1, What is Redis
Redis is an open source component based on memory data structure, which is used as database, cache and message agent
Redis provides data structures such as string, hashes, lists, sets and sorted sets as
Interval query, bitmap, overweight logarithm, spatial index, data stream
Redis includes built-in replication, Lua script, LRU expulsion policy, transaction and persistence mechanism at different levels
It also provides highly available sentry based and automatic zoning
Official interpretation: https://redis.io/
2, Why Redis?
With the development of the times and the progress of science and technology, applications on the market have a large amount of data storage all the time
If the relational database is used uniformly, the data in the file disk will be read through IO every time the data is loaded
It will greatly reduce the carrying capacity and performance of the system, because IO reads the disk, and the addressing of the disk is ms level, and the speed will be affected by the bandwidth of the hard disk
Based on the above scenarios, non relational storage came into being. Among them, redis is the best representative of key value storage
Because redis stores data based on in memory. Memory addressing is nanosecond (ns) (s > MS > US > ns)
Therefore, disk addressing will be 10W slower than memory addressing, and the bandwidth of disk is generally G/M. the bandwidth of memory will be much larger than that of disk
3, What can Redis do for us
1, Under the hot data with large amount of data and frequent queries, redis can reduce the pressure on the database
2, Because redis is memory level storage, the response of data is very fast, which can improve the high availability of our program
4, Install Redis(Linux)
1. Download and unzip the installation package (the download link can be found on the official website of redis) https://redis.io/ )
wget https://download.redis.io/releases/redis-6.2.1.tar.gz tar -xf redis-6.2.1.tar.gz
2. Generate executable program
Enter the extracted redis In the file directory, there will be one Makefile Document, execution make After compiling instructions The script of this file will actually take the parameters you enter to help you enter src Directory to execute real Makefile file ... make be careful:Errors may be reported during installation because the script needs to be executed C The language compiler needs to be installed first gcc ... yum install gcc Installation completed gcc After that, some garbage files generated by the just executed script file should be emptied first ... make distclean Then re execute make command
2. Configure global variables (optional)
Configure if necessary redis Each time the service starts automatically, you need to enter/etc/profile Configure global variables under this file Find the last line and add your own configuration ... export REDIS_HOME=Yours redis File address ... export PATH=$PATH:$REDIS_HOME/bin Don't forget to make the configuration effective after saving ... source /etc/profile
3. Extract executable files to a separate directory (optional)
take make Several executable files generated by the command are output separately to the directory you specify,Enter into redis Execute in the file directory of ... make install PREFIX=The address directory of the file you want to output
