This article is transferred from: Le byte
This article mainly explains: Redis
For more Java related information, you can pay attention to the official account number: 999
Cache cache
Cache concept
A cache is a replica set of original data stored on a computer for easy access.
Common caching scenarios for Web projects
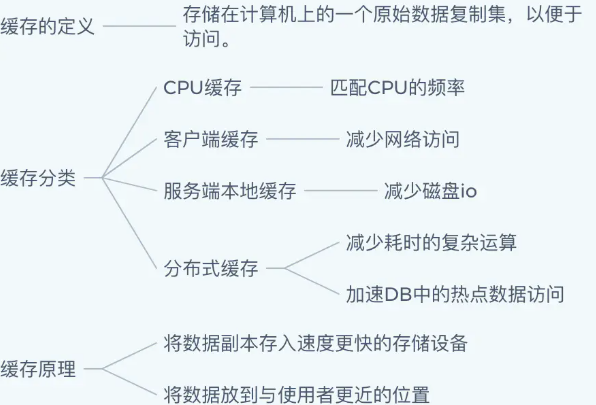
Buffer breakdown
Concept:
- For some keys with expiration time set, if these keys may be accessed at some time points, they are very "hot" data
reason:
- When the cache expires at a certain time point, there are a large number of concurrent requests for the key at this time point. The key fails to hit, and a large number of requests penetrate to the database server
Solution:
- For hotspot data, carefully consider the expiration time to ensure that the key will not expire during the hotspot period. Some can even be set never to expire.
- Using a mutex lock (such as Java's multi-threaded lock mechanism), the first thread will lock the key when it accesses it. After the query database returns, insert the value into the cache and release the lock
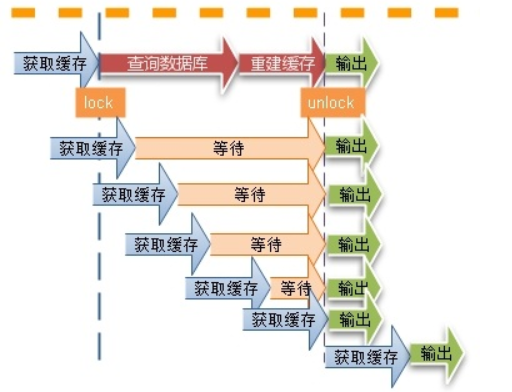
Cache avalanche
Concept:
- A large number of key s set the same expiration time, resulting in all caches failing at the same time, resulting in large instantaneous DB requests, sudden pressure increase and avalanche.
- If the cache server goes down, it can also be regarded as a cache avalanche.
- Cause: a large number of caches fail at the same time; A large number of requests fall on the backend DB;
Solution:
- Set different expiration times (random values) for different key s to make the time point of cache invalidation as uniform as possible;
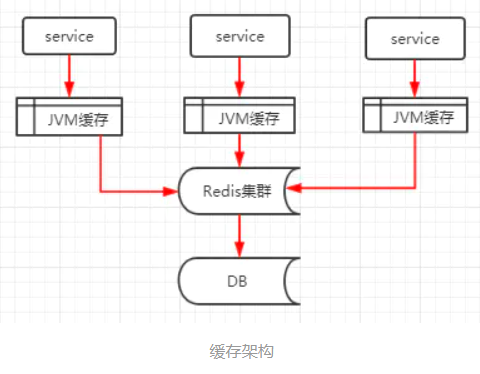
High availability distributed cache cluster is used to ensure high availability of cache
- For L2 cache, A1 is the original cache and A2 is the copy cache. When A1 fails, A2 can be accessed.
Cache penetration
Concept:
- If you access a key that must not exist, the cache will not work, and the request will penetrate into the DB. When the traffic is large, the DB will hang up
- Reason: the key is accessed with high concurrency; If the key fails to hit, go to the backend DB to get it; A large number of requests penetrate the database server
Solution:
Bloom filter,
- Use a large enough bitmap to store the keys that may be accessed. The nonexistent keys are directly filtered to avoid pressure on the underlying data storage system;
- If the value of the access key is not found in the DB, the null value can also be written into the cache, but a shorter expiration time can be set
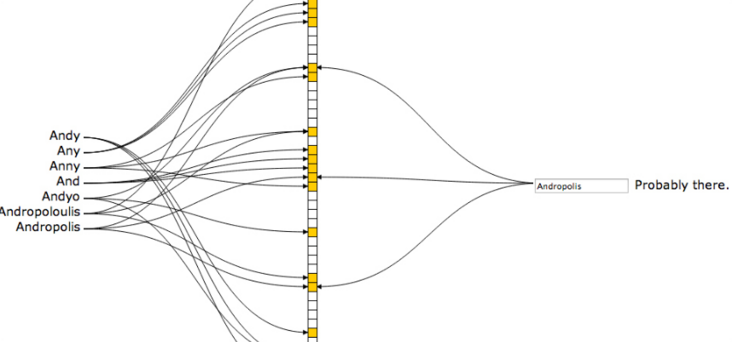
Cache consistency
Concept:
- When the data timeliness requirements are very high, it is necessary to ensure that the data in the cache is consistent with that in the database, and that the data in the cache node and the replica are consistent without differences. (cluster synchronization)
reason:
- When reading and writing the same data, concurrent reading and writing at the database level cannot guarantee the completion order;
- Write request A occurs, and the cache is eliminated in the first step of A; The second step of A is to write the database and send A modification request;
- A read request B occurs. In the first step, B reads the cache and finds that the cache is empty; The second step of B reads the database and sends a read request,
- If the second step of writing data of A has not been completed, A dirty data is read out and put into the cache;
Solution:
- Generally, when the data changes, it will actively update the data in the cache or remove the corresponding cache.
Introduction to Redis

