Solution description
summary
Flink CDC released the latest version 2.1 on November 15, 2021, which adds support for Oracle by introducing built-in Debezium components. This scheme is mainly used to try out the flex connector Oracle CDC. Firstly, the Oracle CDC is debugged locally, and then the Oracle Oceanus Kudu integrated solution is realized in combination with Tencent cloud product flow computing Oceanus and EMR (Kudu), in which there is no complex business logic implementation (the simplest data transfer is carried out here, and users can write corresponding codes according to the actual business situation), And some of the problems found are summarized and shared with readers.
Scheme architecture
The Oracle database environment here is built on a CVM under the EMR cluster through Docker. By manually writing and updating data to the Oracle database, Oceanus captures the changed data in real time and stores it on the Kudu component of EMR. According to the above scheme, the following architecture diagram is designed:

Pre preparation
Create private network VPC
Private network (VPC) is a logically isolated cyberspace customized on Tencent cloud. When building Oceanus cluster, Redis components and other services, it is recommended to select the same VPC before the network can be interconnected. Otherwise, you need to use peer-to-peer connection, NAT gateway, VPN and other methods to get through the network. Please refer to the private network creation steps Help documentation.
Create flow computing Oceanus cluster
Stream computing Oceanus is a powerful tool for real-time analysis of big data product ecosystem. It is an enterprise level real-time big data analysis platform based on Apache Flink, which has the characteristics of one-stop development, seamless connection, sub second delay, low cost, security and stability. Stream computing Oceanus aims to maximize the value of enterprise data and accelerate the construction process of real-time digitization of enterprises.
Create a cluster on the [cluster management] - [new cluster] page of Oceanus console, select region, availability area, VPC, log and storage, and set the initial password. VPC and subnet use the newly created network. After creation, Oceanus clusters are as follows:
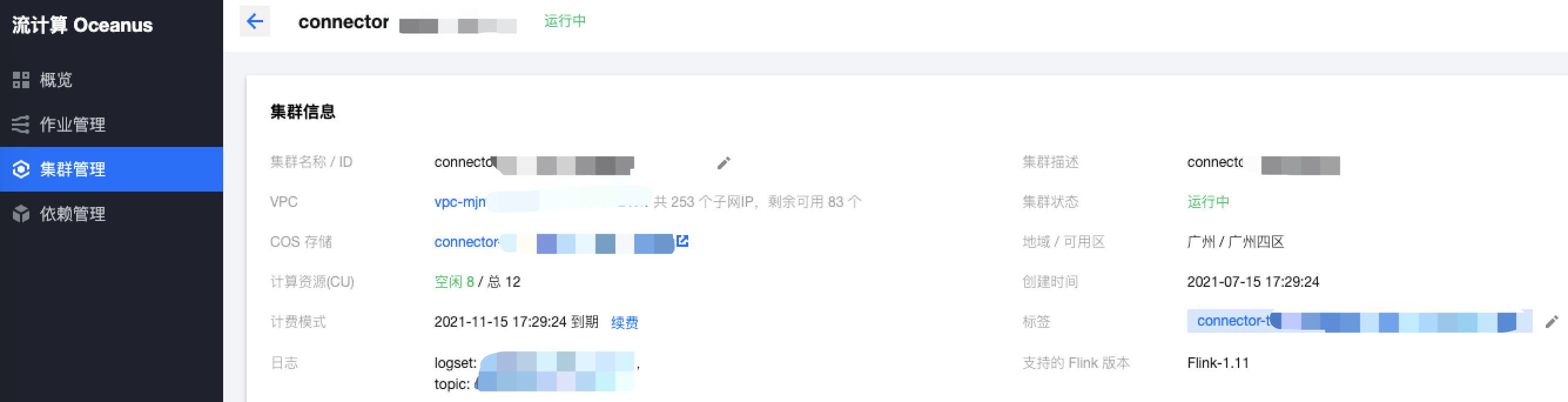
Create EMR cluster
EMR is an elastic open-source pan Hadoop service hosted in the cloud and supports big data frameworks such as Kudu, HDFS, Presto, Flink and Druid. This example mainly needs to use Kudu, Zookeeper, HDFS, Yan, Impala and Knox components.
get into EMR console , click Create cluster in the upper left corner to create a cluster. During the creation process, pay attention to select product version. Different versions contain different components. I choose emr-v3 here Version 2.1. In addition, the [cluster network] needs to select the VPC and corresponding subnet created before. The specific process can be referred to Create EMR cluster.
