background
There is a service in the company project, which is similar to a crawler. It needs to parse the given URL and extract the page title, cover image, summary, icon and other information from the returned HTML. Because this is a pure memory service without DB access, and the downstream service (URL address to be resolved) is not an internal service, there is no need to consider the concurrency pressure. When building the service, WebFlux is selected as the web layer framework, and spring's WebClient is selected as the HTTP client requesting downstream services.
The service is deployed in the k8s container. The JDK version is OpenJDK11, the Pod is configured with 4C4G, and the Java service is configured with a maximum heap memory of 2G.
Problem description
After the service goes online, there is little pressure on the request, but after a long time of operation, the memory occupation of the service heap reaches 99%. A large number of OOM errors appear in log monitoring, and then the container Pod is restarted. It can work normally for a period of time after restart, and then the heap memory occupies 99% again, resulting in OOM error.
Solving process
preliminary analysis
Through container monitoring, check the machine memory occupation diagram for a period of time before Pod restart. It is found that the diagram shows a continuous upward trend, and the Pod restarts after reaching the upper limit of heap memory allocation. Preliminary speculation is that a memory leak has occurred.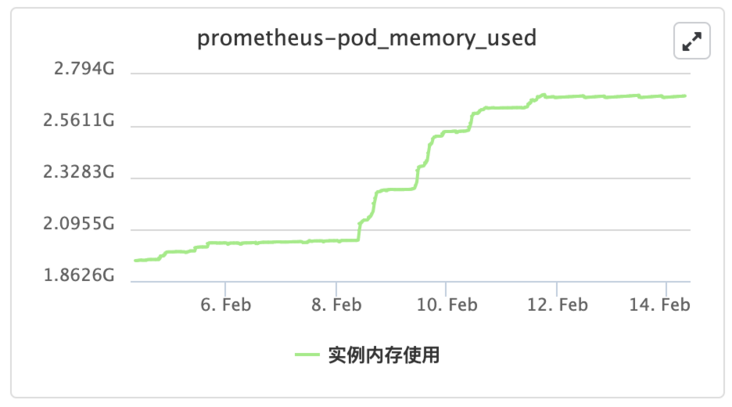
Use jmap -histo:live 1 to check the distribution of living objects. It is found that byte array occupies more memory and the number of PoolSubpage objects is also large. It is suspected that netty has a memory leak.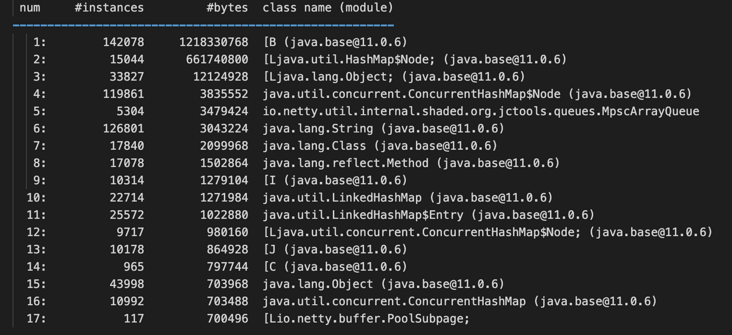
Check the ERROR log in ELK. In addition to the OOM ERROR, a small amount of netty ERROR information is found. The exception stack is as follows:
LEAK: ByteBuf.release() was not called before it's garbage-collected. See https://netty.io/wiki/reference-counted-objects.html for more information.
Recent access records:
Created at:
io.netty.buffer.PooledByteBufAllocator.newHeapBuffer(PooledByteBufAllocator.java:332)
io.netty.buffer.AbstractByteBufAllocator.heapBuffer(AbstractByteBufAllocator.java:168)
io.netty.buffer.AbstractByteBufAllocator.heapBuffer(AbstractByteBufAllocator.java:159)
io.netty.handler.codec.compression.JdkZlibDecoder.decode(JdkZlibDecoder.java:180)
io.netty.handler.codec.ByteToMessageDecoder.decodeRemovalReentryProtection(ByteToMessageDecoder.java:493)
io.netty.handler.codec.ByteToMessageDecoder.callDecode(ByteToMessageDecoder.java:432)
...It can be seen from the exception prompt message that the heap memory ByteBuf of netty is recycled by GC without being released, while netty uses the memory pool for heap memory management. If ByteBuff is recycled by GC without calling the release() method, the reference count of a large number of memory blocks in the memory pool cannot be reset to zero, resulting in the failure of memory recycling. After ByteBuf is recycled by GC, the application can no longer call the release () method, which leads to memory leakage.
Locate the location of the problem
Where netty is used in the project: Redisson, WebFlux and WebClient. Considering that the third-party library is very mature and has been applied in many commercial projects, the problem is unlikely to appear in the library code, which may be due to the wrong way of use. The main coding used in the application is WebClient, which is used to request the HTML of the third-party page.
In the business usage scenario, you need to read the contents of ResponseHeader and ResponseBody. Header is used to parse encoding from content type; Body is used to directly read binary data and determine the real coding format of the page.
