This article is shared from Huawei cloud community< Introduction to novice pronunciation (I): recognize word error rate WER and word error rate CER | editing distance | levinstein distance | dynamic programming >, author: Yellow spicy chicken.
1. Concept of word / word error rate
1.1 word error rate and word error rate
Word error rate (WER) is an important index used to evaluate the performance of ASR. It is used to evaluate the error rate between predicted text and standard text. Therefore, the smaller the word error rate, the better. For example, in English, Arabic speech to text or speech recognition tasks, researchers often use wer to measure the effect of ASR.
Because the smallest unit of a sentence in an English sentence is a word, and the smallest unit in a Chinese sentence is a Chinese character, character error rate (CER) is used to measure the effect of Chinese ASR in Chinese speech to text task or Chinese speech recognition task.
The calculation method of the two is the same, and the wording is unified. Hereinafter, we is used to represent the performance.
1.2 calculation formula
Their calculation formula is:
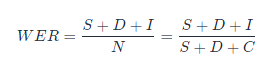
Suppose there is a reference example sentence Ref and a predicted text Hyp generated by ASR system after transcribing speech. In the above formula, s represents the replacement quantity when converting Hyp to Ref, D represents the replacement quantity when converting Hyp to Ref, I represents the insertion quantity when converting Hypo to Ref, and N represents the total number of words or English words in Ref sentences. C stands for the correct number of words recognized in Hyp sentences. That is, the total number of words in the original reference sentence N = S+ D + C.
Again, according to Wikipedia, N is the total number of words in the original text.
Example 1:
Ref: Have you eaten? Hyp: Have you eaten yet?
The standard text is "did you eat", and the transfer result is "did you eat". In the above example, there is an error replacement. Hyp replaces "did" with "did", that is, S=1,D=0, I =0, and the number of words in the reference text is N=4. Therefore, the transfer result is WER= 1/4 = 25%
Example 2:
Ref: Have you eaten? Hyp: Did you eat
The predicted text is "you ate". Compared with the standard text, one "yes" is deleted incorrectly, that is, S=0,D=1,I=0,N=4. Therefore, the result of this transfer is WER = 1/4 = 25%.
Example 3:
Ref: the weather is nice today Hyp: It's a fine day today
In example 3, the Hyp text inserts an "ah" error compared with the standard text, that is, S=0, D=0, I =1, N=6, so the word error rate WER= 1/6 = 16.7%.
2. Realization of word error rate
When the reference text is given, N can be easily counted, and the editing quantity S+I+DS+I+D is calculated through the introduction of editing distance.
2.1 concept of editing distance
Editing distance, proposed by the former Soviet mathematician Vladimir lewinstein in 1965, describes the difference between two strings by calculating the minimum editing number required for the mutual conversion of two strings. Editing operations include replacement, deletion and insertion. Editing distance, also known as Lewinsky distance, is widely used in the fields of word error rate calculation, DNA sequence alignment, spelling detection and so on.
The editing distance is equivalent to S+D+IS+D+I described above.
The formula for editing the distance is:
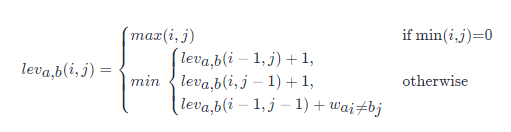
Where ww is the indicator function, and its value is 1 when ai ≠ bj; When ai = aj , its value is 0.
As a novice, looking directly at this formula may not be clear, so. However, if you can use a matrix to represent this formula and deduce it on paper, it will be relatively easy to understand when you look back. Refer to example 2.2.
2.2 calculation of editing distance
Suppose we have two words, horse and ros, and we need to calculate the editing distance between them. Let's assume that horse is the reference example sentence Ref and ros is the predicted text Hyp. Now calculate the minimum operands required to convert ros to horse, that is, the editing distance between them.
Refer to Leetcode questions #71We first define a distance matrix and name it cache. The number of rows of the matrix is ros character length + 1, and the number of columns of the matrix is horse character length + 1, so the cache is a 4 ✖️ 6 matrix. In the following, i is used to represent the number of rows and j is used to represent the number of columns.
The matrix looks like this:
+------+------+---+---+---+---+---+ | | null | h | o | r | s | e | +------+------+---+---+---+---+---+ | null | | | | | | | | r | | | | | | | | o | | | | | | | | s | | | | | | | +------+------+---+---+---+---+---+
The extra row and column are given null. Each element in the matrix will save the operands required for the conversion of characters to each other before the current position. For example, cache[2][3] indicates the minimum number of operands required to convert ro to hor.
If you can get the value of the matrix element in the bottom right corner, you can get the number of edits required for the conversion between ros and horse.