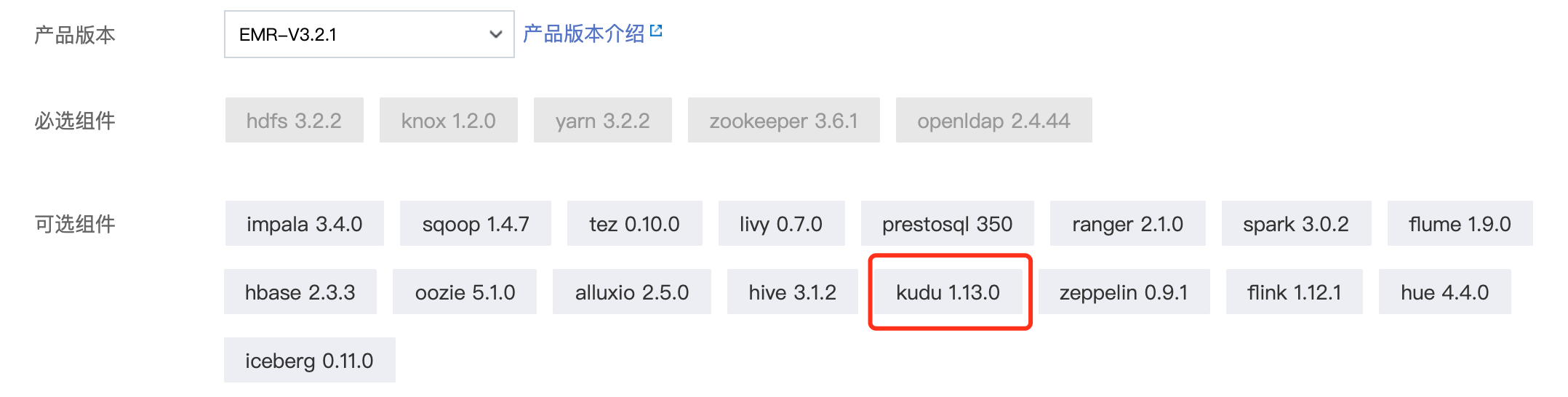
Configure Oracle environment
1. Install Oracle image
Download Docker:
Different CVM environments may be different. I use the offline installation mode here, Installation package official website address . After downloading the configuration, start and run the Docker service according to the following command.
# start-up systemctl start docker # Set startup systemctl enable docker.service # View docker service status systemctl status docker
Download Oracle image:
# Find Oracle mirror version docker search oracle # Download the corresponding image. Here we download truevoly/oracle-12c docker pull truevoly/oracle-12c # Run Docker container docker run -d -p 1521:1521 --name oracle12c truevoly/oracle-12c # Enter container docker exec -it oracle12c /bin/bash
2. Configure Oracle Database
Enable log archiving:
-- Re if necessary source once .profile file source /home/oracle/.profile -- 1. Switch to Oracle user su oracle -- 2. with DBA Identity connection database $ORACLE_HOME/bin/sqlplus /nolog conn /as sysdba show user -- 3. Enable log archiving alter system set db_recovery_file_dest_size = 10G; alter system set db_recovery_file_dest = '/opt/oracle/oradata/recovery_area' scope = spfile; shutdown immediate; startup mount; alter database archivelog; alter database open; -- 4. Check whether the log is archived archive log list;
be careful: 1. /opt/oracle/oradata/recovery_ The area path needs to be established in advance by the root user and given read-write permission: chmod 777 /opt/oracle/oradata/recovery_area. 2. To enable log archiving, restart the database. 3. Archiving logs will occupy a lot of disk space, and expired logs need to be cleaned regularly.
Create tablespace:
CREATE TABLESPACE logminer_tbs DATAFILE '/opt/oracle/oradata/SID/logminer_tbs.dbf' SIZE 25M REUSE AUTOEXTEND ON MAXSIZE UNLIMITED;
Note: the: / opt/oracle/oradata/SID path should be created in advance by the root user and given read-write permission: chmod 777 /opt/oracle/oradata/SID.
