preface:
Learn some notes on Redis by yourself 📒
Write it down, and it's convenient for you to look through it
Course link: https://coding.imooc.com/class/151.html
Book recommendation: Redis development and operation and maintenance
First article: https://sleepymonster.cn
Here is just an introduction or a search ~
For a specific aspect, it is recommended to read other people's articles or books
Thus, Redis will have a deeper understanding. Of course, the above courses are recommended!
Get Redis
install
$ brew install redis $ redis-server // open
Executable description
$ redis-server // Redis server $ redis-cli // Redis command line client $ redis-benchmark // IDS performance test $ redis-check-aof // Redis AOF file repair tool $ redis-check-dump // RDB file checking tool $ redis-sentinel // Sentinel server
Three startup methods
$ redis-server // Default configuration startup $ redis-server --port 6380 // Dynamic parameter start $ redis-server configPath // Profile startup // Verify startup $ ps -ef | grep redis $ netstat -antpl | grep redis $ redis-cli -h ip -p port ping // be careful ⚠️ // Single machine multi instance configuration files can be distinguished by ports
Connection of Redis client
$ redis-cli -h ip -p port > set hello world > Ok > get hello > "world"
Redis common configuration
- Whether daemon is a daemon (no|yes)
- port
- logfile Redis system log
- dir Redis working directory
Profile startup
# Basic settings # Enable persistence daemonize yes # port port 6382 # working directory dir "/usr/local/Cellar/redis/6382-data" # journal logfile "/usr/local/Cellar/redis/6382.log"
$ redis-server ./6382-redis.conf $ ps -ef | grep redis-server | grep 6382 $ cat ./6382.log //view log
Rational use of API
General Command
$ keys //Get all keys > keys* > keys he* // Find the beginning of he > keys he[h-l]* > keys ph? // The keys command is generally not used in production environments $ dbsize //Size of the database > dbsize $ exists key // Judge whether it exists > exists a //Return 1 0 $ del key [key...] //Delete key > del a $ expire key seconds // Set expiration time > expire a 30 > ttl key // View expiration time / / - 2 does not exist - 1 does not exist > persist key // Remove expiration time $ type key // View type // String Hash list set Zset none
matters needing attention
- Run only one open road at a time
- Reject long command
- It's not a single thread
character string
Scenario: cache counter distributed lock
$ get key $ mget key1 key2 key3 // Batch acquisition $ getset key newvalue // Set the new and return the old at the same time $ append key value // Append value to old value $ strlen key // Returns the length of the string $ getrange key start end // Gets all values of the specified subscript of the string $ setrange key index value // Sets all values corresponding to the specified subscript $ set key value $ setnx key value // key cannot be set until it does not exist $ set key value xx // The key can only be set if it exists $ mset key1 value1 key2 value2 // Batch settings $ del key $ incr key // The key is incremented by 1. If the key does not exist, get(key)=1 $ decr key $ incrby key k // The key automatically increases k. if the key does not exist, get(key)=k $ incrbyfloat key 3.5 // Increase floating point number $ decrby key k
Hash
$ hget key field $ hmget key field1 field2 $ hgetall key $ hvals key // Returns the value s of all field s corresponding to the hash key $ hkeys key $ hset key field value $ hmset key field1 value1 field2 value2 $ hsetnx key field value // If it exists, the setting fails $ hdel key field $ hexists key field $ hlen key $ hincrby key field intCounter // The value in the field of the key of the hash is incremented by intCounter $ hincrbyfloat key field floatCounter
list
// increase $ rpush key v1 v2 v3 // Insert from right $ lpush key v1 v2 v3 // Insert from left $ linsert key before|after value newValue // Insert a new value around a specific value of key // Delete $ lpop key $ rpop key // Pop right $ lrem key count value // Delete values equal to value when > 0 starts from the left when < 0 starts from the right when = 0 all $ ltrim key start end // Trim list by index range $ blpop key timeout // Timeout is the blocking timeout $ brpop key timeout // Timeout is the blocking timeout // check $ lrange key start end (include end) // Gets the item of the specified index range // change $ lset key index newValue // set up
aggregate
// Single operation $ sadd key element // If it exists, the addition fails $ srem key element $ scard key // Calculate collection size $ sismember key value // Determine whether value exists in the collection $ srandmember key count // Randomly pick count elements from the collection $ spop key count // Pop up count elements randomly $ smember key // Return all // Difference set, intersection, union set between multiple $ sdiff key1 key2 // Difference set $ sinter key1 key2 // intersection $ sunion key1 key2 // Union $ sdiff|sinter|sunion + store key // Save it
Ordered set
$ zadd key score element // score can be repeated, but element cannot $ zrem key element // Delete element $ zscore key element // Score $ zincrby key increScore element // Control scores for unique element s $ zcard key // Returns the number of elements $ zrank key element // Get ranking $ zrange key 0 -1 withscores // Get the first to last and print out the score $ zrangebyscore key min max [withscores] // Get by score $ zcount key min max $ zremrangebyrank key min max // Start deletion by ranking $ zinterstore | zunionstore
Swiss Army knife
Life cycle: send command - > queue - > execute command - > return result
Slow query
Slow queries occur in the third phase
Client timeout is not necessarily a slow query problem, but it is a factor
- fifo
- Fixed length
// The default value is 10000 $ slowlog-max-len // Slow query time (ms) $ config set slowlog-max-len 1000 // Adopt dynamic configuration // Default 128 $ slow-log-slower-than //Threshold for slow queries // Basic API $ slowlog get [n] //Get slow query queue $ slowlog len // Get slow query queue length $ slowlog reset // Clear slow query
Experience:
- Slowlog Max len is usually set to 1ms
- Slow log slow than is generally set to 1000
- Persistent slow queries on a regular basis
Pipeline
Lifecycle: transfer command - > calculation - > return result
Pipeline is a one-time package. After transmitting the command, execute it n times and then come back.
How to use? How to package and send the query command to pipeline.
Suggestions for use:
- Pay attention to the carrying quantity
- pipeline can only work on one Redis
- Difference between M operation and pipeline
Publish and subscribe
Different from message queuing mode
Message queuing is to grab a publish subscription is a broadcast 📢
Role: Publisher subscriber channel
Model: Publisher - > channel < - subscriber (can subscribe to mu lt iple channels) (message stacking function is not allowed)
$ publish channel message // The issue command returns the number of subscribers $ subscribe [channel] // Subscriptions can be one or more $ unsubscribe [channel] // Unsubscribe $ psubscribe [pattern] // subscription model $ punsubscribe [pattern] // Unsubscribe from the specified mode $ punsub channels // Lists channels with at least one subscriber $ punsub numsub [channel] // Lists the number of subscribers for a given channel $ punsub numpat // Lists the number of subscribed modes
Bitmap (bitmap)
Bit (binary) that can actually be manipulated
$ setbit key offset value // Specify the index setting value for the bitmap. / / the previous corresponding value is returned $ getbit key offset // Gets the specified index value of the bitmap $ bitcount key [start end] // Gets the number of 1 in a certain range of the bitmap $ bitop op destkey key [key...] // Perform and or not xor operations on multiple bitmaps and store the results in destkey $ bitpos key targetbit [start] [end] // Calculates the position where the value corresponding to the first offset in the specified range of the bitmap is equal to destkey
Suggestions for use:
- type=string max. 512M
- Note the offset
- Bitmap is not absolutely good
HyperLogLog
A minimal space completes the statistics of independent quantities
$ pfadd key element [element...] // Add element $ pfcount key [key...] // Calculate independent totals $ pfmerge destkey sourcekey [sourcekey...] // Merge multiple
limitations:
- Error rate 0.81%
- Can't get a single piece of data
GEO
Store similar latitude and longitude to calculate the distance between two places
$ geo key longitude latitude member // Add geographic location $ geopos key member [member...] // Get geographic location $ geodist key member1 member2 [unit] // Get the distance between two places $ georadius // Complex query document https://cloud.tencent.com/developer/section/1374022
explain:
- since 3.2+
- type geoKey = zset
- Remove direct use of Zset API
Trade off of Redis persistence
The data in memory will be saved asynchronously on disk
- Snapshot mode Redis RDB
- Log writing Redis AOF
RDB
Create a snapshot of RDB binary file, store it on the hard disk, and reload it after restart
There are three ways to trigger
- save (synchronization)
Because save is synchronous, it may cause blocking and cannot respond to the client
The new file replaces the old one.
- bgsave (asynchronous)
Creating a child process (also blocked here) fork() will respond to the client normally, but will consume memory
- automatic
The rule is: save as: dump rdb
| Seconds | Changes |
|---|---|
| 900 | 1 |
| 300 | 10 |
| 60 | 10000 |
// Optimal configuration
Turn off automatic
dbfilename dump-${port}.rdb
dir /oneBigDiskPath
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
- A way not to be ignored
- Full replication
- debug reload
- shutdown
AOF
Write AOF file in real time
- Three strategies
| strategy | describe | shortcoming |
|---|---|---|
| always | Write buffer, flush to disk, and each command will be written. | High IO overhead |
| everysec | Refresh to disk every second. | Lost 1 second data |
| no | Operating system | Uncontrollable |
- AOF override
Solve the problem of writing bigger and bigger
Simplify expired, repeated and useless optimization.
