1, Redis Cluster
Redis Cluster is a distributed solution officially provided by redis. When encountering bottlenecks such as memory, concurrency and traffic, Cluster architecture can be used to achieve the purpose of load balancing. Official documents: https://redis.io/topics/cluster-tutoria
1. Why use redis cluster cluster?
1.first Redis Single instance mainly has the problems of single point, limited capacity and upper limit of flow and pressure. Redis Single point of failure can be replicated through master-slave replication,And automatic failover sentinel Sentinel mechanism. but Redis single Master The instance provides read-write services, and there are still capacity and pressure problems. Therefore, it is necessary to partition data and build multiple instances Master The instance also provides read-write services (not only from replica Node provides read service). 2.Concurrency problem redis Officials say it can reach 100000/s,100000 commands per second What if the business needs 1 million commands per second? The solution is as follows 1.The right thing is to consider distributed, add machines, distribute data to different locations, share centralized pressure, and do one thing with a pile of machines.It also needs a certain mechanism to ensure that the data is partitioned, and the data is distributed in each master Master Nodes should not be confused. Of course, it is best to support online data hot migration.
2. What is redis cluster
Why build a redis cluster. Redis stores data in memory, but our computers generally have little memory, which means that redis is not suitable for storing big data. Redis is more suitable for dealing with high concurrency. The storage capacity of one device is very limited, but the cooperation of multiple devices can increase the internal memory many times, which requires clustering.
Redis There are many ways to build clusters, such as using client fragmentation Twemproxy,Codis Wait, but from redis 3.0 Later versions support redis-cluster Cluster, it is Redis Official solutions: Redis-Cluster The central structure is adopted, and each node saves data and the whole cluster state,Each node is connected to all other nodes. his Redis-cluster The architecture diagram is as follows:
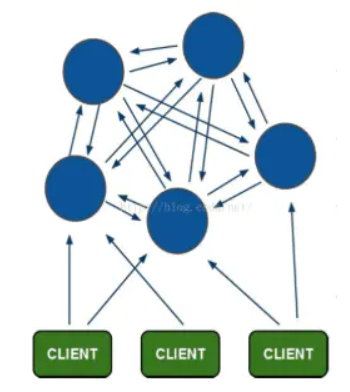
2.1.redis cluster features
1.be-all redis Nodes are interconnected(PING-PONG mechanism),Binary protocol is used internally to optimize transmission speed and bandwidth. 2.Client and redis Node direct connection,No intermediate is required proxy layer.The client does not need to connect to all nodes of the cluster,Connect to any available node in the cluster. 3.Nodal fail It takes effect only when more than half of the nodes in the cluster detect failure.
2.2 redis cluster data distribution
There are 16384 hash slots in the redis cluster. Each redis instance is responsible for some slots. All information in the cluster is updated through node data exchange. There are many key s and value s in a hash slot.
2.3 principle of data distributed storage
Redis cluster uses data sharding: 16384 hashing slots are built in redis cluster. When a key value needs to be placed in redis cluster, redis first uses crc16 algorithm to calculate a result for the key, and then calculates the remainder of the result for 16384 (the cluster uses the common formula crc16 (key)% 16384), In this way, each key will correspond to a hash slot numbered between 0-16384, and redis will assign this key to the nodes in the corresponding range. Similarly, when any node connecting three nodes wants to obtain the key, it will use the same algorithm, and then jump internally to the node storing the key to obtain data.
For example, the values of three nodes: hash slot distribution are as follows:
cluster1: 0-5460 cluster2: 5461-10922 cluster3: 10923-16383
cluster1: 0-5460 cluster2: 5461-10922 cluster3: 10923-16383
This method of distributing Hashi slots to different nodes makes it easy for users to add or delete nodes to the cluster. for instance:
- If the user adds A new node d to the cluster, the cluster only needs to move some slots in nodes A, B and C to node D.
- If the user wants to remove node A from the cluster, the cluster only needs to move all hash slots in node A to node B and node C, and then remove the blank (excluding any hash slots) node A.
Because moving a hash slot from one node to another will not cause node blocking, whether adding a new node, removing an existing node, or changing the number of hash slots contained in a node will not cause the cluster to go offline.
