1. Redis Cluster Architecture Details:
1. All Redis nodes are interconnected with each other (PING-PONG mechanism). Binary protocol is used to prioritize transmission speed and bandwidth.
2. Node failure will take effect only when more than half of the master nodes in the cluster fail to detect.
3. Clients are directly connected to redis nodes, and do not need proxy layer. Clients do not need to connect all nodes in the cluster, so they can connect any available node in the cluster.
4. redis-cluster maps all physical nodes to [0-1638] slot, and cluster maintains node < - > slot < - > key.
2. The redis-cluster election:
The electoral process involves the participation of all masters in the cluster. If more than half of the master nodes communicate with the current master node over time, the current master node is considered to be dead. The following two scenarios are cluster_state: fail, when the cluster is not available, all operations on the cluster are not available, and a ((error) CLUSTERDOWN The cluster is down) error is received:
-
If any master in the cluster hangs up and the current master has no slave, the cluster enters a fail state, which can also be understood as a fail state when the slot mapping of the cluster [0-16383] is incomplete.
-
If more than half of the master s in the cluster are deactivated, the cluster will fail regardless of slave.
By default, each cluster node uses two TCP ports, 6379 and 16379. 6379 serves the connection of clients and 16379 is used for cluster bus, that is, the node to node communication channel using binary protocol. Nodes use cluster bus for fault detection, configuration update, fault transfer authorization and so on.
Redis Clustering Principle:
1. Redis Cluster Architecture:
Redis Cluster uses virtual slot partition to map all data into 0-16384 integer slots according to the algorithm
Redis Cluster is a centrless structure
Each node holds data and the state of the entire cluster.
2. Cluster roles:
Master: Allocating slots between Masters
Slave: Slave synchronizes data with the Master it specifies
3. TCP ports used by cluster nodes
6379 Port for Client Connection
16379 Port for Cluster Bus
Redis version 3.0 and above began to support clustering, using hash slot (hash slot), which can integrate multiple Redis instances to form a cluster, that is, to disperse data to multiple servers in the cluster.
.
Redis cluster (Redis cluster) is a centralized structure. As shown in the figure below, each node stores data and the state of the entire cluster. Each node will save the information of other nodes, know the slots that other nodes are responsible for, and send heartbeat information regularly with other nodes, which can timely sense the abnormal nodes in the cluster.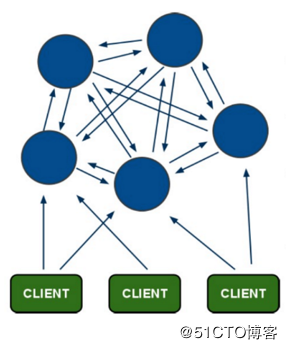
When the client sends commands related to database keys to any node in the cluster, the node receiving the command calculates which slot the data to be processed by the command belongs to, and checks whether the slot is assigned to itself. If the slot where the key is located is assigned to the current node, the node will directly hold the command; if the key is assigned to the current node, the node will directly hold the command. The slot in which the value is located is not assigned to the current node, so the node returns a MOVED error to the client, directs the client to redirect the correct node, and sends back the command that it wanted to execute before.
.
Cluster roles are master and slave. There are 16384 slots allocated between masters. Slve synchronizes data with the master it specifies to achieve backup. When one of the masters is unable to provide services, the master slave will be promoted to master to ensure the integrity of slots between clusters. When one of the masters and its slave fail, resulting in slot incompleteness and cluster failure, it needs operation and maintenance personnel to deal with it.
.
After the cluster is built, each node in the cluster sends PING messages to other nodes regularly. If the node receiving PING messages does not return PONG messages within the specified time, the node sending PING messages will mark it as suspected offline (PFAIL). Each node exchanges the status information of each node in the cluster by sending messages to each other. If already in a cluster, more than half of the primary nodes report a suspected downline of a primary node x, then the primary node x will be marked as offline (FAIL), and a FAIL message about the primary node x will be broadcast to the cluster. All the nodes receiving the FAIL message will immediately mark the primary node x as offline. Offline.
.
When we need to reduce or increase the number of servers in the cluster, we need to change the slots that have been assigned to one node (source node) to another node (target node), and move the key pairs contained in the slots from the source node to the target node.
.
Redis cluster re-fragmentation is performed by Redis cluster management software redis-trib, which does not support automatic fragmentation and needs to calculate the number of Slot s migrated from which nodes. In the process of re-fragmentation, the cluster does not need to be offline, and both source and target nodes can continue to process command requests.