Because we can easily calculate the operands required to convert null to null or null to any character. For example, the operands from null to null are 0, that is, cache[0][0]=0; The operand from null to h is 1, that is, cache[0][1]=1, and the operand from null to ho is 2, that is, cache[0][2]=2. The operands from null to hor, hors and horse are 3, 4 and 5 respectively.
Therefore, the distance matrix can be obtained:
+------+------+---+---+---+---+---+ | | null | h | o | r | s | e | +------+------+---+---+---+---+---+ | null | 0 | 1 | 2 | 3 | 4 | 5 | ➡️ | r | | | | | | | | o | | | | | | | | s | | | | | | | +------+------+---+---+---+---+---+
At the same time, a mode can be found. When i=0, cache[i][j] = j,
Similarly, the operands that convert the vertical columns r, ro and ros to null are 1, 2 and 3 respectively, that is, 1, 2 and 3 characters are deleted respectively.
The following distance matrix is obtained:
+------+------+---+---+---+---+---+
| | null | h | o | r | s | e |
+------+------+---+---+---+---+---+
| null | 0 | 1 | 2 | 3 | 4 | 5 |
| r | 1 | | | | | |
| o | 2 | | | | | |
| s | 3 | | | | | |
+------+------+---+---+---+---+---+
⬇️It is found that when j=0, cache[i][j] = i.
To calculate the remaining part of the distance matrix, we first define two matrix rules,
When r \neq cr = c, the matrix value in the lower right corner is the minimum value of the surrounding three values + 1:
+---------+----------------------------------+ | replace | remove | +---------+----------------------------------+ | insert | min(replace, remove, insert) + 1 | +---------+----------------------------------+
When r = cr=c, the matrix value in the lower right corner is the value of the diagonal matrix in the upper left corner.
+---+------------------------------+ |↘️ | | +---+------------------------------+ | | just copy the diagonal value | +---+------------------------------+
For the first element in the upper left corner that is not filled, r needs to be converted to h. according to the first case above, the minimum value of the three surrounding values + 1, that is, 0 + 1 = 1. Therefore, the distance matrix is shown in the following figure:
+------+------+---+---+---+---+---+ | | null | h | o | r | s | e | +------+------+---+---+---+---+---+ | null | 0 | 1 | 2 | 3 | 4 | 5 | | r | 1 | 1 | | | | | | o | 2 | | | | | | | s | 3 | | | | | | +------+------+---+---+---+---+---+
According to the above two rules, we can fill the distance matrix:
+------+------+---+---+---+---+---+ | | null | h | o | r | s | e | +------+------+---+---+---+---+---+ | null | 0 | 1 | 2 | 3 | 4 | 5 | | r | 1 | 1 | 2 | 2 | 3 | 4 | | o | 2 | 2 | 1 | 2 | 3 | 4 | | s | 3 | 2 | 2 | 2 | 2 | 3 | +------+------+---+---+---+---+---+
Get the value in the lower right corner, that is, the minimum number of edits converted from ros to horse, that is, the editing distance between ros and horse is 3.
At this time, we can describe the above two rules in formula language:
When r \neq cr = c, the matrix value in the lower right corner is the minimum value of the surrounding three values + 1:
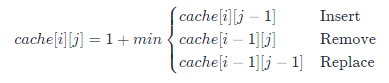
When r = cr=c, the matrix value in the lower right corner is the value of the diagonal matrix in the upper left corner:

Now we can combine the above calculation processes:

It is not difficult to find that this formula is lewinstein formula, and it is also a state equation for calculating editing distance by dynamic programming method.
Implemented using Python code:
def min_distance(word1: str, word2: str) -> int:
row = len(word1) + 1
column = len(word2) + 1
cache = [ [0]*column for i in range(row) ]
for i in range(row):
for j in range(column):
if i ==0 and j ==0:
cache[i][j] = 0
elif i == 0 and j!=0:
cache[i][j] = j
elif j == 0 and i!=0:
cache[i][j] = i
else:
if word1[i-1] == word2[j-1]:
cache[i][j] = cache[i-1][j-1]
else:
replace = cache[i-1][j-1] + 1
insert = cache[i][j-1] + 1
remove = cache[i-1][j] + 1
cache[i][j] = min(replace, insert, remove)
return cache[row-1][column-1]
if __name__ == "__main__":
min_distance("ros", "horse")If you replace the above characters with Chinese characters or words, and then calculate the value of S+D+IS+D+I in two sentences, it is easy to calculate WER.
reference resources
- Wikipedia: Word Error Rate
- Minimum Edit distance (Dynamic Programming) for converting one string to another string
- Leetcode: 72. Edit Distance
- Multiple lines one side of equation with a Curly Bracket
Click focus to learn about Huawei cloud's new technologies for the first time~