1, Overview of relational database and non relational database
1. Relational database
- Relational database is a structured database, which is created on the basis of relational model (two-dimensional table model) and is generally record oriented.
- SQL statement (standard data query language) is a language based on relational database, which is used to retrieve and operate the data in relational database.
- Mainstream relational databases include Oracle, MySQL, SQL Server, Microsoft Access, DB2, etc.
2. Non relational database
- NoSQL(NoSQL = Not Only SQL), which means "not just SQL", is the general name of non relational databases.
- In addition to the mainstream relational database, all databases are considered to be non relational.
- Mainstream NoSQL databases include Redis, MongBD, Hbase, Memcached, etc.
3. The difference between relational database and non relational database
① Different data storage methods
- The main difference between relational and non relational databases is the way of data storage. Relational data is naturally in table format, so it is stored in rows and columns of the data table. Data tables can be associated with each other, stored cooperatively, and data can be easily extracted.
- On the contrary, non relational data is not suitable to be stored in rows and columns of the data table, but large blocks are combined together. Non relational data is usually stored in data sets, such as documents, key value pairs, or graph structures. Your data and its characteristics are the primary factors affecting the choice of data storage and extraction methods.
② Different expansion modes
- The biggest difference between SQL and NoSQL databases may be in the expansion mode. To support the growing demand, of course, it needs to be expanded.
- To support more concurrency, the SQL database is vertically expanded, that is, to improve processing capacity and use faster computers, so that the same data set can be processed faster. Because the data is stored in relational tables, the performance bottleneck of the operation may involve many tables, which need to be solved by improving the computer performance. Although SQL database has a large expansion space, it will eventually reach the upper limit of vertical expansion.
- NoSQL database is horizontally expanded. Because non relational data storage is naturally distributed, the expansion of NoSQL database can share the load by adding more common database servers (nodes) to the resource pool.
③ Support for transactional is different
- If the data operation needs high transaction or complex data query needs to control the execution plan, the traditional SQL database is your best choice in terms of performance and stability. SQL database supports fine-grained control over the atomicity of transactions and is easy to roll back transactions.
- Although NoSQL databases can also use transaction operations, they cannot be compared with relational databases in terms of stability, so their real shining value is in the scalability of operations and large amount of data processing.
4. Background of non relational database
- Can be used to deal with web2 0 three high problems of pure dynamic website type
- High performance -- high concurrent read and write requirements for database
- Huge Storage -- Requirements for efficient storage and access of massive data
- High scalability & & high availability -- demand for high scalability and availability of database
- Both relational database and non relational database have their own characteristics and application scenarios. The close combination of the two will give web2 0 database development brings new ideas. Let relational databases focus on relationships and non relational databases focus on storage. For example, in a MySQL database environment with separate reading and writing, frequently accessed data can be stored in a non relational database to improve access speed.
2, Introduction to Redis
- Redis is an open source NoSQL database written in C language.
- Redis runs based on memory and supports persistence. It adopts the storage form of key value (key value pair). It is an indispensable part of the current distributed architecture.
1. Single thread mode of Redis
- Redis server program is a single process model, that is, multiple redis processes can be started on one server at the same time. The actual processing speed of redis completely depends on the execution efficiency of the main process.
- If only one Redis process is running on the server, when multiple clients access at the same time, the processing capacity of the server will be reduced to a certain extent
- If multiple Redis processes are started on the same server, Redis will put great pressure on the CPU of the server while improving the concurrent processing capacity.
- In the actual production environment, you need to decide how many Redis processes to start according to the actual needs. If the requirements for high concurrency are higher, you may consider starting multiple processes on the same server. If CPU resources are tight, single process can be used.
2. Advantages of Redis
- It has extremely high data reading and writing speed: the maximum data reading speed can reach 110000 times / s, and the maximum data writing speed can reach 81000 times / s.
- Support rich data types: support key value, Strings, Lists, Hashes, Sets, Ordered Sets and other data type operations.
- String: string (can be integer, floating-point and string, commonly referred to as element)
- List: list (implement queue, elements are not unique, first in first out principle)
- Set: set (different elements)
- Hash: hash hash value (the key of hash must be unique)
- set /ordered set: set /ordered set
- Support data persistence: the data in memory can be saved in disk and can be loaded again for use when restarting.