Official website
Introduction to Redis
Redis is an open source (BSD licensed) in memory data structure storage system, which can be used as database, cache and message middleware. It supports many types of data structures, such as strings, hashes, lists, sets, sorted sets and range queries, bitmaps, hyperlogs and geospatial index radius queries. Redis has built-in replication, Lua scripting, LRU events, transactions and different levels of disk persistence, and provides high availability through redis Sentinel and Cluster
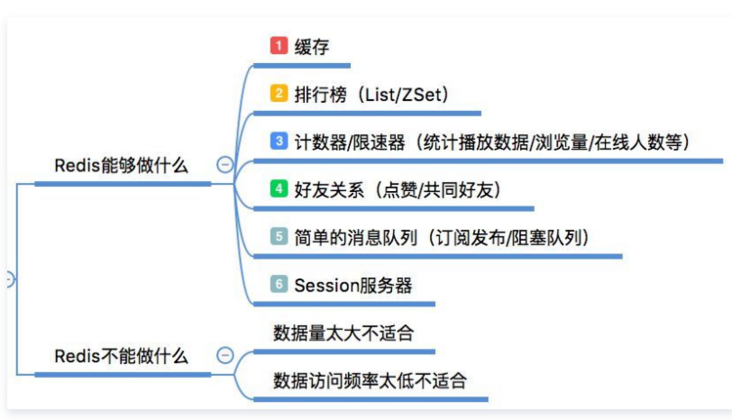
Redis performance
The following is the official benchmark data:
The test completed 50 concurrent execution of 100000 requests. The value set and obtained is a 256 byte string.
Results: the reading speed is 110000 times / s and the writing speed is 81000 times / s
Introduction to Redis history
In 2008, Salvatore Sanfilippo, founder of an Italian start-up company Merzia, customized a database to avoid the low performance of MySQL and developed it in 2009. This is Redis.
Since March 15, 2010, the development of Redis has been hosted by VMware.
Since May 2013, the development of Redis has been sponsored by pivot.
Description: Pivotal is a new company jointly established by EMC and VMware. Pivot hopes to provide a native foundation for a new generation of applications, based on the IT characteristics of leading cloud and network companies. Pivot's mission is to promote these innovations and provide them to enterprise IT architects and independent software providers.
Support language

Supported data types
string,hash,list,set,sorted set
Redis installation (SingleNode)
Installation dependency
yum -y install gcc-c++ autoconf automake

Download and upload

decompression
tar zxvf redis-5.0.3.tar.gz
Precompiling and installation
Switch to the decompression directory
cd redis-5.0.3/ ## Compile source code make MALLOC=libc ## Create redis installation directory mkdir -p /opt/lzj/redis ## If you need to specify the installation path, you need to add the PREFIX parameter** make PREFIX=/opt/lzj/redis/ install
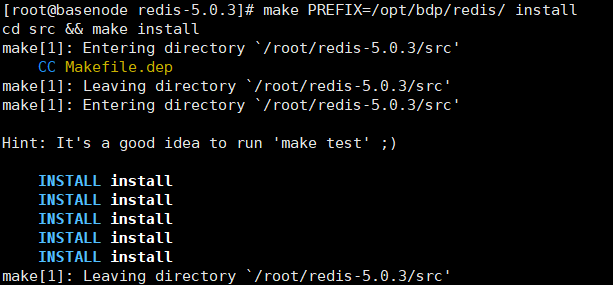

Redis cli: client
Redis server: server side
Foreground start
##The default port number of redis service is 6379 ./redis-server
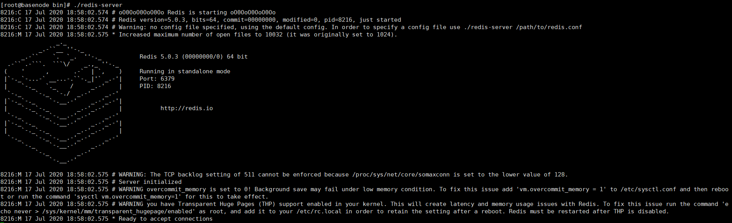
Background start
Copy redis.conf to the installation path
## Create a profile directory mkdir -p /opt/lzj/redis/conf ## Copy configuration file to directory
Modify redis.conf under the installation path and modify the daemon to yes

When starting, specify the configuration file path

windows client access
Install Redis client

Modify the configuration file redis.conf
Note that bind 127.0.0.1 can enable all ip accesses to redis. If you want to specify multiple ip accesses but not all ip accesses, you can set bind

Turn off the protection mode and change it to no

Add access authentication
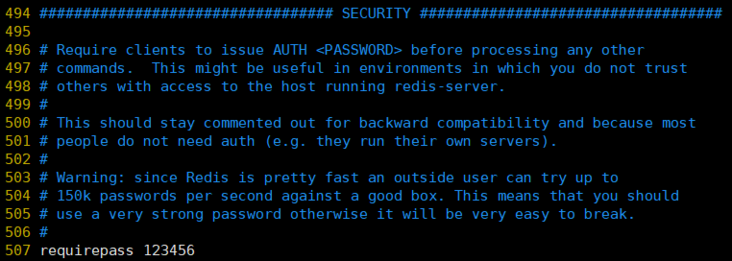
We can modify the number of default databases, which is 16 by default, and modify database 32, which is 32 by default

After modification, kill -9 XXXX kills the redis process and restarts redis

Establish connection again - > success
<img src="https://i0.hdslb.com/bfs/album/ac98020a966ed38c74b3d5e295efa5d46e59c7aa.png" alt="image-20200717111412879" style="zoom: 80%;" />
Redis command
Redis cli connection
-h: Used to specify the ip address
-p: Used to specify the port
-a: Used to specify the authentication password

The PING command returns PONG

Specify database

Redis cli operation
Operation Key
Exists query whether the key exists
keys query whether the specified key exists
Type query the data type of the key
scan scans all key s in the current library
Operation String
set: add a String type data
Get: get a String type data
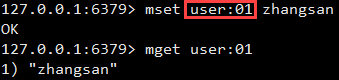
mset: add multiple String type data
mget: get multiple String type data
incr: add 1 to value
decr: subtract 1 from value

