1. Collaborative process is just an idea, and there is no participation at the operating system level, so it is all realized by the application developers of the three rings. There are various collaborative process frameworks on the market. Here, take the libco Library of wechat as an example to see how the collaborative process is implemented! Libco is a collaborative process library developed and used in the background of wechat, which claims to be able to schedule tens of millions of collaborative processes; In terms of use, libco not only provides a set of pthread like co process communication mechanism, but also can co process the blocked IO calls of the third-party library without modification; Before formally introducing the source code of libco, first intuitively feel the effect of libco. The demo code is as follows:
void A() { cout << 1 << " "; cout << 2 << " "; cout << 3 << " "; } void B() { cout << "x" << " "; cout << "y" << " "; cout << "z" << " "; } int main(void) { A(); B(); }
This code is very simple and can be understood by anyone who has just started programming. The results are as follows:
1 2 3 x y z
If libco's coprocessing api is used to switch between A and B functions (note that this is A simplified pseudo code to grasp the trunk and avoid being disturbed by trivial codes), it is as follows:
void A() { cout << 1 << " "; cout << 2 << " "; co_yield_ct(); // Cut out to main coordination process cout << 3 << " "; } void B() { cout << "x" << " "; co_yield_ct(); // Cut out to main coordination process cout << "y" << " "; cout << "z" << " "; } int main(void) { ... // Main coordination process co_resume(A); // Start collaboration A co_resume(B); // Start collaboration B co_resume(A); // Slave process A Continue at the cutout co_resume(B); // Slave process B Continue at the cutout }
The result then changes:
1 2 x 3 y z
You can see that the code switches back and forth between A and B functions, and the whole switching order depends entirely on co_yield_ct and co_resume two functions are artificially controlled! In this way, when A function is blocked, it can be manually switched to B function for execution; When the B function is blocked, switch to the A function to continue to execute without wasting A bit of CPU time!
2. When interpreting the linux source code before, when encountering some functions, we always look at the structure first, and then read the function function. The reason is very simple: important fields and data will be uniformly managed in the structure (in essence, they can be quickly addressed, which is conducive to reading and writing). All codes of the function are carried out around the reading and writing of these data in the structure! One of the important structures of libco is stCoRoutine_t (the structure is related to the executed function only when the name contains routine), which is defined as follows:
