointTimeout(60000L);
//2. Read Kafka dwd_page_log topic data creation stream
String groupId = "unique_visit_app";
String sourceTopic = "dwd_page_log";
String sinkTopic = "dwm_unique_visit";
FlinkKafkaConsumer<String> kafkaSource = MyKafkaUtil.getKafkaSource(sourceTopic, groupId);
DataStreamSource<String> kafkaDS = env.addSource(kafkaSource);
//3. Convert each row of data into JSON objects
SingleOutputStreamOperator<JSONObject> jsonObjDS = kafkaDS.process(new ProcessFunction<String, JSONObject>() {
@Override
public void processElement(String s, Context context, Collector<JSONObject> collector) throws Exception {
try {
JSONObject jsonObject = JSON.parseObject(s);
collector.collect(jsonObject);
} catch (Exception e) {
e.printStackTrace();
context.output(new OutputTag<String>("dirty") {
}, s);
}
}
});
/*
kafkaDS.map(new MapFunction<String, JSONObject>() {
@Override
public JSONObject map(String s) throws Exception {
try {
return JSON.parseObject(s);
} catch (Exception e) {
e.printStackTrace();
System.out.println("Dirty data found: "+ s);
return null;
}
}
});
*/
//4. Group by mid
KeyedStream<JSONObject, String> keyedStream = jsonObjDS.keyBy
(jsonObject -> jsonObject.getJSONObject("common").getString("mid"));
//5. Filter out the data not accessed for the first time today
SingleOutputStreamOperator<JSONObject> filterDS = keyedStream.filter(new UvRichFilterFunction());
//6. Write to Kafka topic of DWM layer
filterDS.map(json -> json.toString()).addSink(MyKafkaUtil.getKafkaSink(sinkTopic));
//7. Start task
env.execute();
}
public static class UvRichFilterFunction extends RichFilterFunction<JSONObject>{
private ValueState<String> firstVisitState ;
private SimpleDateFormat simpleDateFormat;
@Override
public void open(Configuration parameters) throws Exception {
simpleDateFormat=new SimpleDateFormat("yyyy-MM-dd");
ValueStateDescriptor<String> stringValueStateDescriptor = new ValueStateDescriptor<>("visit-state", String.class);
//Create status TTL configuration object
StateTtlConfig stateTtlConfig = StateTtlConfig.newBuilder(Time.days(1))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.build();
//Keep for 24 hours
stringValueStateDescriptor.enableTimeToLive(stateTtlConfig);
firstVisitState = getRuntimeContext().getState(stringValueStateDescriptor);
}
@Override
public boolean filter(JSONObject jsonObject) throws Exception {
//Take out the last visited page
String lastPageId = jsonObject.getJSONObject("page").getString("last_page_id");
//Determine whether there is a previous page (whether it came in from the previous page, not newly opened)
if (lastPageId == null || lastPageId.length()<=0){
//Fetch status data
String firstVisitData = firstVisitState.value();
//Data extraction time
Long ts = jsonObject.getLong("ts");
String curDate = simpleDateFormat.format(ts);
if (firstVisitData == null || firstVisitData.equals(curDate)){
firstVisitState.update(curDate);
return true;
}else {
return false;
}
}else {
return false;
}
}
}
}
3, DWM visitor jump out of detail calculation
Demand analysis and ideas
Jump out
Jumping out means that the user exits after successfully visiting one page of the website and does not continue to visit other pages of the website. The jump out rate is divided by the number of jumps out divided by the number of visits.
By focusing on the jump out rate, we can see whether the drained visitors can be attracted quickly, the quality comparison between the users drained from the channel, and the comparison of the jump out rate before and after application optimization can also see the results of optimization and improvement.
Thinking of calculating jump out behavior
First of all, we should identify which are jump out behaviors, and identify the last page visited by these jump out visitors. Then we should grasp several characteristics:
- This page is the first page recently visited by the user
This can be determined by whether the page has a previous page (last_page_id). If the representation is empty, it means that this is the first page visited by the visitor this time.
- For a long time after the first visit (set by yourself), users do not continue to visit other pages.
The recognition of this first feature is very simple and last is retained_ page_ It is OK if the ID is empty. However, the judgment of the second access is actually a little troublesome. First, it can not be concluded with one piece of data. It needs to be combined. It needs to be combined with one piece of existing data and non-existing data. Moreover, an existing piece of data should be obtained from a non-existent data. What is more troublesome is that he does not exist forever, but does not exist within a certain time range. So how to identify the combination behavior with certain failure?
The simplest way is Flink's own CEP technology. This CEP is very suitable for identifying an event through multiple data combinations.
The user jump out event is essentially a combination of a condition event and a timeout event.