Operation hash
hset: add a hash type data
hget: get a hash type data
hmset: adding multiple hash type data
hmget: get multiple hash type data
hgetAll: get all hash type data specified
hdel: delete the specified hash type data (one or more)

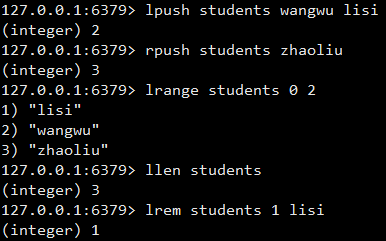
Operation list
lpush: add (header) list type data on the left
rpush: right add (tail) type data
lrange: get list type data start start subscript end end subscript inclusion relationship
llen: get the number of entries
lrem: delete several specified list type data in the list
lrem key count value count > 0 Delete from front to back count individual value count <0 Delete absolute values from back to front( count) individual value count = 0 Delete all value
Operation set
sadd: add set type data
smembers: get set type data
scard: get the number of entries
srem: delete data

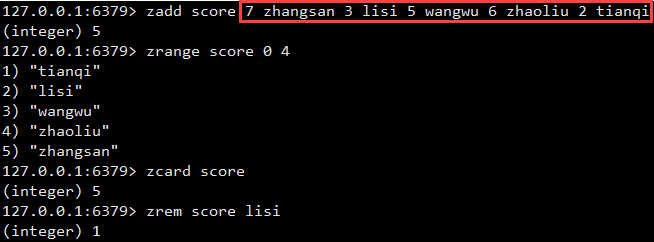
Operation sorted set
sorted set is sorted by fractional value. The larger the fractional value, the lower it is.
zadd: add sorted set type data
zrange: get sorted set type data
zcard: get the number of entries
zrem: delete data
zadd needs to place the Float or Double type fractional value parameter before the value parameter
Zscore|zincrby: zincrby key increment member is the score value of the member of the ordered set key plus increment
Action namespace

Operation failure time
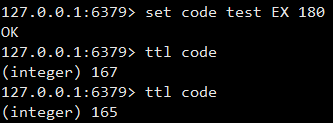
Redis has four different commands that can be used to set the key's lifetime (how long the key can exist) or expiration time (when the key will be deleted):
Explre < key > < ttl >: used to set the lifetime of the key to ttl seconds.
Pexpire < key > < ttl >: used to set the lifetime of key to ttl ` Ms.
Expireat < key > < timestamp >: used to set the expiration time of the key to the second timestamp specified by the timestamp.
Pexpireat < key > < timestamp >: used to set the expiration time of the key to the milliseconds timestamp specified by timestamp.
TTL: the value obtained is - 1, indicating that the validity period of this key is not set. When the value is - 2, it proves that the validity period has passed.
Method 1
Method 2
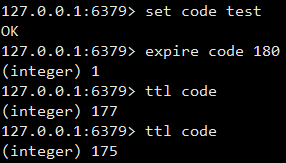
Method 3
First parameter: key
Second parameter: value
Third parameter:
NX is set only when the key does not exist to prevent overwriting
XX is set only when the key exists. No new key is created
The fourth parameter: EX is seconds and PX is milliseconds

delete
del: used to delete data (general, applicable to all data types)
hdel: used to delete hash type data

Redis transaction mechanism
Redis transaction is a separate isolation operation: all commands in the transaction will be serialized and executed sequentially. During the execution of the transaction, it will not be interrupted by command requests sent by other clients.
The main function of Redis transaction is to concatenate multiple commands to prevent other commands from jumping in the queueMulti,Exec,discard
- After entering the Multi command, the entered commands will enter the command queue in turn, but will not be executed,
- After entering Exec, Redis will execute the commands in the previous command queue in turn.
- In the process of team formation, you can give up team formation through discard

Error handling of transactions
- When an error is reported in a command in the queue forming stage, all queues in the whole queue will be cancelled when it is executed.
- If an error is reported in a command in the execution phase, only the error reported command will not be executed, while other commands will be executed and will not be rolled back.
Mechanism of transaction lock
- Pessimistic lock
- Optimistic lock
- Redis uses this check and set mechanism to implement transactions
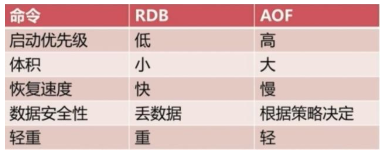
Data persistence
Redis is an in memory database. Data is stored in memory. Although the data in memory is fast to read, it is easy to lose. Redis also provides us with persistence mechanisms, namely RDB(Redis DataBase) and AOF(Append Only File)
RDB(Redis DataBase)
- RDB persistence can generate point in time snapshots of data sets within a specified time interval, which is the default persistence method
- This method is to write the data in memory to the binary file in the form of snapshot. The default file name is dump.rdb
RDB provides three trigger mechanisms: save, bgsave, and automation
save trigger mode
- This command will block the current Redis server. During the execution of the save command, Redis cannot process other commands until the RDB process is completed.
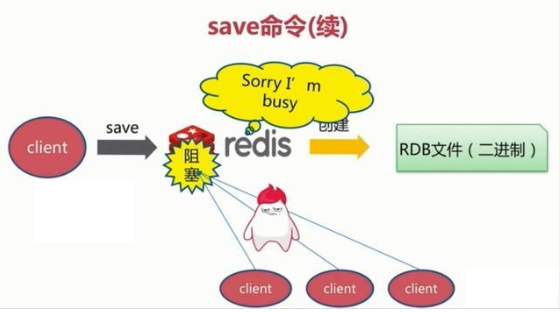
bgsave trigger mode
- When this command is executed, Redis will perform snapshot operations asynchronously in the background, and the snapshot can also respond to client requests.
- The Redis process performs a fork operation to create a child process. The RDB persistence process is in the charge of the child process and ends automatically after completion. Blocking only occurs in the fork phase and generally takes a short time.