Preparation:
1. Six servers, three master, three slave, all centos 7, IP address 192.168.1.10-60 in turn (the number of servers participating in the cluster is best even, each master automatically corresponds to a slave, if it is odd, the cluster can not achieve redundancy, because there must be a master without corresponding slave, Once the master crashes, the whole cluster loses part of its data.
2. Required source package: https://pan.baidu.com/s/12L6jNOBrXeLH4I445_uUtQ extraction code: smn6
3. All redis servers must be guaranteed to have no data, preferably newly installed, because if data exists, they will report errors when clustering later.
4. Configuring firewall traffic, I'm lazy, and it's closed directly here.
Start deploying:
Configuration on 192.168.1.10:
[root@localhost media]# ls redis-3.2.0.gem redis-3.2.9.tar.gz [root@localhost media]# cp * /usr/src/ # Replication of packages [root@localhost media]# cd /usr/src/ [root@localhost src]# ls # I'm sure they're all there. debug kernels redis-3.2.0.gem redis-3.2.9.tar.gz [root@localhost src]# tar zxf redis-3.2.9.tar.gz [root@localhost src]# cd redis-3.2.9/ [root@localhost redis-3.2.9]# make && make install # Compile and install [root@localhost redis-3.2.9]# cd utils/ # Enter another subdirectory [root@localhost utils]# ./install_server.sh # Enter all the way. # Because make install only installs binary files into the system and does not start scripts and configuration files, it is necessary to set up the relevant configuration files needed by redis service through install_server.sh. [root@localhost utils]# cd /etc/init.d/ #Optimizing the Start-Stop Mode of redis Control [root@localhost init.d]# mv redis_6379 redis [root@localhost init.d]# chkconfig --add redis #Adding redis to system services [root@localhost init.d]# systemctl restart redis #Restart the service to test its effectiveness [root@localhost /]# vim /etc/redis/6379.conf # Modify the configuration file and modify the following ....................... bind 192.168.1.10 // Setting up listener IP address daemonize yes logfile /var/log/redis_6379.log // Specify log files cluster-enabled yes // Start cluster cluster-config-file nodes-6379.conf // Cluster Profile cluster-node-timeout 15000 // Node timeout, default to milliseconds cluster-require-full-coverage no // Change yes to no port 6379 // Monitor port # Save exit
Don't rush to start the service after the modification of the main configuration file, because we need to install redis on each server, install it according to the previous method, and then modify the configuration file. Every server has to be modified, just to listen for different IP addresses, the other configurations are the same. So, hey hey hey hey hey~~~~~
192.168.1.20 Configuration:
# After installing redis [root@localhost utils]# scp root@192.168.1.10:/etc/redis/6379.conf /etc/redis/ # Let's copy the master file of the first station directly and use it. Just modify the listening IP. [root@localhost utils]# vim /etc/redis/6379.conf ........................ bind 192.168.1.20
Then configure the remaining servers in turn.
Back to configuration 192.168.1.1:
Create clusters using scripts:
[root@localhost /]# yum -y install ruby rubygems # A script for ruby is used to create a cluster. Before creating a cluster, you need to install ruby's running environment and client, which can be installed on any server. [root@localhost src]# gem install redis --version 3.2.0 # To execute this command, you need the file redis-3.2.0.gem, so switch to the directory that owns the file before execution. Successfully installed redis-3.2.0 Parsing documentation for redis-3.2.0 Installing ri documentation for redis-3.2.0 1 gem installed [root@localhost src]# ./redis-trib.rb create --replicas 1 \ > 192.168.1.10:6379 \ > 192.168.1.20:6379 \ > 192.168.1.30:6379 \ > 192.168.1.40:6379 \ > 192.168.1.50:6379 \ > 192.168.1.60:6379 .20:6379 192.168.1.30:6379 192.168.1.40:6379 192.168.1.50:6379 192.168.1.60:6379 >>> Creating cluster >>> Performing hash slots allocation on 6 nodes... Using 3 masters: 192.168.1.10:6379 192.168.1.20:6379 192.168.1.30:6379 Adding replica 192.168.1.40:6379 to 192.168.1.10:6379 Adding replica 192.168.1.50:6379 to 192.168.1.20:6379 Adding replica 192.168.1.60:6379 to 192.168.1.30:6379 M: 4234dad1a041a91401d6e635c800581172e850dc 192.168.1.10:6379 slots:0-5460 (5461 slots) master M: b386e4089c6f45a59d371549cda306669dd6938f 192.168.1.20:6379 slots:5461-10922 (5462 slots) master M: c1d6d14364e8c5db2ae1ea3ee07360a8b17127d8 192.168.1.30:6379 slots:10923-16383 (5461 slots) master S: e772a17543efb1e11cd05d792c11319b0fbfee5f 192.168.1.40:6379 replicates 4234dad1a041a91401d6e635c800581172e850dc S: f0a387bf5f366de0e25c575588349bd424a0ff90 192.168.1.50:6379 replicates b386e4089c6f45a59d371549cda306669dd6938f S: abc2fef19988e6626243feff831bced36b83b642 192.168.1.60:6379 replicates c1d6d14364e8c5db2ae1ea3ee07360a8b17127d8 Can I set the above configuration? (type 'yes' to accept): yes # Remember yes here >>> Nodes configuration updated >>> Assign a different config epoch to each node >>> Sending CLUSTER MEET messages to join the cluster Waiting for the cluster to join..... >>> Performing Cluster Check (using node 192.168.1.10:6379) M: 4234dad1a041a91401d6e635c800581172e850dc 192.168.1.10:6379 slots:0-5460 (5461 slots) master 1 additional replica(s) M: c1d6d14364e8c5db2ae1ea3ee07360a8b17127d8 192.168.1.30:6379 slots:10923-16383 (5461 slots) master 1 additional replica(s) M: b386e4089c6f45a59d371549cda306669dd6938f 192.168.1.20:6379 slots:5461-10922 (5462 slots) master 1 additional replica(s) S: f0a387bf5f366de0e25c575588349bd424a0ff90 192.168.1.50:6379 slots: (0 slots) slave replicates b386e4089c6f45a59d371549cda306669dd6938f S: e772a17543efb1e11cd05d792c11319b0fbfee5f 192.168.1.40:6379 slots: (0 slots) slave replicates 4234dad1a041a91401d6e635c800581172e850dc S: abc2fef19988e6626243feff831bced36b83b642 192.168.1.60:6379 slots: (0 slots) slave replicates c1d6d14364e8c5db2ae1ea3ee07360a8b17127d8 [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered.
Test the cluster:
[root@localhost /]# redis-cli -h 192.168.1.20 -p 6379 -c
192.168.1.20:6379 > set Zhangsan 123123 # Create a value
-> Redirected to slot [12767] located at 192.168.1.30:6379
OK
192.168.1.30:6379 > get Zhangsan # is also available
"123123"
[root@localhost src]# ./redis-trib.rb check 192.168.1.10:6379 # Viewing Cluster Status >>> Performing Cluster Check (using node 192.168.1.10:6379) M: 4234dad1a041a91401d6e635c800581172e850dc 192.168.1.10:6379 slots:0-5460 (5461 slots) master 1 additional replica(s) M: c1d6d14364e8c5db2ae1ea3ee07360a8b17127d8 192.168.1.30:6379 slots:10923-16383 (5461 slots) master 1 additional replica(s) M: b386e4089c6f45a59d371549cda306669dd6938f 192.168.1.20:6379 slots:5461-10922 (5462 slots) master 1 additional replica(s) S: f0a387bf5f366de0e25c575588349bd424a0ff90 192.168.1.50:6379 slots: (0 slots) slave replicates b386e4089c6f45a59d371549cda306669dd6938f S: e772a17543efb1e11cd05d792c11319b0fbfee5f 192.168.1.40:6379 slots: (0 slots) slave replicates 4234dad1a041a91401d6e635c800581172e850dc S: abc2fef19988e6626243feff831bced36b83b642 192.168.1.60:6379 slots: (0 slots) slave replicates c1d6d14364e8c5db2ae1ea3ee07360a8b17127d8 [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered.
The difference between redis-3.x.x and redis-5.x.x creating clusters:
The command is different. redis-3.x.x uses redis-trib.rb command. The grammar is as follows:
[root@localhost ~]#redis-trib.rb create --replicas 1 192.168.1.1:6379 ..192.168.1.6:6379 #redis-3.x.x creates clusters. [root@localhost src]# redis-trib.rb check 192.168.1.1:6379 #Viewing Cluster Status # Redis-trib.rb can not be used directly. You need to do the following to use redis-trib.rb directly [root@localhost src]# cd /usr/src/redis-5.0.5/src/ [root@localhost src]# cp redis-trib.rb /usr/local/bin/ #Copy the script to local.. / bin for direct use. Otherwise, you need to execute the file with ". /" in the directory