3. Redis Cluster master-slave mode
redis cluster In order to ensure the high availability of data, the master-slave mode is added. A master node corresponds to one or more slave nodes. The master node provides data access, and the slave node pulls data backups from the master node. When the master node hangs up, the slave node will select one to act as the master node, so as to ensure that the cluster will not hang up. 1.Master-slave switching mechanism The election process is all in the cluster master participate in,If more than half master Communication between node and fault node exceeds(cluster-node-timeout),If the node is considered to be faulty, the failover operation will be triggered automatically. #The slave node corresponding to the failed node is automatically upgraded to the master node 2.When will the whole cluster become unusable? If any primary node of the cluster hangs up,If the current master node does not have a slave node, the cluster cannot continue because we no longer have a way to provide services for the hash slot within the range of this node. However, if the master node and the corresponding slave node fail at the same time, then Redis Cluster Cannot continue.
2, Cluster deployment
Environmental preparation: 1.Prepare three machines, turn off the firewall and selinux 2.Make analysis and analyze each other. notes:There are two schemes for planning architecture. One is single machine multi instance. Here we use multi machine deployment: Three machines, two on each machine redis Instance, one master One slave,The first column is the main warehouse and the second column is the standby warehouse #Remember to select the control node redis-cluster1 192.168.116.172 7000,7001 redis-cluster2 192.168.116.173 7002,7003 redis-cluster3 192.168.116.174 7004,7005
1. The three machines operate in the same way
1.install redis [root@redis-cluster1 ~]# mkdir /data [root@redis-cluster1 ~]# yum -y install gcc automake autoconf libtool make [root@redis-cluster1 ~]# wget https://download.redis.io/releases/redis-6.2.0.tar.gz [root@redis-cluster1 ~]# tar xzvf redis-6.2.0.tar.gz -C /data/ [root@redis-cluster1 ~]# cd /data/ [root@redis-cluster1 data]# mv redis-6.2.0/ redis [root@redis-cluster1 data]# cd redis/ [root@redis-cluster1 redis]# make #compile [root@redis-cluster1 redis]# mkdir /data/redis/data #Create a directory for storing data
2.Create node directory:According to the plan redis Create a corresponding directory (named after the port number) in the installation directory of the node [root@redis-cluster1 redis]# pwd /data/redis [root@redis-cluster1 redis]# mkdir cluster #Create cluster directory [root@redis-cluster1 redis]# cd cluster/ [root@redis-cluster1 cluster]# mkdir 7000 7001 #Create node directory [root@redis-cluster2 redis]# mkdir cluster [root@redis-cluster2 redis]# cd cluster/ [root@redis-cluster2 cluster]# mkdir 7002 7003 [root@redis-cluster3 redis]# mkdir cluster [root@redis-cluster3 redis]# cd cluster/ [root@redis-cluster3 cluster]# mkdir 7004 7005
3.Copy the configuration file to the node directory,#The three machines operate in the same way [root@redis-cluster1 cluster]# cp /data/redis/redis.conf 7000/ [root@redis-cluster1 cluster]# cp /data/redis/redis.conf 7001/ [root@redis-cluster2 cluster]# cp /data/redis/redis.conf 7002/ [root@redis-cluster2 cluster]# cp /data/redis/redis.conf 7003/ [root@redis-cluster3 cluster]# cp /data/redis/redis.conf 7004/ [root@redis-cluster3 cluster]# cp /data/redis/redis.conf 7005/
4.Modify each cluster redis Configuration file.(Mainly ports ip,pid File, three machines operate the same),Amend as follows: [root@redis-cluster1 cluster]# cd 7000/ [root@redis-cluster1 7000]# vim redis.conf #Amend as follows bind 192.168.116.172 #The configuration file of each instance is modified to the ip address of the corresponding node port 7000 #Listening port. When running multiple instances, you need to specify a different port number for each planned instance daemonize yes #redis running in the background pidfile /var/run/redis_7000.pid #pid file. When running multiple instances, you need to specify different pid files logfile /var/log/redis_7000.log #Log file location. When running multiple instances, the files need to be modified differently. dir /data/redis/data #Directory where data is stored appendonly yes #When AOF persistence is enabled, redis will append every write operation request received to the appendonly.aof file. When redis restarts, it will restore the previous state from the file. appendfilename "appendonly.aof" #AOF file name appendfsync everysec #Indicates that write operations are accumulated and synchronized once per second The following is an example of opening a comment and modifying it cluster-enabled yes #Enable cluster cluster-config-file nodes-7000.conf #The cluster configuration file is automatically updated by redis and does not need to be manually configured. When running multiple instances, please note that it is modified to the corresponding port cluster-node-timeout 5000 #In milliseconds. The timeout time of cluster node, that is, the disconnection time threshold of the master and slave nodes in the cluster. If it exceeds this value, it is considered that the master node is not allowed, and the slave node may become the master cluster-replica-validity-factor 10 #During failover, all slaves will request to be applied as the master. However, some slaves may be disconnected from the master for a period of time, resulting in outdated data and should not be promoted to the master. This parameter is used to judge whether the disconnection time between the slave node and the master is too long. (calculation method: cluster node timeout * cluster replica validity factor, here: 5000 * 10ms) cluster-migration-barrier 1 #A host will keep the minimum number of slaves connected so that another slave can migrate to a host that is no longer covered by any slave cluster-require-full-coverage yes #All slot s (16384) in the cluster are covered before services can be provided #Note: All node configuration files are modified. Remember to modify ip,Port pid file...Avoid conflict. Make sure that all machines are modified.