Automatic trigger
- Automatic triggering is completed by our configuration file.
#configuration file # after 900 sec (15 min) if at least 1 key changed # after 300 sec (5 min) if at least 10 keys changed # after 60 sec if at least 10000 keys changed save 900 1 save 300 10 save 60 10000 #Meaning of configuration file The server made at least one modification to the database within 900 seconds The server made at least 10 modifications to the database within 300 seconds The server made at least 10000 modifications to the database within 60 seconds
- stop-writes-on-bgsave-error
# However if you have setup your proper monitoring of the Redis server # and persistence, you may want to disable this feature so that Redis will # continue to work as usual even if there are problems with disk, # permissions, and so forth. # The default value is yes. When RDB is enabled and the last background saving of data fails, does Redis stop receiving data. stop-writes-on-bgsave-error yes
- rdbcompression
# Compress string objects using LZF when dump .rdb databases? # For default that's set to 'yes' as it's almost always a win. # If you want to save some CPU in the saving child set it to 'no' but # the dataset will likely be bigger if you have compressible values or keys. # The default value is yes. For snapshots stored on disk, you can set whether to compress storage. rdbcompression yes
- rdbchecksum
# RDB files created with checksum disabled have a checksum of zero that will # tell the loading code to skip the check. # The default value is yes. After storing the snapshot, we can also let redis use the CRC64 algorithm for data verification, but doing so will increase the performance consumption by about 10% rdbchecksum yes
- dbfilename
# The filename where to dump the DB # Set the file name of the snapshot. The default is dump.rdb dbfilename dump.rdb
- dir
# The working directory. # The DB will be written inside this directory, with the filename specified # above using the 'dbfilename' configuration directive. # The Append Only File will also be created inside this directory. # Note that you must specify a directory here, not a file name. # Set the storage path of snapshot files. This configuration item must be a directory, not a file name dir ./
Advantages and disadvantages of RDB
Advantages:
- RDB files are compact and full backup, which is very suitable for backup and disaster recovery.
- When generating RDB files, the redis main process will fork() a sub process to handle all saving work. The main process does not need any disk IO operations
- RDB recovers large data sets faster than AOF.
inferiority
- When snapshot persistence is performed, a child process will be started to be specifically responsible for snapshot persistence, and the child process will have the memory data of the parent process,
- When the parent process modifies memory, the child process will not react,
- Therefore, the data modified during snapshot persistence will not be saved and data may be lost.
AOF(Append Only File)
- Full backup is always time-consuming. Sometimes we provide a more efficient way AOF. The working mechanism is very simple. redis will append each received write command to the file through the write function. The common understanding is logging.

rewrite policy
- Rewrite the log to reduce the size of the log file. redis provides the bgrewrite AOF command.
- Save the data in memory to the temporary file in the form of command, and a new process will fork out to rewrite the file.
- The contents of the database in the whole memory are rewritten into a new aof file by command