// bgrewriteaof // AOF override configuration // Auto AOF rewrite min size AOF file rewrites the required size // Auto AOF rewrite percentage AOF file growth rate // aof_ Current size AOF current size // aof_base_size AOF last started and overridden size
- to configure
appendonly yes
appendfilename "appendonly-${port}.aof"
appendfsync evertsec
dir /bigdiskpath
no-appendfsync-on-rewrite yes
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
Best strategy
-
RDB
-
RDB "off"
-
centralized management
-
Master slave
-
-
AOF
- On: caching and storage
- Rewrite centralized management
-
optimum
- Small fragment
- Caching and storage
- monitor
Development, operation and maintenance FAQs
- fork
- Synchronous operation
- The more memory you need, the more time you need
- info: latest_fork_usec query last fork time
- Improvement: control the maximum available memory maxmemory of Redis instance; Reasonably configure linux memory allocation strategy VM overcommit_ memory=1; Reduce fork frequency
- Subprocess overhead and optimization
- It is mainly used for CPU intensive writing during file generation
- Improvement: no CPU binding and no intensive deployment of COU
- Memory overhead, which will share the memory of the parent process
- Hard disk consumption iostat /iotop de analysis
- Improvement: do not deploy with high hard disk load service; no-appendfsync-on-rewrite=yes
- AOF blocking
Viewing the log, you will find:... Xxxmaking too long xxxx
aof_delayed_fsync historical cumulative AOF blocking quantity
Redis replication
Master slave replication
A single machine has a bottleneck. In case of machine failure, the client cannot link
And there is also a capacity bottleneck; QPS bottleneck period
One master and multiple slave can be realized. Only one master data can be unidirectional in one slave