- Atomicity: all Redis operations are atomicity.
- Support data backup: data backup in master save mode.
Redis is a memory based database, and caching is one of its most common application scenarios. In addition, the common application scenarios of redis also include the operation of obtaining the latest N data, ranking application, counter application, storage relationship, real-time analysis system and logging.
3, Redis deployment
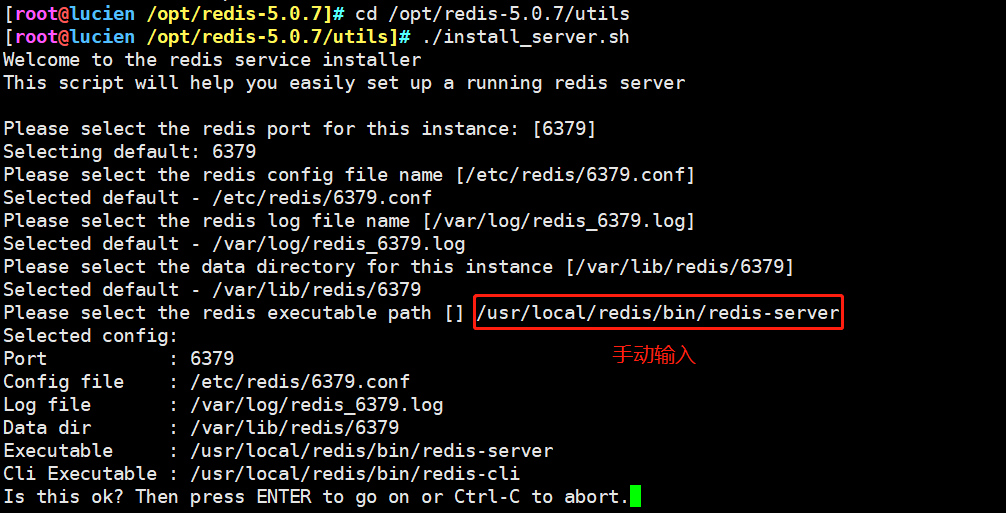
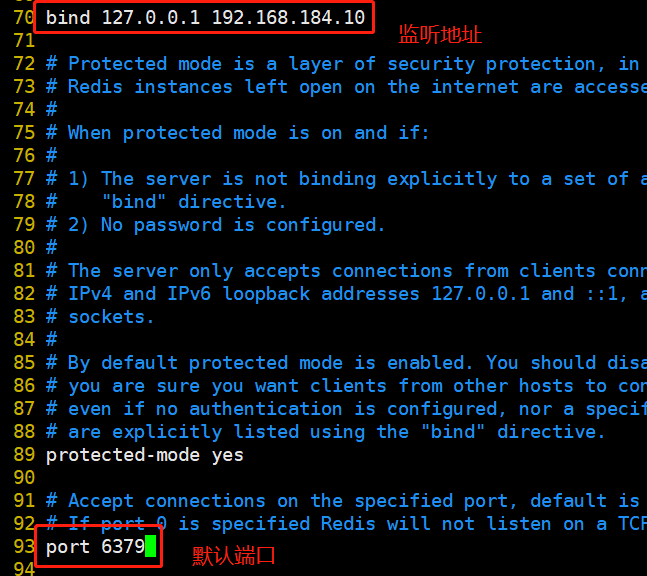
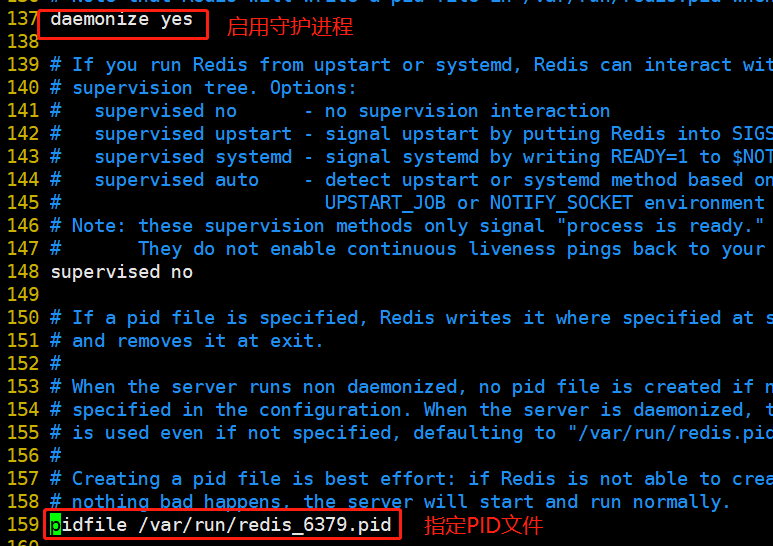
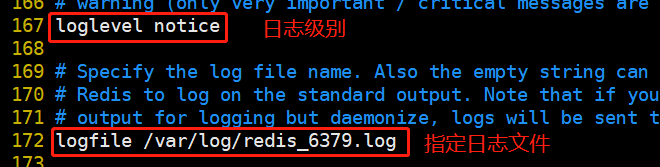
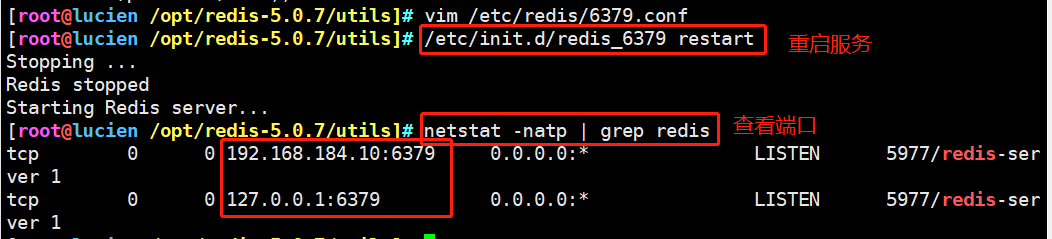
systemctl stop firewalld setenforce 0 yum install -y gcc gcc-c++ make cd /opt tar zxvf redis-5.0.7.tar.gz cd /opt/redis-5.0.7/ make make PREFIX=/usr/local/redis install #Since the makefile file is directly provided in the Redis source package, there is no need to execute it first after decompressing the software/ configure. You can directly execute the make and make install commands to install #Execute the install provided in the software package_ server. SH script file sets the relevant configuration files required by Redis service cd /opt/redis-5.0.7/utils ./install_server.sh #Keep returning Please select the redis executable path [/usr/local/bin/redis-server] /usr/local/redis/bin/redis-server #It needs to be manually modified to / usr / local / redis / bin / redis server ---------------------------------------------------------------------------- Selected config: Port : 6379 #Default listening port 6379 Config file : /etc/redis/6379.conf #Profile path Log file : /var/log/redis_6379.log #log file path Data dir : /var/lib/redis/6379 #Data file path