5.Start each node on the three machines(The three machines operate in the same way) [root@redis-cluster1 ~]# cd /data/redis/src/ [root@redis-cluster1 src]# ./redis-server ../cluster/7000/redis.conf [root@redis-cluster1 src]# ./redis-server ../cluster/7001/redis.conf [root@redis-cluster2 7003]# cd /data/redis/src/ [root@redis-cluster2 src]# ./redis-server ../cluster/7002/redis.conf [root@redis-cluster2 src]# ./redis-server ../cluster/7003/redis.conf [root@redis-cluster3 7005]# cd /data/redis/src/ [root@redis-cluster3 src]# ./redis-server ../cluster/7004/redis.conf [root@redis-cluster3 src]# ./redis-server ../cluster/7005/redis.conf
View port



6.Create cluster: operate on one of the nodes redis After the node is built, it needs to be completed redis cluster Cluster building: in the process of cluster building, 6 clusters need to be guaranteed redis All instances are running. Redis Is based on IP and Port The order of, determine master and slave , so we should arrange the order before execution. parameter: --cluster-replicas 1:Represents creating a slave node for each master node in the cluster.Writing process:Master node ip+port Corresponding to a slave node ip+port(be careful:If the nodes are on different machines, pay attention to the writing position of the master node to avoid that the master node is on the same machine, which will affect the performance. Normally, the first three nodes are the master nodes, and the latter are the slave nodes) [root@redis-cluster1 src]# cd /data/redis/src/ [root@redis-cluster1 src]# ./redis-cli --cluster create --cluster-replicas 1 192.168.116.172:7000 192.168.116.172:7001 192.168.116.173:7002 192.168.116.173:7003 192.168.116.174:7004 192.168.116.174:7005 >>> Performing hash slots allocation on 6 nodes... Master[0] -> Slots 0 - 5460 Master[1] -> Slots 5461 - 10922 Master[2] -> Slots 10923 - 16383 Adding replica 192.168.116.173:7003 to 192.168.116.172:7000 Adding replica 192.168.116.174:7005 to 192.168.116.173:7002 Adding replica 192.168.116.172:7001 to 192.168.116.174:7004 M: de5b4b2f6a559362ed56d4de1e3994fd529917b5 192.168.116.172:7000 slots:[0-5460] (5461 slots) master S: 2e8c1caa63ac4a1b9a6eea4f0fd5eab4c6b73c21 192.168.116.172:7001 replicates 60e3755761c9cbdacb183f59e3d6205da5335e86 M: e0370608cd33ddf5bb6de48b5627799e181de3b6 192.168.116.173:7002 slots:[5461-10922] (5462 slots) master S: 4035841f20f07674671e6bff5d4c6db99c00626b 192.168.116.173:7003 replicates de5b4b2f6a559362ed56d4de1e3994fd529917b5 M: 60e3755761c9cbdacb183f59e3d6205da5335e86 192.168.116.174:7004 slots:[10923-16383] (5461 slots) master S: e200afc33b10bd6975160bfeda7277d02371981a 192.168.116.174:7005 replicates e0370608cd33ddf5bb6de48b5627799e181de3b6 Can I set the above configuration? (type 'yes' to accept): yes #Write yes agree >>> Nodes configuration updated >>> Assign a different config epoch to each node >>> Sending CLUSTER MEET messages to join the cluster Waiting for the cluster to join . >>> Performing Cluster Check (using node 192.168.116.172:7000) M: de5b4b2f6a559362ed56d4de1e3994fd529917b5 192.168.116.172:7000 slots:[0-5460] (5461 slots) master 1 additional replica(s) M: e0370608cd33ddf5bb6de48b5627799e181de3b6 192.168.116.173:7002 slots:[5461-10922] (5462 slots) master 1 additional replica(s) S: 2e8c1caa63ac4a1b9a6eea4f0fd5eab4c6b73c21 