Data copies can be accessed, and functions such as reading performance can be expanded
The default is full copy
// Replicated configuration // The command does not need to be restarted // The unified configuration needs to be restarted // slaveof command $ slaveof masterIP $ slaveof no one // Break and become the slave node of others // to configure slaveof ip port slave-read-only yes $ info replication // View tiles (existing roles) $ redis-cli -p 6379 info server | grep run # View runID
Full replication
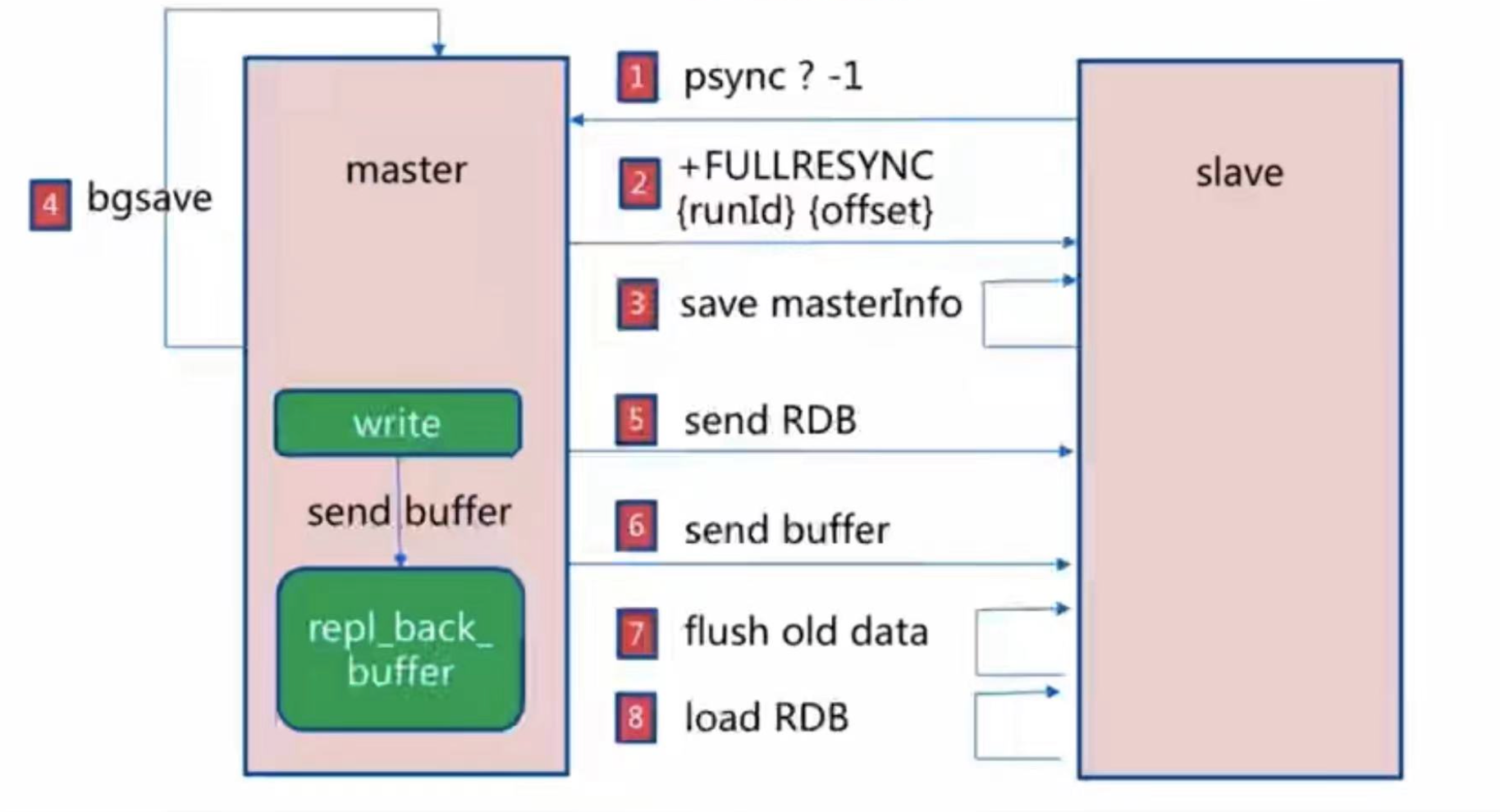
Cost: bgsave time; RDB file network transmission time; Clear RDB time from node; Load RDB from node; AOF rewrite time
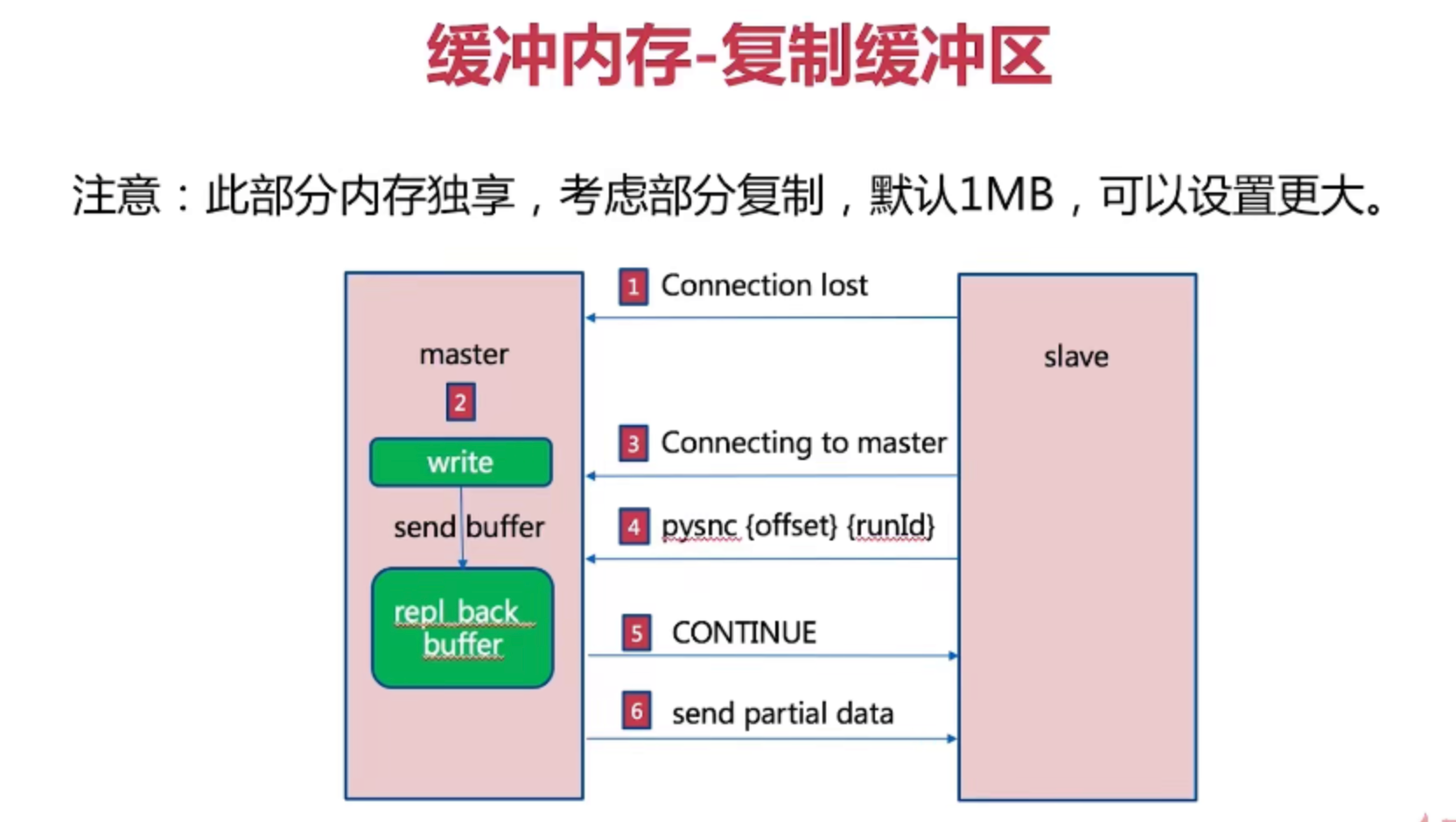
Partial replication
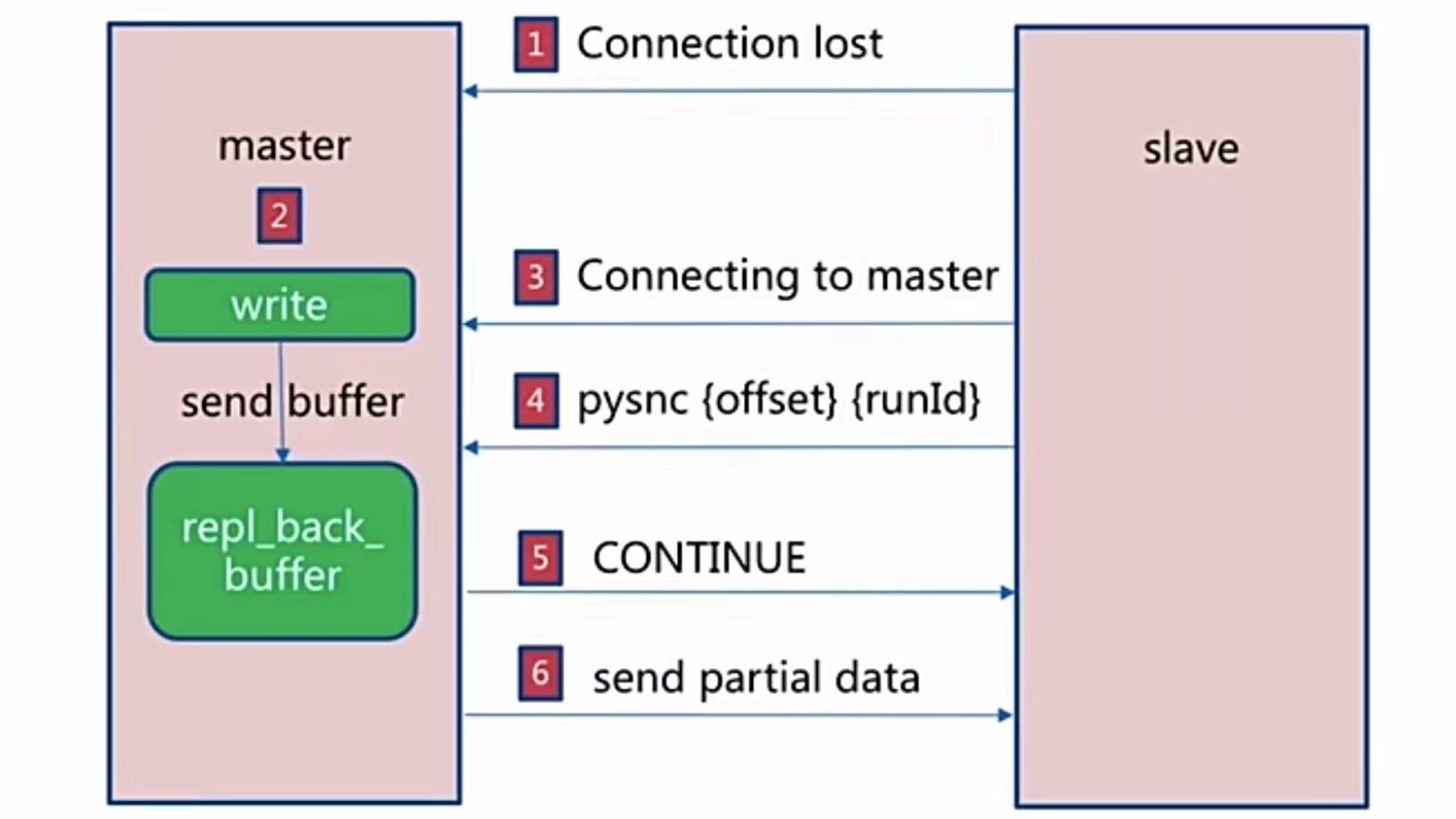
Fault handling
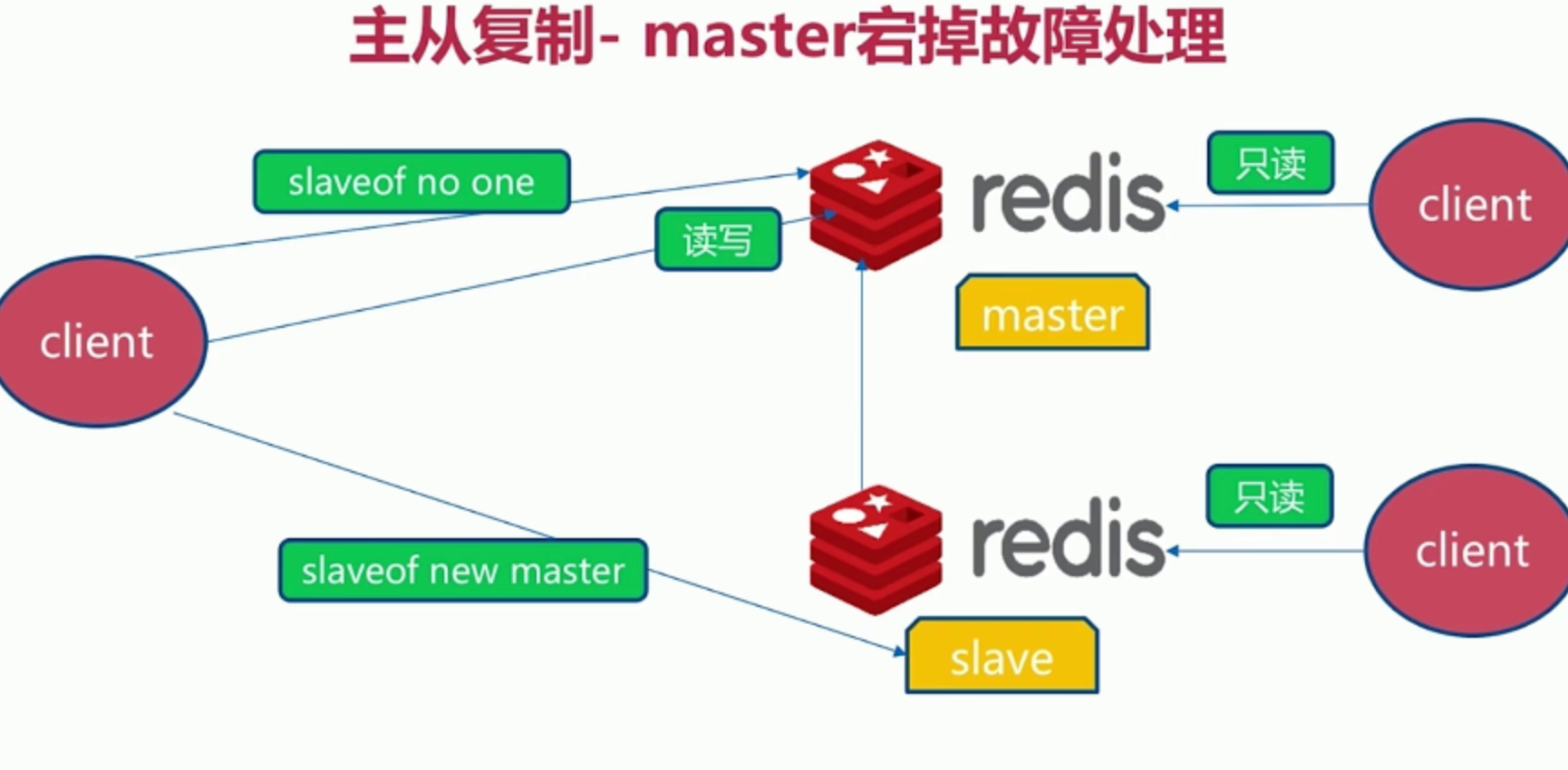
Automatic failover: slave failure, master failure
Slave failure: migrate to another slave
Master failure: find a slave to become the master
Problems in development, operation and maintenance
- Read write separation
- Allocate read traffic to slave nodes
- Replication data latency
- Expired data read
- Slave node failure
- Inconsistent master-slave configuration
- maxmemory inconsistency: missing data
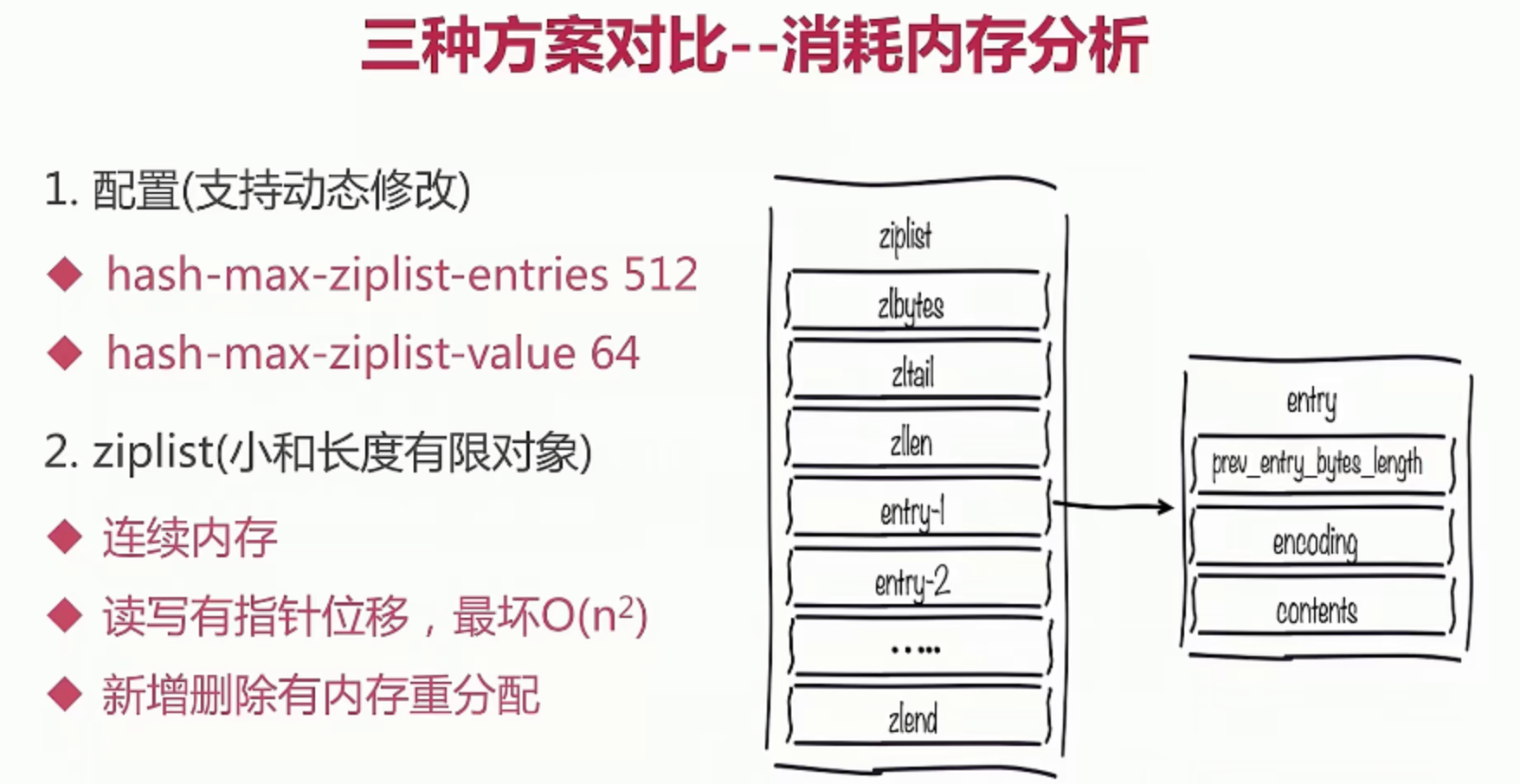
- Data structure optimization parameters (for example: hash Max ziplost entities): memory inconsistency
- Avoid full replication
- First full copy
- Node run ID mismatch
- Insufficient replication backlog buffer
- Avoid replication storm
- A single master node hangs up and multiple slave nodes start full replication
- A machine is full of master s, and the machine hangs up
Redis Sentinel
Basic architecture
High availability of master-slave replication: there is a problem with the master node, usually manual failover; Limited write and storage capacity.
