I. Hash
1.1 Introduction
The dictionary in Redis is implemented using a hash table as the underlying implementation, where a hash table has multiple nodes and each node holds a key-value pair.
In Redis source files, the implementation code for the dictionary is in dict.c and dict.h files.
Redis's database is implemented using a dictionary as the underlying layer, representing all the data in the database as key-value pairs.Moreover, all the commands to add, delete, check and change the database are based on the operation of the dictionary.
Dictionaries are also the underlying implementation of hash keys in Redis. When a hash key contains more key-value pairs or when the elements in the key-value pairs are longer strings, Redis uses dictionaries as the underlying implementation of hash keys.
When hash removes the last element, the data structure is automatically deleted and memory is reclaimed.
Dictionaries, also known as symbol table s, associative array s, or map s, are abstract data structures used to hold key-value pair s.
Usage of the 1.2 command
- hset(key, field, value): Add the element field<->value to the hash named key
- hget(key, field): Returns the value of field in hash named key
- hmget(key, field1,...field N): Returns the value of field i in hash named key
- Hmset (key, field 1, value1,..., field N, value N): Add the element field i<->value I to the hash named key
- hincrby(key, field, integer): Increase the value of field in hash named key by integer
- hexists(key, field): Domain with key field in hash named key
- hdel(key, field): Delete a field with a hash key of key
- hlen(key): Returns the number of elements in a hash named key
- hkeys(key): Returns all keys in hash with the name key
- hvals(key): Returns the value of all keys in the hash named key
- hgetall(key): Returns all keys (field s) and their corresponding value s in a hash named key
1.3 Source Code Analysis
Data with hash structure is mainly used for dictionary structure.
In addition to the dictionary that hash uses, all keys and value s from the entire Redis database make up a global dictionary, as well as a collection of keys with expiration times.
//This structure is defined in server.h
typedef struct redisDb {
dict *dict; /*A Dictionary of the entire database The keyspace for this DB */
dict *expires; /*Dictionary with expired time Timeout of keys with a timeout set */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
} redisDb;The mapping relationship that stores value and score values in the zset collection is also implemented through the dict structure.
//This structure is defined in server.h
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;Redis defines dictEntry, dictType, dictht and dict to implement the dictionary structure, which are described below.
//The array pointed to by the table of the hash table holds the address of this dictEntry type.Defined in dict.h/dictEntryt
typedef struct dictEntry {//Node of Dictionary
void *key;
union {//Communities used
void *val;
uint64_t u64;//These two parameters are useful
int64_t s64;
} v;
struct dictEntry *next;//Point to the next hash node to resolve hash key conflicts (collision)
} dictEntry;
//dictType types hold pointers to methods that manipulate dictionaries for different types of key s and value s
typedef struct dictType {
unsigned int (*hashFunction)(const void *key); //Functions for calculating hash values
void *(*keyDup)(void *privdata, const void *key); //Functions that copy key s
void *(*valDup)(void *privdata, const void *obj); //Functions that copy value
int (*keyCompare)(void *privdata, const void *key1, const void *key2); //Functions to compare key s
void (*keyDestructor)(void *privdata, void *key); //Destructor to destroy key
void (*valDestructor)(void *privdata, void *obj); //Destructors that destroy Vals
} dictType;
//Hash table definition dict.h/dictht in redis
typedef struct dictht { //Hashtable
dictEntry **table; //Stores the address of an array that holds the address of the dictEntry hash table node.
unsigned long size; //Hashtable table size, initialization size 4
unsigned long sizemask; //Location index used to map hash values to table s.It always has a value equal to (size-1).
unsigned long used; //Records the number of nodes (key-value pairs) that the hash table already has.
