1, Multilevel cache architecture
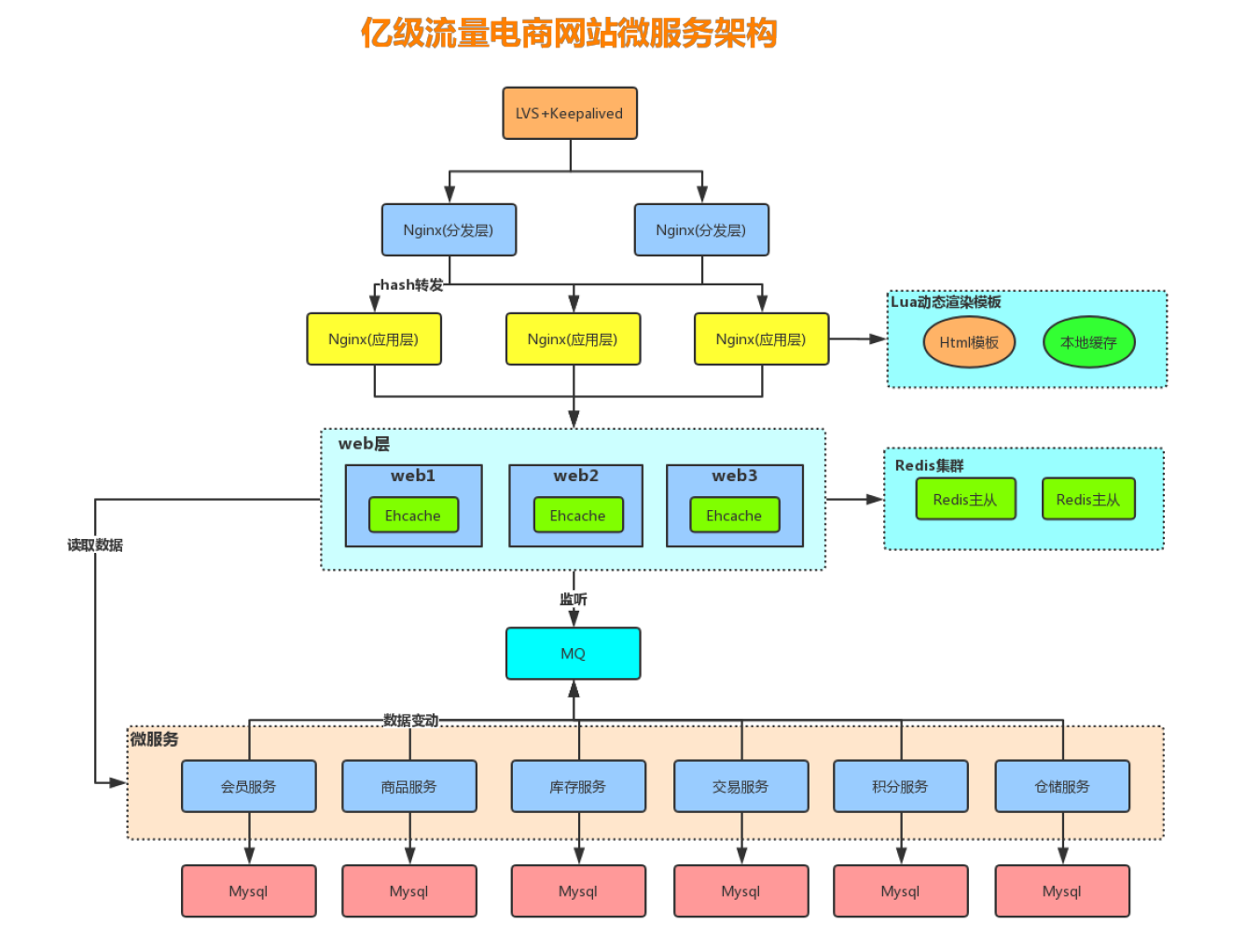
2, Cache design
1. Cache penetration
Cache penetration refers to querying a data that does not exist at all, and neither the cache layer nor the storage layer will hit. Generally, for the sake of fault tolerance, if the data cannot be found from the storage layer, it will not be written to the cache layer.
Cache penetration will cause nonexistent data to be queried in the storage layer every request, losing the significance of cache protection for back-end storage.