{"common":{"mid":"101"},"page":{"page_id":"home"},"ts":1000000000}
{"common":{"mid":"102"},"page":{"page_id":"home"},"ts":1000000001}
{"common":{"mid":"102"},"page":{"page_id":"home","last_page_id":"aa"},"ts":1000000020}
{"common":{"mid":"102"},"page":{"page_id":"home","last_page_id":"aa"},"ts":1000000030}
code
package com.atguigu.app.dwm;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.atguigu.utils.MyKafkaUtil;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.cep.CEP;
import org.apache.flink.cep.PatternFlatSelectFunction;
import org.apache.flink.cep.PatternFlatTimeoutFunction;
import org.apache.flink.cep.PatternStream;
import org.apache.flink.cep.pattern.Pattern;
import org.apache.flink.cep.pattern.conditions.SimpleCondition;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import java.util.List;
import java.util.Map;
public class UserJumpDetailApp {
public static void main(String[] args) throws Exception {
//1. Obtain execution environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// //1.1 setting status
// env.setStateBackend(new FsStateBackend("hdfs://hadoop102:9000/gmall/dwd_log/ck"));
//1.2 open CK
// env.enableCheckpointing(10000L, CheckpointingMode.EXACTLY_ONCE);
// env.getCheckpointConfig().setCheckpointTimeout(60000L);
//2. Read Kafka dwd_page_log topic data creation stream
String sourceTopic = "dwd_page_log";
String groupId = "userJumpDetailApp";
String sinkTopic = "dwm_user_jump_detail";
FlinkKafkaConsumer<String> kafkaSource = MyKafkaUtil.getKafkaSource(sourceTopic, groupId);
DataStreamSource<String> kafkaDS = env.addSource(kafkaSource);
// DataStream<String> kafkaDS = env
// .fromElements(
// "{\"common\":{\"mid\":\"101\"},\"page\":{\"page_id\":\"home\"},\"ts\":1000000000} ",
// "{\"common\":{\"mid\":\"102\"},\"page\":{\"page_id\":\"home\"},\"ts\":1000000001}",
// "{\"common\":{\"mid\":\"102\"},\"page\":{\"page_id\":\"good_list\",\"last_page_id\":" +
// "\"home\"},\"ts\":1000000020} ",
// "{\"common\":{\"mid\":\"102\"},\"page\":{\"page_id\":\"good_list\",\"last_page_id\":" +
// "\"detail\"},\"ts\":1000000025} "
// );
//
//DataStream<String> kafkaDS = env.socketTextStream("hadoop103",9999);
//Extract the timestamp in the data and generate watermark
WatermarkStrategy<JSONObject> watermarkStrategy = WatermarkStrategy.<JSONObject>forMonotonousTimestamps().withTimestampAssigner(new SerializableTimestampAssigner<JSONObject>() {
@Override
public long extractTimestamp(JSONObject jsonObject, long l) {
return jsonObject.getLong("ts");
}
});
//3. Convert data to JSON object
SingleOutputStreamOperator<JSONObject> jsonObjDS = kafkaDS.process(new ProcessFunction<String, JSONObject>() {
@Override
public void processElement(String s, Context context, Collector<JSONObject> collector) throws Exception {
try {
JSONObject jsonObject = JSON.parseObject(s);
collector.collect(jsonObject);
} catch (Exception e) {
context.output(new OutputTag<String>("dirty"){},s);
}
}
}).assignTimestampsAndWatermarks(watermarkStrategy);
//4. Partition according to Mid
KeyedStream<JSONObject, String> keyedStream = jsonObjDS.keyBy(jsonObject -> jsonObject.getJSONObject("common").getString("mid"));
//5. Define pattern sequence
Pattern<JSONObject, JSONObject> pattern = Pattern.<JSONObject>begin("start").where(new SimpleCondition<JSONObject>() {
@Override
public boolean filter(JSONObject jsonObject) throws Exception {
//Take out the previous page information
String lastPageId = jsonObject.getJSONObject("page").getString("last_page_id");
return (lastPageId == null || lastPageId.length() <= 0);
}
}).followedBy("follow").where(new SimpleCondition<JSONObject>() {
@Override
public boolean filter(JSONObject value) throws Exception {
String lastPageId = value.getJSONObject("page").getString("last_page_id");
return lastPageId != null && lastPageId.length() > 0;
}
}).within(Time.seconds(10));
//6. Apply the pattern sequence to the flow
PatternStream<JSONObject> patternStream = CEP.pattern(keyedStream, pattern);
//7. Extract events and timeout events
OutputTag<String> timeOutTag = new OutputTag<String>("timeOut") {};
SingleOutputStreamOperator<Object> selectDS = patternStream.flatSelect(timeOutTag, new PatternFlatTimeoutFunction<JSONObject, String>() {
@Override
public void timeout(Map<String, List<JSONObject>> map, long l, Collector<String> collector) throws Exception {
collector.collect(map.get("start").get(0).toString());
}
}, new PatternFlatSelectFunction<JSONObject, Object>() {
@Override
public void flatSelect(Map<String, List<JSONObject>> map, Collector<Object> collector) throws Exception {
//Nothing there?
//Because of what's inside! It's no use!
}
});
//8. Write data to Kafka
FlinkKafkaProducer<String> kafkaSink = MyKafkaUtil.getKafkaSink(sinkTopic);
selectDS.getSideOutput(timeOutTag).addSink(kafkaSink);
//9. Implementation of tasks
env.execute();
}
}
4, DWM commodity order wide table
Demand analysis and ideas
Orders are important objects of statistical analysis. There are many dimensions of statistical needs around orders, such as users, regions, commodities, categories, brands, etc.
In order to make the statistical calculation more convenient and reduce the association between large tables, the relevant data around orders will be integrated into a wide table of orders in the process of real-time calculation.