/*The structure of the function executed by the co process jump (i.e. yield and resume), It contains the three most important elements of collaborative process operation: Coprocessor running environment, entry of execution function and function parameters */ struct stCoRoutine_t { stCoRoutineEnv_t *env;//Collaborative operation environment pfn_co_routine_t pfn;// Function executed by coprocess jump void *arg;//Parameters of function coctx_t ctx;//Save the following environment of the cooperation process char cStart;//Whether the coordination process starts char cEnd;//Is the cooperation process over char cIsMain;//Currently main Function char cEnableSysHook; //Is the system running hook,Non intrusive logic char cIsShareStack;//Whether stacks are shared among multiple processes void *pvEnv; //char sRunStack[ 1024 * 128 ]; stStackMem_t* stack_mem;// Stack space of coroutine runtime //save stack buffer while confilct on same stack_buffer; char* stack_sp; unsigned int save_size; char* save_buffer; stCoSpec_t aSpec[1024]; };
See, this structure almost contains several important elements of the coprocessor: the scheduling environment of the coprocessor, the functions and parameters to be run by the coprocessor, and the context to be saved during coprocessor switching! The relationship between these structures is as follows: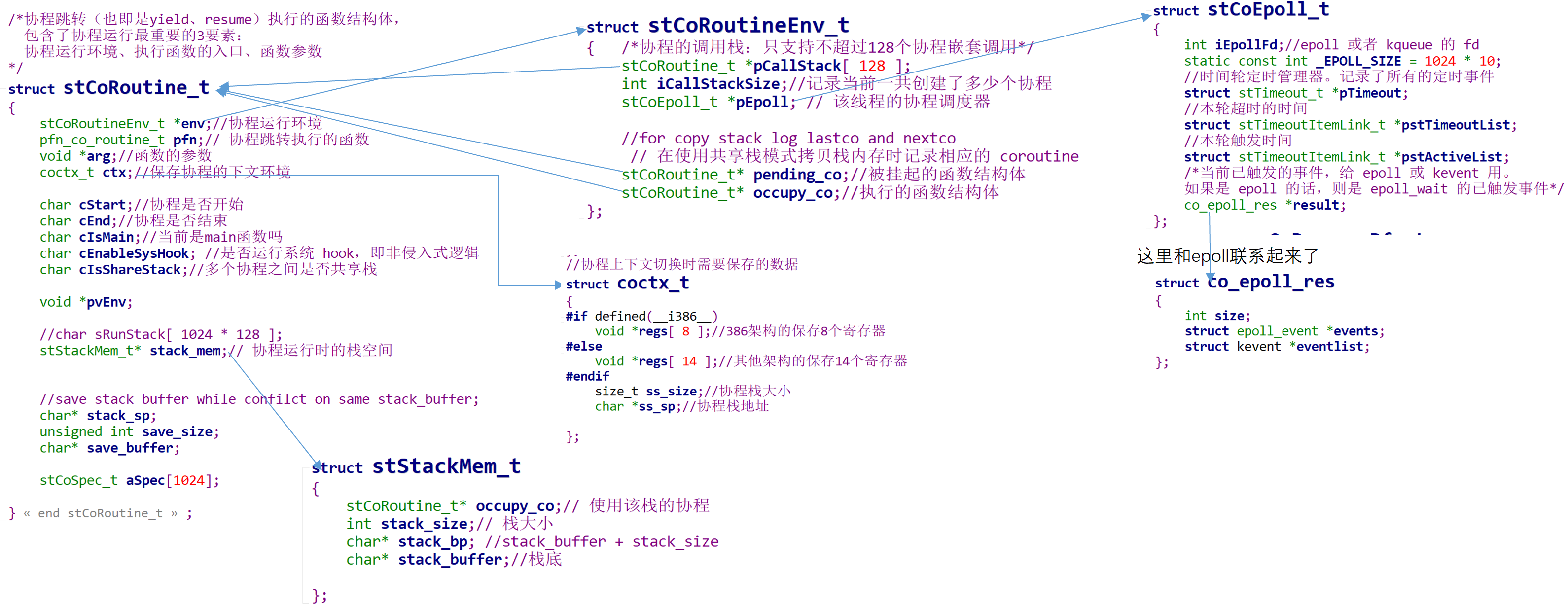
When the structure is available, the next step is to initialize the structure, and then Co_ create_ The core of Env function is to include the incoming function entry, parameters, env and other variables into stCoRoutine_t unified management, while initializing the stack and other variables!
/*Create collaboration env: The structure of the execution function of the coprocessor jump can also be understood as the environment of the function pfn: Function entry for CO process jump execution Initialize stCoRoutine_t *lp structure */ struct stCoRoutine_t *co_create_env( stCoRoutineEnv_t * env, const stCoRoutineAttr_t* attr, pfn_co_routine_t pfn,void *arg ) { stCoRoutineAttr_t at; if( attr ) { memcpy( &at,attr,sizeof(at) ); } if( at.stack_size <= 0 ) { at.stack_size = 128 * 1024;//Synergetic stack 128 k } else if( at.stack_size > 1024 * 1024 * 8 )//No more than 8 M { at.stack_size = 1024 * 1024 * 8; } if( at.stack_size & 0xFFF ) { at.stack_size &= ~0xFFF;//Low stack size 12 bit Clear, that is, page alignment at.stack_size += 0x1000; } stCoRoutine_t *lp = (stCoRoutine_t*)malloc( sizeof(stCoRoutine_t) ); memset( lp,0,(long)(sizeof(stCoRoutine_t))); /*stCoRoutine_t It contains the three most important elements of collaborative process operation: environment, function entry and parameters*/ lp->env = env; lp->pfn = pfn; lp->arg = arg; stStackMem_t* stack_mem = NULL; if( at.share_stack )//If shared memory is used { stack_mem = co_get_stackmem( at.share_stack); at.stack_size = at.share_stack->stack_size; } else//Otherwise, reassign the process stack { stack_mem = co_alloc_stackmem(at.stack_size); } lp->stack_mem = stack_mem; lp->ctx.ss_sp = stack_mem->stack_buffer; lp->ctx.ss_size = at.stack_size; lp->cStart = 0; lp->cEnd = 0; lp->cIsMain = 0; lp->cEnableSysHook = 0; lp->cIsShareStack = at.share_stack != NULL; lp->save_size = 0; lp->save_buffer = NULL; return lp; }
It should be used after the initialization of the collaboration structure is completed. Remember the demo case at the beginning of the article? Co directly called in main_ Resume function, as follows:
void co_resume( stCoRoutine_t *co ) { stCoRoutineEnv_t *env = co->env; // Gets the structure of the currently running collaboration // Every time a new process is generated, it is put into the array management stCoRoutine_t *lpCurrRoutine = env->pCallStack[ env->iCallStackSize - 1 ]; if( !co->cStart ) { // For the to be run co Layout context: initialize the stack of the coroutine, and put the function parameters and return address on the stack coctx_make( &co->ctx,(coctx_pfn_t)CoRoutineFunc,co,0 ); co->cStart = 1; } //The coroutines to be recovered are added to the array, indicating that they are running env->pCallStack[ env->iCallStackSize++ ] = co; co_swap( lpCurrRoutine, co ); }
The only parameter is the co process structure; The previous work is all kinds of preparatory work, and the key is the last one_ Swap function. From the name and parameters, we can know that the co process structures (essentially functions) switch with each other!
void co_swap(stCoRoutine_t* curr, stCoRoutine_t* pending_co) { stCoRoutineEnv_t* env = co_get_curr_thread_env(); //get curr stack sp char c; /*Record the position of the curr collaboration stack, which can be used to recover the stack content when switching back to curr later*/ curr->stack_sp= &c; if (!pending_co->cIsShareStack) { env->pending_co = NULL; env->occupy_co = NULL; } else //Shared stack mode { env->pending_co = pending_co; //get last occupy co on the same stack mem //Fetch the existing coroutines in the shared stack stCoRoutine_t* occupy_co = pending_co->stack_mem->occupy_co; //set pending co to occupy thest stack mem; //Record the pending coroutines in the shared stack pending_co->stack_mem->occupy_co = pending_co; /*env Record the pending and occupancy processes so that they can still be found after switching*/ env->occupy_co = occupy_co; if (occupy_co && occupy_co != pending_co) { /*Save the process in another place*/ save_stack_buffer(occupy_co); } } //swap context /*The core functions of coprocess switching: switching general registers, esp+ebp, eip;*/ coctx_swap(&(curr->ctx),&(pending_co->ctx) ); //stack buffer may be overwrite, so get again; stCoRoutineEnv_t* curr_env = co_get_curr_thread_env(); stCoRoutine_t* update_occupy_co = curr_env->occupy_co; stCoRoutine_t* update_pending_co = curr_env->pending_co; if (update_occupy_co && update_pending_co && update_occupy_co != update_pending_co) { //resume stack buffer if (update_pending_co->save_buffer && update_pending_co->save_size > 0) { memcpy(update_pending_co->stack_sp, update_pending_co->save_buffer, update_pending_co->save_size); } } }
co_ The core of swap is coctx_swap, because it involves register operation, C language can't do anything. Here, assembly is used to do it simply and roughly: first push the context of curr to the stack of curr, then switch rsp to the pending stack through movq% RSI,% rsp, and finally assign the pending context to the register through a series of pop, and the last ret assigns the address at the top of the stack to eip, This completes the switch!