Executable : /usr/local/redis/bin/redis-server #Executable path Cli Executable : /usr/local/redis/bin/redis-cli #Client command tool ----------------------------------------------------------------------------- #Put the redis executable file into the directory of the path environment variable ln -s /usr/local/redis/bin/* /usr/local/bin/ /etc/init.d/redis_6379 stop #stop it /etc/init.d/redis_6379 start #start-up /etc/init.d/redis_6379 restart #restart /etc/init.d/redis_6379 status #state #Modify the configuration / etc / redis / 6379 Conf parameter vim /etc/redis/6379.conf bind 127.0.0.1 192.168.184.10 #Line 70, add the listening host address port 6379 #Line 93: Redis's default listening port daemonize yes #Line 137, enable the daemon pidfile /var/run/redis_6379.pid #Line 159, specify PID file loglevel notice #167 lines, log level logfile /var/log/redis_6379.log #172 line, specify log file /etc/init.d/redis_6379 restart netstat -natp | grep redis

4, Redis command tool
redis-server #Tool for starting Redis redis-cli #Redis command line tool redis-benchmark #It is used to detect the operation efficiency of Redis on this machine redis-check-aof #Fix AOF persistent file redis-check-rdb #Repair RDB persistent file
1. Redis cli command line tool
redis-cli -h host -p port -a password -h Specify remote host -p appoint Redis Port number of the service -a Specify the password. If the database password is not set, it can be omitted-a option If no option representation is added, 127 is used.0.0.1:6379 Connect the on this machine Redis database

2. Redis benchmark test tool
- Redis benchmark is the official redis performance testing tool, which can effectively test the performance of redis services.