What data needs to be integrated with orders?
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-kDTYAKAz-1629586654467)(D: \ real-time data warehouse \ picture 13.png)]
As shown in the figure above, we have split the data into fact data and dimension data, The fact data (green) enters the kafka data stream (DWD layer) and the dimension data (blue) enters hbase for medium and long-term storage. Then, we need to integrate and associate the real-time and dimension data in the DWM layer to form a wide table. Here, we need to deal with two kinds of associations: fact data and fact data association, fact data and dimension data association.
- Fact data and fact data association are actually the association between streams.
- Fact data is associated with dimension data, which is actually querying external data sources in flow calculation.
code implementation
Receive order and order detail data from Kafka's dwd layer
package com.atguigu.app.dwm;
import com.alibaba.fastjson.JSON;
import com.atguigu.bean.OrderDetail;
import com.atguigu.bean.OrderInfo;
import com.atguigu.bean.OrderWide;
import com.atguigu.utils.MyKafkaUtil;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.ProcessJoinFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import java.text.SimpleDateFormat;
/**
* Mock -> MySQL(binlog) -> MaxWell -> Kafka(ods_base_db_m)
* -> DbBaseApp(Modify configuration, Phoenix)
* -> Kafka(dwd_order_info,dwd_order_detail) -> OrderWideApp
*/
public class OrderWideApp {
public static void main(String[] args) throws Exception {
//1. Obtain execution environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// //1.1 setting status
// env.setStateBackend(new FsStateBackend("hdfs://hadoop102:9000/gmall/dwd_log/ck"));
//1.2 open CK
// env.enableCheckpointing(10000L, CheckpointingMode.EXACTLY_ONCE);
// env.getCheckpointConfig().setCheckpointTimeout(60000L);
//2. Read kafka order and order details subject data dwd_order_info dwd_order_detail
String orderInfoSourceTopic = "dwd_order_info";
String orderDetailSourceTopic = "dwd_order_detail";
String orderWideSinkTopic = "dwm_order_wide";
String groupId = "order_wide_group";
FlinkKafkaConsumer<String> orderInfoKafkaSource = MyKafkaUtil.getKafkaSource(orderInfoSourceTopic, groupId);
DataStreamSource<String> orderInfoKafkaDS = env.addSource(orderInfoKafkaSource);
FlinkKafkaConsumer<String> orderDetailKafkaSource = MyKafkaUtil.getKafkaSource(orderDetailSourceTopic, groupId);
DataStreamSource<String> orderDetailKafkaDS = env.addSource(orderDetailKafkaSource);
//3. Convert each row of data into a JavaBean, extract the timestamp, and generate a WaterMark
WatermarkStrategy<OrderInfo> orderInfoWatermarkStrategy = WatermarkStrategy.<OrderInfo>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<OrderInfo>() {
@Override
public long extractTimestamp(OrderInfo orderInfo, long l) {
return orderInfo.getCreate_ts();
}
});
WatermarkStrategy<OrderDetail> orderDetailWatermarkStrategy = WatermarkStrategy.<OrderDetail>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<OrderDetail>() {
@Override
public long extractTimestamp(OrderDetail orderDetail, long l) {
return orderDetail.getCreate_ts();
}
});
KeyedStream<OrderInfo, Long> orderInfoWithIdKeyedStream = orderInfoKafkaDS.map(jsonStr -> {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
//Convert JSON string to JavaBean
OrderInfo orderInfo = JSON.parseObject(jsonStr, OrderInfo.class);
//Take out the creation time field
String create_time = orderInfo.getCreate_time();
//Split by space
String[] createTimeArr = create_time.split(" ");
orderInfo.setCreate_date(createTimeArr[0]);
orderInfo.setCreate_hour(createTimeArr[1]);
orderInfo.setCreate_ts(sdf
.parse(create_time).getTime());
return orderInfo;
}).assignTimestampsAndWatermarks(orderInfoWatermarkStrategy)
.keyBy(OrderInfo::getId);
KeyedStream<OrderDetail, Long> orderDetailWithOrderKeyedStream = orderDetailKafkaDS.map(jsonStr -> {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
OrderDetail orderDetail = JSON.parseObject(jsonStr, OrderDetail.class);
orderDetail.setCreate_ts(sdf.parse(orderDetail.getCreate_time()).getTime());
return orderDetail;
}).assignTimestampsAndWatermarks(orderDetailWatermarkStrategy)
.keyBy(OrderDetail::getOrder_id);
//4. Double flow JOIN
SingleOutputStreamOperator<OrderWide> orderWideDS = orderInfoWithIdKeyedStream.intervalJoin(orderDetailWithOrderKeyedStream)
.between(Time.seconds(-5), Time.seconds(5))//In the production environment, in order not to lose data, set the time to the maximum network delay
.process(new ProcessJoinFunction<OrderInfo, OrderDetail, OrderWide>() {