.globl coctx_swap .type coctx_swap, @function coctx_swap: leaq 8(%rsp),%rax # rax=(*rsp) + 8; # At this time, the top element of the stack is the current% Rip (that is, the next instruction to be executed when the current collaboration is suspended and waked up again) # The address at the top of the stack will be saved to the address after cur - >[9]So save rsp of # It's time to skip these 8 bytes leaq 112(%rdi),%rsp#rsp=(*rdi) + (8*14); # %rdi stores the address of the first parameter of the function, that is, the address of curr - > CTX # Then add the length of 14 registers to be saved to make rsp point to curr - > CTX - > regs[13] pushq %rax # curr->ctx->regs[13] = rax; # Save rsp and look at the comments in the first line of code pushq %rbx # curr->ctx->regs[12] = rbx; pushq %rcx # curr->ctx->regs[11] = rcx; pushq %rdx # curr->ctx->regs[10] = rcx; pushq -8(%rax) # curr->ctx->regs[9] = (*rax) - 8; # Save the address of the next instruction to be executed when the process is suspended and waked up again pushq %rsi # curr->ctx->regs[8] = rsi; pushq %rdi # curr->ctx->regs[7] = rdi; pushq %rbp # curr->ctx->regs[6] = rbp; pushq %r8 # curr->ctx->regs[5] = r8; pushq %r9 # curr->ctx->regs[4] = r9; pushq %r12 # curr->ctx->regs[3] = r12; pushq %r13 # curr->ctx->regs[2] = r13; pushq %r14 # curr->ctx->regs[1] = r14; pushq %r15 # curr->ctx->regs[0] = r15; movq %rsi, %rsp # rsp = rsi; # rsi stores the address of the second parameter of the function, even if rsp points to pending_ co->ctx->regs[0] popq %r15 # r15 = pending_co->ctx->regs[0]; popq %r14 # r14 = pending_co->ctx->regs[1]; popq %r13 # r13 = pending_co->ctx->regs[2]; popq %r12 # r12 = pending_co->ctx->regs[3]; popq %r9 # r9 = pending_co->ctx->regs[4]; popq %r8 # r8 = pending_co->ctx->regs[5]; popq %rbp # rbp = pending_co->ctx->regs[6]; popq %rdi # rdi = pending_co->ctx->regs[7]; popq %rsi # rsi = pending_co->ctx->regs[8]; popq %rax # rax = pending_co->ctx->regs[9]; # Compared with the front, CTX - > regs[9]Stored in is the address of the next instruction to be executed after the coprocessor is awakened popq %rdx # rdx = pending_co->ctx->regs[10]; popq %rcx # rcx = pending_co->ctx->regs[11]; popq %rbx # rbx = pending_co->ctx->regs[12]; popq %rsp # rsp = pending_co->ctx->regs[13]; rsp += 8; # This code is the key to understanding the whole process. And coctx_ When saving rsp in make function, subtract 8 and save the corresponding. pushq %rax # rsp -= 8;*rsp = rax; # At this time, the top element of the stack is the address of the next instruction to be executed after the coroutine is awakened xorl %eax, %eax # eax = 0; # Clear eax, and the content in eax is used as the return value of the function ret # This is equivalent to POPQ% rip, which can wake up the last suspended collaboration and then run
Since then, call resume to complete the switching of function execution! Resume's code analysis is finished, and it's another yield! In fact, the core functions of these two functions are switching functions, so the bottom layer calls co_swap, as follows:
void co_yield_env( stCoRoutineEnv_t *env ) { //Take out two coprocedures from the array for exchange stCoRoutine_t *last = env->pCallStack[ env->iCallStackSize - 2 ]; stCoRoutine_t *curr = env->pCallStack[ env->iCallStackSize - 1 ]; env->iCallStackSize--; co_swap( curr, last); }
See, is the code super simple?