} dictht;
//The dictionary structure is defined in dict.h/dict
typedef struct dict {
dictType *type; //Point to the dictType structure, which contains custom functions that allow key s and value s to store any type of data.
void *privdata; //Private data that holds the parameters of the function in the dictType structure.
dictht ht[2]; //Two hash tables.
long rehashidx; //The rehash flag, rehashidx==-1, indicates that rehash is not in progress
int iterators; //Number of iterators in iteration
} dict;
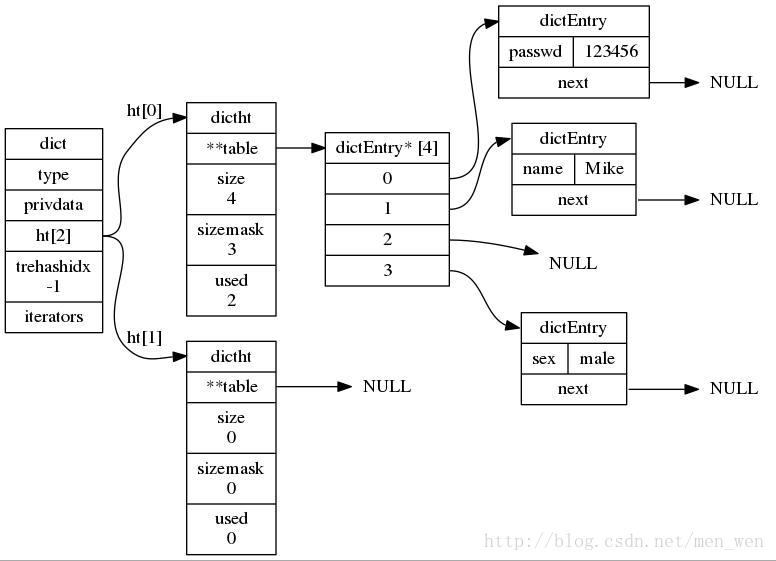
As you can see from the source code, dict structure contains two hashtables, usually only one hashtable is valid.
However, when dict scales up, you need to allocate a new hashtable and move progressively, where the two hashtables store the old hashtable and the new hashtable, respectively.When the move is over, the old hashtable is deleted and the new hashtable is replaced.
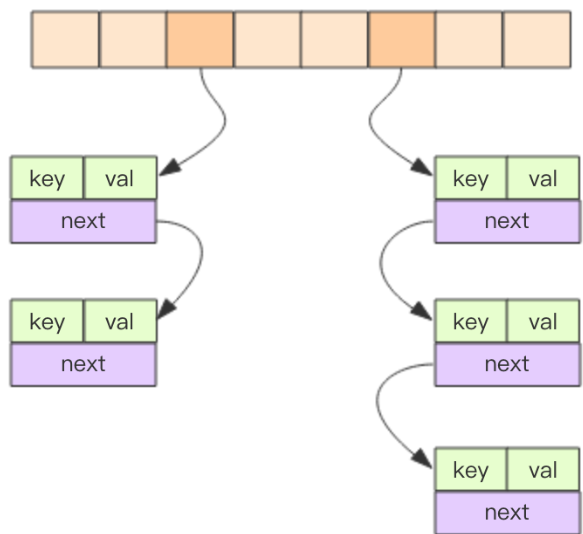
The essence of the dictionary data structure falls on the hashtable structure represented by dictht.Hashtable is almost identical in structure to Java's HashMap and resolves hash conflicts in a bucket-wise manner.The first dimension is an array, and the second dimension is a list of chains.The array stores a pointer to the first element of the first two-dimensional chain table.
1.4 Hash algorithm
When adding a key-value pair to a dictionary, the hash and index values need to be calculated based on the size of the key, and then the hash table node containing the new key-value pair is placed on the specified index of the hash table array based on the index value.
// DP Hash
h = dictHashKey(d, key);
// Call hash algorithm to calculate hash value
#define dictHashKey(d, key) (d)->type->hashFunction(key)Redis provides three functions for calculating hashes:
- Thomas Wang's 32 bit Mix function, hashing an integer, implemented in dictIntHashFunction
unsigned int dictIntHashFunction(unsigned int key) //Hash function for calculating int integer hash value
{
key += ~(key << 15);
key ^= (key >> 10);
key += (key << 3);
key ^= (key >> 6);
key += ~(key << 11);
key ^= (key >> 16);
return key;
}- Hash strings using the MurmurHash2 hash algorithm, which is implemented in dictGenHashFunction
unsigned int dictGenHashFunction(const void *key, int len) { //Hash function for calculating the hash value of a string
/* 'm' and 'r' are mixing constants generated offline.