4. Use the tool to generate multiple redis processes (optional)
stay redis/utils There is one in the directory install_server.sh Documents,After executing the file, it will help you automatically start one redis process At the same time, I will ask you this time redis Process you want Assigned port number(The default value is 6379) Profile address(If not specified, it will be assigned to you/etc/redis/Port number.conf) Log address(Assign to if not specified/var/log/redis_Port number.log) Data storage address(Assign to if not specified/var/lib/redis/Port number) implement redis-server Address of the file(If not specified, it will be found/usr/local/bin/redis-server) ... ./install_server.sh After everything is confirmed, press enter to generate the above related operations journal: Copied /tmp/6381.conf => /etc/init.d/redis_6381 Installing service... Successfully added to chkconfig! Successfully added to runlevels 345! Starting Redis server... Installation successful! From the instruction log, we can know redis It will also help us automatically start the process. The script of the service is copied to/etc/init.d/redis_6381
At this point, the redis installation can be concluded
5, Redis five data types
Redis is stored by the key value data structure. There are different types and object information in the key
The key value value in Redis is binary safe, which means that any binary sequence can be used
Key also has a corresponding type. You can use TYPE KEY_NAME view the type of key
You can also use the Object endcoding key to view the internal codes of. The type diagram of each type is as follows 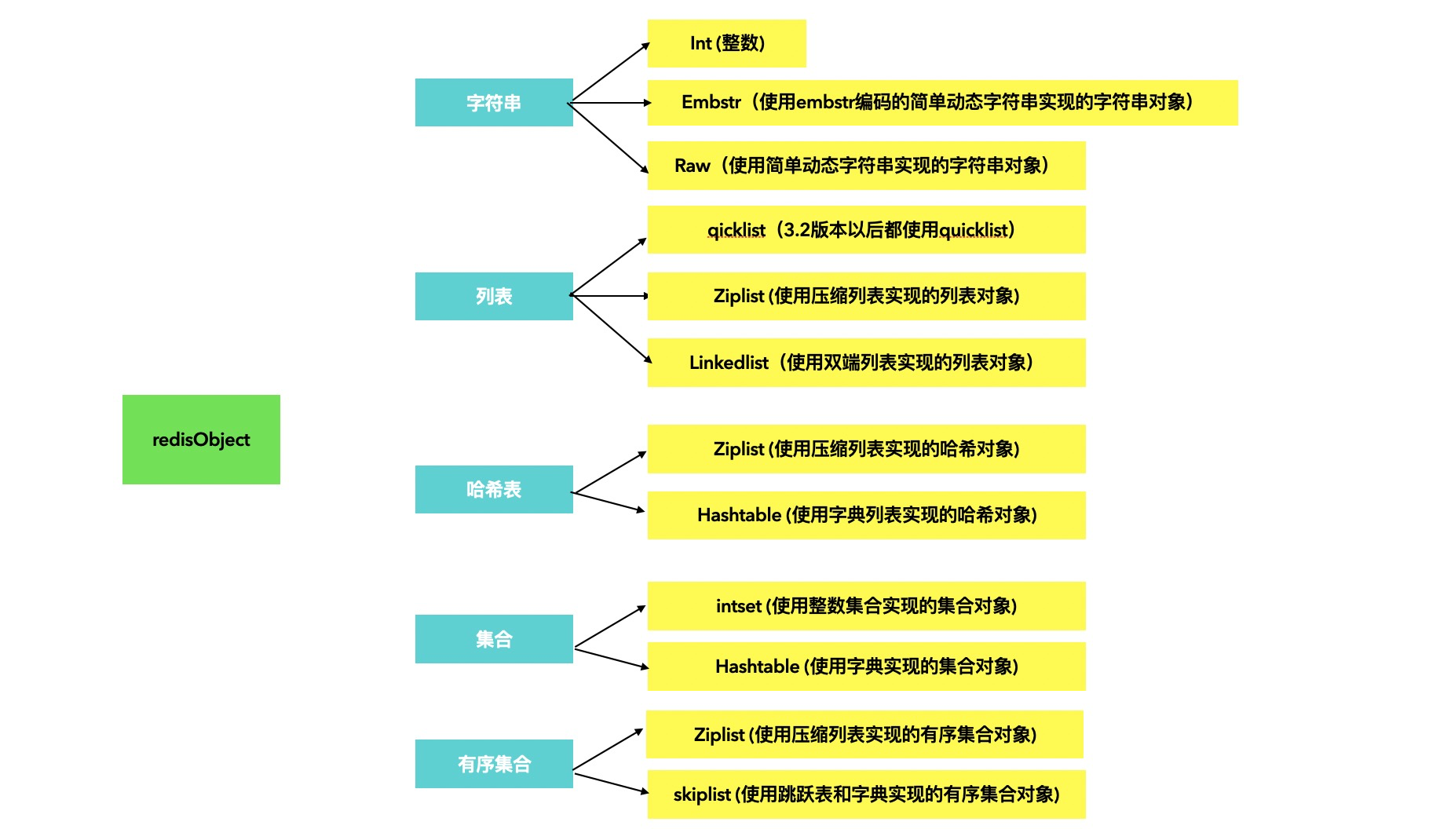
1, String (Bit arrays/simply bitmaps)
// You can treat the String value as a series of bits: you can set and clear individual bits and count all bits set to 1 // Find the first bit set to 1 or 0 // In addition to some simple operation commands of string type, there are some worth noting. Take set k1 v1 as an example 1.STRLEN key because redis It is stored in binary, so it is set in v1 Values are stored as binary serialization v1: 01110110 00110001 adopt STRLEN k1 The length of the view value is 2, which means the length of 2 bytes 2.BITCOUNT key [start end] View a key worth start Bytes to end How many 1s exist in a byte, in v1 As an example BITCOUNT k1 0 0 see key by k1 The number of bits from the 0th byte to 1 in the 0th byte of the value of. The input is 5 3.BITPOS key bit [start] [end] Returns a number in a string start Bytes to end A byte is set to the position of 0 or 1 for the first time 4.BITOP operation destkey key [key ...] For one or more strings that hold binary bits key Perform bit operation and save the result to destkey upper operation support AND(and) , OR(or) , NOT(wrong) , XOR(XOR) Four parameter values string Binary usage scenario For the e-commerce platform, if you want to count the login days of each customer every year, if you use database storage, you need to store 365 pieces of data at most It is assumed that the number of active users of the platform is 1000 w Person times, then the storage capacity of the table in a year reaches 36.5 Billion data. If used redis Using the characteristics of binary 0 and 1, log in every day to store a bit 1 Then a customer needs 365 bits of storage at most,46 bytes per user*1000w The end user only needs 470 M