@Override
public void processElement(OrderInfo orderInfo, OrderDetail orderDetail, Context context, Collector<OrderWide> collector) throws Exception {
collector.collect(new OrderWide(orderInfo, orderDetail));
}
});
//Test printing
orderWideDS.print(">>>>>>>>>>>>>>>");
//5. Associated dimension
//6. Write data to Kafka dwm_order_wide
//7. Start task
env.execute();
}
}
Test results:

Query Phoenix tool class encapsulation
package com.atguigu.utils;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.atguigu.common.GmallConfig;
import org.apache.commons.beanutils.BeanUtils;
import java.sql.*;
import java.util.ArrayList;
import java.util.List;
public class PhoenixUtil {
//statement
private static Connection connection;
//Initialize connection
private static void init(){
try {
Class.forName(GmallConfig.PHOENIX_DRIVER);
connection = DriverManager.getConnection(GmallConfig.PHOENIX_SERVER);
//Set the library of Phoenix connected to
connection.setSchema(GmallConfig.HBASE_SCHEMA);
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException("Failed to get connection!");
}
}
public static <T>List<T> queryList(String sql,Class<T> cls){
//Initialize connection
init();
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
try {
//Compile SQL
preparedStatement = connection.prepareStatement(sql);
//Execute query
resultSet = preparedStatement.executeQuery();
//Get metadata information in query results
ResultSetMetaData metaData = resultSet.getMetaData();
int columnCount = metaData.getColumnCount();
ArrayList<T> list = new ArrayList<>();
while (resultSet.next()){//Right line
T t = cls.newInstance();
for (int i = 1; i <= columnCount; i++) {//Pair column
BeanUtils.setProperty(t,metaData.getColumnName(i),resultSet.getObject(i));
}
list.add(t);
}
return list;
} catch (Exception throwables) {
throw new RuntimeException("Failed to query dimension information");
}finally {
if (preparedStatement != null){
try {
preparedStatement.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
if (resultSet != null){
try {
resultSet.close();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}
}
}
public static void main(String[] args) {
System.out.println(queryList("select * from GMALL200821_REALTIME.DIM_BASE_TRADEMARK", JSONObject.class));
}
}
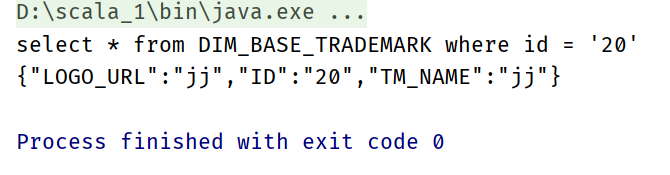
test result


Query dimension information tool class encapsulation
package com.atguigu.utils;
import com.alibaba.fastjson.JSONObject;
import org.apache.flink.api.java.tuple.Tuple2;
import java.util.List;
//Tool class for querying dimension tables
/*
select * from t where id = '' and name ='';
*/
public class DimUtil {
public static JSONObject getDimInfo(String tableName, Tuple2<String,String>... columnValues){
if (columnValues.length<=0){
throw new RuntimeException("When querying dimension data, please set at least one query criteria");//Throw an exception and stop the operation
}
StringBuilder whereSql = new StringBuilder(" where ");
//Traverse the query criteria and assign whereSql
for (int i = 0; i < columnValues.length; i++) {
Tuple2<String, String> columnValue = columnValues[i];
String column = columnValue.f0;
String value = columnValue.f1;
whereSql.append(column).append(" = '").append(value).append("'");
//Judge if it is not the last condition, add "and"
if (i < columnValues.length -1){
whereSql.append("and");
}
}
String querySql= "select * from "+tableName + whereSql.toString();
System.out.println(querySql);
//Query dimension data in Phoenix
List<JSONObject> queryList = PhoenixUtil.queryList(querySql, JSONObject.class);
return queryList.get(0);
}
public static JSONObject getDimInfo(String tableName,String value){
return getDimInfo(tableName,new Tuple2<>("id",value));
}
public static void main(String[] args) {
System.out.println(getDimInfo("DIM_BASE_TRADEMARK","20"));
}
}
test result
Optimize 1 bypass cache
Code implementation - DimUtil
package com.atguigu.utils;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import org.apache.flink.api.java.tuple.Tuple2;
import redis.clients.jedis.Jedis;
import java.util.List;
//Tool class for querying dimension tables
/*
select * from t where id = '' and name ='';
*/
/**
* <p>
* Redis
* 1.What data dimension data is stored in JsonStr
* 2,What type of String Set Hash is used
* 3.RedisKey Your design? String:tableName+id Set : tableName Hash:tableName
*
* <p>
* The collection method is excluded because we need to set the expiration time for each independent dimension data
*/
public class DimUtil {
public static JSONObject getDimInfo(String tableName, Tuple2<String,String>... columnValues){