Basic architecture: fault judgment, transfer and notification.
The client obtains redis information from Sentinel. (multiple sets can be monitored)
Automatic failover... (Port default: 26379)
install and configure
Configure and enable master-slave nodes
Configure and enable Sentinel monitoring master node
// Master node
redis-server redis-7000.conf
port 7000
daemonzie yes
pidfile ${dir}-7000.pid
logfile 7000.log
dir ${dir}
// Slave node
redis-server redis-7001.conf
port 7001
daemonzie yes
pidfile ${dir}-7001.pid
logfile 7001.log
dir ${dir}
slaveof ip port
// Sentinel configuration
port ${port}
dir ${dir}
pidfile ${port}.pid
sentinel monitor mymaster ip 7000 2 // 2 means: if two sentinel s think there is a problem, they start failover
sentinel down-after-milliseconds mymaster 30000 // Similar to ping
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
client
You need to know that Sentinel node collection and masterName start traversal
Internal is implemented by publishing and subscribing. (not agent mode)
from redis.sentinel import Sentinel
sentinel = Sentinel(['localhost', 26379], ['localhost', 26380], ['localhost', 26381], socket_timeout=0.1)
sentinel.discover_master('mymaster')
sentinel.discover_slaves('mymaster')
Timed task principle
- Every 10 seconds, each sentinel executes info on the master and slave
- Discover slave nodes
- Confirm master-slave relationship
- Every 2 seconds, each sentinel exchanges information through the channel of the master node
- Interact through channels
- Interactive views on nodes and their own information
- ping other sentinel s and redis every second
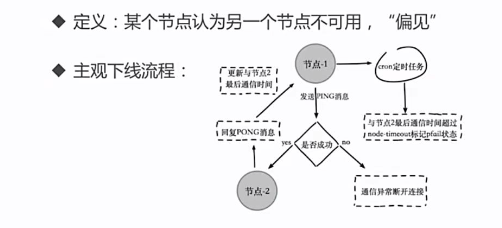
Subjective / objective offline - > leader election - > complete failover
- Subjective / objective
sentinel monitor mymaster ip 7000 <quorum> sentinel down-after-milliseconds <masterName> <timeout>
Subjective offline: that is, the offline judgment of each sentinel individual node
Objective offline: it exceeds the uniform quota, that is, multiple users think they are offline
- Leader election
sentinel is-master-down-by-addr // You can not only judge whether the master is offline, but also apply as a leader
sentinel will agree with you if he has not agreed with others.
If the number of votes is more than half and greater than quorum, the leader will be elected again.
- Complete failover
- After it is selected, it will be slaveof no one to make it a master node.
- Send commands to the remaining slave nodes to make them become slave nodes of the new master.
- Set the original master to slave and keep an eye on it.
- Attention
- Select the one with higher slave priority
- Nodes with larger offsets are selected (more complete replication)
- Select a node with a smaller runID
Common development, operation and maintenance problems
sentinel failover <masterName> // Manual logoff (manual trigger failover)
- When the slave node goes offline, it should be judged that the time is temporary, such as subsequent cleaning work
- Only the slave will be offline, and the corresponding read client cannot transfer itself. = > Client connection slave node resource pool
- Sentinel quantity should be > = 3.
Redis Cluster
Why cluster?
Higher concurrency and data volume are required
data distribution
- Sequential partition
- The dispersion is easy to tilt
- Key value distribution is related to business
- Hash partitioning
- High digital dispersion
- Key value distribution is independent of business
- Node redundancy partition (the range of data migration is too large)
- Operations such as node scaling or capacity expansion will lead to data migration
- For the performance of migration, it is recommended to double the capacity
- Consistent hash partition
- Optimized remainder partition
- Only neighboring nodes are affected, but data migration will still occur
- Ensure minimum data migration and load balancing
- Virtual slot partition (used by Redis Cluster)
- Each slot maps a data subset to achieve partitioning
- Use the CRC16 function to find the matching area directly
Build clusters
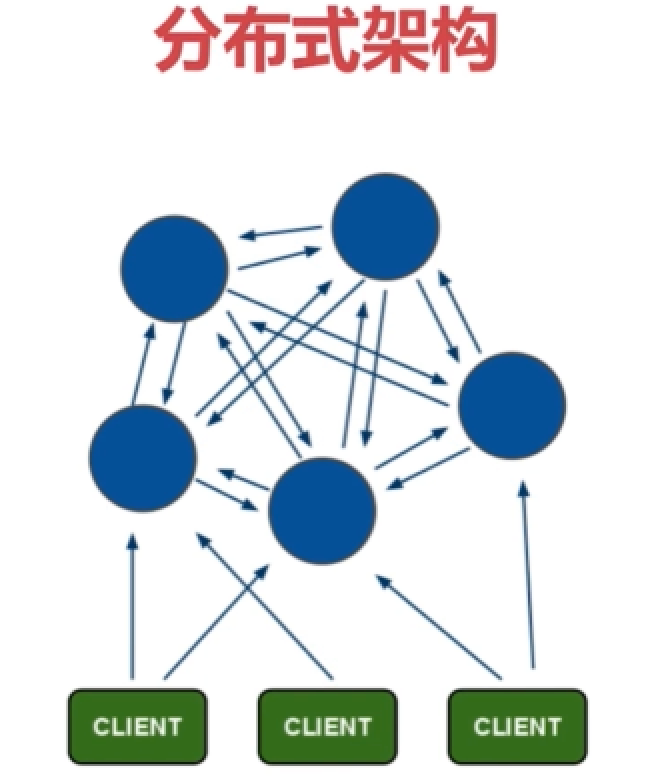
To access. If the data is not in the corresponding slot, you will be notified to access the corresponding slot.
Each node is responsible for a part of the data and needs a total client to manage it.
Each node is responsible for reading and writing, and each node communicates with each other.
- node
cluster-enabled yes // Cluster mode startup
- meet
They communicate with each other
- Assign slot
Assign the size of each slot
- copy
Each primary node has a secondary node.