2, List
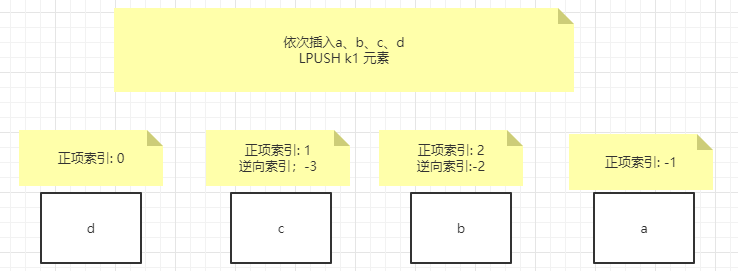
// List value type is a collection of string elements in insertion order. They are basically linked lists (two-way) // Moreover, the elements can be popped from the left or right of the set, which can achieve the storage effect similar to that of stack (FILO) and queue (FIFO) // In addition to the basic operations, there are several commands that need to be noted as follows 1.BLMOVE source destination LEFT|RIGHT LEFT|RIGHT timeout Pop up an element from the set, put it into another set and return the element; Or block until there is a valid element 2.BLPOP/BRPOP Remove and get left in collection/The first element on the right or blocking guide has a valid element Usage scenario: Followers of a blogger, order sequence of takeout orders, etc
3, Set
// set is a collection of non repeating and unordered string elements 1.SCARD key Get a set Number of elements in 2.SDIFF key [key ...] Returns the element of the difference between a set and a given set 3.SPOP key [count] Remove and return a random element 4.SRANDMEMBER key [count] Gets one or more non repeating random elements Usage scenario:Put the name of the lucky draw into the collection as an element, and one or more winners will pop up at random each time, so that one person can only win one prize
4, Hash
// A map consisting of a field and an associated value. Both field and value are strings 1.HRANDFIELD key [count [WITHVALUES]] Get one or more random attributes WITHVALUES Will output filed Corresponding value 2.HSETNX key field value When someone key of field Only when it does not exist can it be set successfully Usage scenario: 1.Shopping cart generation key:order number field:Commodity attribute 2.Information storage of user login key:User's id field:user attribute
5, Sorted Set
Bottom implementation principle of sorted set (skip list)
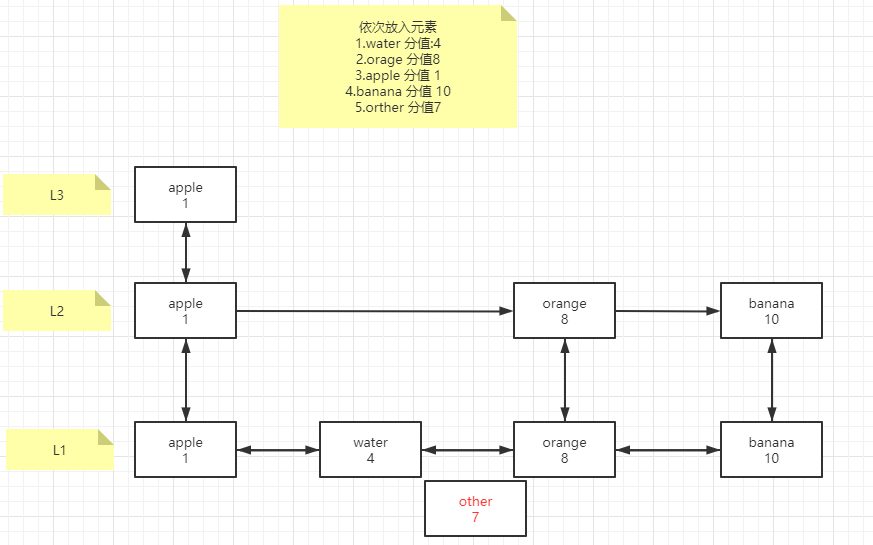
The bottom layer of sorted set is implemented based on the jump table. According to the illustration and case, the explanation process is as follows
1. When the first four elements are inserted in turn, they will be randomly layered. When other elements are to be inserted
2. According to the score 7, if the first layer is larger than the last element of the first layer, it will fall to L2 layer
3. If 7 is smaller than 8 after the L2 layer is compared in turn, find the position of the L1 layer orange, compare it forward, and select the index position of the element to be inserted
// Each floating element is called a number, but each floating element is similar to a number // The elements inside are always sorted by score, so the difference is that it is a series of elements that can be retrieved 1.BZPOPMAX/BZPOPMIN key [key ...] timeout Remove and return multiple sorted sets Medium highest/One or more elements with a low score, or blocking know that there is a valid element 2.ZMSCORE key member [member ...] Returns the score of an element
Summary
The specific commands corresponding to each type can be viewed through the official website of redis or the client through instructions such as helpo @string
Chinese official website address http://redis.cn/topics/data-types-intro.html