if (columnValues.length<=0){
throw new RuntimeException("When querying dimension data, please set at least one query criteria");//Throw an exception and stop the operation
}
//Create Phoenix Where clause
StringBuilder whereSql = new StringBuilder(" where ");
StringBuilder rediskey = new StringBuilder(tableName).append(":");
//Traverse the query criteria and assign whereSql
for (int i = 0; i < columnValues.length; i++) {
Tuple2<String, String> columnValue = columnValues[i];
String column = columnValue.f0;
String value = columnValue.f1;
whereSql.append(column).append(" = '").append(value).append("'");
rediskey.append(value);
//Judge if it is not the last condition, add "and"
if (i < columnValues.length -1){
whereSql.append("and");
rediskey.append(":");
}
}
//Get Redis connection
Jedis jedis = RedisUtil.getJedis();
String dimJsonStr = jedis.get(rediskey.toString());
//Judge whether data is queried from Redis
if (dimJsonStr!=null&& dimJsonStr.length()>0){
jedis.close();
return JSON.parseObject(dimJsonStr);
}
String querySql= "select * from "+tableName + whereSql.toString();
System.out.println(querySql);
//Query dimension data in Phoenix
List<JSONObject> queryList = PhoenixUtil.queryList(querySql, JSONObject.class);
JSONObject dimJsonObj = queryList.get(0);
//Write data to Redis
jedis.set(rediskey.toString(),dimJsonObj.toString());
jedis.expire(rediskey.toString(),24*60*60);
return dimJsonObj;
}
public static JSONObject getDimInfo(String tableName,String value){
return getDimInfo(tableName,new Tuple2<>("id",value));
}
public static void main(String[] args) {
System.out.println(getDimInfo("DIM_BASE_TRADEMARK","20"));
}
}
Code implementation - RedisUtil
package com.atguigu.utils;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public class RedisUtil {
public static JedisPool jedisPool=null;
public static Jedis getJedis(){
if(jedisPool==null){
JedisPoolConfig jedisPoolConfig =new JedisPoolConfig();
jedisPoolConfig.setMaxTotal(100); //Maximum number of available connections
jedisPoolConfig.setBlockWhenExhausted(true); //Connection exhausted wait
jedisPoolConfig.setMaxWaitMillis(2000); //waiting time
jedisPoolConfig.setMaxIdle(5); //Maximum idle connections
jedisPoolConfig.setMinIdle(5); //Minimum number of idle connections
jedisPoolConfig.setTestOnBorrow(true); //Test the connection ping pong
jedisPool=new JedisPool( jedisPoolConfig, "hadoop103",6379 ,1000);
System.out.println("Open connection pool");
return jedisPool.getResource();
}else{
// System.out.println("connection pool:" + jedisPool.getNumActive());
return jedisPool.getResource();
}
}
}
After redis is started
Optimization 2: asynchronous query
In the process of Flink flow processing, it is often necessary to interact with external systems and complete the fields in the fact table with a dimension table.
For example, in the e-commerce scenario, the skuid of a commodity needs to be associated with some attributes of the commodity, such as the industry, manufacturer and manufacturer of the commodity; In the logistics scenario, if you know the package id, you need to associate the package industry attribute, shipment information, receipt information, and so on.
By default, in Flink's MapFunction, a single parallel can only interact synchronously: * * send the request to external storage, IO block, wait for the request to return, and then continue to send the next request** This way of synchronous interaction often consumes a lot of time waiting on the network. In order to improve processing efficiency, you can increase the parallelism of MapFunction, but increasing the parallelism means more resources, which is not a very good solution.
Flink introduces Async I/O in 1.2. In the asynchronous mode, IO operations are asynchronized. A single parallel can send multiple requests continuously. Which request returns first is processed first, so there is no need for blocking waiting between consecutive requests, which greatly improves the flow processing efficiency.
Async I/O is a very popular feature contributed by Alibaba to the community. It solves the problem that network delay has become a system bottleneck when interacting with external systems.
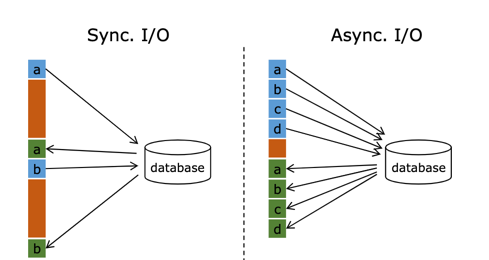
Asynchronous query actually entrusts the query operation of dimension table to a separate thread pool, so that it will not be blocked by a query. A single parallel can send multiple requests continuously to improve the concurrency efficiency.
This method is especially for operations involving network IO to reduce the consumption caused by request waiting.