-
install
- Native install command
// Configuration node port ${port} daemonzie yes pidfile "${dir}-${port}.pid" logfile "${port}.log" dir "${dir}" dbfilename "dump-${port}.rdb" cluster-enabled yes // Cluster mode startup cluster-config-file "nodes-${port}.conf" // Add corresponding configuration cluster-node-timeout 15000 // Failover / node offline time cluster-require-full-coverage no // If one fails, the service will not be stopped // Turn on the node (3 master x 3 slave here) $ redis-server redis-7000.conf $ redis-server redis-7001.conf ... // meet communication $ redis-cli -h 127.0.0.1 -p 7000 cluster meet 127.0.0.1 7001 // Establish contact between the two parties // Assign slot $ redis-cli -h 127.0.0.1 -p 7000 cluster addslots {0...5461} // 16384 average $ redis-cli -h 127.0.0.1 -p 7001 cluster addslots {5461...10922} // 16384 average $ redis-cli -h 127.0.0.1 -p 7002 cluster addslots {10923...16383} // 16384 average // Allocation of master-slave relationship to achieve failover $ redis-cli -h 127.0.0.1 -p 7003 cluster replicate ${node-id-7000} $ redis-cli -h 127.0.0.1 -p 7004 cluster replicate ${node-id-7001} $ redis-cli -h 127.0.0.1 -p 7005 cluster replicate ${node-id-7002} // query state $ redis-cli -p 7000 cluster nodes $ redis-cli -p 7000 cluster info $ redis-cli -p 7000 cluster slots- Installation of official tools
- The Ruby environment is ready to download, compile and install
- Installation of Rubygem redis client
- Install redis trib rb
- Reference link: https://codeantenna.com/a/g07I0RgJZW
cp ${REDIS_HOME}/src/redis-trib.rb /usr/loacl/bin // redis is enabled in the configuration, but the cluster is not online yet // One click on // After each master node, there is a slave node. The first three are master nodes and the last three are slave nodes $ ./redis-trib.rb create --replicas 1 127.0.0.1:8000 127.0.0.1:8001 127.0.0.1:8002 127.0.0.1:8003 127.0.0.1:8004 127.0.0.1:8005
Cluster scaling
Principle: transfer of slot key values (understand the relationship between slot node keys)
-
Capacity expansion
-
Prepare new node - > same configuration
-
Join cluster meet - > cluster meet
-
$ redis-trib.rb add-node 127.0.0.1:xxxx 127.0.0.1:xxxx(Already exists) // It's official, too
-
Function 1: expand the migration slot and data
-
Responsible for failover as a slave node
-
-
Migrate slots and data
-
Slot migration plan
-
Migrate data
$ cluster setslot {slot} importing {sourceNodeId} // Send data to the target node so that the target node is ready to import into the slot $ cluster setslot {slot} migrating {targetNodeId} // Let the source node prepare the data to be moved out of the slot $ cluster getkeysinslot {slot} {conut} // The source node circularly obtains count keys belonging to the slot $ migrate {targetIp} {targetPort} key 0 {timeout} // The source node migrates the specified key $ cluster setslot {slot} node {targetNodeId} // Inform other nodes that my current slot is on the new one // The above is too troublesome $ redis-trib.rb reshard 127.0.0.1:7000 // Follow the prompts $ redis-cli -p 7000 cluster slots // View results- Add slave node
-
-
-
shrink
-
Offline migration slot
-
$ redis-trib.rb reshard --from {Fromid} --to {Toid} --slots 1366 127.0.0.1:7006
-
-
Forget node
-
$ cluster forget {downNodeID} // All other nodes need to be forgotten // You must lower the slave node first and then the master node, otherwise automatic transfer will be triggered $ redis-trib.rb del-node 127.0.0.1:7000 {DownnodeId} // Automatic completion
-
-
Close node
-
Client routing
- moved redirection (slot miss)
- -c naming will be redirected automatically. If not used, MOVED (cluster mode) will be returned
- ask redirection (the client records the source node but has migrated to the target node)
- smart client
- Select a running node in the cluster, and use cluster slots to initialize the slot and node mapping
- Map the results of cluster slots to local and create jedispools for each
- Ready to execute command
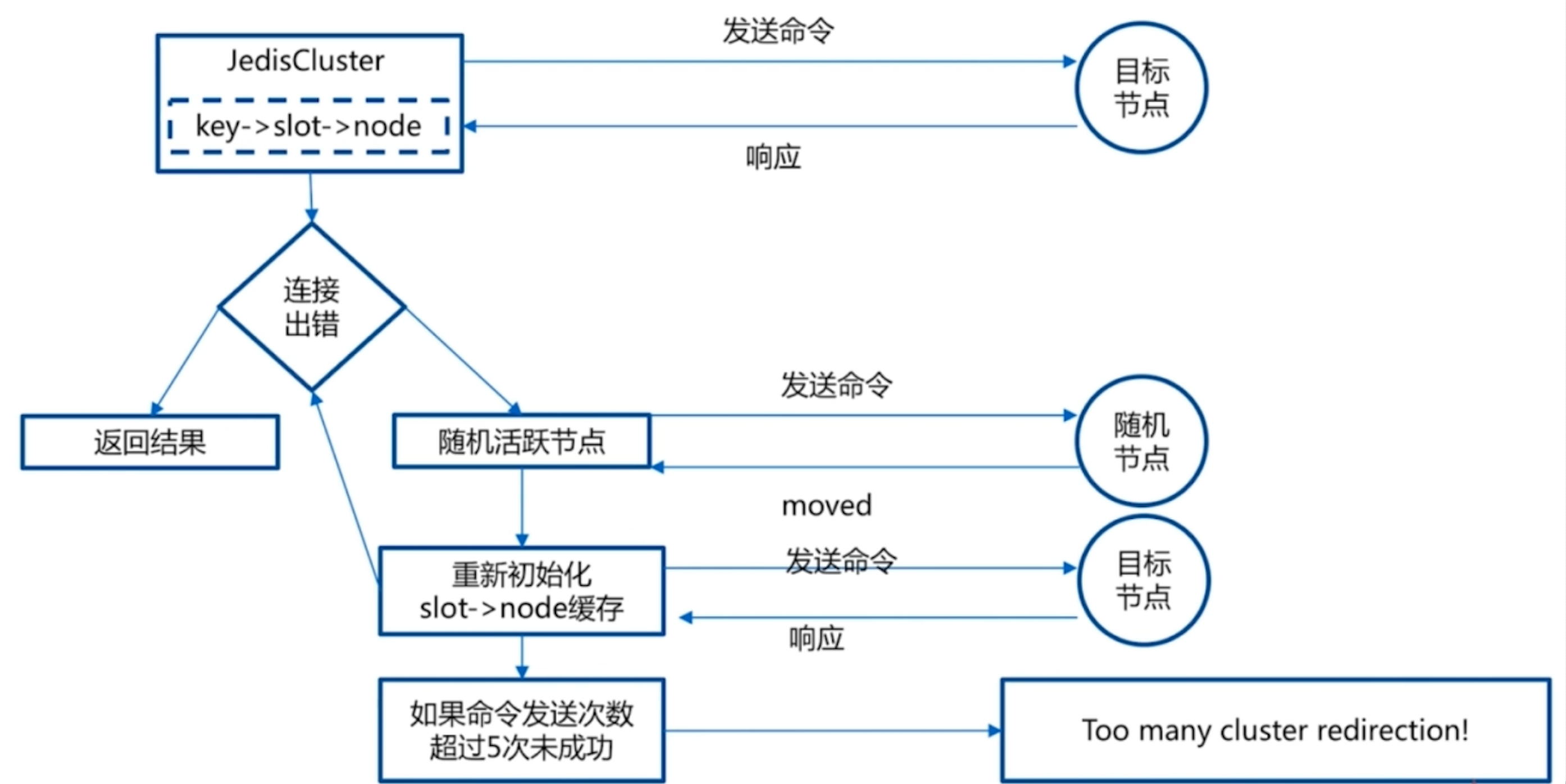
Failover
-
Fault finding:
-
Find by ping / pong
-
Subjective findings:
-
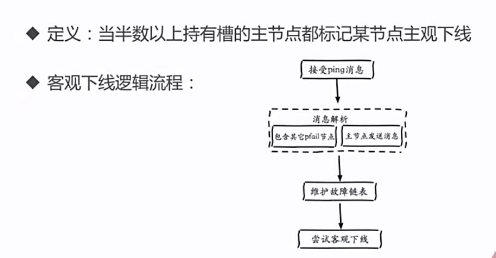
Objective offline:
When more than half of the master nodes holding slots mark a node as offline
-
-
Fault recovery
- Qualification examination
- Time to prepare for election
- Election voting
Development, operation and maintenance FAQs
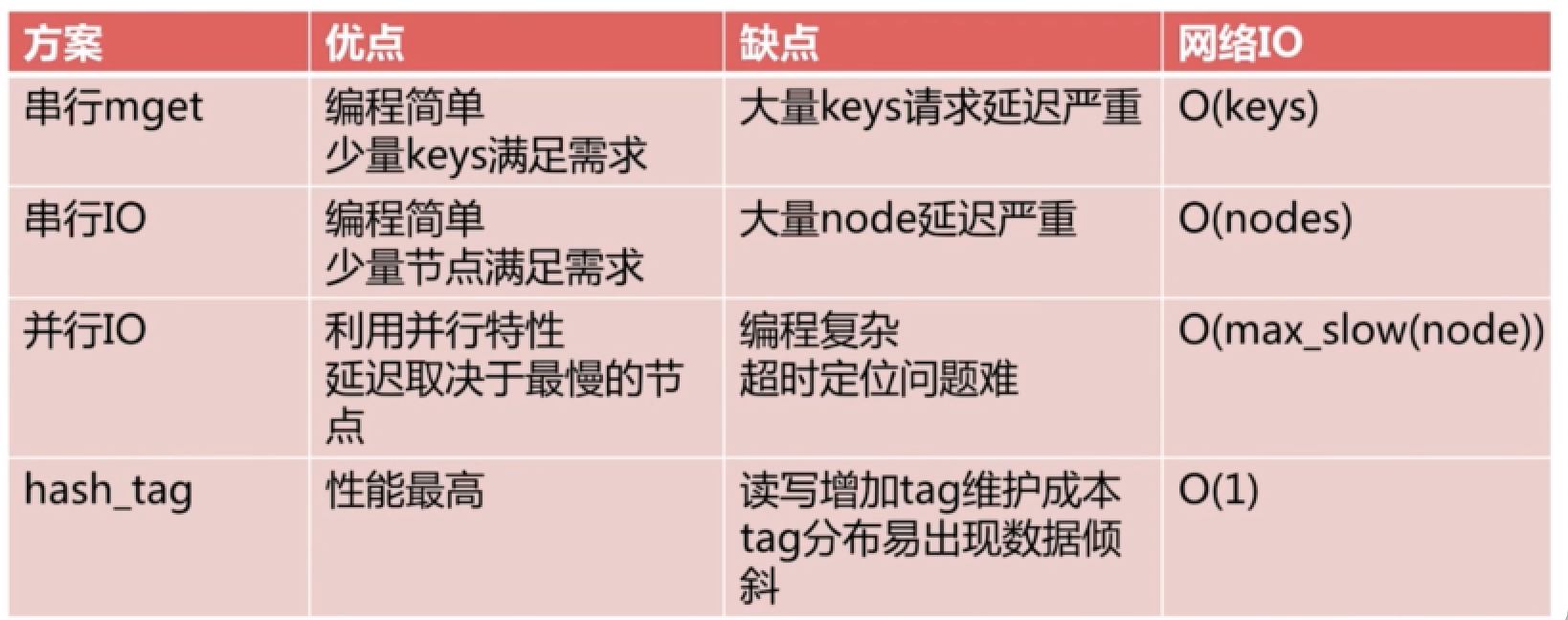