AOF configuration information
############################## APPEND ONLY MODE ############################### # By default Redis asynchronously dumps the dataset on disk. This mode is # good enough in many applications, but an issue with the Redis process or # a power outage may result into a few minutes of writes lost (depending on # the configured save points). # # The Append Only File is an alternative persistence mode that provides # much better durability. For instance using the default data fsync policy # (see later in the config file) Redis can lose just one second of writes in a # dramatic event like a server power outage, or a single write if something # wrong with the Redis process itself happens, but the operating system is # still running correctly. # # AOF and RDB persistence can be enabled at the same time without problems. # If the AOF is enabled on startup Redis will load the AOF, that is the file # with the better durability guarantees. appendonly no # The name of the append only file (default: "appendonly.aof") appendfilename "appendonly.aof"
# Redis supports three different modes: # no: don't fsync, just let the OS flush the data when it wants. Faster. # always: fsync after every write to the append only log. Slow, Safest. # everysec: fsync only one time every second. Compromise. # appendfsync always appendfsync everysec # appendfsync no
# Timing and condition of rewriting # Automatic rewrite of the append only file. # Redis is able to automatically rewrite the log file implicitly calling # BGREWRITEAOF when the AOF log size grows by the specified percentage. # # This is how it works: Redis remembers the size of the AOF file after the # latest rewrite (if no rewrite has happened since the restart, the size of # the AOF at startup is used). # # This base size is compared to the current size. If the current size is # bigger than the specified percentage, the rewrite is triggered. Also # you need to specify a minimal size for the AOF file to be rewritten, this # is useful to avoid rewriting the AOF file even if the percentage increase # is reached but it is still pretty small. # # Specify a percentage of zero in order to disable the automatic AOF # rewrite feature. auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb
Trigger strategy of AOF
Sync always every modification
- In synchronous persistence, every time a data change occurs, it will be immediately recorded to the disk. The performance is poor, but the data integrity is good
Sync everysec per second:
- Asynchronous operation, recorded every second. If it goes down within one second, data will be lost
Different no:
- Never sync
AOF strengths and weaknesses
advantage
- Aof can better protect data from loss. Generally, AOF will perform fsync operation through a background thread every 1 second, and the data will be lost for 1 second at most.
- AOF log files do not have any disk addressing overhead. The writing performance is very high, and the files are not easy to be damaged.
- Even if the AOF log file is too large, the background rewriting operation will not affect the reading and writing of the client.
- The commands of AOF log files are recorded in a very readable way. This feature is very suitable for emergency recovery of catastrophic accidental deletion.
inferiority
- For the same data, the AOF log file is usually larger than the RDB data snapshot file
The write QPS supported by AOF is lower than that supported by RDB
- QPS: Queries Per Second means "query rate per second"
- TPS: it is the abbreviation of TransactionsPerSecond, that is, the number of transactions / second
Selection of RDB and AOF
Adults do not do multiple-choice questions
- If both AOF and RDB are used, AOF is used as the template for recovering data at startup
- If you choose, the two together are better.
- Because you understand the two persistence mechanisms, the rest depends on your own needs. There are different choices for different needs, but they are usually used in combination
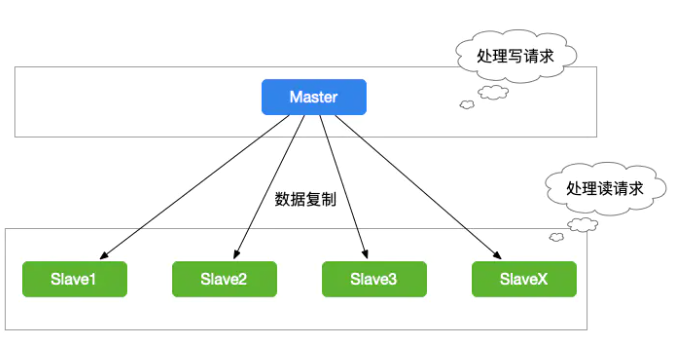
Master slave replication cluster
Although redis reads and writes very fast, it also has a very high reading pressure. In order to share the reading pressure, redis supports master-slave replication. The master-slave structure of redis can adopt one master-slave or multi-slave structure. Redis master-slave replication can be divided into full synchronization and incremental synchronization according to whether it is full or not.
Build master-slave server
- Create a profile in the Redis main profile folder
Master node profile
## Import a generic profile include /opt/lzj/redis/conf/redis.conf ## Current primary server port port 7100 ## Set master service password requirepass 123456 ## Current main service process ID pidfile /var/run/redis_7100.pid ## Current main service RDB file name dbfilename dump7100.rdb ## Current main service file storage path
Slave nodes need to be configured
- Add directly to the profile (permanent)
## Import a generic profile include /opt/lzj/redis/conf/redis.conf ## Current primary server port port 7200 ## Current main service process ID pidfile /var/run/redis_7200.pid ## Current main service RDB file name dbfilename dump7200.rdb ## Current main service file storage path dir /opt/lzj/redis/conf/ ## Synchronize the network information of the master node (slaveof must be used for the lower version, and replica of is recommended for the higher version) replicaof 127.0.0.1 7100 ## Set the password information of the master node masterauth 123456 ## The slave node only reads to ensure the consistency of master-slave data
- stay redis Enter in the client command line (temporary) - replicaof 127.0.0.1 7100 - config set masterauth 123456 - End slave server fate (end) - slaveof no one
Data synchronization mechanism
The master-slave structure of redis can adopt a master-slave or cascade structure. Redis master-slave replication can be divided into full synchronization and incremental synchronization according to whether it is full or not
When the master and slave are just connected, full synchronization is performed; After full synchronization, perform incremental synchronization.
Full synchronization
- Redis full replication usually occurs in the Slave initialization stage. At this time, the Slave needs to copy all the data on the Master
- Connect the slave server to the master server and send the SYNC command;
- After receiving the SYNC naming, the master server starts to execute the BGSAVE command to generate an RDB file and uses the buffer to record all write commands executed thereafter;
- After the master server BGSAVE executes, it sends snapshot files to all slave servers, and continues to record the executed write commands during sending;
- After receiving the snapshot file from the server, discard all old data and load the received snapshot;
- After sending the snapshot from the master server, start sending the write command in the buffer to the slave server;
- Loading the snapshot from the server, receiving the command request, and executing the write command from the main server buffer;

Incremental synchronization
- Redis incremental replication refers to the process of synchronizing write operations from the master server to the Slave server when the Slave starts working normally after initialization.
- The main process of incremental replication is that the master server sends the same write command to the slave server every time it executes a write command, and the slave server receives and executes the received write command.
Asynchronous nature of master-slave replication
The master-slave replication is non blocking for the master redis server
- This means that when the slave server performs master-slave replication synchronization, the master redis can still handle external access requests;
The master-slave replication is also non blocking for the slave redis server
- This means that even in the process of master-slave replication from redis, external query requests can be accepted, but at this time, the old data is returned from redis
Server disconnection and reconnection
- Since Redis 2.8, if the connection is disconnected, you can continue to copy from the interrupted place after reconnection without resynchronizing
- The implementation of partial synchronization depends on maintaining a synchronization log and synchronization ID for each slave server in the memory of the master server
- When synchronizing with the master server, each slave server will carry its own synchronization ID and the last synchronization location
- After the master-slave connection is disconnected, the slave server actively attempts to connect to the master server at an interval of 1 s (default)
- If the offset ID carried from the server is still in the synchronous backup log on the master server
- Then, continue the last synchronization operation from the offset sent by the slave
- If the offset sent by the slave is no longer in the synchronous backup log of the master, a full update must be performed
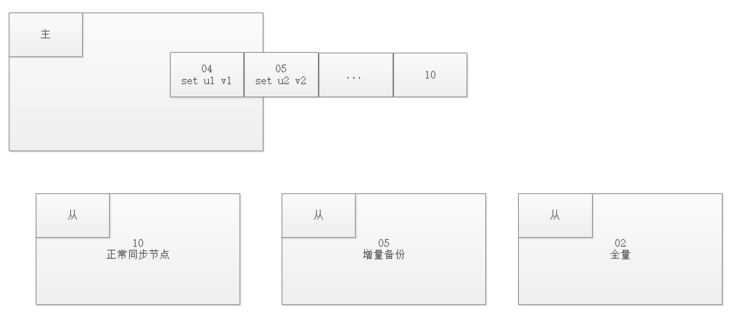
Redis sentry
In the master-slave replication mode of Redis, once the master node fails to provide services due to failure, you need to manually promote the slave node to the master node, and notify the client to update the master node address
Sentinel sentinel is a highly available solution officially provided by redis. It can be used to monitor the operation of multiple redis service instances
Sentinel function and function
Monitoring:
- Sentinel will constantly check whether your master and slave servers are working properly.
Notification:
- When a monitored Redis server has a problem, Sentinel can send a notification to the administrator or other applications through the API.
Automatic failover:
- When a master server cannot work normally, Sentinel will start an automatic failover operation, which will upgrade one of the failed master servers from the server to a new master server, and change other slave servers of the failed master server to copy the new master server; When the client tries to connect to the failed primary server, the cluster will also return the address of the new primary server to the client, so that the cluster can use the new primary server instead of the failed server.