Code implementation - OrderWideApp
package com.atguigu.app.dwm;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.atguigu.app.func.DimAsyncFunction;
import com.atguigu.bean.OrderDetail;
import com.atguigu.bean.OrderInfo;
import com.atguigu.bean.OrderWide;
import com.atguigu.utils.MyKafkaUtil;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.AsyncDataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.ProcessJoinFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.concurrent.TimeUnit;
/**
* Mock -> Mysql(binLog) -> MaxWell -> Kafka(ods_base_db_m) -> DbBaseApp(Modify configuration, Phoenix)
* -> Kafka(dwd_order_info,dwd_order_detail) -> OrderWideApp(Associated dimension (Redis)
*/
public class OrderWideApp {
public static void main(String[] args) throws Exception {
//1. Obtain execution environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//1.1 setting status
// env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/gmall/dwd_log/ck"));
// //1.2 open CK
// env.enableCheckpointing(10000L, CheckpointingMode.EXACTLY_ONCE);
// env.getCheckpointConfig().setCheckpointTimeout(60000L);
//2. Read Kafka order and order details subject data dwd_order_info dwd_order_detail
String orderInfoSourceTopic = "dwd_order_info";
String orderDetailSourceTopic = "dwd_order_detail";
String orderWideSinkTopic = "dwm_order_wide";
String groupId = "order_wide_group";
FlinkKafkaConsumer<String> orderInfoKafkaSource = MyKafkaUtil.getKafkaSource(orderInfoSourceTopic, groupId);
DataStreamSource<String> orderInfoKafkaDS = env.addSource(orderInfoKafkaSource);
FlinkKafkaConsumer<String> orderDetailKafkaSource = MyKafkaUtil.getKafkaSource(orderDetailSourceTopic, groupId);
DataStreamSource<String> orderDetailKafkaDS = env.addSource(orderDetailKafkaSource);
//3. Convert each row of data into a JavaBean and extract the timestamp to generate a WaterMark
WatermarkStrategy<OrderInfo> orderInfoWatermarkStrategy = WatermarkStrategy.<OrderInfo>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<OrderInfo>() {
@Override
public long extractTimestamp(OrderInfo element, long recordTimestamp) {
return element.getCreate_ts();
}
});
WatermarkStrategy<OrderDetail> orderDetailWatermarkStrategy = WatermarkStrategy.<OrderDetail>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<OrderDetail>() {
@Override
public long extractTimestamp(OrderDetail element, long recordTimestamp) {
return element.getCreate_ts();
}
});
KeyedStream<OrderInfo, Long> orderInfoWithIdKeyedStream = orderInfoKafkaDS.map(jsonStr -> {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
//Convert JSON string to JavaBean
OrderInfo orderInfo = JSON.parseObject(jsonStr, OrderInfo.class);
//Take out the creation time field
String create_time = orderInfo.getCreate_time();
//Split by space
String[] createTimeArr = create_time.split(" ");
orderInfo.setCreate_date(createTimeArr[0]);
orderInfo.setCreate_hour(createTimeArr[1]);
orderInfo.setCreate_ts(sdf.parse(create_time).getTime());
return orderInfo;
}).assignTimestampsAndWatermarks(orderInfoWatermarkStrategy)
.keyBy(OrderInfo::getId);
KeyedStream<OrderDetail, Long> orderDetailWithOrderIdKeyedStream = orderDetailKafkaDS.map(jsonStr -> {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
OrderDetail orderDetail = JSON.parseObject(jsonStr, OrderDetail.class);
orderDetail.setCreate_ts(sdf.parse(orderDetail.getCreate_time()).getTime());
return orderDetail;
}).assignTimestampsAndWatermarks(orderDetailWatermarkStrategy)
.keyBy(OrderDetail::getOrder_id);
//4. Double flow JOIN
SingleOutputStreamOperator<OrderWide> orderWideDS = orderInfoWithIdKeyedStream.intervalJoin(orderDetailWithOrderIdKeyedStream)
.between(Time.seconds(-5), Time.seconds(5)) //In the production environment, in order not to lose data, set the time to the maximum network delay
.process(new ProcessJoinFunction<OrderInfo, OrderDetail, OrderWide>() {
@Override
public void processElement(OrderInfo orderInfo, OrderDetail orderDetail, Context context, Collector<OrderWide> collector) throws Exception {
collector.collect(new OrderWide(orderInfo, orderDetail));
}
});
//Test printing
// orderWideDS.print(">>>>>>>>>");
//5. Associated dimension
//5.1 associated user dimension
SingleOutputStreamOperator<OrderWide> orderWideWithUserDS = AsyncDataStream.unorderedWait(orderWideDS,
new DimAsyncFunction<OrderWide>("DIM_USER_INFO") {
@Override
public String getKey(OrderWide orderWide) {
return orderWide.getUser_id().toString();
}
@Override
public void join(OrderWide orderWide, JSONObject dimInfo) throws ParseException {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
//Retrieve the birthday in the user dimension
String birthday = dimInfo.getString("BIRTHDAY");
long currentTS = System.currentTimeMillis();
Long ts = sdf.parse(birthday).getTime();
//Process Birthday field to age
Long ageLong = (currentTS - ts) / 1000L / 60 / 60 / 24 / 365;
orderWide.setUser_age(ageLong.intValue());
//Retrieve gender in user dimension
String gender = dimInfo.getString("GENDER");
orderWide.setUser_gender(gender);
}
},
60,
TimeUnit.SECONDS);
//orderWideWithUserDS.print("Users>>>>>>");
//5.2 associated region dimension