They're not really 'magic', they just happen to work well. */
//Two values, m and r, are used to compute hashes only because they work well.
uint32_t seed = dict_hash_function_seed;
const uint32_t m = 0x5bd1e995;
const int r = 24;
/* Initialize the hash to a 'random' value */
uint32_t h = seed ^ len; //Initialization
/* Mix 4 bytes at a time into the hash */
const unsigned char *data = (const unsigned char *)key;
//Regarding each of the four sets of string key s as uint32_t, the arithmetic arrives at h
while(len >= 4) {
uint32_t k = *(uint32_t*)data;
k *= m;
k ^= k >> r;
k *= m;
h *= m;
h ^= k;
data += 4;
len -= 4;
}
/* Handle the last few bytes of the input array */
switch(len) {
case 3: h ^= data[2] << 16;
case 2: h ^= data[1] << 8;
case 1: h ^= data[0]; h *= m;
};
/* Do a few final mixes of the hash to ensure the last few
* bytes are well-incorporated. */
h ^= h >> 13;
h *= m;
h ^= h >> 15;
return (unsigned int)h;
}- A simple hash algorithm based on djb hash is used, which is implemented in dictGenCaseHashFunction.
unsigned int dictGenCaseHashFunction(const unsigned char *buf, int len) { //Hash function for calculating the hash value of a string
unsigned int hash = (unsigned int)dict_hash_function_seed;
while (len--)
hash = ((hash << 5) + hash) + (tolower(*buf++)); /* hash * 33 + c */
return hash;
}After calculating the hash value, you need to calculate its index.Redis uses the following formula to calculate the index value.
// For example, h is 5, hash table size is initialized to 4, sizemask is size-1,
// So h&sizemask = 2,
// So the key-value pair is stored at index 2
idx = h & d->ht[table].sizemask;1.4 rehash
When the size of a hash table does not meet demand, two or more keys may be assigned to the same index on the hash table array, resulting in a collision.
The way to resolve conflicts in Redis is to separate chaining.However, conflicts need to be avoided as much as possible, and hash tables need to be expanded or shrunk in order for their load factor s to remain within a reasonable range.
Expansion: When the number of elements in the hash table is equal to the length of the first dimension array, the expansion begins. The new expanded array is twice the size of the original array.However, if Redis is making bgsave, Redis tries not to expand (dict_can_resize) in order to reduce excessive splitting of memory pages (Copy On Write), but if the hash table is already very full and the number of elements is five times the length of the first dimension array (dict_force_resize_ratio), the hash table is already too crowded, at that time it will force expansion.
Compact: As the hash table becomes more sparse due to progressive deletion of elements, Redis shrinks the hash table to reduce the space occupied by the first dimension array of the hash table.The condition is that the number of elements is less than 10 percent of the length of the array.Scaling does not take into account whether Redis is doing bgsave.
The expansion of a large dictionary is time consuming and requires that you reapply for a new array and then reattach all the elements in the old dictionary's chain table under the new array, which is an O(n) level operation.