6, Publish / subscribe
The sender (publisher) is not planning to send a message to a specific recipient (subscriber). Instead, the published news is divided into different channels, and there is no need to know what kind of subscribers subscribe to it. Subscribers who are interested in one or more channels only need to receive the messages they are interested in, and do not need to know what kind of publishers publish them. This decoupling of publishers and subscribers can bring greater scalability and more dynamic network topology
1.Multiple clients subscribe to a channel(passageway) SUBSCRIBE myRedis 2.By publisher myRedis Publish messages through the pipeline PUBLISH myRedis hello world 3.Multiple clients will receive messages from publishers at the same time
7, Piping
Typically, a request follows the following steps:
The client sends a query request to the server and listens for the return of socket, usually in blocking mode, waiting for the server to respond
The server processes the command and returns the result to the client
Client: INCR X
Server: 1
Client: INCR X
Server: 2
Client: INCR X
Server: 3
Client: INCR X
Server: 4
One request/The response server can handle the new request even if the old request has not been responded. This allows multiple commands to be sent to the server without waiting for a reply, which is read in the last step. This is the pipe( pipelining),Is a technology widely used for decades For example, many POP3 The protocol supports this function, which greatly speeds up the process of downloading new mail from the server. Redis Early support pipeline( pipelining)Technology, so no matter what version you're running You can use pipes( pipelining)operation Redis
8, Redis transaction
The transaction in Redis is a separate isolation operation:
All commands in a transaction are serialized and executed sequentially. During the execution of the transaction, it will not be interrupted by the command request sent by the client
A transaction is an operation: all commands in the transaction are either executed or not executed at all
Generally speaking, as long as the redis transaction is started, the following commands are not actually executed, but stored in a queue
After the transaction is committed, all commands in the queue will be executed. If one fails, all commands will be abandoned
// Multiple keys can be monitored before starting a transaction. As long as the keys monitored by other teams are operated during the start of the transaction, the execution of this transaction will be abandoned WATCH k1 k2 // Open transaction MULTI // Perform operations set k1 v1 set k2 v2 // Commit transaction / discard transaction EXEC/DISCARD
9, LRU
1, Maxmemory configuration instruction
1. When redis is used as a cache, when you add data, it is very convenient for him to automatically recycle the data
2.LRU is the only recycling method supported by Redis
3.maxmemory configuration instruction is used to configure the limited memory size when Redis stores data
4. Through redis Conf can set this instruction, or use the CONFIG SET command to configure maxmemory 100mb at runtime
5. Setting maxmemory to 0 means there is no memory limit. This is the default value for 64 bit systems, and the default memory limit for 32-bit systems is 3GB.