SingleOutputStreamOperator<OrderWide> orderWideWithProvinceDS = AsyncDataStream.unorderedWait(orderWideWithUserDS,
new DimAsyncFunction<OrderWide>("DIM_BASE_PROVINCE") {
@Override
public String getKey(OrderWide orderWide) {
return orderWide.getProvince_id().toString();
}
@Override
public void join(OrderWide orderWide, JSONObject dimInfo) throws Exception {
//Extract dimension information and set it into orderWide
orderWide.setProvince_name(dimInfo.getString("NAME"));
orderWide.setProvince_area_code(dimInfo.getString("AREA_CODE"));
orderWide.setProvince_iso_code(dimInfo.getString("ISO_CODE"));
orderWide.setProvince_3166_2_code(dimInfo.getString("ISO_3166_2"));
}
}, 60, TimeUnit.SECONDS);
//orderWideWithProvinceDS.print("Province>>>>>>>>");
//5.3 associated SKU dimensions
SingleOutputStreamOperator<OrderWide> orderWideWithSkuDS = AsyncDataStream.unorderedWait(
orderWideWithProvinceDS, new DimAsyncFunction<OrderWide>("DIM_SKU_INFO") {
@Override
public void join(OrderWide orderWide, JSONObject jsonObject) throws Exception {
orderWide.setSku_name(jsonObject.getString("SKU_NAME"));
orderWide.setCategory3_id(jsonObject.getLong("CATEGORY3_ID"));
orderWide.setSpu_id(jsonObject.getLong("SPU_ID"));
orderWide.setTm_id(jsonObject.getLong("TM_ID"));
}
@Override
public String getKey(OrderWide orderWide) {
return String.valueOf(orderWide.getSku_id());
}
}, 60, TimeUnit.SECONDS);
//orderWideWithSkuDS.print("sku>>>>");
//5.4 associated SPU dimensions
SingleOutputStreamOperator<OrderWide> orderWideWithSpuDS = AsyncDataStream.unorderedWait(
orderWideWithSkuDS, new DimAsyncFunction<OrderWide>("DIM_SPU_INFO") {
@Override
public void join(OrderWide orderWide, JSONObject jsonObject) throws Exception {
orderWide.setSpu_name(jsonObject.getString("SPU_NAME"));
}
@Override
public String getKey(OrderWide orderWide) {
return String.valueOf(orderWide.getSpu_id());
}
}, 60, TimeUnit.SECONDS);
//orderWideWithSpuDS.print("spu");
//5.5 associated brand dimension
SingleOutputStreamOperator<OrderWide> orderWideWithTmDS = AsyncDataStream.unorderedWait(
orderWideWithSpuDS, new DimAsyncFunction<OrderWide>("DIM_BASE_TRADEMARK") {
@Override
public void join(OrderWide orderWide, JSONObject jsonObject) throws Exception {
orderWide.setTm_name(jsonObject.getString("TM_NAME"));
}
@Override
public String getKey(OrderWide orderWide) {
return String.valueOf(orderWide.getTm_id());
}
}, 60, TimeUnit.SECONDS);
//5.6 associated category dimension
SingleOutputStreamOperator<OrderWide> orderWideWithCategory3DS = AsyncDataStream.unorderedWait(
orderWideWithTmDS, new DimAsyncFunction<OrderWide>("DIM_BASE_CATEGORY3") {
@Override
public void join(OrderWide orderWide, JSONObject jsonObject) throws Exception {
orderWide.setCategory3_name(jsonObject.getString("NAME"));
}
@Override
public String getKey(OrderWide orderWide) {
return String.valueOf(orderWide.getCategory3_id());
}
}, 60, TimeUnit.SECONDS);
orderWideWithCategory3DS.print("3DS>>>>");
//6. Write data to Kafka DWM_ order_ wide
orderWideWithCategory3DS.map(JSON::toJSONString)
.addSink(MyKafkaUtil.getKafkaSink(orderWideSinkTopic));
//7. Start task
env.execute();
}
}
5, DWM - goods - payment spread sheet
Demand analysis and ideas
The main reason for the wide payment table is that the payment table does not include the order details, the payment amount is not subdivided into commodities, and there is no way to count the payment status of commodity level.
Therefore, the core of this wide table is to associate the information of the payment table with the order details.
Code implementation - payment entity class - PaymentInfo
package com.atguigu.bean;
import lombok.Data;
import java.math.BigDecimal;
@Data
public class PaymentInfo {
Long id;
Long order_id;
Long user_id;
BigDecimal total_amount;
String subject;
String payment_type;
String create_time;
String callback_time;
}
Code implementation - payment wide table entity class - PaymentWide
package com.atguigu.bean;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.commons.beanutils.BeanUtils;
import java.lang.reflect.InvocationTargetException;
import java.math.BigDecimal;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class PaymentWide {
Long payment_id;
String subject;
String payment_type;
String payment_create_time;
String callback_time;
Long detail_id;
Long order_id;
Long sku_id;
BigDecimal order_price;
Long sku_num;
String sku_name;
Long province_id;
String order_status;
Long user_id;
BigDecimal total_amount;
BigDecimal activity_reduce_amount;
BigDecimal coupon_reduce_amount;
BigDecimal original_total_amount;
BigDecimal feight_fee;
BigDecimal split_feight_fee;
BigDecimal split_activity_amount;
BigDecimal split_coupon_amount;
BigDecimal split_total_amount;
String order_create_time;
String province_name;//Query dimension table
String province_area_code;
String province_iso_code;
String province_3166_2_code;
Integer user_age; //User information
String user_gender;
Long spu_id; //To be associated as dimension data
Long tm_id;
Long category3_id;
String spu_name;
String tm_name;
String category3_name;
public PaymentWide(PaymentInfo paymentInfo, OrderWide orderWide) {
mergeOrderWide(orderWide);
