Relational database and non relational database
Relational database
Relational database is a structured database, which is created on the basis of relational model (two-dimensional table model) and is generally record oriented.
SQL statement (standard data query language) is a language based on relational database, which is used to retrieve and operate the data in relational database.
Mainstream relational databases include Oracle, MySQL, SQL Server, Microsoft Access, DB2, etc.
Non relational database
NoSQL (NoSQL=NotOnlySQL), which means "not just sQL", is the general name of non relational databases.
In addition to the mainstream relational databases, all databases are considered non relational.
Mainstream NoSQL databases include Redis, MongBD, Hbase, Memcached, etc.
The difference between relational database and non relational database
1. Different data storage methods
The main difference between relational and non relational databases is the way of data storage. Relational data is naturally tabular, so it is stored in rows and columns of the data table. Data tables can be associated with each other, stored cooperatively, and data can be easily extracted.
On the contrary, non relational data is not suitable to be stored in rows and columns of the data table, but large blocks are combined together. Non relational data is usually stored in data sets, such as documents, key value pairs, or graph structures. What are your data and its characteristics
The primary factor affecting the selection of data storage and extraction methods.
Relational: it depends on the E-R diagram of the relational model and stores data in a tabular format
Non relational: in addition to storing data in tabular form, it is usually combined in large blocks to store data
2. Different expansion modes
The biggest difference between SQL and NoSQL databases may be in the expansion mode. To support the growing demand, of course, it needs to be expanded.
To support more concurrency, the SQL database is vertically expanded, that is, to improve processing capacity and use faster computers, so that the same data set can be processed faster. Because the data is stored in relational tables, the performance of the operation is a bottleneck
It may involve many tables, which need to be improved by improving computer performance. Although the sQL database has a large expansion space, it will eventually reach the upper limit of vertical expansion. NoSQL database is horizontally expanded. Because non relational
Data storage is naturally distributed. The expansion of NoSQL database can share the load by adding more common database servers (nodes) to the resource pool.
Relationships: vertical (NATURAL table format)
Non off: horizontal (natural distribution)
3. Support for transactional is different
If the data operation needs high transaction or complex data query needs to control the execution plan, the traditional SQL database is the best choice in terms of performance and stability. SQL database supports fine-grained control over transaction atomicity, and
Easy to roll back transactions. Although NoSQL databases can also use transaction operations, they cannot be compared with relational databases in terms of stability, so their real value is in the scalability of operations and large amount of data processing.
Relational: especially suitable for tasks with high transactional requirements and the need to control the implementation plan
Non relationship: it will be slightly weak here, and its value lies in high scalability and large amount of data processing
Background of non relational database
Can be used to deal with web2 0 three high problems of pure dynamic website type.
(1) High performance ---- high concurrent read and write requirements for the database
(2) Hugestorag ------------------- requirements for efficient storage and access of massive data
(3) High scalability & & high availability ------ requirements for high scalability and availability of database
Summary:
| Relational database: | Instance - > Database - > Table - > record row and data column |
|---|---|
| Non relational database | Instance - > Database - > collection – > key value pair |
Non relational databases do not need to build databases and sets (tables) manually.
Introduction to Redis
Redis is an open source NoSQL database written in C language.
Redis runs based on memory and supports persistence (supports storage on disk). It adopts the storage form of key value (key value pair). It is an indispensable part of the current distributed architecture.
Redis server program is a single process model
Redis service can start multiple redis processes on one server at the same time. The actual processing speed of redis completely depends on the execution efficiency of the main process. If only one redis process is running on the server, when multiple clients visit at the same time
When asked, the processing capacity of the server will decline to a certain extent; If multiple Redis processes are started on the same - server, Redis will put great pressure on the server CPU while improving the concurrent processing capacity. Namely: in actual production
In the environment, you need to decide how many Redis processes to start according to the actual needs. If the requirements for high concurrency are higher, you may consider starting multiple processes on the same server. If CPU resources are tight, single process can be used.
It is suggested that two processes can be started
① , backup
② . while resisting high concurrency, try not to put too much pressure on the CPU
Advantages of redis
(1) It has extremely high data reading and writing speed: the maximum data reading speed can reach 110000 times / s, and the maximum data writing speed can reach 81000 times / s.
(2) = = support rich data types: = = support key value, Strings, Lists, Hashes, Sets, OrderedSets and other data type operations.
pS :
String string (can be integer, floating point and character type, collectively referred to as element)
list: (implement queue, elements are not unique, first in first out principle)
Set set: (different elements)
hash hash value: (the key of hash must be unique)
set /ordered sets
(3) Support data persistence: the data in memory can be saved on disk and can be loaded again for use when restarting.
(4) Atomicity: all Redis operations are atomicity.
(5) Support data backup: data backup in master save mode.
Redis is a memory based database, and caching is one of its most common application scenarios. In addition, common redis application scenarios also include operations to obtain the latest N data, leaderboard applications, counter applications, storage relationships, real-time analysis systems, and logging.