- Batch operation mget mset must be on a slot
- Serial mget (for loops come one by one)
- Serial IO (client coheres packets first and then goes to pipline)
- Parallel IO (multithreading occurs when the client first gathers packets and then goes to pipline)
- hash_tag (hash all key s to one node)
- Avoid using large clusters. Large businesses can use multiple clusters
- Cluster node timeout: balance of bandwidth and failover speed
- A separate set of clusters is recommended for publishing and subscribing, because it will broadcast at each node, which will increase the bandwidth
- Inconsistent memory configuration: hash Max ziplist value; Set Max intset entries, etc
- Do not use hash for hotspot key s_ tag; Or use a local cache
- The slave node under the cluster cannot write or read, and will jump to the master node
- Official data migration is not recommended. Redis migrate tool is recommended; redis-port
| Cluster vs single machine |
|---|
| The batch operation of key must be in one slot |
| The key transaction and the key supported by Lua are on the same node |
| key is the minimum granularity of data partition |
| Multiple databases are not supported |
| Replication can only copy one layer |
cache
Gain and loss
| benefit | cost | Usage scenario |
|---|---|---|
| Accelerated reading and writing | Data inconsistency is related to the update policy | Reduce high consumption SQL |
| Reduce back-end load | Code maintenance cost | Accelerated response time |
| ... | Operation and maintenance cost | Merge bulk writes into bulk writes |
Cache update policy
| strategy | uniformity | Maintenance cost |
|---|---|---|
| LRU/LFU/FIFO algorithm elimination: for example, maxmemory policy | worst | bottom |
| Timeout elimination: for example, expire | Poor | bottom |
| Active update: development control lifecycle | strong | high |
- Low consistency: maximum memory and obsolescence strategy
- High consistency: combination of timeout elimination and active update, maximum memory and elimination
Cache granularity control
- Generality: the total attribute is better
- Occupied space: some properties are better
- Code maintenance: on the surface, the total attribute is better
Cache penetration problem
The cached key does not exist, and a large amount of traffic hits the storage layer
- Business code problem
- Malicious attacks, reptiles
Discovery: business time, business logic, related indicators
solve:
- Cache empty object: if the cache does not exist, the key in the cache will be null
- Bloom filter interception
Cache avalanche
The cache crashed, and a large amount of traffic hit the storage layer. When designing, the storage layer is a small traffic, resulting in cascading failure
- Ensure high availability of mixed storage
- The dependent isolation component is the back-end current limiting component
- Advance drill: stress test
Optimization of bottomless hole problem
The performance of "adding machines" does not improve, but decreases. There are more nodes, and the IO(node) is higher and higher
- Naming itself optimization
- Reduce network communication times
- Reduce access costs
Hot key reconstruction optimization
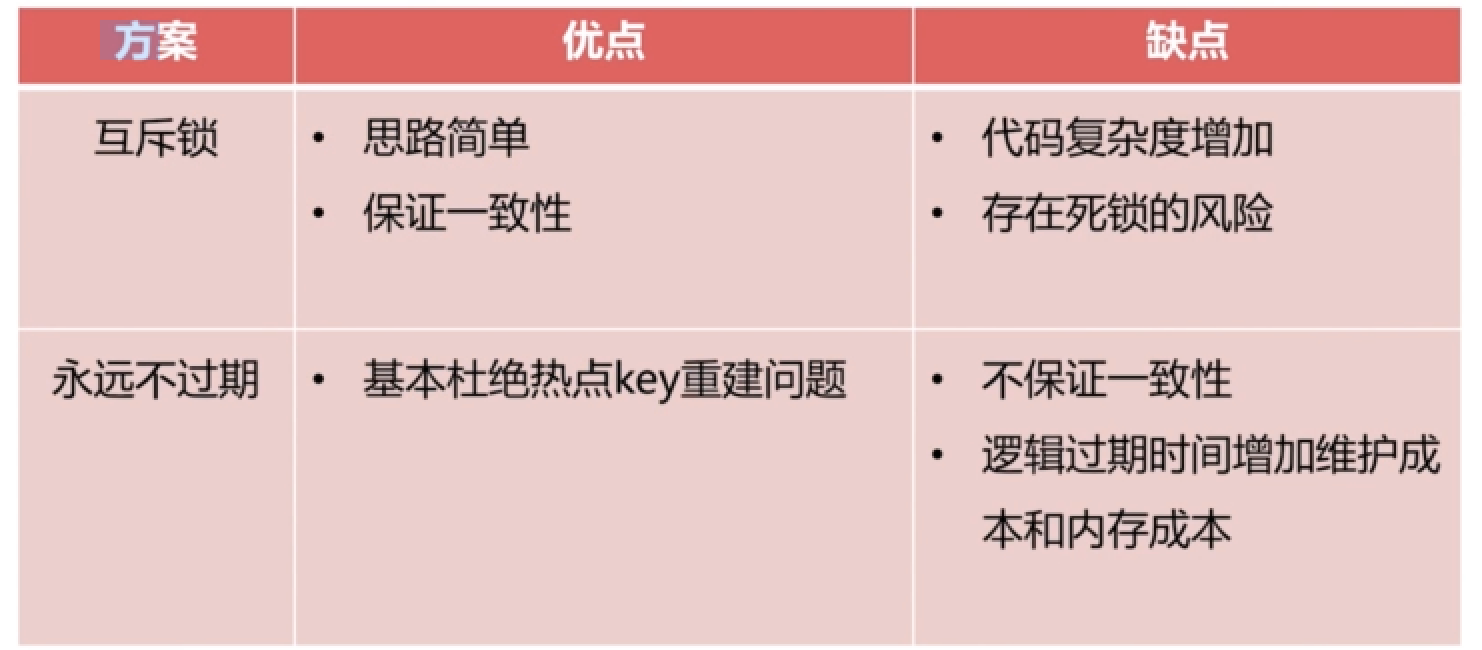
Hot key + a long reconstruction time. When concurrent, a large number of threads will not hit during the reconstruction time, resulting in reconstruction.
- Reduce the number of re caches
- The data shall be consistent as much as possible
- Reduce potential risks
- mutex
- Never expire, logic to solve.
Redis cloud platform CacheCloud
Open source address: https://github.com/sohutv/cachecloud
- One click Redis
- Monitoring and alarm
- Client: transparent use, performance reporting
- Visual operation and maintenance: configuration, capacity expansion, etc
- Existing Redis direct access and migration
Redis bloom filter
Basic:
Reference link: https://juejin.cn/post/6844904134894698510
Question: if there are 5 billion phone numbers, how to judge that 100000 phone numbers already exist?
Principle: a very long binary vector and several hash functions are mapped through hash. If they are all 1, they exist
Probability that the error is set to 1: 1 - (1 - 1/m)^nk (m vectors, n data, k hash functions)
Compared with local filters, Redis based Bloom filters can be synchronized and have large capacity
Every language has its own way of writing, but the general idea is the same.