6. When the specified memory limit is reached, you need to choose different behaviors, that is, strategies. Redis can only return an error to the command, which will make more memory used, or recycle some old data to avoid memory limitation when adding data
2, Recycling strategy
When maxmemory When the limit is reached Redis Behaviors that will be used by Redis of maxmemory-policy Configure to configure The following policies are available: noeviction: Returns an error when the memory limit is reached and the client attempts to execute a command that will allow more memory to be used allkeys-lru: Try recycling the least used key( LRU),Make the newly added data have space to store volatile-lru: Try recycling the least used key( LRU),But only for keys in expired collections,Make the newly added data have space to store allkeys-random: Reclaim random keys to make room for newly added data olatile-random: Reclaiming random keys allows space for newly added data, but only for keys in expired sets volatile-ttl: Reclaim keys in expired collections, with priority to reclaim lifetime( TTL)Shorter keys,Make the newly added data have space to store If the key does not meet the conditions of the recycling policy volatile-lru, volatile-random as well as volatile-ttl Just like noeviction Almost
10, Redis persistence
Redis persistence provides two different levels of persistence methods:
1:RDB persistence can snapshot and store your data at a specified time interval
2. The AOF persistence mode records every write operation to the server
When the server restarts, these commands will be re executed to recover the original data
The AOF command uses redis protocol to append and save each write operation to the end of the file
Redis can also rewrite AOF files in the background, so that the volume of AOF will not be too large
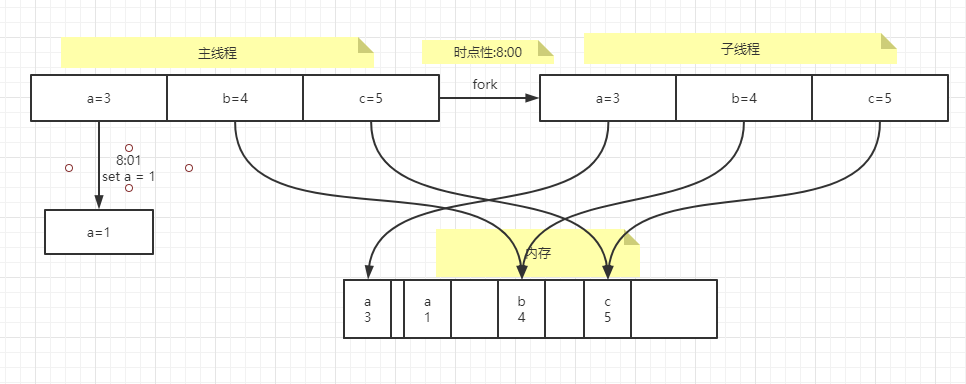
working principle
AOF Rewrite and RDB Like creating snapshots, copy on write is cleverly utilized(copy on write)mechanism Copy on write: The kernel only penetrates the virtual space structure for the newly generated child process. They copy the virtual space structure of the parent process, but do not allocate physical memory They share the physical space of the parent process. When the behavior of changing the response segment occurs in the parent-child process, they allocate physical space to the segment responded by the child process RDB: 1.redis call forks Create a child process and have both parent and child processes 2.The subprocess writes the data set to a temporary RDB In the file 3.When the child process completes the new RDB When a file is written, Redis Use new RDB File replaces the original RDB File and delete the old one RDB file AOF: 1.redis implement fork(),Have both parent and child processes 2.The subprocess starts a new AOF The contents of the file are written to a temporary file 3.For all newly executed write commands, the parent process accumulates them into a memory cache While adding these changes to the existing AOF The end of the file, so that even if there is a shutdown in the middle of rewriting Existing AOF Files are also safe 4.When the child process finishes rewriting, it sends a signal to the parent process. After receiving the signal, the parent process Append all data in the memory cache to the new AOF End of file 5.Redis Replace the old file with the new file, and then all commands will be appended directly to the new file AOF End of file
RDB
to configure
// Open the redis configuration file and find the configuration document related to snapshooting // Redis will save the DB. If the conditions of how many times the DB has been modified in how many seconds are met, redis will start the save instruction save <seconds> <changes> // File name of RDB storage dbfilename dump.rdb // File address directory dir /var/lib/redis/6380
summary
advantage: 1.Non blocking, fast speed and small space 2.If there are specific scenarios, such as shutdown maintenance, you can use save Data persistence 3.Similar to serialized storage, data recovery is faster shortcoming: 1.There is a point in time problem. Once a point in time does not start persistence Redis In case of downtime, there will be a large amount of data loss 2.Zippers are not supported, only one dump.rdb File. If there is a lot of data, it will be written in full every time
AOF
The AOF file is a log file that is only appended. It orderly saves all writes to redis in the format of redis protocol
You can use different fsync strategies: no fsync, fsync per second, and fsync every time you write Use the default fsync per second policy
fsync is handled by the background thread, and the main thread will try its best to handle the client request). In case of failure, you can lose up to 1 second of data
Log rewrite
Because the operation mode of AOF is to continuously append commands to the end of the file, the file volume of AOF will become larger and larger with the continuous increase of commands
For example, if you continuously set the values of 1 and 2 for a key 1w times, the AOF file needs to use 1w records.