192.168.116.172:7001 slots: (0 slots) slave replicates 60e3755761c9cbdacb183f59e3d6205da5335e86 M: 60e3755761c9cbdacb183f59e3d6205da5335e86 192.168.116.174:7004 slots:[10923-16383] (5461 slots) master 1 additional replica(s) S: 4035841f20f07674671e6bff5d4c6db99c00626b 192.168.116.173:7003 slots: (0 slots) slave replicates de5b4b2f6a559362ed56d4de1e3994fd529917b5 S: e200afc33b10bd6975160bfeda7277d02371981a 192.168.116.174:7005 slots: (0 slots) slave replicates e0370608cd33ddf5bb6de48b5627799e181de3b6 [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered.
7.Viewing the cluster status can connect to any node in the cluster, where node 192 in the cluster is connected.168.116.172:7000 # Log in to the cluster client, - c ID log in as a cluster [root@redis-cluster1 src]# ./redis-cli -h 192.168.116.172 -c -p 7000 192.168.116.172:7000> ping PONG 192.168.116.173:7002> cluster info #View cluster information cluster_state:ok #Cluster status cluster_slots_assigned:16384 #Allocated slot cluster_slots_ok:16384 cluster_slots_pfail:0 cluster_slots_fail:0 cluster_known_nodes:6 #Number of cluster instances ...... 192.168.116.172:7000> cluster nodes #View cluster instances
3, Cluster operation
1. Client login
Test link redis,Access data(Just link any machine in the cluster.) Storage: [root@redis-cluster1 src]# ./redis-cli -h 192.168.116.172 -c -p 7000 192.168.116.172:7000> ping PONG 192.168.116.172:7000> set name qianfeng -> Redirected to slot [5798] located at 192.168.116.173:7002 OK 192.168.116.173:7002> read [root@redis-cluster3 src]# ./redis-cli -h 192.168.116.173 -c -p 7002 192.168.116.173:7002> ping PONG 192.168.116.173:7002> get name "qianfeng" 192.168.116.173:7002> exists name #Check whether a key exists (integer) 1
2. Add node to cluster
preparation:
1.Prepare a new machine, modify the host name, close the firewall and selinux.
2.Install the same version redis,Single machine multi instance. Configure the master-slave port profile.
New preparation cluster4,The first column is master The second column is slave.
192.168.116.175 redis-cluster4 7006 7007
[root@redis-cluster4 ~]# mkdir /data
[root@redis-cluster4 ~]# yum -y install gcc automake autoconf libtool make
[root@redis-cluster4 ~]# wget https://download.redis.io/releases/redis-6.2.0.tar.gz
[root@redis-cluster4 ~]# tar xzvf redis-6.2.0.tar.gz -C /data/
[root@redis-cluster4 ~]# cd /data/
[root@redis-cluster4 data]# mv redis-6.2.0/ redis
[root@redis-cluster4 data]# cd redis/
[root@redis-cluster4 redis]# make #compile
[root@redis-cluster4 redis]# mkdir data #Create data directory
[root@redis-cluster4 redis]# mkdir cluster
[root@redis-cluster4 redis]# mkdir cluster/{7006,7007} #Create cluster node
[root@redis-cluster4 redis]# cp redis.conf cluster/7006/
[root@redis-cluster4 redis]# cp redis.conf cluster/7007/
Start modifying configuration file...As before, pay attention to the changes:Port ip,pid file...
start-up
[root@redis-cluster4 src]# ./redis-server ../cluster/7006/redis.conf
[root@redis-cluster4 src]# ./redis-server ../cluster/7007/redis.conf
1.When you are ready, start adding nodes: cluster4 Add to cluster
[root@redis-cluster4 src]# ./redis-cli --cluster add-node 192.168.116.175:7006 192.168.116.172:7000
>>> Adding node 192.168.116.175:7006 to cluster 192.168.116.172:7000
......