Investigation, design and Go implementation of Bloom filter https://juejin.cn/post/6863059963145617416
Distributed bloom filter
- Multiple Bloom filters
- Improving efficiency based on pipeline
Redis development specification
Key value design
-
key name design
-
Readability and manageability, such as business name: Table Name: id
-
The concise line controls the length of the key
-
Does not contain special characters
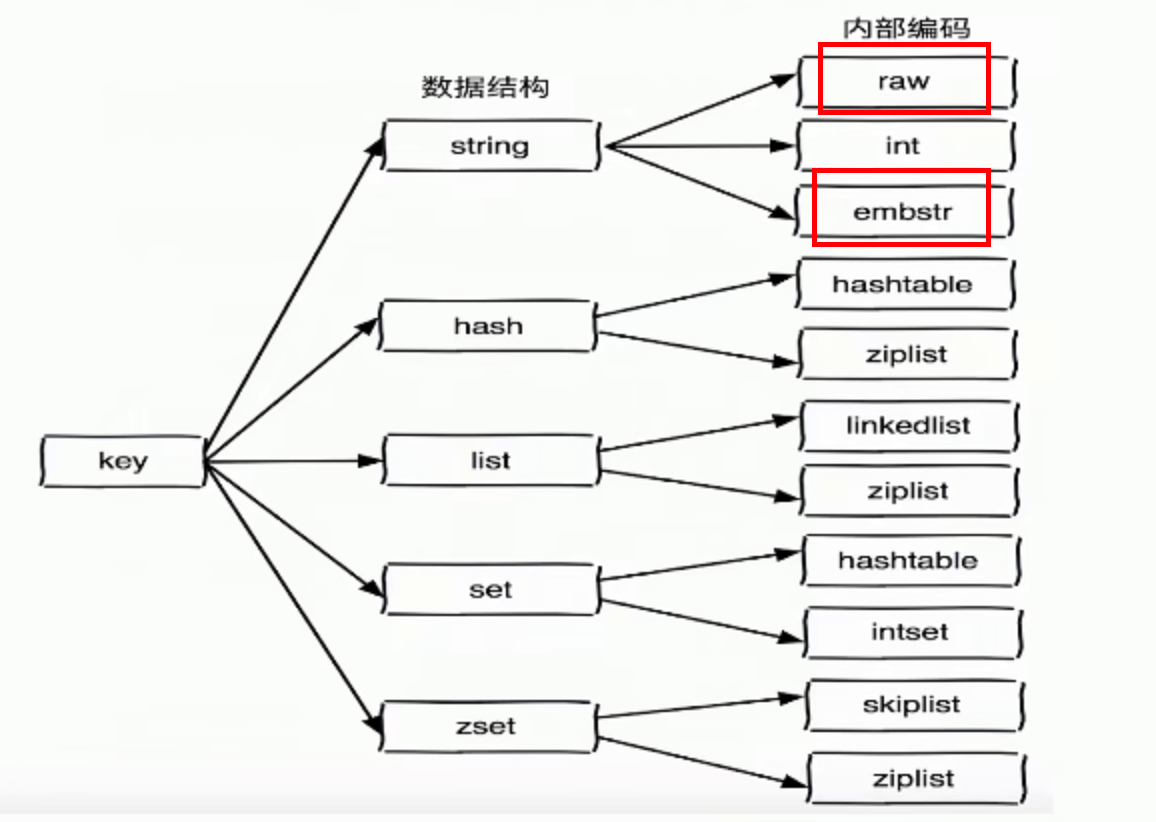
The short string is embstr (< = 39) and the long string is raw. Limiting the length will save memory
-
-
value design
-
Refuse bigkey. Redis cli -- bigkeys / debug object key, etc. are officially provided
-
Select the appropriate data structure
For example, now record what pictures someone sent
- Scheme 1: set key value
- Scheme 2: hset allPics picId userId
- Scheme 3: hset picId/100 picID%100 userId
-
-
Expiration time management
- Don't put everything in the trash can and remember to set the expiration time
- The expiration time should not be centralized
Discover and delete Bigkey
- Redis cli -- bigkeys, but the size cannot be limited
- The debug object key may be blocked. You can query it with the commands of len, zcard, scard, HLEN, etc
- Active alarm sends an alarm when it is detected that it is greater than the alarm value
- Blocking: deleting Bigkey will be particularly slow. Pay attention to implicit deletion
- Reids4.0 lazy delete background delete
Naming tips
- O(N) the above command focuses on the number of N. For traversal requirements, hscan, sscan and zscan can can be used instead
- Disable commands: key *, flush, etc
- Rational use of select
- Redis transaction function is weak
- There are special requirements for reusing the Redis cluster version on Lua
- If necessary, use the monitor command. It is recommended not to use it for a long time
Client optimization
- Avoid multiple applications using one Redis instance: business splitting that they don't want to do, and service public data.