3. The above code perfectly completes the switching between different codes within a thread, but the switching time is controlled manually. If it is network IO? Developers cannot accurately predict the timing of sending and receiving data, so there is no legal person to make collaborative process switching for accurate "buried point" resume and yield. How should this business scenario be handled? Previously, epoll was used to monitor whether an event arrives in the socket. How can epoll be reused here? In Example_ echosrv. In the C file, wechat officially provides the use cases of the service side collaboration process. There is not much code, but it involves the back and forth switching between multiple methods such as main, readwrite and accept, and there is a for loop inside the method. The whole process is complex. I drew a simple sketch, as follows:
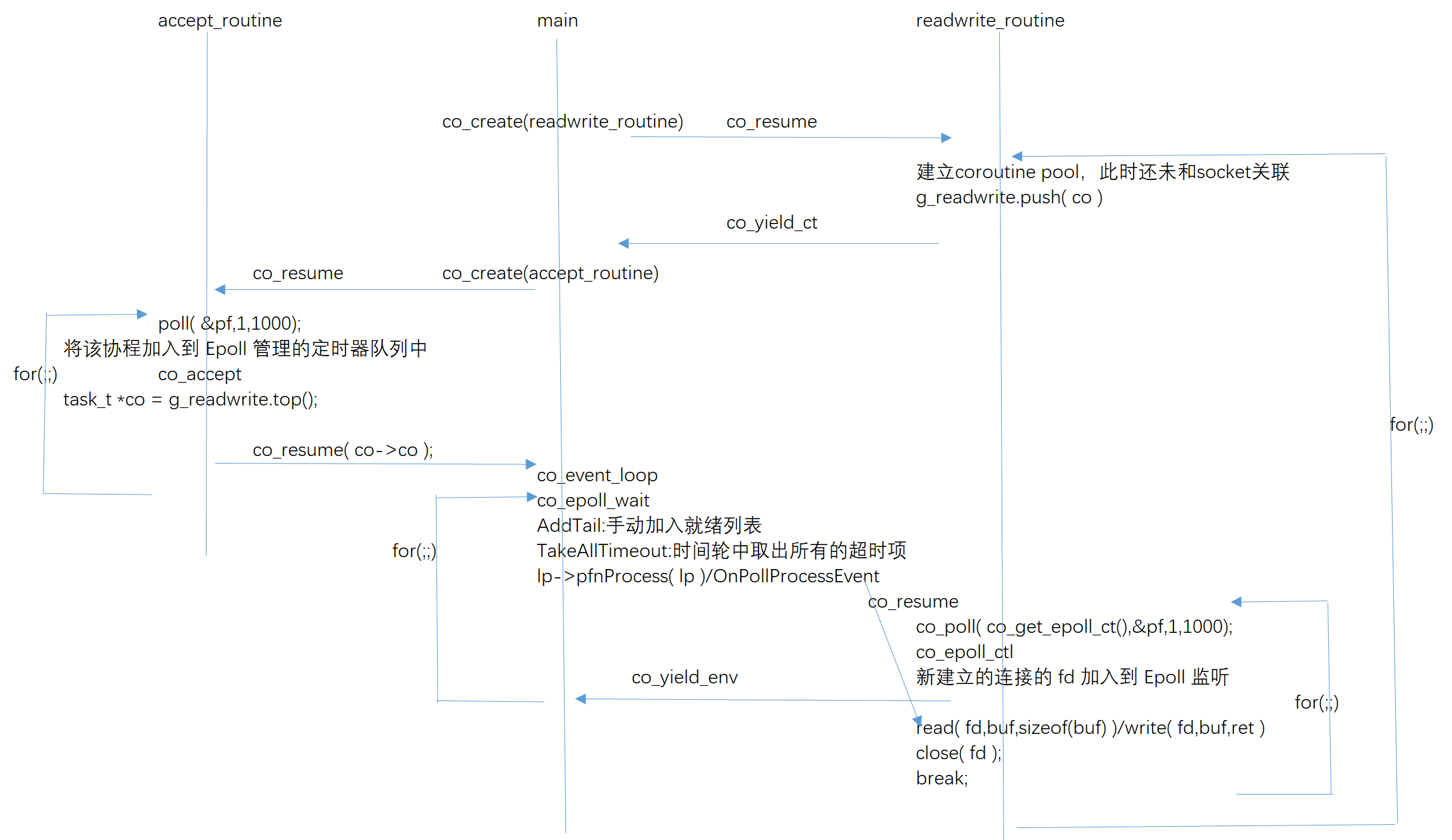
It can be seen that there is only one thread in the whole process; There is an accept that is specifically responsible for accepting client connections_ Co processes, mian main processes that listen to events, and readwrite processes that add events and are responsible for reading and writing_ so! epoll is also used for event monitoring and triggering of network io. Then, it leads to the appropriate co process to handle these IO events through yield and resume switching! The whole process is not difficult in logic, but very complicated. You need to calm down and smooth it slowly! In order to realize the whole process, several key functions need to be highlighted.