mergePaymentInfo(paymentInfo);
}
public void mergePaymentInfo(PaymentInfo paymentInfo) {
if (paymentInfo != null) {
try {
BeanUtils.copyProperties(this, paymentInfo);
payment_create_time = paymentInfo.create_time;
payment_id = paymentInfo.id;
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
}
}
}
public void mergeOrderWide(OrderWide orderWide) {
if (orderWide != null) {
try {
BeanUtils.copyProperties(this, orderWide);
order_create_time = orderWide.create_time;
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
}
}
}
}
Code implementation - payment wide table processing main program - PaymentWideApp
package com.atguigu.app.dwm;
import com.alibaba.fastjson.JSON;
import com.atguigu.bean.OrderWide;
import com.atguigu.bean.PaymentInfo;
import com.atguigu.bean.PaymentWide;
import com.atguigu.utils.MyKafkaUtil;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.ProcessJoinFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
import java.text.ParseException;
import java.text.SimpleDateFormat;
/**
* Mock -> Mysql(binLog) -> MaxWell -> Kafka(ods_base_db_m) -> DbBaseApp(Modify configuration, Phoenix)
* -> Kafka(dwd_order_info,dwd_order_detail) -> OrderWideApp(Association dimension (redis) - > Kafka (dwm_order_wide)
* -> PaymentWideApp -> Kafka(dwm_payment_wide)
*/
public class PaymentWideApp {
public static void main(String[] args) throws Exception {
//1. Obtain execution environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//1.1 setting status
//env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/gmall/dwd_log/ck"));
//1.2 open CK
//env.enableCheckpointing(10000L, CheckpointingMode.EXACTLY_ONCE);
//env.getCheckpointConfig().setCheckpointTimeout(60000L);
//Modify user name
//System.setProperty("HADOOP_USER_NAME", "atguigu");
//2. Read Kafka subject data dwd_payment_info dwm_order_wide
String groupId = "payment_wide_group";
String paymentInfoSourceTopic = "dwd_payment_info";
String orderWideSourceTopic = "dwm_order_wide";
String paymentWideSinkTopic = "dwm_payment_wide";
DataStreamSource<String> paymentKafkaDS = env.addSource(MyKafkaUtil.getKafkaSource(paymentInfoSourceTopic, groupId));
DataStreamSource<String> orderWideKafkaDS = env.addSource(MyKafkaUtil.getKafkaSource(orderWideSourceTopic, groupId));
//3. Convert the data into JavaBean s and extract the timestamp to generate WaterMark
SingleOutputStreamOperator<PaymentInfo> paymentInfoDS = paymentKafkaDS
.map(jsonStr -> JSON.parseObject(jsonStr, PaymentInfo.class))
.assignTimestampsAndWatermarks(WatermarkStrategy.<PaymentInfo>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<PaymentInfo>() {
@Override
public long extractTimestamp(PaymentInfo element, long recordTimestamp) {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
try {
return sdf.parse(element.getCreate_time()).getTime();
} catch (ParseException e) {
e.printStackTrace();
throw new RuntimeException("Time format error!!");
}
}
}));
SingleOutputStreamOperator<OrderWide> orderWideDS = orderWideKafkaDS
.map(jsonStr -> JSON.parseObject(jsonStr, OrderWide.class))
.assignTimestampsAndWatermarks(WatermarkStrategy.<OrderWide>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<OrderWide>() {
@Override
public long extractTimestamp(OrderWide element, long recordTimestamp) {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
try {
return sdf.parse(element.getCreate_time()).getTime();
} catch (ParseException e) {
e.printStackTrace();
throw new RuntimeException("Time format error!!");
}
}
}));
//4. Group by OrderID
KeyedStream<PaymentInfo, Long> paymentInfoKeyedStream = paymentInfoDS.keyBy(PaymentInfo::getOrder_id);
KeyedStream<OrderWide, Long> orderWideKeyedStream = orderWideDS.keyBy(OrderWide::getOrder_id);
//5. Double flow JOIN
SingleOutputStreamOperator<PaymentWide> paymentWideDS = paymentInfoKeyedStream.intervalJoin(orderWideKeyedStream)
.between(Time.minutes(-15), Time.seconds(0))
.process(new ProcessJoinFunction<PaymentInfo, OrderWide, PaymentWide>() {
@Override
public void processElement(PaymentInfo paymentInfo, OrderWide orderWide, Context ctx, Collector<PaymentWide> out) throws Exception {
out.collect(new PaymentWide(paymentInfo, orderWide));
}
});
//Print test
paymentWideDS.print(">>>>>>>>>>");
//6. Write data to Kafka DWM_ payment_ wide
paymentWideDS.map(JSON::toJSONString).addSink(MyKafkaUtil.getKafkaSink(paymentWideSinkTopic));
//7. Start task
env.execute();
}
}
Code implementation - date conversion tool class - DateTimeUtil
package com.atguigu.utils;
import java.time.LocalDateTime;
import java.time.ZoneId;
import java.time.ZoneOffset;
import java.time.format.DateTimeFormatter;
import java.util.Date;
public class DateTimeUtil {
private final static DateTimeFormatter formator = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
public static String toYMDhms(Date date) {
LocalDateTime localDateTime = LocalDateTime.ofInstant(date.toInstant(), ZoneId.systemDefault());
return formator.format(localDateTime);
}
public static Long toTs(String YmDHms) {
LocalDateTime localDateTime = LocalDateTime.parse(YmDHms, formator);
return localDateTime.toInstant(ZoneOffset.of("+8")).toEpochMilli();
}
}