redis installation and deployment
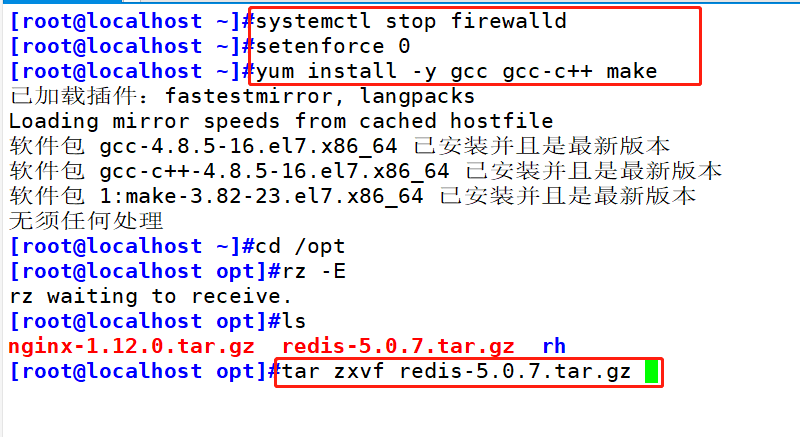
systemctl stop firewalld setenforce 0 yum install -y gcc gcc-c++ make yum repolist again yum yum install -y gcc* #Redis-5.0.7 tar. Upload GZ compressed package to / opt directory tar zxvf redis-5.0.7.tar.gz -C /opt/ cd /opt/redis-5.0.7/ make make PREFIX=/usr/local/redis install #Since the Makefile file is directly provided in the redis source package, you don't need to execute it first after decompressing the software package/ configure. You can directly execute the make and make install commands to install #Execute the install server provided by the software package SH script file sets the relevant configuration files required by Redis service cd /opt/ redis-5.0.7/utils ./install server.sh #Keep returning Please select the redis executable path [/usr/local/bin/redis-server] /usr/local/redis/bin/ redis-server #It needs to be manually modified to / usr / local / redis / bin / redis server Pay attention to correct input at one time

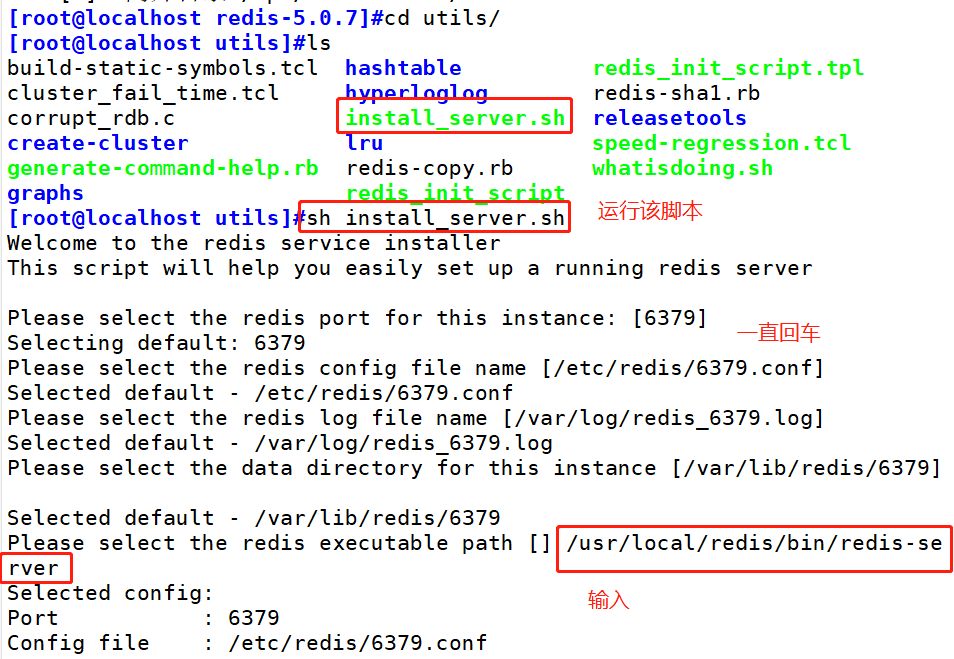
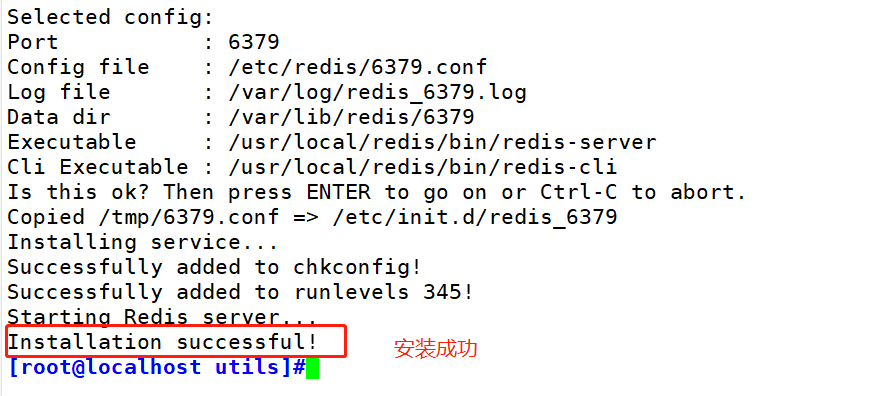
Selected config: Port :6379 #The default listening port is 6379 Config file :/etc/redis/6379.conf #Profile path Log file :/var/log/redis_6379.1og #log file path Data dir :/var/lib/redis/6379 #Data file path Executable :/usr/local/redis/bin/redis-server #Executable path Cli Executable :/usr/local/redis/bin/redis-cli #Client command tool
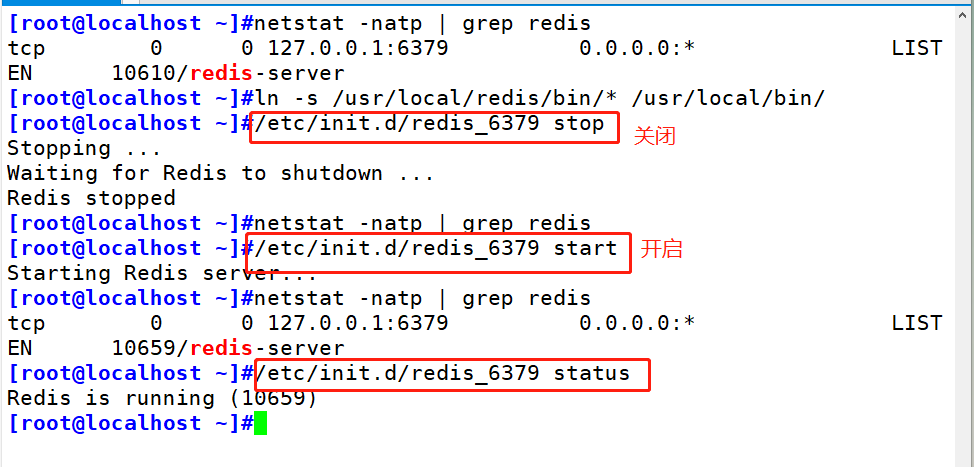
#Put the redis executable file into the directory of path environment variable for system identification ln -s /usr/local/redis/bin/* /usr/local/bin/ #When install_ server. After the SH script runs, the Redis service has been started. The default listening port is 6379 netstat -natp | grep redis #Redis service control /etc/init.d/redis_6379 stop #stop it /etc/init.d/redis_6379 start #start-up /etc/init.d/redis_6379 restart #restart /etc/init.d/redis_6379 status #state
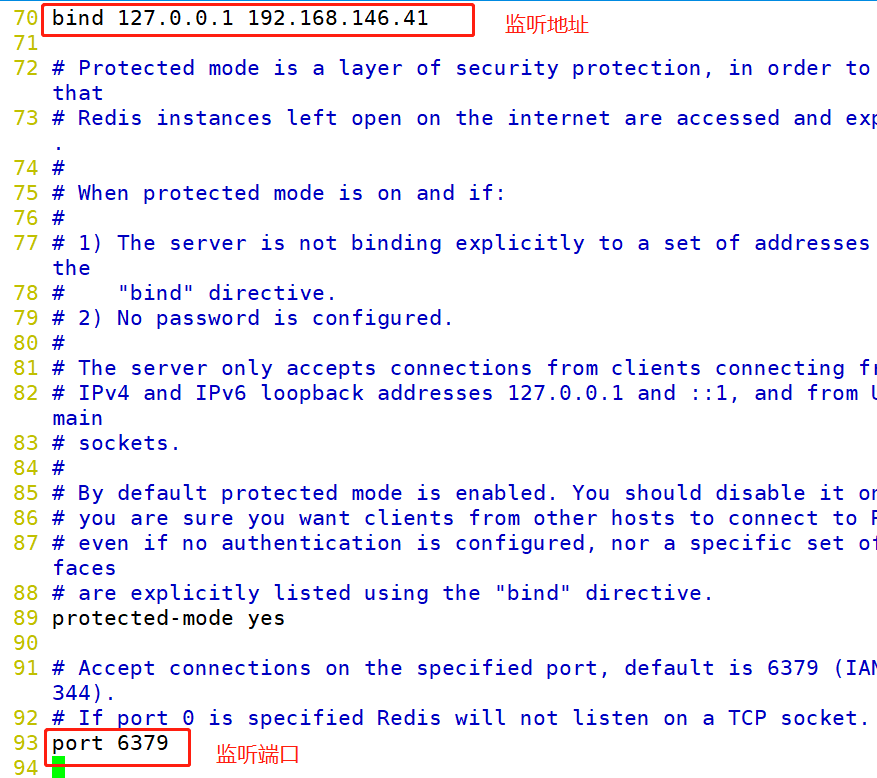
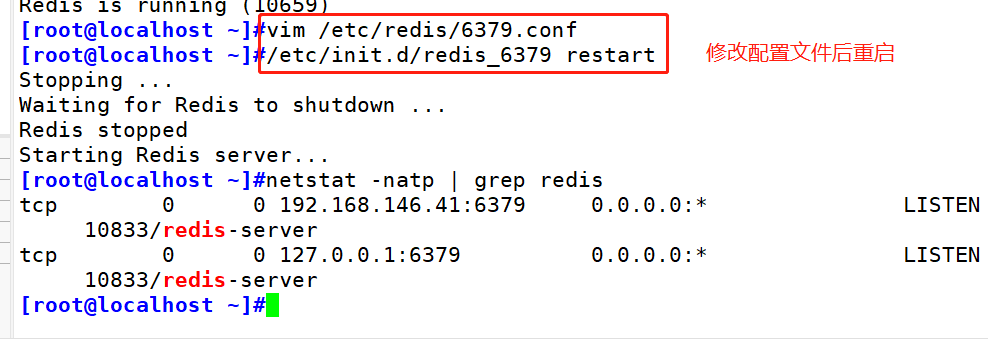
#Modify the configuration / etc / redis / 6379 Conf parameter vim /etc/redis/6379.conf bind 127.0.0.1 192.168.146.41 #Line 70, add the listening host address port 6379 #Line 93, Redis's default listening port daemonize yes #Line 137, enable the daemon pidfile /var/run/redis_6379.pid #Line 159, specify the PID file loglevel notice #Line 167, log level logfile /var/log/redis_6379.log #Line 172, specify the log file /etc/init.d/redis_6379 restart
Redis command