However, in fact, the value of this key is the last written value, and the remaining 9999 are redundant
To handle this situation, rebuild the AOD file, execute BGREWRITERAOF command, and Redis will generate a new file
This file contains the minimum commands required to rebuild the current dataset
to configure
// By default, the AOF persistence mechanism is turned off. You need to find appendonly in the configuration file and set it to yes appendonly no // You can also set the write policy. appendfsync is the write per second policy by default. We can use the default policy # appendfsync always asynchronously appends and writes to the log, which is slow and safe appendfsync everysec Once per second # appendfsync no is not applicable to asynchronous append. Just let the operating system refresh the data when needed // Default appended file name appendfilename "appendonly.aof" // Compare the basic size of the file with the current size. If the current size is greater than the specified percentage (auto AOF rewrite percentage) // Rewriting will be triggered. If you want to disable rewriting AOF, you can set the percentage to 0 and the default minimum file size is 64m // Assuming that the basic size is 64m and the current file size is 128m, the aof reconstruction mechanism will be triggered auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb
summary
advantage: 1.Every write operation will be recorded AOF According to the default asynchronous write mechanism, the maximum lost data is 1 second, which is safe 2.AOF It's just an addition to the log file, so even for some reasons(Disk space is full, downtime during write)The complete write command was not executed You can also use redis-check-aof Tools to fix these problems 3.When aof When the file volume is too large, it will be automatically checked in the background AOF Rewrite. Finished AOF The file contains the minimum set of instructions for the current dataset And the whole rewriting is safe, even if there is a shutdown in the rewriting process, the existing AOF Files will not be lost shortcoming: 1.If relative to the same data set, AOF The volume of the file is larger than RDB The volume of the file should be large 2.according to fsync Strategy, AOF May be slower than RDB. In general, every second fsync The performance of is still very high And close fsync Can let AOF Speed and RDB As fast
Persistence options
Generally speaking, if you want to achieve data security comparable to PostgreSQL, you should use both persistence functions at the same time.
If you care about your data very much, but can still withstand data loss within a few minutes, you can only use RDB persistence.
Many users only use AOF persistence, but we don't recommend this method: generating RDB snapshot s regularly is very convenient for database backup, and the speed of RDB recovery of data sets is faster than that of AOF recovery. In addition, using RDB can also avoid the bug of AOF program mentioned earlier.
For the reasons mentioned above, we may integrate AOF and RDB into a single persistence model in the future
Open AOF and RDB at the same time
On redis2 Before version 4. If AOF is enabled, only cancellation and repeated merging of log instruction sets will be performed
On redis2 4 and beyond. If AOF is enabled, rewriting will store the original data in the header of the AOF file in RDB
Then continue to increase the log by recording the log
So: in redis2 4 and later versions, AOF is a hybrid. The speed of RDB and the total amount of AOF are utilized
summary
From the summary of the notes above, we can draw a few points:
1.Redis is a memory based Middleware that can be used as a cache / database
2. The persistence mode of redis and the implementation principle of AOF and RDB
3. Characteristics and usage scenarios of each data type of redis