Flink has been supported in SQL Client since version 1.13 savepoint Resume the job. Flink savepoint introduction
Next, we build a my from Flink SQL Client sql An example of cdc data entering hudi data Lake through kafka. The overall process is as follows:
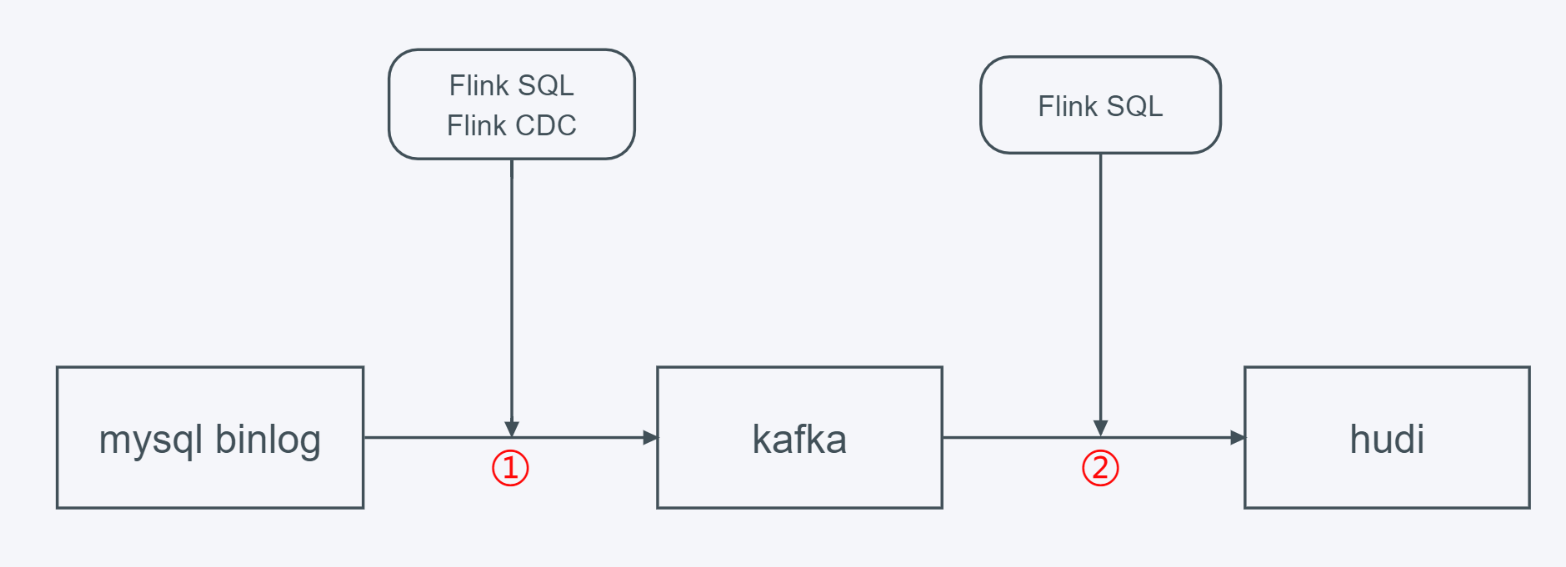
In the second step above, we manually stop the Flink task of kafka → hudi, and then recover from the savepoint in the Flink SQL Client.
The following work is similar to Flink SQL Client actual CDC data into the lake It's just the of this article flink The version is 1.13.1, which can be used to complete the verification of this paper.
Environmental dependence
hadoop 3.2.0
zookeeper 3.6.3
kafka 2.8.0
mysql 5.7.35
flink 1.13.1-scala_2.12
flink cdc 1.4
hudi 0.10.0-SNAPSHOT (latest master branch compilation [2021 / 10 / 08])
datafaker 0.7.6
See for the description of each component Flink SQL Client actual CDC data into the lake
Component description, installation and use can be searched directly in the search box in the upper right corner with keywords.