redis-server:Used to start Redis Tools for redis-benchmark: For detection Redis Operating efficiency of the machine redis-check-aof:repair AOF Persistent file redis-check-rdb:repair RDB Persistent file redis-cli: Redis Command line tools. rdb and aof yes redis Two forms of persistence in services RDBAOF redis-cli Commonly used to log in to redis database
Remote login
grammar: redis-cli -h host -p port -a password -h:Specify remote host -p:appoint Redis Port number of the service -a:Specify the password. If the database password is not set, it can be omitted-a option If no option representation is added, 127 is used.0.0.1:6379 Connect the on this machine Redis database redis-cli -h 192.168.146.41 -p 6379

Common commands of redis database
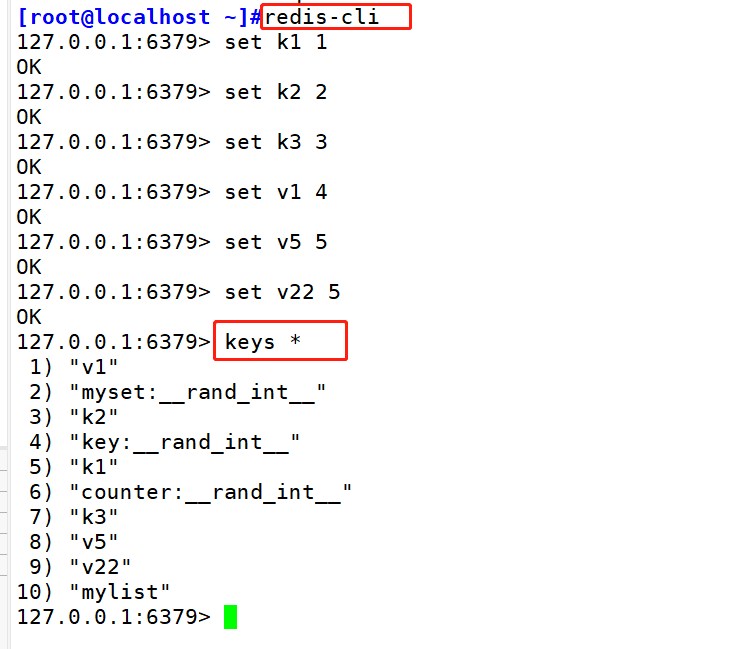
set: Store data in command format set key value get: Get data in command format get key redis-cli 127.0.0.1:6379> set teacher zhangsan OK 127.0.0.1:6379> get teacher " zhangsan" #The keys command can take the list of key values that meet the rules. Usually, it can be combined with *? And other options. 127.0.0.1 :6379> set k1 1 127.0.0.1:6379> set k2 2 127.0.0.1:6379> set k3 3 127.0.0.1:6379> set v1 4 127.0.0.1:6379> set v5 5 127.0.0.1:6379> set v22 5 127.0.0.1:6379> KEYS * #View all keys in the current database 127.0.0.1:6379> KEYS v* #View data starting with v in the current database 1) "v5" 2) "v1" 3) "v22" 127.0.0.1:6379> KEYS v? #View the data in the current database that starts with v and then contains any -- bit“ 1) "v5" 2) "v1" 127.0.0.1:6379> KEYS v?? #View the data starting with v and followed by any two digits in the current database 1) "v22" #The exists command can determine whether the key value exists. 127.0.0.1:6379> exists teacher #Determine whether the teacher key exists (integer) 1 #1 indicates that the teacher key exists 127.0.0.1:6379> exists tea . (integer) 0 #0 indicates that the tea key does not exist #The del command can delete the specified key of the current database. 127.0.0.1:6379> keys * 127.0.0.1:6379> del v5 (integer) 1 127.0.0.1:6379> get v5 (nil)

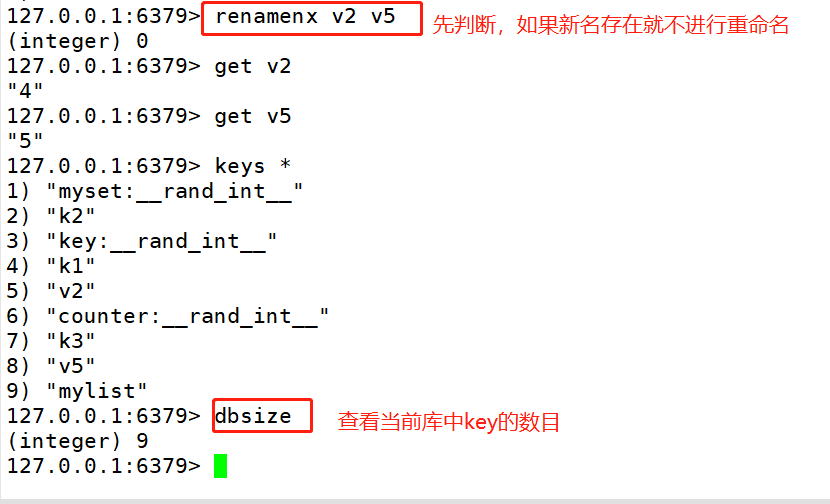
# The type command can obtain the value type corresponding to the key. 127.0.0.1:6379> type k1 string # The rename command renames an existing key. (overlay) Command format: rename source key target key use rename The command renames regardless of the target key Rename whether there are any and the source key The value of overrides the target key Value of. In actual use, it is recommended to use it first exists Command view target key Whether it exists, Then decide whether to implement it rename Command to avoid overwriting important data. 127.0.0.1:6379> keys v* 1) "v1" 2) "v22" 127.0.0.1:6379> rename v22 v2 OK 127.0.0.1:6379> keys v* 1)"v1" 2)"v2" 127.0.0.1:6379> get v1 "4" 127.0.0.1:6379> get v2 "5" 127.0.0.1:6379> rename v1 v2 127.0.0.1:6379> get v1 (nil) 127.0.0.1:6379> get v2 "4" #renamenx rename n No modification x Make modifications nx combination:Judge first The function of the command is to key Rename and detect whether the new name exists if the target key If it exists, it will not be renamed.