How sentry works
In redis sentinel, there are three scheduled tasks. These tasks can be used to find new nodes and node states.
- Every 10 seconds, each sentinel node performs info operations on the master node and slave node
- Every 2 seconds, each sentinel node exchanges information through the channel (sentinel:hello) of the master node
- Every second, each sentintel node ping s the master node, slave node and other sentinel nodes
SDOWN: the current sentintel node considers a redis node unavailable.
- If the time of an instance from the last valid reply to the PING command exceeds the value specified by down after milliseconds, the instance will be marked as offline by Sentinel.
- If a master server is marked as subjective offline, all Sentinel nodes of the master server are being monitored to confirm that the master server has indeed entered the subjective offline state once per second.
Objective offline (ODOWN) a certain number of sentinel nodes think that a redis node is unavailable.
- If a master server is marked as subjective offline and a sufficient number of sentinels (at least up to the number specified in the configuration file) agree with this judgment within the specified time range, the master server is marked as objective offline.
- In general, each Sentinel will send INFO commands to all master and slave servers it knows once every 10 seconds. When a master server is marked as objectively offline by Sentinel, the frequency of Sentinel sending INFO commands to all slave servers of the offline master server will be changed from once in 10 seconds to once per second.
- Sentinel and other sentinel negotiate the status of the master node. If the master node is in SDOWN status, a new master node will be selected automatically by voting. Point the remaining slave nodes to the new master node for data replication.
- When a sufficient number of sentinel agree that the primary server is offline, the objective offline status of the primary server will be removed. When the master server returns a valid reply to Sentinel's PING command again, the subjective offline status of the master server will be removed.
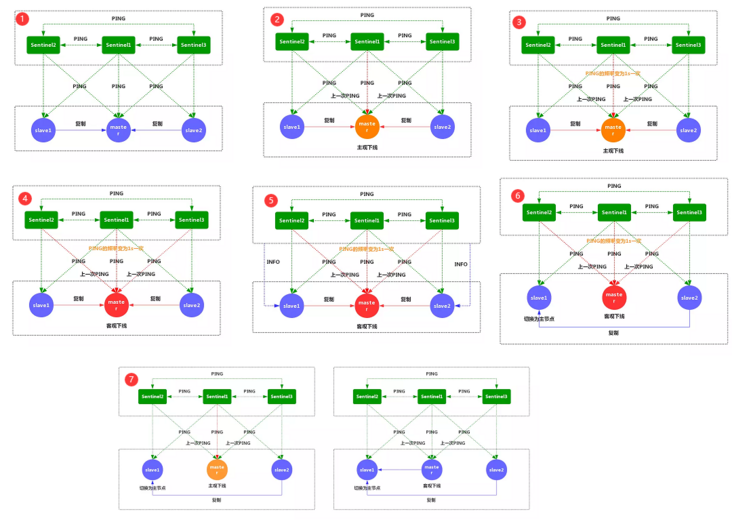
Failover process
Sentinel internal leader election
1) . each sentinel node that subjectively goes offline sends the above command to other sentinel nodes to set it as the leader.
2) . if the sentinel node receiving the command has not agreed to the command sent by other sentinel (has not voted), it will agree, otherwise it will be rejected.
3) If the sentinel node finds that it has more than half the votes and reaches the value of quorum, it will become a leader.
4) If multiple sentinel s become leaders in this process, they will wait for a period of time for re-election.
Master election
- Select the slave node with the highest slave priority
- Select the node with the largest copy offset
- Select the one with the smallest runId (earliest startup)
Status change
- Select a new master node, and change the remaining nodes to the slave node of the new master node
- The original master node goes online again and becomes the slave node of the new master node
Notification client
- When all nodes are configured, sentinel will notify the client of node change information.
- The client connects to the new master node
Sentinel environment construction
Build a master-slave cluster of multiple computers
Host port Node classification Sentinel 192.168.58.161 20601 master 20600 192.168.58.162 20601 slave 20600 192.168.58.163 20601 slave 20600 Master node
## Import a generic profile include /opt/lzj/redis/conf/redis.conf ## Current primary server IP and port bind 0.0.0.0 port 20601 ## Remove safe mode protected-mode no ## Set master service password requirepass 123456 ## Current main service process ID pidfile /var/run/redis_20601.pid ## Current main service RDB file name dbfilename dump20601.rdb ## Current main service file storage path dir /opt/lzj/redis/conf/ ## Set the password information of the master node masterauth 123456 ## Background start when setting
Slave node
## Import a generic profile include /opt/lzj/redis/conf/redis.conf ## Current primary server IP and port bind 0.0.0.0 port 20601 ## Remove safe mode protected-mode no ## Set master service password requirepass 123456 ## Current main service process ID pidfile /var/run/redis_20601.pid ## Current main service RDB file name dbfilename dump20601.rdb ## Current main service file storage path dir /opt/lzj/redis/conf/ ## Synchronize the network information of the master node (slaveof must be used for the lower version, and replica of is recommended for the higher version) replicaof 192.168.201.101 20601 ## Set the password information of the master node masterauth 123456 ## The slave node only reads to ensure the consistency of master-slave data slave-read-only yes ## Background start when setting
- The three computers start up separately Redis - redis-server /opt/lzj/redis/conf/redis20601.conf
A robust RedisSentinel cluster should use at least three Sentinel instances and ensure that these instances are placed on different machines or even different physical areas
## redis-sentinel /opt/lzj/redis/conf/sentinel.conf ## Set the Sentinel's interface port 20600 ## sentinel monitor keyword ## Master 20601 gives a name to the master-slave server cluster (monitor the master server and obtain the information of the slave server) ## 192.168.58.161 20601 IP and port of master server ## 2. The statistics of the failure of the primary server. More than 2 votes are considered to be invalid sentinel monitor master20601 192.168.201.101 20601 2 ## Set master server password sentinel auth-pass master20601 123456 ## The main server switches when it goes offline for more than 10 seconds (30S by default) sentinel down-after-milliseconds master20601 10000 ## Failover timeout sentinel failover-timeout master20601 180000 ## During failover, the smaller the number of slave s allowed to synchronize the new master at the same time, the longer it takes to complete the failover sentinel parallel-syncs master20601 1 ## Turn off security verification protected-mode no
Redis high availability
In Redis, technologies to achieve high availability mainly include persistence, replication, sentinel and cluster. The following briefly describes their functions and what problems they solve:
- Persistence: persistence is the simplest highly available method. Its main function is data backup, that is, data is stored on the hard disk to ensure that data will not be lost due to process exit.
Replication: replication is the basis of highly available Redis. Sentinels and clusters achieve high availability on the basis of replication.
- Replication mainly realizes multi machine backup of data, load balancing for read operation and simple fault recovery.
- The defects are that the fault recovery cannot be automated, the write operation cannot be load balanced, and the storage capacity is limited by a single machine.
- Sentry: Based on replication, sentry realizes automatic fault recovery. The defect is that the write operation cannot be load balanced, and the storage capacity is limited by a single machine.
- Cluster: through cluster, Redis solves the problems that write operations cannot be load balanced and storage capacity is limited by a single machine, and realizes a relatively perfect high availability scheme.
Cluster design idea
- Cluster can be said to be a combination of sentinel and master-slave mode. The master-slave and master reselection functions can be realized through cluster
- Different nodes manage different key s
- The operation of the same Key is handled by only one master
- In order to ensure the (single point of failure and efficiency) of the master node, at least one slave node is prepared for each master node
- Cluster is a facility that can share data among multiple Redis nodes
- The cluster does not support Redis commands that need to process multiple keys at the same time
Consistency Hash
Business scenario
- For an e-commerce platform, Redis needs to be used to store the picture resources of commodities. The storage format is a key Value pair, the key Value is the picture name, and the Value is the path of the file server where the picture is located. We need to find the path on the file server where the file is located according to the file name. The number of our pictures is about 3000w, and the database is divided according to our rules, The rule is randomly allocated. We deploy 12 cache servers with a storage capacity of 500w per server, and perform master-slave replication