There are two basic reasons for cache penetration:
1. Problems with its own business code or data;
2. Some malicious attacks and crawlers cause a large number of empty hits.
Solution to cache penetration problem
1. Cache empty objects
String get(String key) {
// Get data from cache
String cacheValue = cache.get(key);
// Cache is empty
if (StringUtils.isBlank(cacheValue)) {
// Get from storage
String storageValue = storage.get(key);
cache.set(key, storageValue);
// If the stored data is empty, you need to set an expiration time (300 seconds)
if (storageValue == null) {
cache.expire(key, 60 * 5);
}
return storageValue;
} else {
// Cache is not empty
return cacheValue;
}
}
2. Bloom filter
For malicious attacks, the cache penetration caused by requesting a large amount of nonexistent data from the server can also be filtered first with the bloom filter. For nonexistent data, the bloom filter can generally be filtered out to prevent the request from being sent to the back end. When the bloom filter says that a value exists, the value may not exist; When it says it doesn't exist, it certainly doesn't exist.
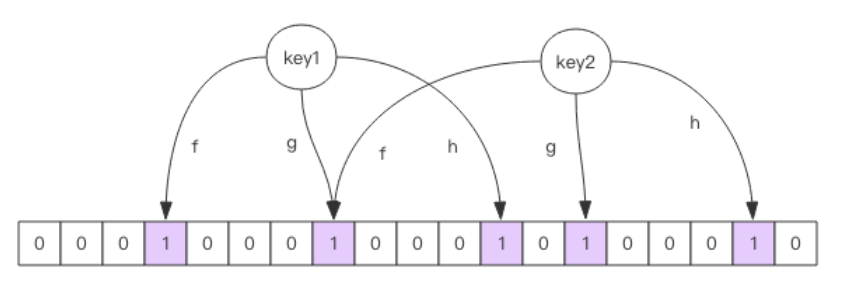
Bloom filter is a large set of bits and several different unbiased hash functions. Unbiased means that the hash value of an element can be calculated evenly.
When adding a key to the bloom filter, multiple hash functions will be used to hash the key to obtain an integer index value, and then modulo the length of the bit array to obtain a position. Each hash function will calculate a different position. Then set these positions of the digit group to 1 to complete the add operation.
When you ask the bloom filter whether a key exists, just like add, you will calculate several positions of the hash to see whether these positions in the bit group are all 1. As long as one bit is 0, it means that the key in the bloom filter does not exist. If they are all 1, this does not mean that the key must exist, but it is very likely to exist, because these bits are set to 1, which may be caused by the existence of other keys. If the digit group is sparse, the probability will be large. If the digit group is crowded, the probability will be reduced.
This method is suitable for application scenarios with low data hit, relatively fixed data and low real-time performance (usually with large data sets). Code maintenance is complex, but the cache space takes up little.
redisson can be used to implement bloom filter and introduce dependency:
<dependency> <groupId>org.redisson</groupId> <artifactId>redisson</artifactId> <version>3.6.5</version> </dependency>
Example pseudocode:
package com.jihu.redis.redisson.bloomFilter;
import org.redisson.Redisson;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
public class RedissionBloomFilter {
public static void main(String[] args) {
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.131.171:6380");
// Construct Redisson
RedissonClient redisson = Redisson.create(config);
RBloomFilter<Object> bloomFilter = redisson.getBloomFilter("nameList");
// Initialize bloom filter: it is estimated that the element is 100000000L and the error rate is 3%. The size of the underlying bit array will be calculated according to these two parameters
bloomFilter.tryInit(100000000L, 0.03);
// Insert xiaoyan into the bloom filter
bloomFilter.add("xiaoyan");
// Determine whether the following users are in the bloom filter
System.out.println(bloomFilter.contains("jihu")); // false
System.out.println(bloomFilter.contains("xuner")); // false
System.out.println(bloomFilter.contains("xiaoyan")); // true
}
}
View results:
18:04:45.087 [redisson-netty-1-1] DEBUG org.redisson.command.CommandAsyncService - connection released for command null and params null from slot null using connection RedisConnection@1310301061 [redisClient=[addr=redis://192.168.131.171:6380], channel=[id: 0x02a5d42b, L:/192.168.131.1:8111 - R:/192.168.131.171:6380]] false 18:04:45.091 [redisson-netty-1-3] DEBUG org.redisson.command.CommandAsyncService - connection released for command null and params null from slot null using connection RedisConnection@85296485 [redisClient=[addr=redis://192.168.131.171:6380], channel=[id: 0x6cb143ed, L:/192.168.131.1:8112 - R:/192.168.131.171:6380]] false 18:04:45.098 [redisson-netty-1-6] DEBUG org.redisson.command.CommandAsyncService - connection released for command null and params null from slot null using connection RedisConnection@36085293 [redisClient=[addr=redis://192.168.131.171:6380], channel=[id: 0x15024e01, L:/192.168.131.1:8119 - R:/192.168.131.171:6380]] true
To use bloom filter, you need to put all data into bloom filter in advance, and put it into bloom filter when adding data. Bloom filter caches and filters pseudo code:
//Initialize bloom filter
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("nameList");
//Initialize bloom filter: the expected element is 100000000L, and the error rate is 3%
bloomFilter.tryInit(100000000L, 0.03);
//Store all the data into the bloom filter
void init(){
for (String key: keys) {
bloomFilter.put(key);
}
}
String get(String key) {
// Judge whether the key exists from the level cache of Bloom filter
Boolean exist = bloomFilter.contains(key);
if(!exist){
return "";
}
// Get data from cache
String cacheValue = cache.get(key);
// Cache is empty
if (StringUtils.isBlank(cacheValue)) {
// Get from storage
String storageValue = storage.get(key);
cache.set(key, storageValue);
// If the stored data is empty, you need to set an expiration time (300 seconds)
if (storageValue == null) {
cache.expire(key, 60 * 5);
}
return storageValue;
} else {
// Cache is not empty
return cacheValue;
}
}
2. Cache failure (breakdown)
The failure of mass cache at the same time may lead to a large number of requests penetrating the cache to the database at the same time, which may cause the database to be under excessive pressure or even hang up. In this case, when we increase the cache in batch, we'd better set the cache expiration time of this batch of data to different times in a time period.