(Not covered) Command format: renamenx source key Target key 127.0.0.1:6379> get teacher "zhangsan" 127.0.0.1:6379> get v2 "4" 127.0.0.1:6379> renamenx v2 teacher (integer) 0 127.0.0.1:6379> keys * 127.0.0.1:6379> get teacher " zhangsan" 127.0.0.1:6379> get v2 "4" #The dbsize command is used to view the number of key s in the current database. 127.0.0.1:6379> dbsize (integer) 9

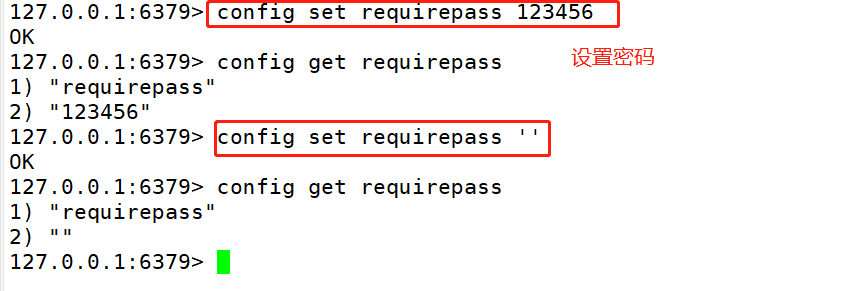
#Use the config set require repass yourpassword command to set the password 127.0.0.1:6379> config set requirepass 123456 #Use config get requi repass Command view password(--Once the password is set, the password must be verified first, otherwise all operations are unavailable) 127.0.0.1:6379> auth 123456 127.0.0.1:6379> config get requi repass #Delete password 127.0.0.1:6379> auth 123123 127.0.0.1:6379> config set requirepass ' ' #redis cannot be restarted because the above settings are not set
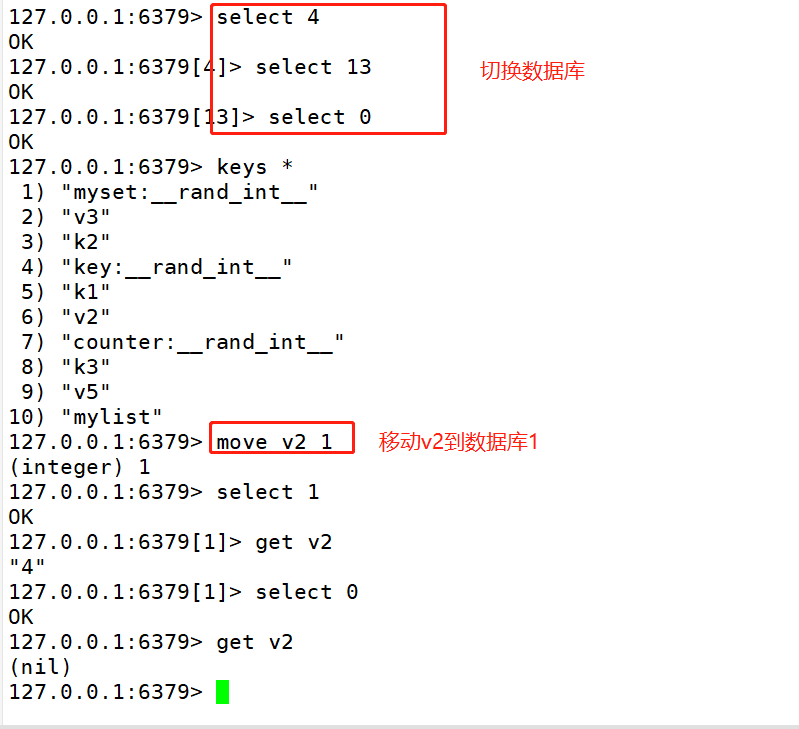
Redis Common commands for multiple databases(16 0-15) Redis Support multiple databases, Redis By default, there are 16 databases, and the database name is 0-15 Named in turn. Multiple databases are independent and do not interfere with each other. #Switching between multiple databases Command format: select Serial number use redis-cli connect Redis After the database, the database with sequence number 0 is used by default. 127.0.0.1:6379> select 10 #Switch to the database with serial number 10 127.0.0.1:6379[10]> select 15 #Switch to the database with serial number 15 127.0.0.1:6379[15]> select 0 #Switch to database with sequence number 0 #Moving data between multiple databases format:move Key value serial number 127.0.0.1:6379> set k1 100 OK 127.0.0.1:6379> get k1 "100" 127 .0.0.1:6379> select 1 OK 127 .0.0.1:6379[1]> get k1 (nil) 127.0.0.1:6379[1]> select 0 #Switch to target database 0 OK 127.0.0.1:6379> get k1 #Check whether the target data exists "100" 127 .0.0.1:6379> move k1 1 #Move k1 from database 0 to database 1 (integer) 1 127.0.0.1:6379> select 1 #Switch to target database 1 OK 127.0.0.1:6379[1]> get k1 #View moved data "100" 127.0.0.1:6379[1]> select 0 OK 127.0.0.1:6379> get k1 #The value of k1 cannot be viewed in database 0 (nil) #Clear data in database FLUSHDB:Clear current database data FLUSHALL :Clear all database data and use with caution!