Using the Hash method, each image can be located to a specific server when sorting

Question:
When the Redis server changes, the location of all caches will change
- The number of Redis cache servers increased from 6 to 8
- The number of Redis cache servers in the server cluster of 6 is reduced to 5 in case of failure
Algorithm principle
Take mold
- The consistent Hash algorithm takes the module of 32 square of 2
- The whole space is organized clockwise. The point directly above the ring represents 0, the first point to the right of 0 represents 1, and so on, 2, 3, 4, 5, 6... Until 2 ^ 32-1
- This ring of 2 ^ 32 points is called a Hash ring
The server
- Hash each server so that each machine can determine its position on the hash ring
data
- The data key uses the same function Hash to calculate the Hash value and determine the position of the data on the ring
location
- When you "walk" clockwise along the ring, the first server you encounter is the server where the data should be located
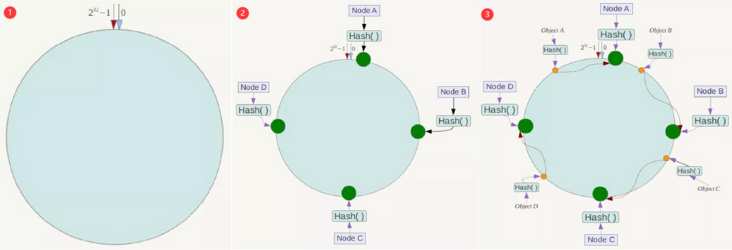
Algorithm fault tolerance
- When we add servers or delete servers
- It only affects the next node of the processing node
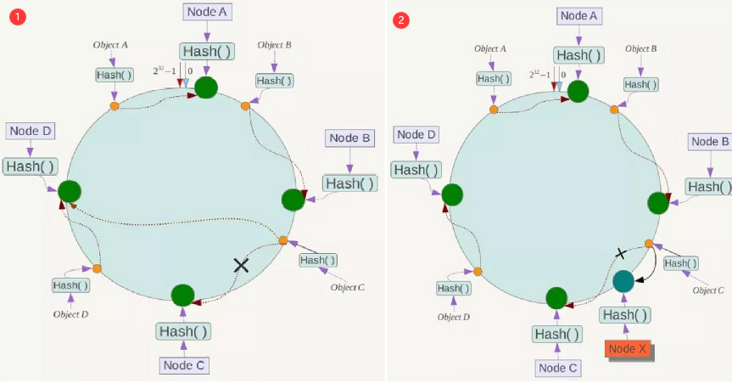
Data skew and virtual node
- The goal of uniform consistency hash is that if there are N servers and M hash values of clients,
- Then each server should handle about M/N users. That is, the load of each server should be balanced as much as possible

Redis Slot
- Redis cluster uses data sharding instead of consistent hashing to realize:
- A Redis cluster contains 16384 hash slots. Each key in the database belongs to one of the 16384 hash slots. The cluster uses the formula CRC16(key)%16384 to calculate which slot the key belongs to. The CRC16(key) statement is used to calculate the CRC16 checksum of the key
- Moving a hash slot from one node to another will not cause node blocking, so whether adding a new node, removing an existing node, or changing the number of hash slots contained in a node will not cause the cluster to go offline.
- Objects are hashed to a specified Node through CRC16 before being saved to Redis
- Each Node is equally allocated a Slot segment, corresponding to 0-16383. Slots cannot be repeated or missing, otherwise objects will be stored repeatedly or cannot be stored.
Nodes also monitor each other. Once a Node exits or joins, the data will be migrated according to the unit of Slot
- If Node1 is disconnected, 0-5640 slots will be equally allocated to Node2 and Node3
Advantages and disadvantages
advantage:
- Redis write operations are allocated to multiple nodes, which improves the write concurrency and makes capacity expansion simple.
Disadvantages:
- Each Node is responsible for mutual monitoring, high concurrency data writing and high concurrency data reading, and the work task is heavy