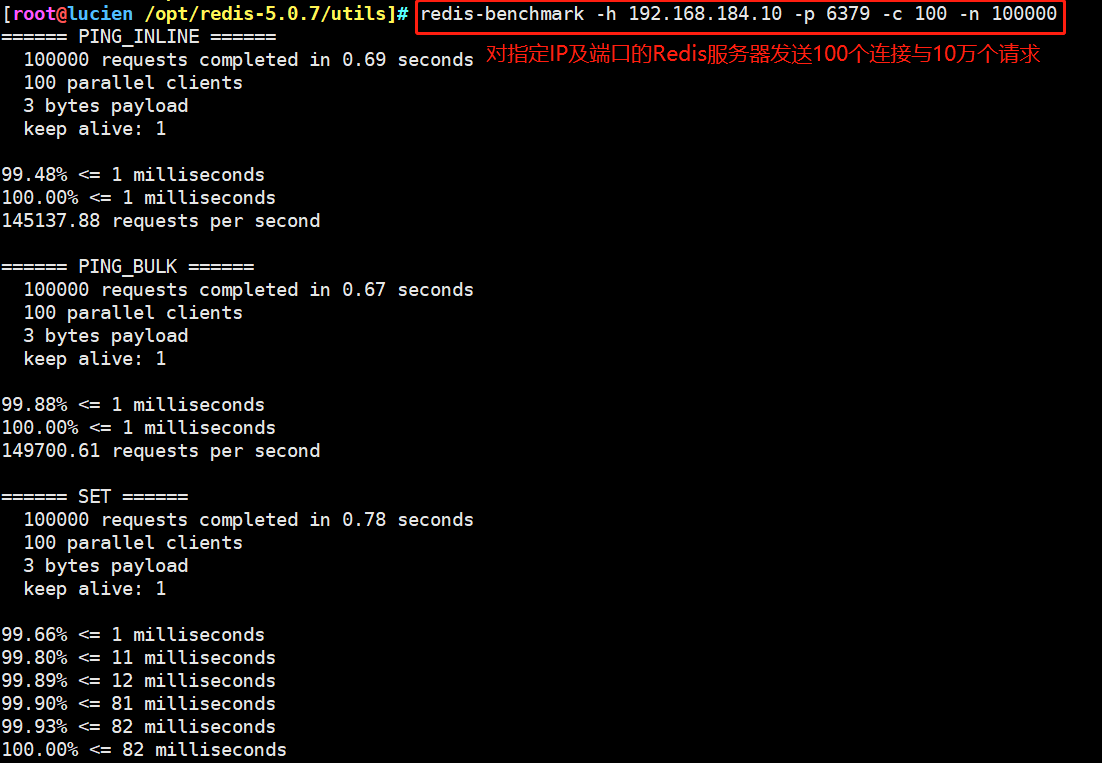
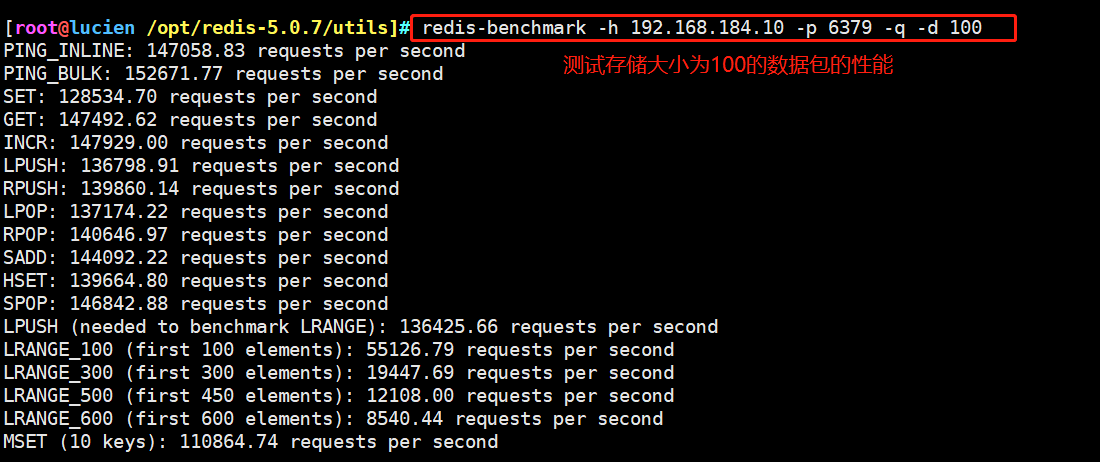
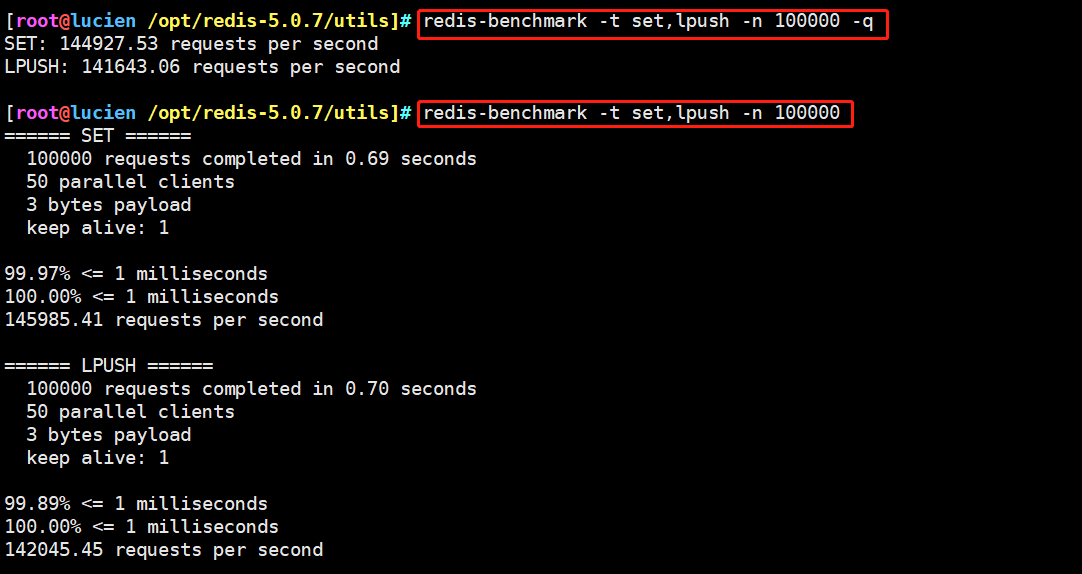
redis-benchmark [option] [Option value] -h Specify the server host name. -p Specify the server port. -s Specify server socket -c Specifies the number of concurrent connections. -n Specify the number of requests. -d Specified in bytes SET/GET The data size of the value. -k 1=keep alive 0=reconnect . -r SET/GET/INCR Use random key, SADD Use random values. -P Pipeline requests. -q forced return redis. Show only query/sec Value. –csv with CSV Format output. -l Generate a loop and permanently execute the test. -t Run only a comma separated list of test commands. -I Idle pattern. Open only N individual idle Connect and wait. Example: towards IP The address is 192.168.184.10,Port 6379 Redis The server sends 100 concurrent connections and 100000 requests to test the performance redis-benchmark -h 192.168.184.10 -p 6379 -c 100 -n 100000 Test the performance of accessing