Redis high availability
In the web server, high availability refers to the time when the server can be accessed normally. The measurement standard is how long it can provide normal services (99.9, 99.998, 99.9998, etc.).
However, in the context of Redis, the meaning of high availability seems to be broader. In addition to ensuring the provision of normal services (such as master-slave separation and fast disaster recovery technology), it is also necessary to consider the expansion of data capacity and data security will not be lost.
In Redis, high availability technologies mainly include persistence, master-slave replication, sentinel and cluster. Their functions and problems are described below.
Persistence: persistence is the simplest high availability method (sometimes it is not even classified as a high availability method). Its main function is data backup, that is, data is stored on the hard disk to ensure that data will not be lost due to process exit.
Master-slave replication: master-slave replication is the basis of highly available Redis. Sentinels and clusters achieve high availability on the basis of master-slave replication. Master-slave replication mainly realizes multi machine backup of data, load balancing for read operation and simple fault recovery. Defect: failure recovery cannot be automated; The write operation cannot be load balanced; The storage capacity is limited by a single machine. Based on master-slave replication, sentinel realizes automatic fault recovery. Defect: write operation cannot be load balanced; The storage capacity is limited by a single machine.
Sentry: Based on master-slave replication, sentry realizes automatic fault recovery. Defect: write operation cannot be load balanced; The storage capacity is limited by a single machine.
Cluster: through cluster, Redis solves the problem that the write operation cannot be load balanced and the storage capacity is limited by a single machine, and realizes a relatively perfect high availability scheme
redis persistence
Persistence function: Redis is an in memory database, and all data are stored in memory. In order to avoid permanent loss of data after abnormal exit of Redis process due to server power failure and other reasons, it is necessary to regularly save the data in Redis from memory to hard disk in some form (data or command); When Redis restarts next time, use persistent files to recover data. In addition, for disaster backup, persistent files can be copied to a remote location.
Redis provides two ways for persistence:
● RDB persistence: the principle is to save the database records of IDS in memory to disk regularly.