Operation guide
Import test data into mysql using datafaker
- Create a stu8 table in the database
mysql -u root -p create database test; use test; create table stu8 ( id int unsigned auto_increment primary key COMMENT 'Self increasing id', name varchar(20) not null comment 'Student name', school varchar(20) not null comment 'School name', nickname varchar(20) not null comment 'Student nickname', age int not null comment 'Student age', score decimal(4,2) not null comment 'achievement', class_num int not null comment 'Class size', phone bigint not null comment 'Telephone number', email varchar(64) comment 'Home network mailbox', ip varchar(32) comment 'IP address' ) engine=InnoDB default charset=utf8;Copy
- New meta Txt file, the file content is:
id||int||Self increasing id[:inc(id,1)] name||varchar(20)||Student name school||varchar(20)||School name[:enum(qinghua,beida,shanghaijiaoda,fudan,xidian,zhongda)] nickname||varchar(20)||Student nickname[:enum(tom,tony,mick,rich,jasper)] age||int||Student age[:age] score||decimal(4,2)||achievement[:decimal(4,2,1)] class_num||int||Class size[:int(10, 100)] phone||bigint||Telephone number[:phone_number] email||varchar(64)||Home network mailbox[:email] ip||varchar(32)||IP address[:ipv4]Copy
- Generate 1000000 pieces of data and write them to the test. In mysql Stu8 table (set the data as large as possible so that the task of writing to hudi can continue)
datafaker rdb mysql+mysqldb://root:Pass-123-root@hadoop:3306/test?charset=utf8 stu8 1000000 --meta meta.txt Copy
Download the jar packages related to hudi, Flink MySQL CDC and Flink Kafka
This article provides a compiled hudi - Flex - bundle_ 2.12-0.10.0-SNAPSHOT. Jar. If you want to compile hudi yourself, you can compile it directly from the clone master branch. (note to specify the hadoop version)
Download the jar package to the lib directory of flink
cd flink-1.13.1/lib wget https://obs-githubhelper.obs.cn-east-3.myhuaweicloud.com/blog-images/category/bigdata/flink/flink-sql-client-savepoint-example/hudi-flink-bundle_2.12-0.10.0-SNAPSHOT.jar wget https://repo1.maven.org/maven2/com/alibaba/ververica/flink-sql-connector-mysql-cdc/1.4.0/flink-sql-connector-mysql-cdc-1.4.0.jar wget https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-kafka_2.12/1.13.1/flink-sql-connector-kafka_2.12-1.13.1.jarCopy
If you encounter the problem of missing some classes during starting and running the flick task, please download the relevant jar package and place it in the directory of flick-1.13.1/lib. The missing packages encountered during the operation of this experiment are as follows (click to download):
- commons-logging-1.2.jar
- htrace-core-3.1.0-incubating.jar
- htrace-core4-4.1.0-incubating.jar
- hadoop-mapreduce-client-core-3.2.0.jar
Start the flink session cluster on yarn
First, make sure Hadoop is configured_ Classpath, for the open source version Hadoop 3 2.0, which can be set as follows:
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$HADOOP_HOME/share/hadoop/client/*:$HADOOP_HOME/share/hadoop/common/*:$HADOOP_HOME/share/hadoop/hdfs/*:$HADOOP_HOME/share/hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/tools/*:$HADOOP_HOME/share/hadoop/yarn/*:$HADOOP_HOME/etc/hadoop/*Copy
For Flink, you need to open checkpoint, configure the savepoint directory, and modify the flink-conf.yaml configuration file
execution.checkpointing.interval: 150000ms state.backend: rocksdb state.checkpoints.dir: hdfs://hadoop:9000/flink-chk state.backend.rocksdb.localdir: /tmp/rocksdb state.savepoints.dir: hdfs://hadoop:9000/flink-1.13-savepoints Copy
Start the flink session cluster
cd flink-1.13.1 bin/yarn-session.sh -s 4 -jm 2048 -tm 2048 -nm flink-hudi-test -dCopy
start-up flink sql client
cd flink-1.13.1 bin/sql-client.sh embedded -s yarn-session -j ./lib/hudi-flink-bundle_2.12-0.10.0-SNAPSHOT.jar shellCopy