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Send CLUSTER MEET to node 192.168.116.175:7006 to make it join the cluster.
[OK] New node added correctly.
View cluster node information(Just log in to a client)
[root@redis-cluster1 src]# ./redis-cli -h 192.168.116.172 -c -p 7000
192.168.116.172:7000> CLUSTER nodes

Detailed explanation: runid: The name of the node described in this line id. ip:prot: The name of the node described in this line ip and port flags: Comma separated tag bits. Possible values are: 1.master: The node described in this line is master 2.slave: The node described in this line is slave 3.fail?:The node described in this line may not be available 4.fail:The node described in this line is unavailable (failed) master_runid: The name of the node described in this line master of id,If it is master Then display- ping-sent: Last sent ping of Unix Timestamp, 0 means not sent pong-recv: Last received pong of Unix Timestamp, 0 means not received config-epoch: Number of master-slave switches link-state: Connection status, connnected and disconnected hash slot: This line describes master Stored in key of hash Scope of
2.Give new node hash Slot allocation The new node needs to be modified hash Slot allocation so that the main section can store data. (if there is data, remember to synchronize the data in advance, and then migrate the slot from other nodes to the new node.) [root@redis-cluster1 src]# ./redis-cli --cluster reshard 192.168.116.175:7006 >>> Performing Cluster Check (using node 192.168.116.175:7006) ...... [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered. How many slots do you want to move (from 1 to 16384)? 4000 #Enter the number of slots to allocate What is the receiving node ID? 828c48dc72d52ff5be972512d3d87b70236af87c #Enter the node id of the receiving slot and view the newly added 192.168.116.175:7006 id through cluster nodes Please enter all the source node IDs. Type 'all' to use all the nodes as source nodes for the hash slots. Type 'done' once you entered all the source nodes IDs. Input: all Then enter yes confirm Pass again at this time cluster nodes Viewing the node, you can see that the slot assigned by the new node is 0-1332 5461-6794 10923-12255 [root@redis-cluster1 src]# ./redis-cli -h 192.168.116.172 -c -p 7000 192.168.116.172:7000> CLUSTER nodes

3.Add the corresponding slave node to the newly added master node: [root@redis-cluster4 src]# ./redis-cli --cluster add-node 192.168.116.175:7007 192.168.116.175:7006 --cluster-slave --cluster-master-id 308320db4284c9b203aff1d3d9a145616856f681 #id of master >>> Adding node 192.168.116.175:7007 to cluster 192.168.116.175:7006 >>> Performing Cluster Check (using node 192.168.116.175:7006) ...... [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered. >>> Send CLUSTER MEET to node 192.168.116.175:7007 to make it join the cluster. Waiting for the cluster to join >>> Configure node as replica of 192.168.116.175:7006. [OK] New node added correctly. View cluster information 192.168.116.172:7000> CLUSTER nodes

4.Balance the slots of each master node: [root@redis-cluster1 src]# ./redis-cli --cluster rebalance --cluster-threshold 1 192.168.116.172:7000 >>> Performing Cluster Check (using node 192.168.116.172:7000) [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered. >>> Rebalancing across 4 nodes. Total weight = 4.00 Moving 32 slots from 192.168.116.174:7004 to 192.168.116.175:7006 ################################ Moving 32 slots from 192.168.116.173:7002 to 192.168.116.175:7006 ################################ Moving 32 slots from 192.168.116.172:7000 to 192.168.116.175:7006 ################################ Login test: [root@redis-cluster1 src]# ./redis-cli -h 192.168.116.175 -c -p 7007 192.168.116.175:7007> ping PONG 192.168.116.175:7007> get name -> Redirected to slot [5798] located at 192.168.116.175:7006 "qianfeng"
3. Delete node