● AOF persistence (append only file): the principle is to write the IDS operation log to the file in the form of append, which is similar to MySQL binlog.
Because AOF persistence has better real-time performance, that is, less data is lost when the process exits unexpectedly, AOF is the mainstream persistence method at present, but RDB persistence still has its place.
RDB persistence
rdb persistence refers to saving the generated snapshot of the data in the current process in the memory to the hard disk within a specified time interval (so it is also called snapshot persistence), and storing it in binary compression. The saved file suffix is rdb; When Redis restarts, you can read the snapshot file recovery data.
Trigger condition
RDB persistence can be triggered manually or automatically.
① Manual trigger
Both the save command and the bgsave command can generate RDB files.
The save command blocks the Redis server process until the RDB file is created. During the blocking period of the Redis server, the server cannot process any command requests. The bgsave command creates a child process, which is responsible for creating the RDB file, and the parent process (i.e. the Redis main process) continues to process the requests.
During the execution of the bgsave command, only the fork subprocess will block the server. For the Save command, the whole process will block the server. Therefore, save has been basically abandoned. The use of save should be eliminated in the online environment.
Often the production environment bgsave is still not allowed to be used easily
② Automatic trigger
When RDB persistence is triggered automatically, Redis will also select bgsave instead of save for persistence.
save m n
The most common case of automatic triggering is to specify that bgsave will be triggered when n changes occur in m seconds through savemn in the configuration file.
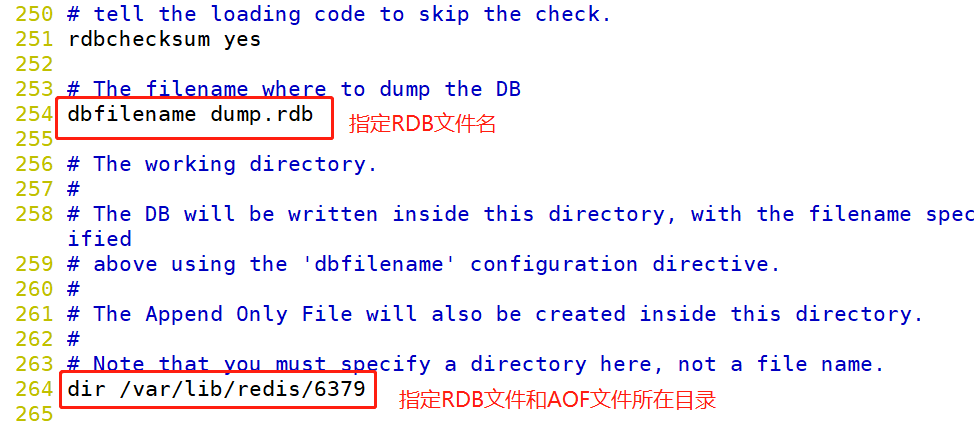
vim /etc/redis/6379.conf --219 that 's ok--The following three save When any one of the conditions is met, it will cause bgsave Call of save 900 1 :When the time reaches 900 seconds, if redis If the data has changed at least once, execute bgsave save 300 10 :When the time reaches 300 seconds, if redis If the data has changed at least 10 times, execute bgsave save 60 10000 :When the time reaches 60 seconds, if redis If the data has changed at least 10000 times, execute bgsave --242 that 's ok--Open RDB File compression rdbcompression yes --254 that 's ok--appoint RDB file name dbfilename dump.rdb --264 that 's ok--appoint RDB Documents and AOF File directory dir /var/lib/redis/6379 ##Other automatic triggering mechanisms except savemn In addition, there are other situations that can trigger bgsave: In the master-slave replication scenario, if the slave node performs full replication, the master node performs full replication bgsave Command, and rdb The file is sent to the slave node. ●implement shutdown Command is executed automatically rdb Persistence.

Execution process
① The Redis parent process first determines whether the child process of save,b or bgsave/ bgrewriteaof is currently executing. If it is executing, the bgsave command returns directly.
The sub processes of bgsave /bgrewriteaof cannot be executed at the same time, mainly based on performance considerations: two concurrent sub processes perform a large number of disk write operations at the same time, which may cause serious performance problems.
② The parent process performs a fork operation to create a child process. In this process, the parent process is blocked, and Redis cannot execute any commands from the client.
③ After the parent process fork s, the bgsave command returns the "Background saving started" information, no longer blocks the parent process, and can respond to other commands.
④ The child process creates an RDB file, generates a temporary snapshot file according to the memory snapshot of the parent process, and atomically replaces the original file after completion.
⑤ The child process sends a signal to the parent process to indicate completion, and the parent process updates the statistics.
Load on startup
RDB file loading is performed automatically when server is started, and there is no special command. However, since A0F has higher priority, Redis will preferentially load A0F files to recover data when AOF is enabled; Only when A0F is closed
RDB files will be detected and loaded automatically when the Redis server is started. The server is blocked while loading RDB files until the loading is complete. When Redis loads an RDB file, it will verify the RDB file. If the file is damaged, an error will be printed in the log and Redis startup fails.
AOF persistence
RDB persistence is to write process data to a file, while AOF persistence is to record each write and delete command executed by Redis in a separate log file, and the query operation will not be recorded; When Redis restarts, priority should be given to executing the in the AOF file
Command to recover data. Compared with RDB, AOF has better real-time performance, so it has become the mainstream persistence scheme
Turn on AOF
Redis The server is on by default RDB,close AOF:To open AOF,It needs to be configured in the configuration file: vim /etc/redis/6379.conf --700 that 's ok--Modify, open AOF appendonly yes --704 that 's ok--appoint A0F File name appendfilename "appendonly.aof" --796 that 's ok--Ignore last--Instruction with possible problems aof-load-truncated yes /etc/init.d/redis_6379 restart


Execution process
Since each write command of Redis needs to be recorded, A0F does not need to be triggered. The execution process of AOF is described below.