packets with a size of 100 bytes redis-benchmark -h 192.168.184.10 -p 6379 -q -d 100 Test on this machine Redis Service in progress set And lpush Performance during operation redis-benchmark -t set,lpush -n 100000 -q
5, Common commands of Redis database
set: Store data, and the command format is set key value get: Get data, command format is get key

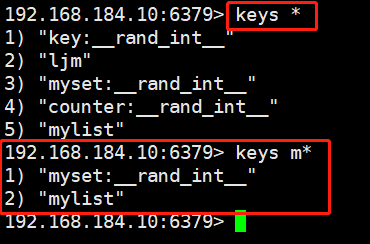
#keys The command can take the list of key values that meet the rules. Usually, it can be combined with *? And other options. keys * #View all data in the current database keys v* #View data starting with v in the current database keys v?? #View the data that starts with v and then contains any bit in the current database keys v?? #View the data that starts with v and contains any two digits in the current database
#exists The command can determine whether the key value exists. exists [key] A return value of 1 indicates existence, and 0 indicates nonexistence #del The command can delete the specified key of the current database. del [key] #type The command can obtain the value type corresponding to the key. type [key]
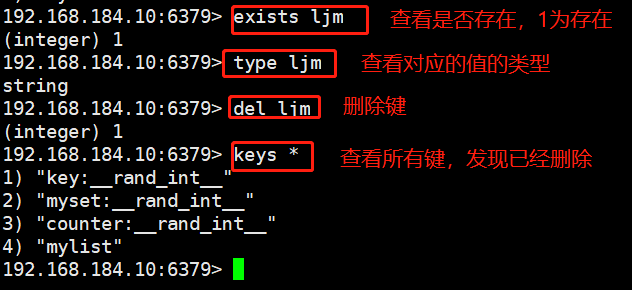
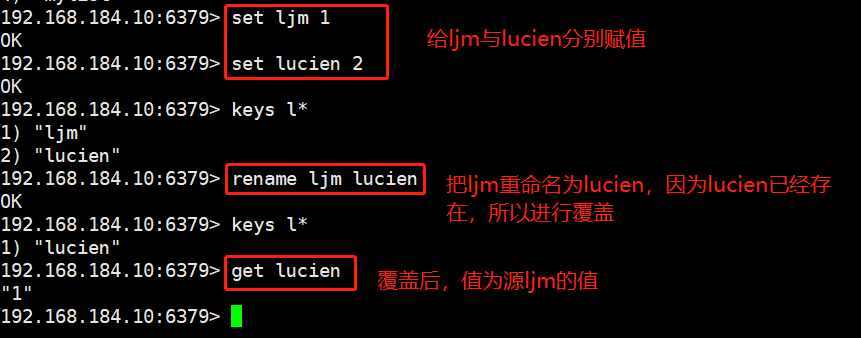
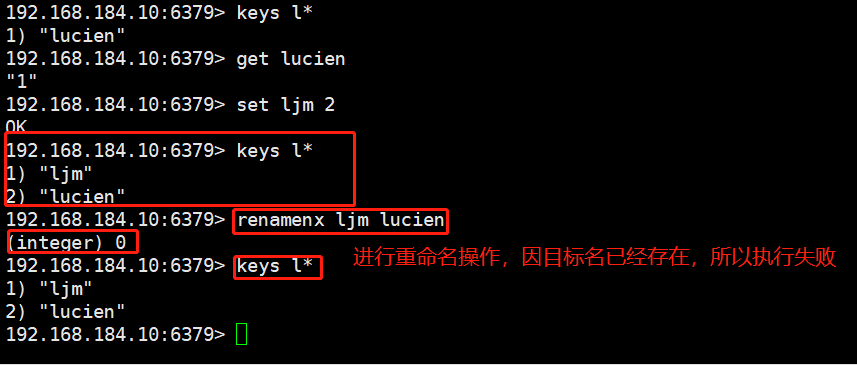
#The rename command renames an existing key. (overlay) rename source key target key use rename When renaming with the command, regardless of the target key Rename whether there are any and the source key The value of overwrites the target key Value of. In actual use, it is recommended to use it first exists Command view target key Whether it exists, and then decide whether to implement it rename Command to avoid overwriting important data. #The rename x command renames an existing key and detects whether the new name exists. If the target key exists, it will not be renamed. (not covered) renamenx source key target key
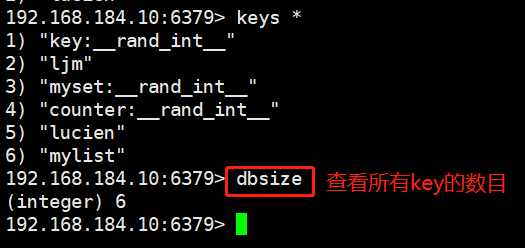
#The dbsize command is used to view the number of key s in the current database.
