 Germeng Society
Germeng Society
AI: Keras PyTorch MXNet TensorFlow PaddlePaddle deep learning practice (updated from time to time)
4.4 real time log analysis
Learning objectives
- target
- Master the connection between Flume and Kafka
We have collected the log data into hadoop, but when doing real-time analysis, we need to collect the click behavior generated by users at each time into KAFKA, waiting for the spark streaming program to consume.
4.4.1 Flume collects logs to Kafka
- Objective: to collect local real-time log behavior data to kafka
- Step:
- 1. Turn on zookeeper and kafka tests
- 2. Create a flume configuration file and open flume
- 3. Open kafka for log writing test
- 4. Script adding and supervisor management
To enable zookeeper, you need to run it all the time on the server side in real time to run it as a daemons
/root/bigdata/kafka/bin/zookeeper-server-start.sh -daemon /root/bigdata/kafka/config/zookeeper.properties
And kafka test:
/root/bigdata/kafka/bin/kafka-server-start.sh /root/bigdata/kafka/config/server.properties
test
Open message producer /root/bigdata/kafka/bin/kafka-console-producer.sh --broker-list 192.168.19.137:9092 --sync --topic click-trace Open consumers /root/bigdata/kafka/bin/kafka-console-consumer.sh --bootstrap-server 192.168.19.137:9092 --topic click-trace
2. Modify the original log collection file and add flume to kafka's source, channel, sink
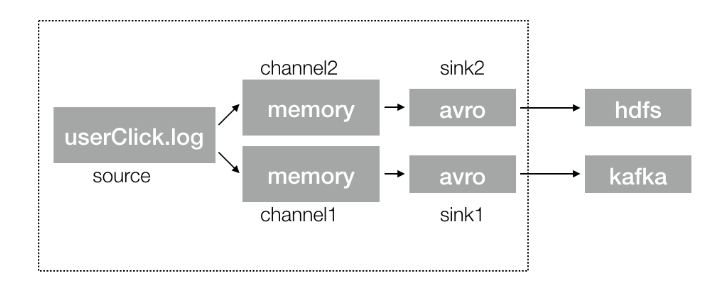
a1.sources = s1
a1.sinks = k1 k2
a1.channels = c1 c2
a1.sources.s1.channels= c1 c2
a1.sources.s1.type = exec
a1.sources.s1.command = tail -F /root/logs/userClick.log
a1.sources.s1.interceptors=i1 i2
a1.sources.s1.interceptors.i1.type=regex_filter
a1.sources.s1.interceptors.i1.regex=\\{.*\\}
a1.sources.s1.interceptors.i2.type=timestamp
# channel1
a1.channels.c1.type=memory
a1.channels.c1.capacity=30000
a1.channels.c1.transactionCapacity=1000
# channel2
a1.channels.c2.type=memory
a1.channels.c2.capacity=30000
a1.channels.c2.transactionCapacity=1000
# k1
a1.sinks.k1.type=hdfs
a1.sinks.k1.channel=c1
a1.sinks.k1.hdfs.path=hdfs://192.168.19.137:9000/user/hive/warehouse/profile.db/user_action/%Y-%m-%d
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.writeFormat=Text
a1.sinks.k1.hdfs.rollInterval=0
a1.sinks.k1.hdfs.rollSize=10240
a1.sinks.k1.hdfs.rollCount=0
a1.sinks.k1.hdfs.idleTimeout=60
# k2
a1.sinks.k2.channel=c2
a1.sinks.k2.type=org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k2.kafka.bootstrap.servers=192.168.19.137:9092
a1.sinks.k2.kafka.topic=click-trace
a1.sinks.k2.kafka.batchSize=20
a1.sinks.k2.kafka.producer.requiredAcks=1
Open the new configuration of flume for testing, and close the previous flume program before opening
supervisor> status collect-click RUNNING May 26 09:43 AM offline STOPPED May 27 06:03 AM supervisor>
- stop collect-click
#!/usr/bin/env bash export JAVA_HOME=/root/bigdata/jdk export HADOOP_HOME=/root/bigdata/hadoop export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin /root/bigdata/flume/bin/flume-ng agent -c /root/bigdata/flume/conf -f /root/bigdata/flume/conf/collect_click.conf -Dflume.root.logger=INFO,console -name a1
After adding, open flume
- start collect-click
3. Open kafka for log writing test
Open kafka script for testing. In order to ensure that zookeeper can be put into the script normally every time, close the previous zookeeper and add zookeeper to kafka's opening script
#!/usr/bin/env bash /root/bigdata/kafka/bin/zookeeper-server-start.sh -daemon /root/bigdata/kafka/config/zookeeper.properties /root/bigdata/kafka/bin/kafka-server-start.sh /root/bigdata/kafka/config/server.properties /root/bigdata/kafka/bin/kafka-topics.sh --zookeeper 192.168.19.137:2181 --create --replication-factor 1 --topic click-trace --partitions 1
4.4.2 super add script
[program:kafka] command=/bin/bash /root/toutiao_project/scripts/start_kafka.sh user=root autorestart=true redirect_stderr=true stdout_logfile=/root/logs/kafka.log loglevel=info stopsignal=KILL stopasgroup=true killasgroup=true
supervisor to update
4.4.3 testing
Open Kafka consumers
/root/bigdata/kafka/bin/kafka-console-consumer.sh --bootstrap-server 192.168.19.137:9092 --topic click-trace
Write one click data:
echo {\"actionTime\":\"2019-04-10 21:04:39\",\"readTime\":\"\",\"channelId\":18,\"param\":{\"action\": \"click\", \"userId\": \"2\", \"articleId\": \"14299\", \"algorithmCombine\": \"C2\"}} >> userClick.log
Observe consumer results
[root@hadoop-master ~]# /root/bigdata/kafka/bin/kafka-console-consumer.sh --bootstrap-server 192.168.19.137:9092 --topic click-trace
{"actionTime":"2019-04-10 21:04:39","readTime":"","channelId":18,"param":{"action": "click", "userId": "2", "art