The execution process of AOF includes:
● append command: append the Redis write command to the buffer aof_buf;
● file write and file sync: set AOF according to different synchronization strategies_ The contents in buf are synchronized to the hard disk;
● file rewrite: Rewrite AOF files regularly to achieve the purpose of compression.
① Command append
Redis first adds the write command to the buffer instead of directly writing to the file. The main reason is to avoid directly writing the write command to the hard disk every time, resulting in the hard disk IO becoming the bottleneck of redis load.
The format of command addition is the protocol format requested by Redis command. It is a plain text format, which has the advantages of good compatibility, strong readability, easy processing, simple operation and avoiding secondary overhead. In A0F file, except for specifying data
The select command of the library (for example, select0 is the selected database No. 0) is added by Redis, and others are write commands sent by the client.
② File write and file sync
Redis provides a variety of file synchronization strategies for AOF cache, which involves the write function and fsync function of the operating system. The description is as follows: in order to improve the efficiency of file writing, in modern operating systems, when users call the write function to write data to a file, the operating system usually temporarily stores the data in one memory buffer, When the buffer is filled or exceeds the specified time limit, the data in the buffer is really written to the hard disk. Although this operation improves the efficiency, it also brings security problems: if the computer shuts down, the data in the memory buffer will be lost; Therefore, the system also provides synchronization functions such as fsync and fdatasync, which can force the operating system to write the data in the buffer to the hard disk immediately, so as to ensure the security of the data.
AOF There are three synchronization methods for the cache synchronization file policy, which are: vim /etc/redis/6379.conf ---729--- ●appendfsync always: Command write aof buf Call the system immediately after fsync Synchronize operations to AOF Documents, fsync When finished, the thread returns. In this case, each write command must be synchronized to the AOF File, hard disk I0 Become a performance bottleneck, Redis It can only support about a few hundred TPS Write, severely reduced Redis Performance of;Even with solid state drives(SSD),It can only process tens of thousands of commands per second, and it will be greatly reduced SSD Life span. ●appendfsync no: Command write aof buf Post call system write Operation, No AOF File do fsync synchronization;Synchronization is the responsibility of the operating system, and usually the synchronization cycle is 30 seconds. In this case, the time of file synchronization is uncontrollable, and there will be a lot of data accumulated in the buffer, Data security cannot be guaranteed. ●appendfsync everysec: Command write aof_ buf Post call system write Operation, write When finished, the thread returns; fsync The synchronous file operation is called once per second by a dedicated thread. everysec It is a compromise between the above two strategies and a balance between performance and data security Redis The default configuration is also our recommended configuration.
③ File rewrite
With the passage of time, the Redis server executes more and more write commands, and the AOF file will become larger and larger: too large AOF file will not only affect the normal operation of the server, but also lead to too long data recovery time.
File rewriting refers to rewriting AOF files regularly to reduce the volume of AOF files. It should be noted that AOF rewriting is to convert the data in the Redis process into write commands and synchronize them to a new AOF file; The old AOF file will not be read or written!
Another point to note about file rewriting is that although file rewriting is strongly recommended for AOF persistence, it is not necessary; Even without file rewriting, data can be persisted and imported when Redis is started:
Therefore, in some implementations, automatic file rewriting is turned off and then executed at a certain time of the day through a scheduled task.
File rewriting can compress AOF files because:
● expired data is no longer written to the file
● invalid commands are no longer written to the file: for example, some data are repeatedly set (set mykey v1, set mykeyv2), some data are deleted (sadd myset v1, del myset), etc.
● multiple commands can be combined into one: for example, Sadd myset V1, Sadd myset V2 and Sadd myset V3 can be combined into sadd myset v1 v2 v3.
It can be seen from the above that since the commands executed by AOF are reduced after rewriting, file rewriting can not only reduce the space occupied by files, but also speed up the recovery speed.
The trigger of file rewriting can be divided into manual trigger and automatic trigger:
Manual trigger: directly call the bgrewriteaof command. The execution of this command is somewhat similar to that of bgsave: both fork subprocesses perform specific work, and they are blocked only during fork.
● auto trigger: automatically execute BGREWRITEAOF by setting auto AOF rewrite min size option and auto AOF rewrite percentage option.
Only when the auto AOF rewrite min size and auto AOF rewrite percentage options are met at the same time will AOF rewriting be triggered automatically, that is, bgrewriteaof operation.
vim /etc/redis/6379.conf ----729---- auto-aof-rewrite-percentage 100 :current AOF file size(Namely aof_current_size)yes.Last log rewrite AOF file size(aof_base_size)Twice the time, hair living BGREWRITEAOF operation ●auto-aof-rewrite-min-size 64mb :current A0F File execution BGREWRITEAOF The minimum value of the command to avoid starting at the beginning Reids Frequent due to small file size BGREWR ITEAOF
As for the process of file rewriting, two points need special attention:
① Rewriting is performed by the parent process fork child process;
② The write command executed by Redis during rewriting needs to be appended to the new AOF file. Therefore, Redis introduces aof_rewrite buf cache.
Load on startup
When AOF is enabled, Redis will preferentially load AOF files to recover data when it is started; RDB files are loaded to recover data only when AOF is closed
When AOF is turned on but the AOF file does not exist, the RDB file will not be loaded even if it exists.
When redis loads the AOF file, it will verify the AOF file. If the file is damaged, an error will be printed in the log and redis startup fails. However, if the end of the AOF file is incomplete (the end of the file is likely to be incomplete due to sudden machine downtime) and the AOF load truncated parameter is enabled, a warning will be output in the log. Redis ignores the end of the AOF file and starts successfully.
The AOF load truncated parameter is on by default.
Advantages and disadvantages of RDB and AOF
(1) RDB persistence
Advantages: RDB files are compact, small in size, fast in network transmission, and suitable for full replication; Recovery is much faster than AOF. Of course, one of the most important advantages of RDB over AOF is that it has a relatively small impact on performance.