Expansion operation specific source code:
static int _dictExpandIfNeeded(dict *d) //Extend d dictionary and initialize
{
if (dictIsRehashing(d)) return DICT_OK; //rehash in progress, return directly
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE); //If the dictionary (hash table 0) is empty, create and return hash table 0 of the initialization size
//1. The ratio between the total number of elements in a dictionary and the size of the dictionary's array is close to 1:1
//2. Extensible flags are true
//3. The ratio between the number of used nodes and the size of the dictionary exceeds dict_force_resize_ratio
if (d->ht[0].used >= d->ht[0].size && (dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2); //Expand to twice the number of nodes
}
return DICT_OK;
}Shrink operation specific source code:
int dictResize(dict *d) //Shrink Dictionary d
{
int minimal;
//If dict_can_resize is set to 0, rehash cannot occur, or rehash is in progress, an error flag DICT_ERR is returned
if (!dict_can_resize || dictIsRehashing(d)) return DICT_ERR;
minimal = d->ht[0].used; //Get the number of existing nodes as the minimum minimal
if (minimal < DICT_HT_INITIAL_SIZE)//However, minimal cannot be less than the minimum DICT_HT_INITIAL_SIZE(4)
minimal = DICT_HT_INITIAL_SIZE;
return dictExpand(d, minimal); //Size Dictionary d with minimal
}Both expansion and shrinking operations call the dictExpand() function, which calculates by calculating the second size parameter passed in, calculates a realsize closest to 2n, then expands or shrinks it. The dictExpand() function source code is as follows:
int dictExpand(dict *d, unsigned long size) //Adjust or create a hash table for dictionary d Based on size
{
dictht n;
unsigned long realsize = _dictNextPower(size); //Get a realsize closest to 2^n
if (dictIsRehashing(d) || d->ht[0].used > size) //rehash or size not large enough to return error flag
return DICT_ERR;
if (realsize == d->ht[0].size) return DICT_ERR; //If the new realsize is the same as the original size, an error flag is returned
/* Allocate the new hash table and initialize all pointers to NULL */
//Initialize members of a new hash table
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
/* Is this the first initialization? If so it's not really a rehashing
* we just set the first hash table so that it can accept keys. */
if (d->ht[0].table == NULL) { //If the ht[0] hash table is empty, set the new hash table n to ht[0]
d->ht[0] = n;
return DICT_OK;
}
d->ht[1] = n; //rehash is required if ht[0] is not empty
d->rehashidx = 0; //Set the rehash flag to 0 to begin incremental rehash
return DICT_OK;
}Shrinking or expanding a hash table requires that all keys in the ht[0] table be rehashed to ht[1], but rehash operations are not one-time, centralized, but are done multiple, incremental, and intermittent so that server performance is not affected.
1.5 incremental rehash
Key to progressive rehash:
- A member of the dictionary structure dict, rehashidx, does not rehash when rehashidx is -1 and starts rehash when rehashidx is 0.
- During rehash, each time a dictionary is added, deleted, found, or updated, it will be determined whether a rehash operation is in progress or, if so, a one-step rehash will be carried forward, and rehashidx+1 will be added.
- When rehash is complete, set rehashidx to -1 to indicate completion of rehash.
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing) {
long index;
dictEntry *entry;
dictht *ht;
// Take small steps here
if (dictIsRehashing(d)) _dictRehashStep(d);
if ((index = _dictKeyIndex(d, key, dictHashKey(d,key), existing)) == -1) return NULL; // If the dictionary is in the process of moving, hook the new element under the new array
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
entry = zmalloc(sizeof(*entry));
entry->next = ht->table[index];
ht->table[index] = entry;
ht->used++;
dictSetKey(d, entry, key);
return entry;
}Redis also actively moves the dictionary in a scheduled task if the client is idle and does not have subsequent instructions to trigger the move.
// Server Timing Tasks
void databaseCron() {
...
if (server.activerehashing) {
for (j = 0; j < dbs_per_call; j++) {
int work_done = incrementallyRehash(rehash_db);
if (work_done) {
break;
} else {
rehash_db++;
rehash_db %= server.dbnum;
}
}
}
}static void _dictRehashStep(dict *d) { //One-step rehash
if (d->iterators == 0) dictRehash(d,1); //One step rehash is possible when the number of iterators is not zero
}
int dictRehash(dict *d, int n) { //n-step rehash
int empty_visits = n*10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0; //A rehash is in progress only if rehashidx is not equal to -1, otherwise 0 is returned
while(n-- && d->ht[0].used != 0) { //n-step with no moving nodes on ht[0]
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
//Make sure that the rehashidx is not out of bounds because rehashidx starts at -1 and 0 indicates that a node has been moved, which is always smaller than the size of the hash table
assert(d->ht[0].size > (unsigned long)d->rehashidx);
//The first loop is used to update the value of rehashidx, because some buckets are empty, rehashidx does not always move one position forward, but may move forward several positions, but no more than 10.