Build cluster environment
Node distribution
Host Master Slave 192.168.58.161 30601 30602 192.168.58.162 30601 30602 192.168.58.163 30601 30602
configuration file
## Import default profile include /opt/lzj/redis/conf/redis.conf ## Host and port of current primary server bind 0.0.0.0 port 30601 ## Background mode operation daemonize no ## Turn off protection mode protected-mode no ## Set master service password requirepass 123456 ## Set slave server password masterauth 123456 ## Current main service process ID pidfile /var/run/redis_30601.pid ## Current main service RDB file name dbfilename dump30601.rdb ## Current main service file storage path dir /opt/lzj/redis/conf/ ## Enable aof persistence mode appendonly yes ## Set AOF file name appendfilename "appendonly30601.aof" ##Cluster correlation cluster-enabled yes cluster-config-file nodes-30601.conf cluster-node-timeout 5000
Start 6 nodes respectively
redis-server /opt/lzj/redis/conf/redis20601.conf
Build cluster
# --Cluster replicas 1 indicates the master-slave configuration ratio. 1 indicates 1:1. The first three are master and the last three are slave # If the password is set in the configuration file, you also need to add - a passwod redis-cli --cluster create 192.168.201.101:30601 192.168.201.102:30601 192.168.201.103:30601 192.168.201.101:30602 192.168.201.102:30602 192.168.201.103:30602 --cluster-replicas 1 -a 123456
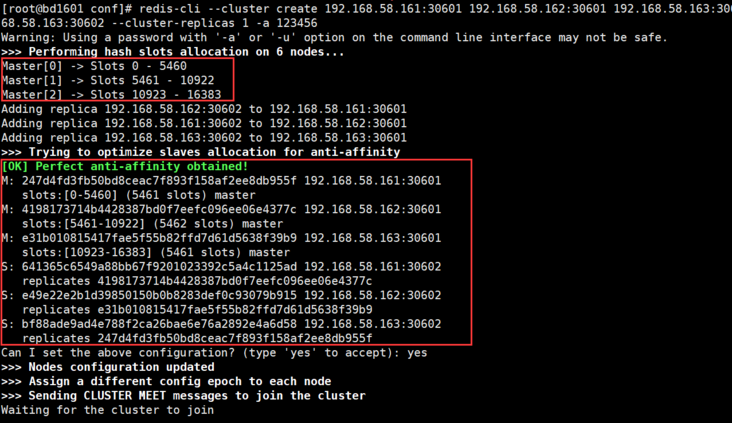
View cluster information
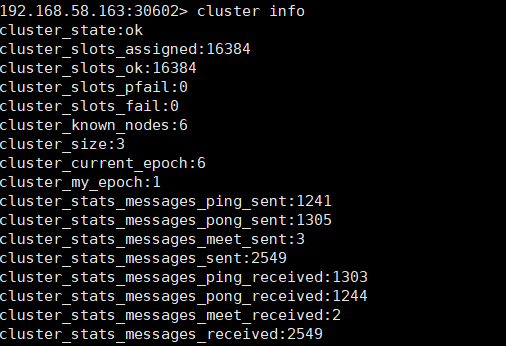
redis-cli -h 127.0.0.1 -p 20601 -a 123456 # View cluster information cluster info # View node list
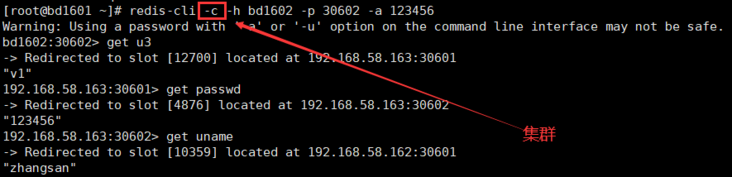
Access cluster
- redis-cli -h bd1602 -p 30602 -a 123456

- redis-cli -c -h bd1602 -p 30602 -a 123456
Common scenarios of Redis
User reply frequency control
- In the community function of the project, you will inevitably encounter spam content. When you wake up, you will find that the home page will suddenly be swiped by some malicious posts and advertisements. If you do not take appropriate mechanisms to control it, the user experience will be seriously affected
- There are many strategies to control advertising spam. The more advanced ones can be through AI. The simplest way is through keyword scanning. Another common way is frequency control, which limits the production speed of single user's content. Users without different levels will have different frequency control parameters
- Redis is used to realize frequency control (bronze 1 hour 3 stickers, silver 1 hour 5 stickers, gold 1 hour 8 stickers)
Fish fighting day list

24-hour hot list
- If there are only 10 places in the novel list, it is too unfair for the 11th novel
- So if the top 20 novels are displayed with the help of 10 positions???
Statistics of daily active users
- Redis HyperLogLog is an algorithm for cardinality statistics. The advantage of HyperLogLog is that when the number or volume of input elements is very, very large, the space required to calculate the cardinality is always fixed and very small.
- In Redis, each hyperlog key only needs 12 KB of memory to calculate the cardinality of nearly 2 ^ 64 different elements. This is in sharp contrast to a collection where the more elements consume more memory when calculating the cardinality.
Shake to get distance quickly
- The geo function is provided in Redis3.2. It supports the storage of geographic location information to realize functions that depend on geographic location information such as nearby location and shaking. The data type of geo is zset
- https://blog.csdn.net/qq_3420...
Thank you for your recognition and support. Xiaobian will continue to forward the high-quality articles of Le byte