#Note: what needs to be mentioned in this place is If you want to offline node 6 and node 7, be sure to offline the slave node first and slot If the offline node 6 is migrated to other nodes, failover will occur, and node 7 will become the master node Removing a redis Before the node, you cannot log in to the node, otherwise you cannot remove the node normally. 1.Exit all linked clients and execute on any machine [root@redis-cluster1 src]# ./redis-cli --cluster del-node 192.168.116.175:7007 dbad32bd47cc177de61109b96447d1f1ef6db2fc #id of the node >>> Removing node dbad32bd47cc177de61109b96447d1f1ef6db2fc from cluster 192.168.116.175:7007 >>> Sending CLUSTER FORGET messages to the cluster... >>> Sending CLUSTER RESET SOFT to the deleted node. [root@redis-cluster1 src]# ./redis-cli -h 192.168.116.172 -c -p 7000 192.168.116.172:7000> CLUSTER NODES

2.Delete master node: node with slot View the number of slots per node [root@redis-cluster1 src]# ./redis-cli --cluster info 192.168.116.172:7000 192.168.116.172:7000 (de5b4b2f...) -> 0 keys | 4096 slots | 1 slaves. 192.168.116.173:7002 (e0370608...) -> 0 keys | 4096 slots | 1 slaves. 192.168.116.174:7004 (60e37557...) -> 0 keys | 4096 slots | 1 slaves. 192.168.116.175:7006 (308320db...) -> 2 keys | 4096 slots | 0 slaves. [OK] 2 keys in 4 masters. Current master node hash slot status to delete: 0-1364 5461-6826 10923-12287 Shared hash slot=1365 + 1366 + 1365 = 4096 individual 1.Migrate the slot on node 6 to another node: ip+port: Node to remove cluster-from:To remove a node id cluster-to:Accept slot master id,The 4096 needs to be moved to different master nodes on average, and the master nodes with different receiving slots need to be written id cluster-slots:Number of slots removed [root@redis-cluster1 src]# ./redis-cli --cluster reshard 192.168.116.175:7006 --cluster-from 308320db4284c9b203aff1d3d9a145616856f681 --cluster-to e0370608cd33ddf5bb6de48b5627799e181de3b6 --cluster-slots 1365 --cluster-yes [root@redis-cluster1 src]# ./redis-cli --cluster reshard 192.168.116.175:7006 --cluster-from 308320db4284c9b203aff1d3d9a145616856f681 --cluster-to de5b4b2f6a559362ed56d4de1e3994fd529917b5 --cluster-slots 1366 --cluster-yes [root@redis-cluster1 src]# ./redis-cli --cluster reshard 192.168.116.175:7006 --cluster-from 308320db4284c9b203aff1d3d9a145616856f681 --cluster-to 60e3755761c9cbdacb183f59e3d6205da5335e86 --cluster-slots 1365 --cluster-yes View node information 192.168.116.173:7002> CLUSTER nodes

You can see that there are no slots.
If an error is reported: [root@redis-cluster1 src]# ./redis-cli --cluster del-node 192.168.116.175:7006 308320db4284c9b203aff1d3d9a145616856f681 >>> Removing node 308320db4284c9b203aff1d3d9a145616856f681 from cluster 192.168.116.175:7006 [ERR] Node 192.168.116.175:7006 is not empty! Reshard data away and try again. You need to check whether all the slots have been moved. If there is no need to reassign the number of moves. This is because there are slots that cannot be removed directly master.
3.delete master node [root@redis-cluster1 src]# ./redis-cli --cluster del-node 192.168.116.175:7006 308320db4284c9b203aff1d3d9a145616856f681 >>> Removing node 308320db4284c9b203aff1d3d9a145616856f681 from cluster 192.168.116.175:7006 >>> Sending CLUSTER FORGET messages to the cluster... >>> Sending CLUSTER RESET SOFT to the deleted node. View cluster information: 192.168.116.173:7002> CLUSTER nodes

You can see that it has become 3 master and 3 slave
4, Master-slave switching
Test: 1.Will node cluster1 Primary node 7000 port redis turn off [root@redis-cluster1 src]# ps -ef |grep redis root 15991 1 0 01:04 ? 00:02:24 ./redis-server 192.168.116.172:7000 [cluster] root 16016 1 0 01:04 ? 00:02:00 ./redis-server 192.168.116.172:7001 [cluster] root 16930 1595 0 08:04 pts/0 00:00:00 grep --color=auto redis [root@redis-cluster1 src]# kill -9 15991 View cluster information: 192.168.116.173:7002> CLUSTER nodes

You can see that the redis on port 7000 has fail ed.