Example pseudocode:
String get(String key) {
// Get data from cache
String cacheValue = cache.get(key);
// Cache is empty
if (StringUtils.isBlank(cacheValue)) {
// Get from storage
String storageValue = storage.get(key);
cache.set(key, storageValue);
//Set an expiration time (a random number between 300 and 600)
int expireTime = new Random().nextInt(300) + 300;
if (storageValue == null) {
cache.expire(key, expireTime);
}
return storageValue;
} else {
// Cache is not empty
return cacheValue;
}
}
// Method 1:
public synchronized List<String> getData01() {
List<String> result = new ArrayList<String>();
// Read data from cache
result = getDataFromCache();
if (result.isEmpty()) {
// Query data from database
result = getDataFromDB();
// Write the queried data to the cache
setDataToCache(result);
}
return result;
}
This method can indeed prevent high concurrency to the database when the cache fails, but when the cache does not fail, you need to queue up to get locks when getting data from the cache, which will greatly reduce the throughput of the system
Solution 2:
static Object lock = new Object();
public List<String> getData02() {
List<String> result = new ArrayList<String>();
// Read data from cache
result = getDataFromCache();
if (result.isEmpty()) {
synchronized (lock) {
// Query data from database
result = getDataFromDB();
// Write the queried data to the cache
setDataToCache(result);
}
}
return result;
}
In this method, the system throughput will not be affected when the cache hits, but when the cache fails, the request will still hit the database, but it is blocked instead of high concurrency However, this will result in poor user experience and additional pressure on the database
Solution 3: public List<String> getData03() {
List<String> result = new ArrayList<String>();
// Read data from cache
result = getDataFromCache();
if (result.isEmpty()) {
synchronized (lock) {
//Double judgment, the second and subsequent requests do not have to go to the database and directly hit the cache
// Query cache
result = getDataFromCache();
if (result.isEmpty()) {
// Query data from database
result = getDataFromDB();
// Write the queried data to the cache
setDataToCache(result);
}
}
}
return result;
}
Although double judgment can prevent highly concurrent requests from hitting the database, the second and subsequent requests are still queued when they hit the cache For example, when 30 requests are concurrent together, in the case of double judgment, the first request goes to the database to query and update the cached data, and the remaining 29 requests are queued to fetch data from the cache in turn The experience of users whose requests are ranked behind will be bad
Solution 4:
static Lock reenLock = new ReentrantLock();
public List<String> getData04() throws InterruptedException {
List<String> result = new ArrayList<String>();
// Read data from cache
result = getDataFromCache();
if (result.isEmpty()) {
if (reenLock.tryLock()) { // If it is distributed, redisson distributed lock should be used
try {
System.out.println("I got the lock,from DB Write cache after getting database");
// Query data from database
result = getDataFromDB();
// Write the queried data to the cache
setDataToCache(result);
} finally {
reenLock.unlock();// Release lock
}
} else {
result = getDataFromCache();// Check the cache first
if (result.isEmpty()) {
System.out.println("I didn't get the lock,There is no data in the cache,Take a nap first");
// You can spin or sleep here
Thread.sleep(100);// Take a nap
return getData04();// retry
}
}
}
return result;
}
Finally, the use of mutual exclusion lock can effectively avoid the previous problems
Of course, in the actual distributed scenario, we can also use distributed locks provided by redis, tail, zookeeper, etc However, if our concurrency is only a few thousand, why kill a chicken?