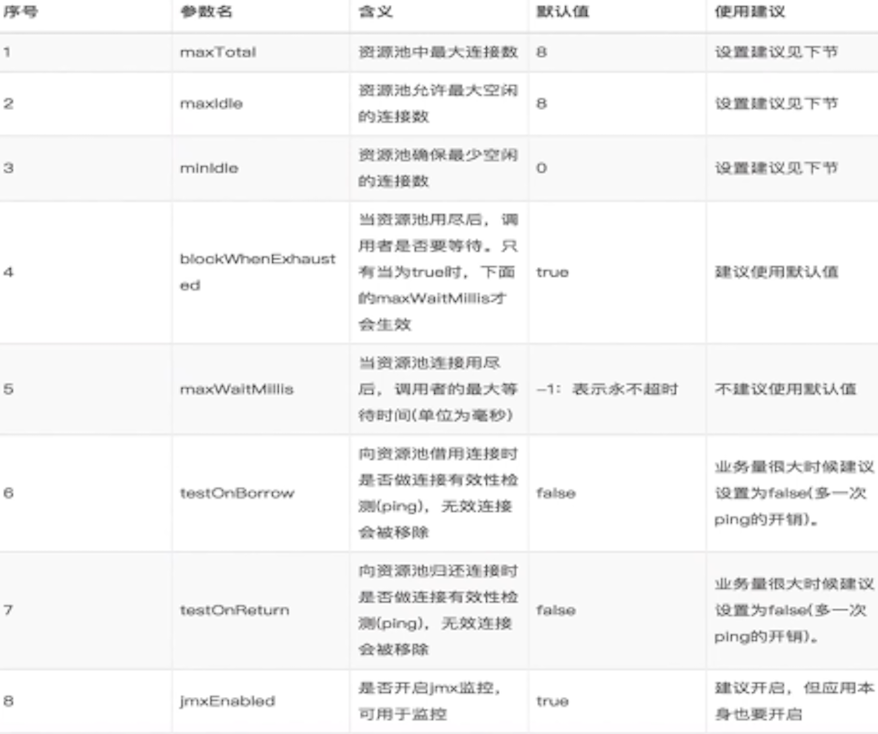
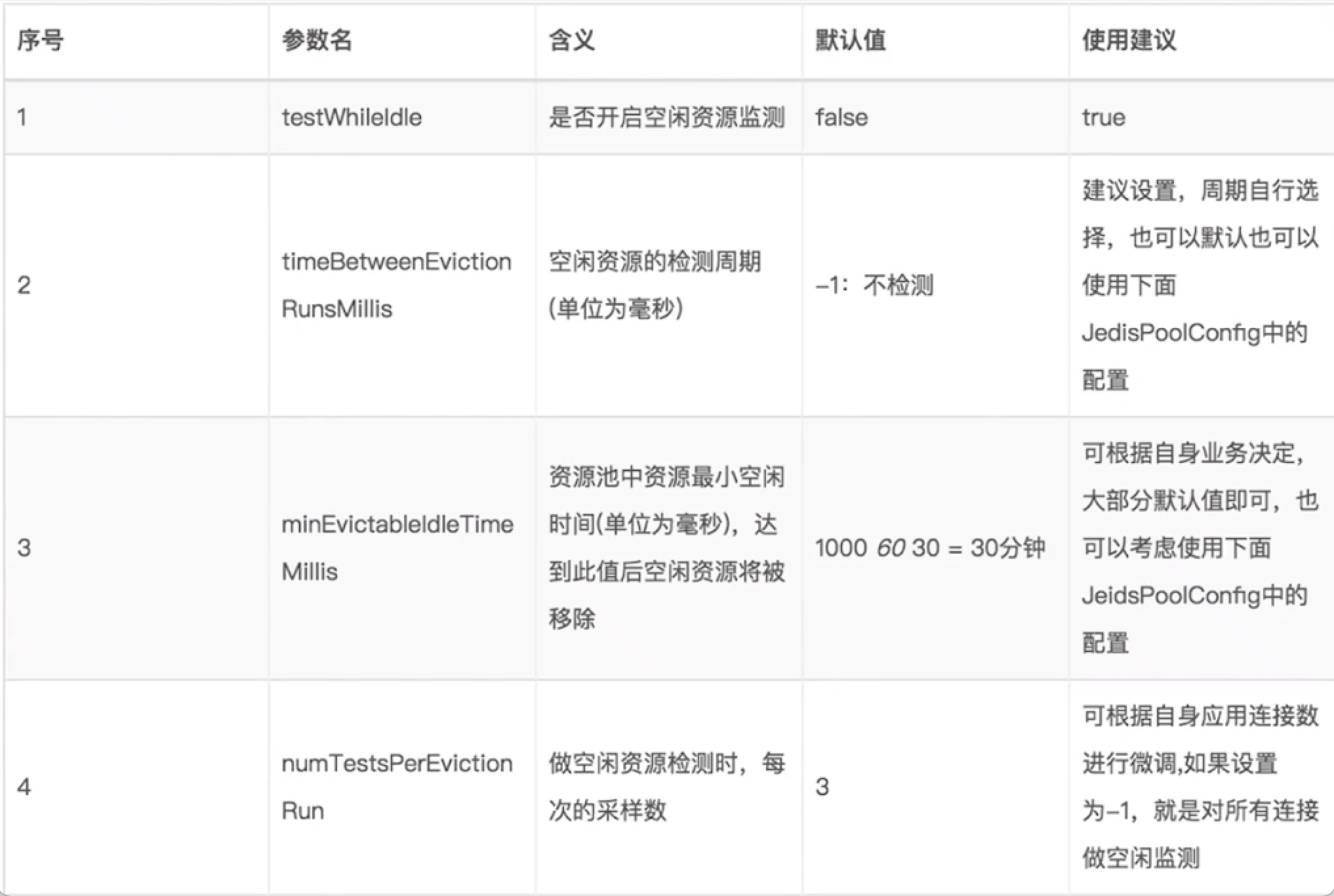
- Use connection pool
- maxTotal is close to maxIdle: IDS concurrency and client execution time (QPS / average time)
Redis memory optimization
View memory
Execute info merge

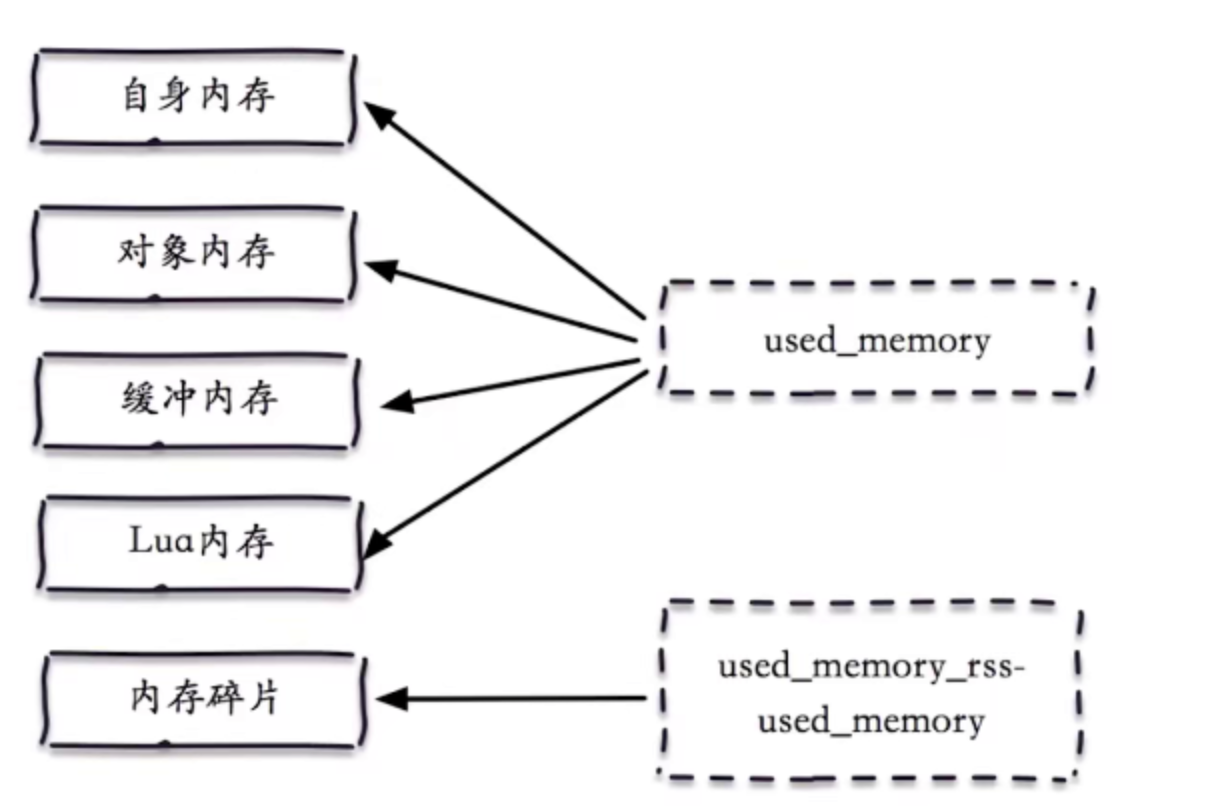
Individual memory buffers
- Client buffer
- Output buffer
- Ordinary client
- slave client
- pubsub client
- Input buffer

- Buffer memory
- Object memory

- Memory fragmentation

- Subprocess

memory management
- Set upper memory limit
$ config set maxmemory 4g $ config rewrite
- Memory reclamation policy
- Processing of expired keys
- Inert deletion
- Scheduled deletion
- Maxmemory police to control the policy after memory overrun
- Noeviction
- Volatile-lru
- Allkeys-random
- volatile-random
- volatile-ttl
- Processing of expired keys
Memory optimization
- Select a reasonable data structure (for object memory)
- Client optimization (there was a memory explosion)

Redis develops some pits
Kernel optimization

- For VM overcommit_ memory


-
Redis sets a reasonable maxmemory to ensure that the machine has 20% ~ 30% idle memory.
-
Centralized management of AOF rewriting and bgsave of RDB.
-
Set VM overcommit_ Memory = 1 to prevent fork failure caused by extreme conditions.
- For swappiness
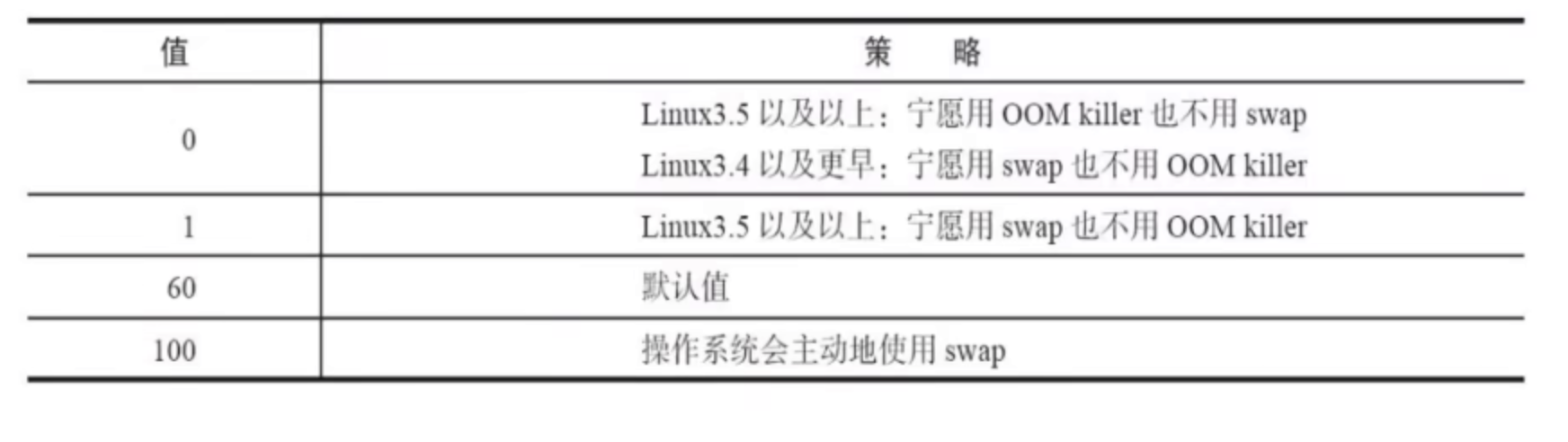

- For THP

- For OOM killer

- NTP synchronization time
- ulimit

- TCP-backlog

Secure Redis
- Characteristics of being attacked
- External IP exists
- Default port
- Boot as root
- No password set
- bind is set to 0.0.0.0
- Seven rules of safety
- Set password
- Camouflage danger command
- bind restricted network card
- firewall
- Regular backup
- Do not use default port
- Started by a non root user
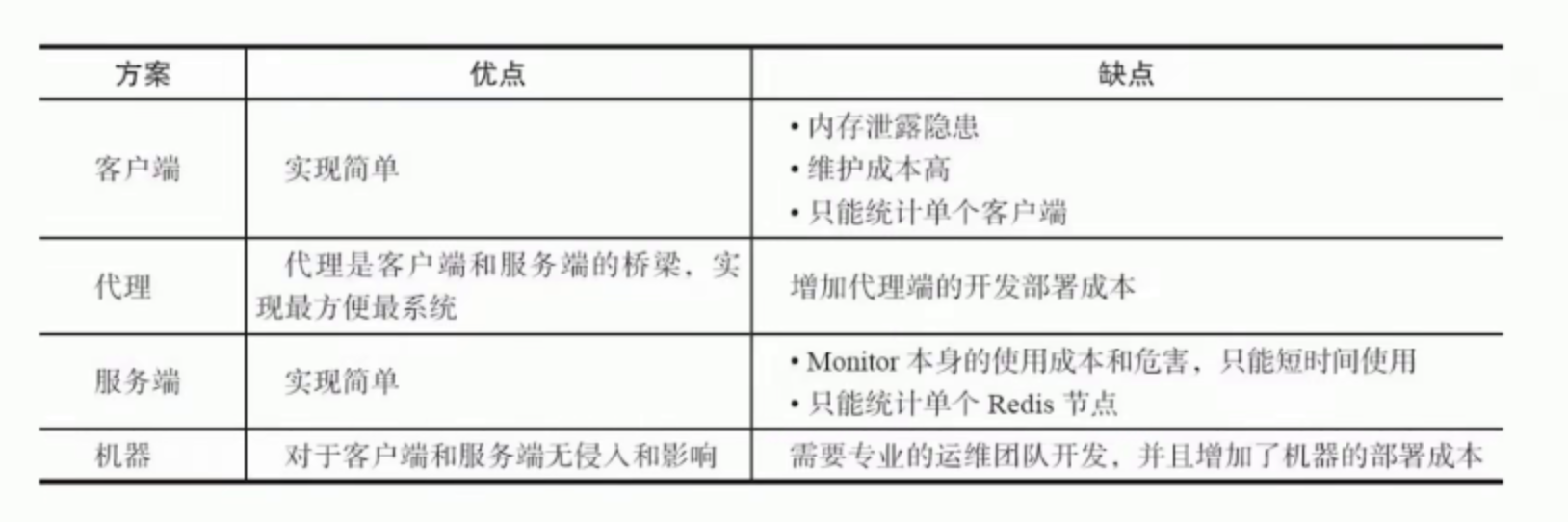
Hotspot Key
- Client discovery: client records, but not recommended
- Agent: agent full increment statistics
- Server: analyze monitor output statistics
- Machine side: grab Redis TCP data statistics