2.Connect the 7000 port of the node redis Start in view [root@redis-cluster1 log]# cd /data/redis/src/ [root@redis-cluster1 src]# ./redis-server ../cluster/7000/redis.conf View node information: 192.168.116.173:7002> CLUSTER nodes

You can see that the master-slave switch has been completed
redis interview questions sorting
1, How to solve Redis,mysql Double write consistency? 1.The most classic cache+Database read / write mode: When reading, first read the cache. If there is no cache, read the database, then take out the data and put it into the cache, and return the response at the same time. When updating, update the database first, and then delete the cache. 2.Set the expiration time for the cache. Under this scheme, the expiration time can be set for the data stored in the cache. All write operations are subject to the database. That is, if the database is written successfully and the cache update fails, as long as the expiration time is reached, the subsequent read requests will automatically read new values from the database and backfill the cache. 2, Cache avalanche The data is not loaded into the cache, or the cache fails in a large area at the same time, resulting in all requests to query the database, resulting in database failure CPU And memory load is too high, or even down. Simple process of avalanche generation: 1,redis Cluster large area fault 2,The cache fails, but there are still a large number of requests to access the cache service redis 3,redis After a large number of failures, a large number of requests turn to mysql database mysql The number of calls soared and soon became unbearable, or even went down directly 4,Due to a large number of Application Service Dependencies mysql and redis At this time, it will soon evolve into an avalanche of server clusters, and finally the website will completely collapse. #solve: 1.Cache high availability The cache layer is designed to be highly available to prevent large-scale cache failure. Even if individual nodes, individual machines, or even computer rooms are down, services can still be provided, such as Redis Sentinel and Redis Cluster Both achieve high availability. 2.Cache degradation Can use ehcache Wait for local cache(Temporary support),It mainly focuses on current limiting, resource isolation (fusing), degradation, etc. of source service access. When the traffic increases sharply and the service has problems, it is still necessary to ensure that the service is still available. The system can automatically degrade according to some key data, or configure switches to realize manual degradation, which will involve the cooperation of operation and maintenance. The ultimate goal of degradation is to ensure that core services are available, even if they are damaged. Before downgrade, sort out the system, such as which businesses are the core(Must guarantee),Which businesses can allow temporary non provision of services(Replace with static pages)And cooperate with the core indicators of the server to set the overall. 3.Redis Backup and fast warm-up 1)Redis Data backup and recovery 2)Cache warm-up 4.Advance drill Finally, before the project goes online, it is recommended to drill the load and possible problems of the application and back-end after the cache layer goes down, and preview the high availability in advance to find problems in advance. 3, Cache penetration Cache penetration refers to querying data that does not exist. For example: from cache redis Missed, need from mysql For database query, if the data cannot be found, it will not be written to the cache, which will cause the nonexistent data to be queried in the database every request, resulting in cache penetration. solve: If the query database is also empty, set a default value directly and store it in the cache, so that there will be a value obtained in the cache the second time, and the database will not be accessed again. Set an expiration time or replace the value in the cache when there is a value. 4, Cache concurrency Concurrency here refers to multiple redis of client meanwhile set key Concurrency problems caused by. actually redis Itself is a single thread operation, multiple client Concurrent operations shall be executed according to the principle of first come, first executed, and the rest shall be blocked. 5, Cache preheating Cache preheating is to load relevant cache data directly into the cache system after the system is online. This can avoid the problem of querying the database first and then caching the data when the user requests it! The user directly queries the pre warmed cache data! solve: 1,Directly write a cache refresh page, which can be manually operated when online; 2,The amount of data is small and can be loaded automatically when the project is started; The purpose is to load data into the cache before the system goes online. Other interviews: 1.Redis Why didn't the authorities provide it Windows edition? Because at present Linux The version has been quite stable, and there are a large number of users, so there is no need to develop windows Version, but it will bring compatibility and other problems. 2.What is the maximum storage capacity of a string type value? 