Create users and authorize:
CREATE USER flinkuser IDENTIFIED BY flinkpw DEFAULT TABLESPACE LOGMINER_TBS QUOTA UNLIMITED ON LOGMINER_TBS; GRANT CREATE SESSION TO flinkuser; GRANT SET CONTAINER TO flinkuser; GRANT SELECT ON V_$DATABASE to flinkuser; GRANT FLASHBACK ANY TABLE TO flinkuser; GRANT SELECT ANY TABLE TO flinkuser; GRANT SELECT_CATALOG_ROLE TO flinkuser; GRANT EXECUTE_CATALOG_ROLE TO flinkuser; GRANT SELECT ANY TRANSACTION TO flinkuser; GRANT LOGMINING TO flinkuser; GRANT CREATE TABLE TO flinkuser; GRANT LOCK ANY TABLE TO flinkuser; GRANT ALTER ANY TABLE TO flinkuser; GRANT CREATE SEQUENCE TO flinkuser; GRANT EXECUTE ON DBMS_LOGMNR TO flinkuser; GRANT EXECUTE ON DBMS_LOGMNR_D TO flinkuser; GRANT SELECT ON V_$LOG TO flinkuser; GRANT SELECT ON V_$LOG_HISTORY TO flinkuser; GRANT SELECT ON V_$LOGMNR_LOGS TO flinkuser; GRANT SELECT ON V_$LOGMNR_CONTENTS TO flinkuser; GRANT SELECT ON V_$LOGMNR_PARAMETERS TO flinkuser; GRANT SELECT ON V_$LOGFILE TO flinkuser; GRANT SELECT ON V_$ARCHIVED_LOG TO flinkuser; GRANT SELECT ON V_$ARCHIVE_DEST_STATUS TO flinkuser;
Data preparation:
-- establish Oracle Watch, for Source end
CREATE TABLE FLINKUSER.TEST1(
ID NUMBER(10,0) NOT NULL ENABLE,
NAME VARCHAR2(50),
PRIMARY KEY(ID)
) TABLESPACE LOGMINER_TBS;
-- Insert several pieces of data manually
INSERT INTO FLINKUSER.TEST1 (ID,NAME) VALUES (1,'1111');Start supplementary logging:
-- Configure database ALTER DATABASE ADD SUPPLEMENTAL LOG DATA; -- Configure tables ALTER TABLE FLINKUSER.TEST1 ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
Scheme realization
This scheme attempts the recently launched flick connector Oracle CDC function. Here, the author first uses Docker configuration to install Oracle 11g and Oracle 12c on the local machine to read and test the local Oracle table, and print out the read data after toRetractStream conversion. After summarizing and sorting out some problems found, I will share with you. Then select a CVM on the EMR cluster to configure the Oracle 12c environment, migrate the code to the Oceanus platform, and drop the final data to Kudu to realize a complete set of solutions for Oracle To Kudu.
Local code development
1. Maven dependence
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-oracle-cdc</artifactId>
<version>2.2-SNAPSHOT</version>
<!-- Dependency here needs to be set to scope,other flink Dependency needs to be set to provied,Oceanus Platform provided -->
<scope>compile</scope>
</dependency>2. Coding
package com.demo;
import com.ververica.cdc.connectors.oracle.OracleSource;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class OracleToKudu {
public static void main(String[] args) throws Exception {
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build();
StreamExecutionEnvironment sEnv = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(sEnv,settings);
// SQL writing method
tEnv.executeSql("CREATE TABLE `oracleSource` (\n" +
" ID BIGINT,\n" +
" NAME VARCHAR,\n" +
" PRIMARY KEY(ID) NOT ENFORCED )\n" +
" WITH (\n" +
" 'connector' = 'oracle-cdc',\n" +
// Please change it to the actual IP address of Oracle
" 'hostname' = 'xx.xx.xx.xx',\n" +
" 'port' = '1521',\n" +
" 'username' = 'flinkuser',\n" +
" 'password' = 'flinkpw',\n" +
" 'database-name' = 'xe',\n" +
" 'schema-name' = 'flinkuser',\n" +
" 'table-name' = 'test1'\n" +
")");
// Stream API writing
// SourceFunction<String> sourceFunction = OracleSource.<String>builder()
// .hostname("xx.xx.xx.xx")
// .port(1521)
// .database("xe")
// .schemaList("flinkuser")
// .tableList("flinkuser.test1")
// .username("flinkuser")
// .password("flinkpw")
// .deserializer(new JsonDebeziumDeserializationSchema())
// .build();
// sEnv.addSource(sourceFunction)
tEnv.executeSql("CREATE TABLE `kudu_sink_table` (\n" +
" `id` BIGINT,\n" +
" `name` VARCHAR\n" +
") WITH (\n" +
" 'connector.type' = 'kudu',\n" +
// Please change it to the actual master IP address
" 'kudu.masters' = 'master-01:7051,master-02:7051,master-03:7051',\n" +
" 'kudu.table' = 'JoylyuTest1',\n" +
" 'kudu.hash-columns' = 'id',\n" +
" 'kudu.primary-key-columns' = 'id'\n" +
")");
// The author has only simplified the data transfer function here. Please develop it according to the actual business situation
tEnv.executeSql("insert into kudu_sink_table select * from oracleSource");
}
}Stream calculation Oceanus JAR job
1. Upload dependency
On the Oceanus console, click dependency management on the left, click New in the upper left corner to create a dependency and upload the local Jar package.
2. Create job
On the Oceanus console, click [operation management] on the left, click [new] in the upper left corner to create a new operation, select Jar operation as the operation type, and click [development and debugging] to enter the operation editing page.