flink reads mysql binlog and writes it to kafka
Create mysql source table
create table stu8_binlog( id bigint not null, name string, school string, nickname string, age int not null, score decimal(4,2) not null, class_num int not null, phone bigint not null, email string, ip string ) with ( 'connector' = 'mysql-cdc', 'hostname' = 'hadoop', 'port' = '3306', 'username' = 'root', 'password' = 'Pass-123-root', 'database-name' = 'test', 'table-name' = 'stu8' );Copy
Create kafka target table
create table stu8_binlog_sink_kafka( id bigint not null, name string, school string, nickname string, age int not null, score decimal(4,2) not null, class_num int not null, phone bigint not null, email string, ip string, primary key (id) not enforced ) with ( 'connector' = 'kafka' ,'topic' = 'cdc_mysql_test_stu8_sink' ,'properties.zookeeper.connect' = 'hadoop1:2181' ,'properties.bootstrap.servers' = 'hadoop1:9092' ,'format' = 'debezium-json' );Copy
Create a task to write mysql binlog log to kafka
insert into stu8_binlog_sink_kafka select * from stu8_binlog;Copy
Flynk reads kafka data and writes hudi data
Create kafka source table
create table stu8_binlog_source_kafka( id bigint not null, name string, school string, nickname string, age int not null, score decimal(4,2) not null, class_num int not null, phone bigint not null, email string, ip string ) with ( 'connector' = 'kafka', 'topic' = 'cdc_mysql_test_stu8_sink', 'properties.bootstrap.servers' = 'hadoop1:9092', 'format' = 'debezium-json', 'scan.startup.mode' = 'earliest-offset', 'properties.group.id' = 'testGroup' );Copy
Create hudi target table
create table stu8_binlog_sink_hudi( id bigint not null, name string, `school` string, nickname string, age int not null, score decimal(4,2) not null, class_num int not null, phone bigint not null, email string, ip string, primary key (id) not enforced ) partitioned by (`school`) with ( 'connector' = 'hudi', 'path' = 'hdfs://hadoop:9000/tmp/test_stu8_binlog_sink_hudi', 'table.type' = 'MERGE_ON_READ', 'write.precombine.field' = 'school' );Copy
Create a task to write kafka data to hudi
insert into stu8_binlog_sink_hudi select * from stu8_binlog_source_kafka;Copy
After the task runs for a period of time, we manually save the hudi job and stop the task
bin/flink stop --savepointPath hdfs://hadoop:9000/flink-1.13-savepoint/ 0128b183276022367e15b017cb682d61 -yid application_1633660054258_0001Copy
Get the specific savepoint path of the task:
[root@hadoop flink]# bin/flink stop --savepointPath hdfs://hadoop:9000/flink-1.13-savepoint/ 0128b183276022367e15b017cb682d61 -yid application_1633660054258_0001
2021-10-07 22:55:51,171 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - Found Yarn properties file under /tmp/.yarn-properties-root.
2021-10-07 22:55:51,171 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - Found Yarn properties file under /tmp/.yarn-properties-root.
Suspending job "0128b183276022367e15b017cb682d61" with a savepoint.
2021-10-07 22:55:51,317 WARN org.apache.flink.yarn.configuration.YarnLogConfigUtil [] - The configuration directory ('/data/flink-1.13.1/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
2021-10-07 22:55:51,364 INFO org.apache.hadoop.yarn.client.RMProxy [] - Connecting to ResourceManager at hadoop/192.168.241.128:8032
2021-10-07 22:55:51,504 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2021-10-07 22:55:51,506 WARN org.apache.flink.yarn.YarnClusterDescriptor [] - Neither the HADOOP_CONF_DIR nor the YARN_CONF_DIR environment variable is set.The Flink YARN Client needs one of these to be set to properly load the Hadoop configuration for accessing YARN.
2021-10-07 22:55:51,567 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface hadoop:34681 of application 'application_1633660054258_0001'.