512M 3.Redis Under what circumstances does the cluster scheme make the whole cluster unavailable? yes A,B,C Three node cluster,Without copying the model,If node B If it fails, the whole cluster will think that 5501 is missing-11000 This range of slots is not available. 4.say something Redis The concept of hash slot? Redis The cluster does not use consistency hash,Instead, the concept of hash slot is introduced, Redis The cluster has 16384 hash slots, each key adopt CRC16 After verification, the 16384 is modeled to determine which slot to place, and each node of the cluster is responsible for a part hash Slot. 5.Redis How are clusters replicated? Asynchronous replication 6.Redis What is the maximum number of nodes in the cluster? 16384 One. 7.Redis How do clusters select databases? Redis The cluster cannot make database selection at present. The default database is 0. 8.How to test Redis Connectivity? ping 9.How with Redis interaction? After installing the server, you can run redis Install supplied Redis Client, you can also open a command prompt and use the following command: redis-cli 10.use Redis What are the benefits? Redis Very fast. It supports server-side locking. It has a rich client library. This is a good counterattack. It supports atomic operations. 11.use Redis What are the disadvantages/Restrictions? It is single threaded. It has limited client support for consistent hashes. It has a large persistence overhead. It is not widely deployed. 12.Redis and RDBMS What's the difference? Redis yes NoSQL Database, and RDBMS yes SQL database Redis Follow the key value structure, and RDBMS Follow the table structure. Redis Very fast, and RDBMS Relatively slow. Redis Store all data sets in main memory, and RDBMS Store its data set in secondary storage. Redis Usually used to store small and commonly used files, while RDBMS Used to store large files. Redis Only Linux,BSD,Mac OS X,Solaris Provide official support. It is not currently available for Windows Provide official support, and RDBMS Provide support for both 13.What is? redis Your business? a)A transaction is a separate isolation operation: all commands in the transaction are serialized and executed sequentially. During the execution of the transaction, it will not be interrupted by command requests sent by other clients. b)A transaction is an atomic operation: all commands in the transaction are either executed or not executed at all. 14.Redis Single point throughput Single point TPS Up to 80000/Seconds, QPS Up to 100000/Seconds, add TPS and QPS Concept of 1.QPS: The maximum number of user visits that the application system can accept per second The number of times a request is processed per second. Note that this is the number of times a request is processed. Specifically, it refers to the number of times a request is sent to the server and the result is returned after it is processed successfully. Understandable in server One of them counter,Add 1, 1 second for each request processed counter=QPS. 2.TPS: Maximum number of requests that can be processed per second Number of transactions processed per second, one application system 1 s How many transactions can be completed? In distributed processing, a transaction may correspond to multiple requests. For measuring the processing capacity of a single interface service, use QPS Quite reasonable. Question 2:Redis How much do you know about the multi database mechanism? Normal: Redis Multiple databases are supported, and the data of each database is isolated and cannot be shared. It can be used in a single machine redis Can support 16 databases( db0 ~ db15) colony: stay Redis Cluster There is only one database space under the cluster architecture, i.e db0. Therefore, we did not use Redis Multi database function! Question 3:Redis Do you think there are any deficiencies in the cluster mechanism? Suppose I have one key,Corresponding value yes Hash Type. If Hash The object is very large, and mapping to different nodes is not supported! It can only be mapped to one node in the cluster! In addition, batch operation is more troublesome! Question 4:understand Redis Batch operation? normal: such as mset,mget Operation, etc colony: What we use in production is Redis Cluster Cluster architecture, different key Will be divided into different slot Therefore, it is used directly mset perhaps mget Such operations will not work. Question 6:Are you right Redis Do you separate reading and writing? normal:Not done colony:No separation of reading and writing. We use Redis Cluster The architecture of is a fragmented cluster architecture redis It operates in memory and does not involve IO Throughput, even if read and write are separated, it will not improve too much performance, Redis The main problem in production is to consider the capacity, with a single machine of up to 10-20G,key Too much reduction redis performance.Therefore, the use of piecemeal cluster structure can ensure our performance. Secondly, after the separation of reading and writing is used, the problems such as master-slave consistency and master-slave delay should be considered to increase the business complexity.