Disadvantages: the fatal disadvantage of RDB file is that its data snapshot persistence mode determines that real-time persistence is inevitable. Today, when data is becoming more and more important, a large amount of data loss is often unacceptable, so AOF persistence
Become the mainstream. In addition, RDB files need to meet specific formats and have poor compatibility (for example, the old version of Redis is not compatible with the new version of RDB files). For RDB persistence, on the one hand, the Redis main process will block when bgsave fork s. On the other hand, the sub process will also bring I0 pressure when writing data to the hard disk.
(2) AOF persistence
Corresponding to RDB persistence, AOF has the advantages of supporting second level persistence and good compatibility. Its disadvantages are large files, slow recovery speed and great impact on performance.
For AOF persistence, the frequency of writing data to the hard disk is greatly increased (second level under everysec Policy), I0 pressure is greater, and even AOF additional blocking may be caused.
The rewriting of AOF files is similar to the bgsave of RDB. There will be blocking during fork and I0 pressure of child processes. Relatively speaking, since AOF writes data to the hard disk more frequently, it will have a greater impact on the performance of Redis main process.
redis performance management
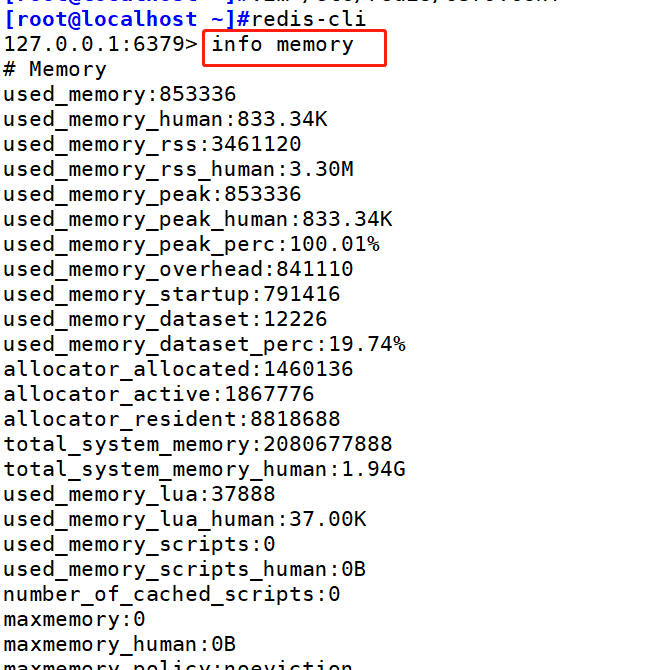
1. View Redis memory usage
192.168.9.236: 7001> info memory
2. Memory fragmentation rate
Operating system allocated memory value used_memory_rss divided by the memory used by Redis used_memory calculates that memory fragmentation is caused by the operating system's inefficient allocation / recycling of physical memory (discontinuous physical memory allocation)
#Tracking the memory fragmentation rate is very important to understand the resource performance of Redis instances:
● it is reasonable that the memory fragmentation rate is slightly greater than 1. This value indicates that the memory fragmentation rate is relatively low
● the memory fragmentation rate exceeds 1.5, indicating that Redis consumes 150 physical memory actually required,
Where 50 is the memory fragmentation rate. You need to enter the shutdown save command on the Redis cli tool and restart the Redis server.
● if the memory fragmentation rate is lower than 1, the Redis memory allocation exceeds the physical memory, and the operating system is exchanging memory. You need to increase available physical memory or reduce Redis memory usage.
3. Memory usage
The memory utilization of the redis instance exceeds the maximum available memory, and the operating system will start exchanging memory and swap space.
#Ways to avoid memory swapping:
● select and install Redis instance according to the cache data size
● use Hash data structure storage as much as possible
● set the expiration time of the key
4. Internal recovery key
Ensure reasonable allocation of redis's limited memory resources.
When the set maximum threshold is reached, you need to select a key recycling policy. By default, the recycling policy is to prohibit deletion.
Modify the maxmemory policy attribute value in the configuration file:
vim /etc/ redis/6379. conf
–598 –
maxmemory-policy noenviction
● volatile LRU: use LRU algorithm to eliminate data from the data set with expiration time
● volatile TTL: select the data that will expire from the data set with expiration time
● volatile random: randomly select data from the data set with expiration time
● allkeys LRU: use LRU algorithm to eliminate data from all data sets
● allkeys random: select any data from the data set
● nonenviction: it is forbidden to eliminate data
summary
Redis Foundation
1. redis is a non relational database (memory / cache)
Compared with other non relational databases, redis has the following advantages:
① Rich data types
② Persistence (the data of memory can be saved on disk) is in the form of RDB and AOF
2. redis cluster mode: sentry, master-slave and cluster
The cluster mode of redis can also be understood as the high availability mode of redis.
Master Slave: it provides backup redundancy. Disadvantages: it cannot automatically repair faults, and write operations cannot be load balanced.
Sentry: it provides the function of automatic fault repair based on master-slave, and the write operation cannot be load balanced.
Cluster: Based on the master-slave basis, it solves the problems of automatic fault repair and write load balancing. At the same time, the resource demand has been improved compared with the first two clusters.
3. Persistence in high availability
RDB and AOF
(1) Persistence mode:
① RDB: periodic snapshot
② AOF: near real-time persistence (in everysec mode)
(2) redis enabled priority
Aof > RDB. redis will use RDB to recover when it is restarted only when the AOF function is turned off
(3) Persistence patterns in RDB and AOF
①RDB:
The child process derived from the (periodic) fork of the redis main process will persist the data in the redis memory and generate it to the rdb file
②AOF:
According to the persistence policy (alawys, no, everysec (default)), the statements in redis are saved in the buffer first, and then synchronized from the buffer to In aof file
4. Recovery strategies / advantages of redis
Like other common non relational databases, redis saves data in memory. When it is saved in memory, when redis is restarted, the memory data is lost, but redis can be restarted in redis through the persistence function of RDB or AOF
After that, the AOF file is read first and the data is recovered based on the AOF file to "persist" the data.