(1) libco implements a timeout manager based on timing wheel for events that require timeout management of condition variables for unified network IO; The time wheel is a dark red wheel array in the figure. Each unit of the array is called a slot. A list of events registered within a certain period of time is stored in a single slot (yellow linked list in the figure). The time of a single slot is 60 milliseconds, and the time of the whole slot is 60 milliseconds;

In order to realize the time wheel, the two core methods are as follows:
/* Insert new item in time wheel * @param * apTimeout :Time wheel structure * apItem :New timeout entry * allNow :Current event (timestamp in ms) * @return :0 Number of successful and else failed rows */ int AddTimeout( stTimeout_t *apTimeout,stTimeoutItem_t *apItem ,unsigned long long allNow ) { if( apTimeout->ullStart == 0 ) { apTimeout->ullStart = allNow;// Set the earliest time of the time wheel to the current time apTimeout->llStartIdx = 0; } /* Error returned when the current time is less than the initial time */ if( allNow < apTimeout->ullStart ) { co_log_err("CO_ERR: AddTimeout line %d allNow %llu apTimeout->ullStart %llu", __LINE__,allNow,apTimeout->ullStart); return __LINE__; } /* Error returned when the current time is greater than the timeout */ if( apItem->ullExpireTime < allNow ) { co_log_err("CO_ERR: AddTimeout line %d apItem->ullExpireTime %llu allNow %llu apTimeout->ullStart %llu", __LINE__,apItem->ullExpireTime,allNow,apTimeout->ullStart); return __LINE__; } // Calculate timeout unsigned long long diff = apItem->ullExpireTime - apTimeout->ullStart; /* The timeout time is greater than the maximum time of the time round. An error is returned */ if( diff >= (unsigned long long)apTimeout->iItemSize ) { diff = apTimeout->iItemSize - 1; co_log_err("CO_ERR: AddTimeout line %d diff %d", __LINE__,diff); //return __LINE__; } /* Add time to the time wheel */ AddTail( apTimeout->pItems + ( apTimeout->llStartIdx + diff ) % apTimeout->iItemSize , apItem ); return 0; } /* Take out all timeout items in the time wheel * @param * apTimeout:Time wheel structure * allNow :Current time (timestamp in ms) * apResult :Linked list of timeout event results */ inline void TakeAllTimeout( stTimeout_t *apTimeout,unsigned long long allNow,stTimeoutItemLink_t *apResult ) { if( apTimeout->ullStart == 0 ) { apTimeout->ullStart = allNow; apTimeout->llStartIdx = 0; } if( allNow < apTimeout->ullStart ) { return ; } int cnt = allNow - apTimeout->ullStart + 1; if( cnt > apTimeout->iItemSize ) { cnt = apTimeout->iItemSize; } if( cnt < 0 ) { return; } for( int i = 0;i<cnt;i++) { int idx = ( apTimeout->llStartIdx + i) % apTimeout->iItemSize; Join<stTimeoutItem_t,stTimeoutItemLink_t>( apResult,apTimeout->pItems + idx ); } apTimeout->ullStart = allNow; apTimeout->llStartIdx += cnt - 1; }
(2) the method that each main function needs to call is used to constantly monitor whether an event occurs, as follows:
/* Event loop: constantly monitor whether an event occurs * @param * ctx:epoll handle * pfn:Exit event loop check function * arg:pfn parameter */ void co_eventloop( stCoEpoll_t *ctx,pfn_co_eventloop_t pfn,void *arg ) { if( !ctx->result ) { ctx->result = co_epoll_res_alloc( stCoEpoll_t::_EPOLL_SIZE ); } co_epoll_res *result = ctx->result; for(;;) { int ret = co_epoll_wait( ctx->iEpollFd,result,stCoEpoll_t::_EPOLL_SIZE, 1 ); stTimeoutItemLink_t *active = (ctx->pstActiveList); stTimeoutItemLink_t *timeout = (ctx->pstTimeoutList); memset( timeout,0,sizeof(stTimeoutItemLink_t) ); //Empty timeout queue for(int i=0;i<ret;i++)//Traversing with events fd { //obtain event Where the data points stTimeoutItem_t stTimeoutItem_t *item = (stTimeoutItem_t*)result->events[i].data.ptr; if( item->pfnPrepare )//If there is a preprocessing function, execute it and add it to the ready list { item->pfnPrepare( item,result->events[i],active ); } else//Manually join the ready list { AddTail( active,item ); } } unsigned long long now = GetTickMS(); /*Take out all timeout items from the time wheel and insert them into the timeout list*/ TakeAllTimeout( ctx->pTimeout,now,timeout ); stTimeoutItem_t *lp = timeout->head; while( lp ) { //printf("raise timeout %p\n",lp); lp->bTimeout = true;//Set to timeout lp = lp->pNext; } //Merge timeout list into ready list Join<stTimeoutItem_t,stTimeoutItemLink_t>( active,timeout ); lp = active->head; while( lp ) { PopHead<stTimeoutItem_t,stTimeoutItemLink_t>( active ); if (lp->bTimeout && now < lp->ullExpireTime) { //If the timeout period has not been reached but has been marked as timeout, the time wheel will be added back int ret = AddTimeout(ctx->pTimeout, lp, now); if (!ret) { lp->bTimeout = false; lp = active->head; continue; } } /*Call sttimeoutitem_ The execution function of item T, that is, OnPollProcessEvent There's Co in it_ resume*/ if( lp->pfnProcess ) { lp->pfnProcess( lp ); } lp = active->head; } if( pfn )//Used for user control to jump out of the event loop { if( -1 == pfn( arg ) ) { break; } } } }
(3) hand over fd to Epoll for management. When the corresponding event of Epoll is triggered, switch back to read or write operation, so as to realize the coordination process managed by Epoll, as follows:
/* poll Kernel: the fd is managed by Epoll. When the corresponding event of Epoll is triggered, Then switch back to read or write, So as to realize the function that Epoll manages the cooperation process * @param * ctx:epoll handle * fds:fd array * nfds:fd Array length * timeout:Timeout ms * pollfunc:Default poll */ typedef int (*poll_pfn_t)(struct pollfd fds[], nfds_t nfds, int timeout); int co_poll_inner( stCoEpoll_t *ctx,struct pollfd fds[], nfds_t nfds, int timeout, poll_pfn_t pollfunc) { if (timeout == 0) { //Call system native poll(In fact, the upper layer poll It has been checked. There is no need to do it here) return pollfunc(fds, nfds, timeout); } if (timeout < 0) { timeout = INT_MAX; } int epfd = ctx->iEpollFd; stCoRoutine_t* self = co_self(); //1.struct change /* 1. Initialize poll related data structures */ stPoll_t& arg = *((stPoll_t*)malloc(sizeof(stPoll_t))); memset( &arg,0,sizeof(arg) ); arg.iEpollFd = epfd; arg.fds = (pollfd*)calloc(nfds, sizeof(pollfd));//distribution nfds individual pollfd arg.nfds = nfds; stPollItem_t arr[2]; //nfds Less than 2 and without using the shared stack if( nfds < sizeof(arr) / sizeof(arr[0]) && !self->cIsShareStack) { // Allocation in stack arg.pPollItems = arr; } else { arg.pPollItems = (stPollItem_t*)malloc( nfds * sizeof( stPollItem_t ) ); } memset( arg.pPollItems,0,nfds * sizeof(stPollItem_t) ); //call co_resume(arg.pArg), Wake up parameters arg.pArg Referred process arg.pfnProcess = OnPollProcessEvent; arg.pArg = GetCurrCo( co_get_curr_thread_env() );//Get the current running collaboration //2. add epoll Add events to epoll Medium monitoring for(nfds_t i=0;i<nfds;i++) { arg.pPollItems[i].pSelf = arg.fds + i; arg.pPollItems[i].pPoll = &arg; arg.pPollItems[i].pfnPrepare = OnPollPreparePfn;// Callback preprocessing function struct epoll_event &ev = arg.pPollItems[i].stEvent; if( fds[i].fd > -1 ) { ev.data.ptr = arg.pPollItems + i; ev.events = PollEvent2Epoll( fds[i].events ); int ret = co_epoll_ctl( epfd,EPOLL_CTL_ADD, fds[i].fd, &ev ); //Event join epoll Monitoring of if (ret < 0 && errno == EPERM && nfds == 1 && pollfunc != NULL) { if( arg.pPollItems != arr ) { free( arg.pPollItems ); arg.pPollItems = NULL; } free(arg.fds); free(&arg); return pollfunc(fds, nfds, timeout); } } //if fail,the timeout would work } //3.add timeout Add timeout to time wheel unsigned long long now = GetTickMS(); arg.ullExpireTime = now + timeout; int ret = AddTimeout( ctx->pTimeout,&arg,now ); int iRaiseCnt = 0; if( ret != 0 ) { co_log_err("CO_ERR: AddTimeout ret %d now %lld timeout %d arg.ullExpireTime %lld", ret,now,timeout,arg.ullExpireTime); errno = EINVAL; iRaiseCnt = -1; } else { // Give the execution right to the coprocessor calling this coprocessor, that is main thread co_yield_env( co_get_curr_thread_env() ); iRaiseCnt = arg.iRaiseCnt; } /*When the event loop of main coroutine Co_ When the corresponding listening event is triggered in EventLoop, execution will resume At this point, the execution of the second half will begin, that is, the handle fds added in the first half will be removed from epoll, Clean up residual data structures*/ { //clear epoll status and memory // Delete the item from the time wheel RemoveFromLink<stTimeoutItem_t,stTimeoutItemLink_t>( &arg ); for(nfds_t i = 0;i < nfds;i++) { int fd = fds[i].fd; if( fd > -1 ) { co_epoll_ctl( epfd,EPOLL_CTL_DEL,fd,&arg.pPollItems[i].stEvent ); } fds[i].revents = arg.fds[i].revents; } if( arg.pPollItems != arr ) { free( arg.pPollItems ); arg.pPollItems = NULL; } free(arg.fds); free(&arg); } return iRaiseCnt; }
Summary:
1. Co process: switching between different methods, from the assembly level, is jmp to different code execution
reference resources:
1, https://www.cyhone.com/articles/analysis-of-libco/ Analysis of source code of wechat libco collaborative Library
2, https://github.com/tencent/libco Libco source code
3, https://www.infoq.cn/article/CplusStyleCorourtine-At-Wechat C/C + + collaboration library libco: how to beautifully complete the asynchronous transformation of wechat
4, https://zhuanlan.zhihu.com/p/27409164 Context switching principle of libco collaboration
5,https://cloud.tencent.com/developer/article/1459729 Design and implementation of libco
6,https://nifengz.com/libco_context_swap/
7, http://kaiyuan.me/2017/07/10/libco/ Libco analysis
8, https://www.changliu.me/post/libco-auto/ Automatic switching
9, https://blog.csdn.net/MOU_IT/article/details/115033799 Event registration poll
10, http://kaiyuan.me/2017/10/20/libco2/ Management of collaborative process