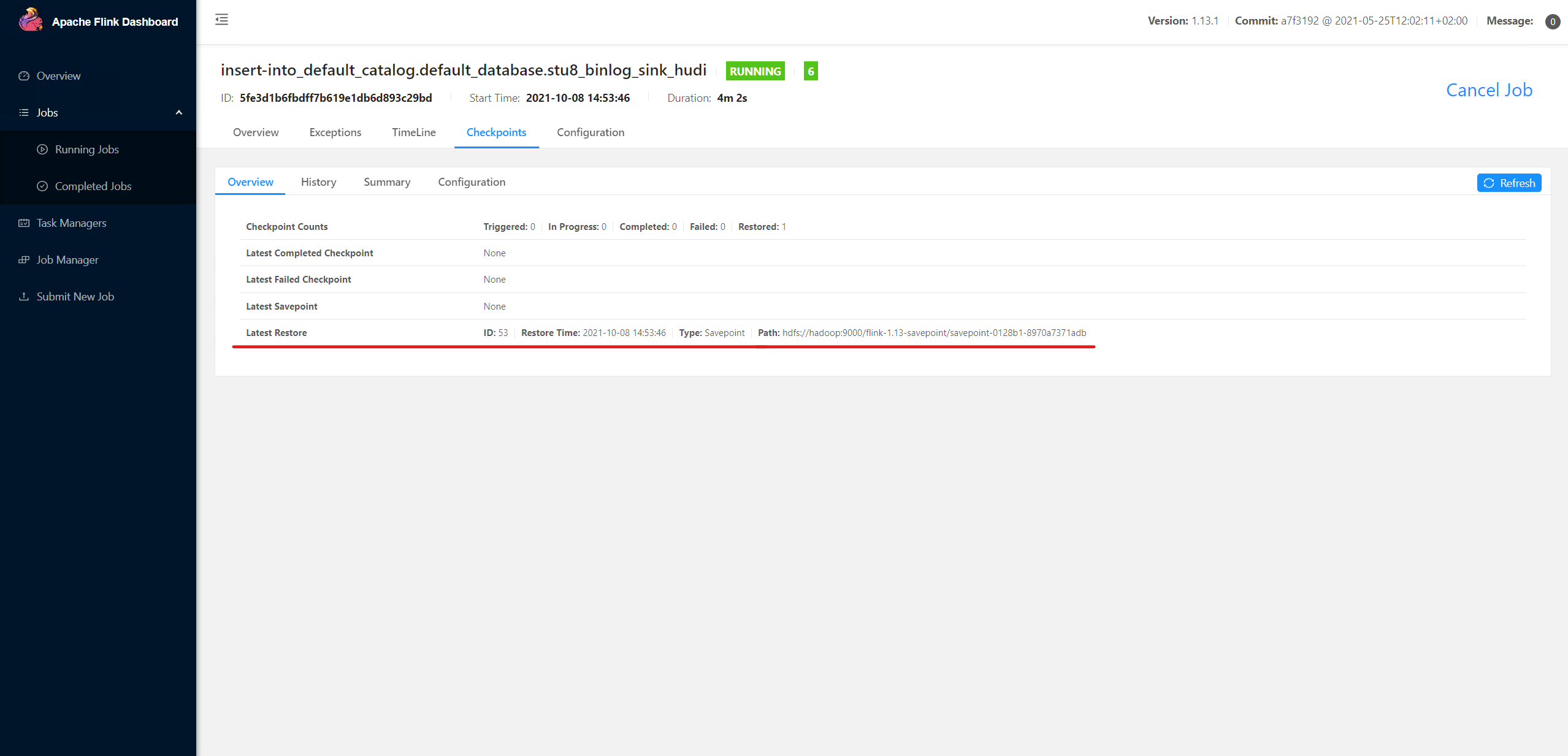
Savepoint completed. Path: hdfs://hadoop:9000/flink-1.13-savepoint/savepoint-0128b1-8970a7371adbCopyRestore task from savepoint: (executed in Flink SQL Client)
SET execution.savepoint.path=hdfs://hadoop:9000/flink-1.13-savepoint/savepoint-0128b1-8970a7371adb insert into stu8_binlog_sink_hudi select * from stu8_binlog_source_kafka;Copy
You can see that the task is restored from the above checkpoint:
This article is the original article of "xiaozhch5", a blogger from big data to artificial intelligence. It follows the CC 4.0 BY-SA copyright agreement. Please attach the original source link and this statement for reprint.
Original link: https://lrting.top/backend/354/