//Move rehashidx to the subscript where ht[0] has nodes, that is, table[d->rehashidx] is not empty
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
de = d->ht[0].table[d->rehashidx]; //The ht[0] subscript rehashidx has a node and gets the address of that node
/* Move all the keys in this bucket from the old to the new hash HT */
//The second loop copies the chain table (or a single node) from each non-empty bucket found in the ht[0] table to ht[1]
while(de) {
unsigned int h;
nextde = de->next; //Back up the address of the next node
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask; //Gets the computed hash value and the subscript h in the hash table
//Insert the node at the position labeled h
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
//Update the counter for the number of two table nodes
d->ht[0].used--;
d->ht[1].used++;
//Point de to a processing node
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL; //Set pointer to null for this subscript after migration
d->rehashidx++; //Update rehashidx
}
/* Check if we already rehashed the whole table... */
if (d->ht[0].used == 0) { //There are no more nodes on ht[0], indicating that the migration is complete
zfree(d->ht[0].table); //Release hash table memory
d->ht[0] = d->ht[1]; //Set migrated Hash Table 1 to Hash Table 0
_dictReset(&d->ht[1]); //Reset ht[1] Hash Table
d->rehashidx = -1; //rehash flag off
return 0; //Completed before signifying
}
/* More to rehash... */
return 1; //Indicates that there are still nodes waiting to migrate
}1.6 hash summary
- Structure: A dictionary object represents an instance of a dict that contains a hash table group of two dicthts and a pointer to dicType.The main purpose of defining two dicthts is to ensure the consistency of the read data during the expansion process, and a series of function pointers are defined in the dicType.For each dictht, there is a dicEntry variable, which can be seen as an array of dictionaries, also known as bucket buckets, which are the primary containers for data.Each dictEntry includes a pointer to the next dictEntry object in addition to the key-value pairs of key and value.
- Hash algorithm: redis provides three main Hash algorithms
- Rehash:rehash occurs during the expansion or shrinking phase, where the expansion occurs twice as long when the number of elements equals the length of the hash table array; the expansion occurs when the number of elements equals 10% of the array length.
- Progressive rehash:
2. set
2.1 Introduction
Redis's set collection is similar to a HashSet in the Java language, and its internal key-value pairs are unique and out of order.Its internal implementation is equivalent to a special dictionary in which all values are a value of NULL.
When the last element in the collection is removed, the data structure is automatically deleted and memory is reclaimed.
The set structure is a dictionary-derived structure, and it has the ability to de-weigh to ensure that each key occurs only once.
2.2 Use
- sadd(key, member): Add element member to the set named key
- srem(key, member): Delete the element member in the set named key
- spop(key): Randomly return and delete an element in the set named key
- smove(srckey, dstkey, member): Moves member elements from a set named srckey to a set named dstkey
-
scard(key): Returns the cardinality of the set named key
sismember(key, member): Test if member is an element of set named key? - sinter(key1, key2,...Key N: Find intersection
- sinterstore(dstkey, key1, key2,...Key N: The set that intersects and saves the intersection to dstkey
- sunion(key1, key2,...Key N: union set
- sunionstore(dstkey, key1, key2,...Key N: Summarize and save the union to the set of dstkeys
- sdiff(key1, key2,...Key N: Find the difference set
- sdiffstore(dstkey, key1, key2,...Key N: Find the difference set and save it to the set of dstkeys
- smembers(key): Returns all elements of a set named key
- srandmember(key): Randomly returns an element of set named key
This concludes the basic introduction of hash and set.