The reason why it is necessary to determine the real encoding format of the page is because some third-party pages declare that the encoding format is UTF-8 through content type in the response header, but the real encoding format is GBK or GB2312, resulting in garbled code when parsing Chinese abstracts. Therefore, it is necessary to judge the real encoding format according to the stream content after reading the binary stream. Brothers who wrote about reptiles should understand.
WebClient provides the following methods to obtain Response:
- WebClient.RequestHeadersSpec#retrieve
The body can be directly processed as an object of the specified type, but the response cannot be directly operated; - WebClient.RequestHeadersSpec#exchange
The response can be operated directly, but the reading operation of the body needs to be handled by itself;
To meet the requirements, webclient.com is used in the project Requestheadersspec#exchange method, which is also the only place in the project where ByteBuf data can be directly operated. When using this method, only the data is read and the body is not released. On the annotation of the method, there is just such a paragraph: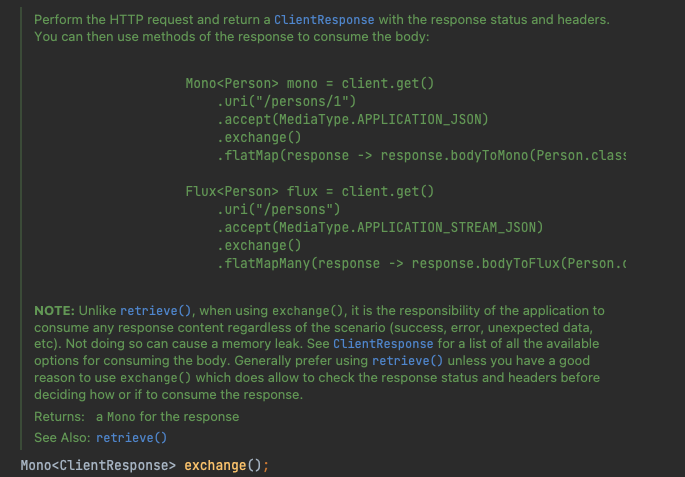
The roughly translated meaning of the NOTE part is:
Unlike retrieve(), when using exchange(), the application should consume the response content in any case (success, exception, unprocessed data, etc.). Failure to do so may result in memory leaks. See ClientResponse for ways to consume the body. Generally, you should use retrieve(), unless you have good reason to use exchange(), which allows you to check the response status and title, and then use it to decide whether to consume the body and how to consume the body.
Just when some business verification fails, for example, when the returned data identified in the content type is not HTML content, the application code returns directly without consuming the body, resulting in memory leakage.
// Request code example
WebClient.builder().build()
.get()
.uri(ctx.getUri())
.headers(headers -> {
headers.set(HttpHeaders.USER_AGENT, CHROME_AGENT);
headers.set(HttpHeaders.HOST, ctx.getUri().getHost());
})
.cookies(cookies -> ctx.getCookies().forEach(cookies::add))
.exchange()
.flatMap(response -> {
// Check again for timeout
// Note that mono is returned directly here Error without releasing the response
if (ctx.isParseTimeout(PARSE_TIMEOUT)) {
return Mono.error(ReadTimeoutException.INSTANCE);
}
// Resolve the redirection first. If there is no redirection, resolve the body
return judgeRedirect(response, ctx)
.flatMap(redirectTo -> followRedirect(ctx, redirectTo))
.switchIfEmpty(Mono.defer(() -> Mono.just(parser.parse(ctx))))
.map(LinkParseResult::detectParseFail);
})solve the problem
The cause of the problem has been located, and the solution has been given in the official document. Please refer to the ClientResponse for the methods that can be used to consume the body. On the comment of the ClientResponse interface, list all the methods used to consume the Response:
The specific functions of each method will not be repeated. According to the business scenario, the releaseBody() method should be called to release when the body is not needed. The modified code is as follows:
// Request code example
WebClient.builder().build()
.get()
.uri(ctx.getUri())
.headers(headers -> {
headers.set(HttpHeaders.USER_AGENT, CHROME_AGENT);
headers.set(HttpHeaders.HOST, ctx.getUri().getHost());
})
.cookies(cookies -> ctx.getCookies().forEach(cookies::add))
.exchange()
.flatMap(response -> {
// Check again for timeout and release the response
if (ctx.isParseTimeout(PARSE_TIMEOUT)) {
return response.releaseBody()
.then(Mono.error(ReadTimeoutException.INSTANCE));
}
// Resolve the redirection first. If there is no redirection, resolve the body
return judgeRedirect(response, ctx)
.flatMap(redirectTo -> followRedirect(ctx, redirectTo))
.switchIfEmpty(Mono.defer(() -> Mono.just(parser.parse(ctx))))
.map(LinkParseResult::detectParseFail);
})summary
When using the responsive HTTP client WebClient, the exchange() method is used to accept the response data, but the ClientResponse#releaseBody() method is not called in some process branches, resulting in a large amount of data not being released, the netty memory pool is full, and subsequent requests report OOM exceptions in the memory application.
Lessons learned: when using unfamiliar third-party libraries, you must read method notes and class notes.
Reference documents:
- Netty memory leak troubleshooting
This paper is based on the operation tool platform of blog group sending one article and multiple sending OpenWrite release