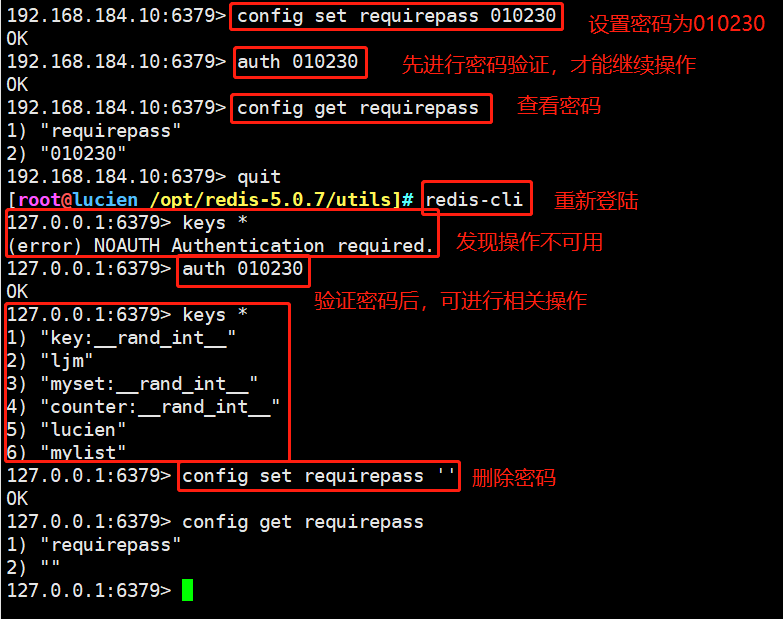
#Set password config set requirepass password #Check the password (once the password is set, the password must be verified first, otherwise all operations are unavailable) auth password config get requirepass #Delete password auth password config get requirepass '' Example: config set requirepass 010230 auth 010230 config get requirepass auth 010230 config get requirepass ''
6, Common commands of Redis multi database
- Redis supports multiple databases. By default, redis contains 16 databases, and the database names are named sequentially with the numbers 0-15.
- Multiple databases are independent and do not interfere with each other.
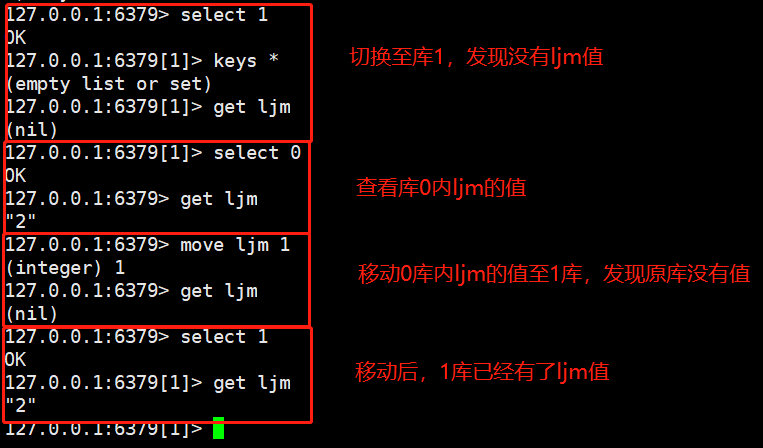
#Switching between multiple databases select Serial number use redis-cli connect Redis After the database, the database with sequence number 0 is used by default.
#Moving data between multiple databases move Key value serial number Example: select 1 get lucien select 0 get lucien move lucien 1 get lucien select 5 get lic select 0 get lucien
Clear data in database FLUSHDB : Clear current database data FLUSHALL : Clear the data of all databases and use it with caution!
7, Redis high availability
- In the web server, high availability refers to the time when the server can be accessed normally. The measurement standard is how long it can provide normal services (99.9%, 99.99%, 99.999%, etc.).
- However, in the context of Redis, the meaning of high availability seems to be broader. In addition to ensuring the provision of normal services (such as master-slave separation and rapid disaster recovery technology), it is also necessary to consider the expansion of data capacity and data security without loss.
1. Major high availability technologies
- Persistence: persistence is the simplest high availability method (sometimes it is not even classified as a high availability method). Its main function is data backup, that is, data is stored on the hard disk to ensure that data will not be lost due to process exit.
- Master-slave replication: master-slave replication is the basis of highly available Redis. Sentinels and clusters achieve high availability on the basis of master-slave replication. Master-slave replication mainly realizes multi machine backup of data, load balancing for read operation and simple fault recovery. Defect: failure recovery cannot be automated; The write operation cannot be load balanced; The storage capacity is limited by a single machine.
- Sentry: Based on master-slave replication, sentry realizes automatic fault recovery. Defect: write operation cannot be load balanced; The storage capacity is limited by a single machine.
- Cluster: through cluster, Redis solves the problem that the write operation cannot be load balanced and the storage capacity is limited by a single machine, and realizes a relatively perfect high availability scheme.