[main package] select the dependency just uploaded, select the latest version, and [main category] fill in com demos. OracleToKudu.
Click operation parameters, select flip Connector kudu in built-in Connector, and click save.
3. Operation
Click [publish draft] to run, and you can view the operation information through [log] panel TaskManager or Flink UI.
Data query
Select a CVM under the EMR cluster to enter and query the data written to kudu.
# Enter the kudu directory cd /usr/local/service/kudu/bin # View all tables of the cluster ./kudu table list master-01,master-02,master-03 # Query the data of JoylyuTest1 table ./kudu table scan master-01,master-02,master-03 JoylyuTest1
Of course, Kudu can also be integrated with Impala to query data through Impala, but it can only be queried by establishing an external table corresponding to Kudu table on Impala. For details, please refer to Summary ocean sink.
CREATE EXTERNAL TABLE ImpalaJoylyuTest1 STORED AS KUDU TBLPROPERTIES ( 'kudu.master_addresses' = 'master-01:7051,master-02:7051,master-03:7051', 'kudu.table_name' = 'JoylyuTest1' );
Problem sorting
The author found some problems when debugging two different Oracle versions: Oracle 11g and Oracle 12C. Here is a summary.
First, the case of table names
The author first tests Oracle 11g, runs it locally after the above steps are configured, and reports the following errors immediately after the data is printed:
Caused by: io.debezium.DebeziumException: Supplemental logging not configured for table HELOWIN.FLINKUSER.test1. Use command: ALTER TABLE FLINKUSER.test1 ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS at io.debezium.connector.oracle.logminer.LogMinerHelper.checkSupplementalLogging(LogMinerHelper.java:407) at io.debezium.connector.oracle.logminer.LogMinerStreamingChangeEventSource.execute(LogMinerStreamingChangeEventSource.java:132) ... 7 more
It can be found from the log information that the author's table TEST1 is automatically converted to a lowercase table TEST1. The error message appears in checksupplementary logging. Therefore, according to the error message, check the source code and find that all in Oracle will be checked here_ LOG_ The groups table is queried once, and the data cannot be queried, resulting in an error (the upper case table name TEST1 is stored in the ALL_LOG_GROUPS table).
static String tableSupplementalLoggingCheckQuery(TableId tableId) {
return String.format("SELECT 'KEY', LOG_GROUP_TYPE FROM %s WHERE OWNER = '%s' AND TABLE_NAME = '%s'", ALL_LOG_GROUPS, tableId.schema(), tableId.table());
}// The source code for converting the table name to lowercase is as follows
private TableId toLowerCaseIfNeeded(TableId tableId) {
return tableIdCaseInsensitive ? tableId.toLowercase() : tableId;
}At present, we can bypass this problem in three ways:
- Directly modify the source code and change the above tolower case to toUppercase.
- When creating an Oracle Source Table, add 'debezium. In the WITH parameter database. tablename. case. Configure insensitive '='false' to make it lose the "case insensitive" feature. You need to specify the upper case table name in table name.
- Switch to another Oracle version. The author uses Oracle 12c version here, which is normal.
Second: data update delay
When the author writes data to Oracle database manually and prints out the data on the IDEA console, it is found that when the data is appended, the data will have a delay of about 15s. When it is updated, the delay is greater. Sometimes it takes 3-5 minutes to capture the changes of the data. For this problem, the Flink CDC FAQ provides a clear solution. When creating an Oracle Source Table, add the following two configuration items to the WITH parameter:
'debezium.log.mining.strategy'='online_catalog', 'debezium.log.mining.continuous.mine'='true'
Third: parallelism setting
When I try to start data reading with parallelism of 2, I find that the error is as follows:
Exception in thread "main" java.lang.IllegalArgumentException: The parallelism of non parallel operator must be 1. at org.apache.flink.util.Preconditions.checkArgument(Preconditions.java:138) at org.apache.flink.api.common.operators.util.OperatorValidationUtils.validateParallelism(OperatorValidationUtils.java:35) at org.apache.flink.streaming.api.datastream.DataStreamSource.setParallelism(DataStreamSource.java:114) at com.demo.OracleToKudu.main(OracleToKudu.java:67)
Through stack information, it is found that the parallelism of Oracle CDC can only be set to 1, which is the same as Oracle CDC official documents agreement.
// Error code part
public static void validateParallelism(int parallelism, boolean canBeParallel) {
Preconditions.checkArgument(canBeParallel || parallelism == 1, "The parallelism of non parallel operator must be 1.");
Preconditions.checkArgument(parallelism > 0 || parallelism == -1, "The parallelism of an operator must be at least 1, or ExecutionConfig.PARALLELISM_DEFAULT (use system default).");
}