[dictionary structure used internally]
>hash
>The key and value in the whole Redis library also form a global dictionary
>key collection with expiration time
>The mapping relationship between value and score stored in Zset is also realized through dictionary structure
struct RedisDb { dict* dict; // all keys key=>value dict* expires; // all expired keys key=>long(timestamp) ... }
struct zset { dict *dict; // all values value=>score zskiplist *zsl; }
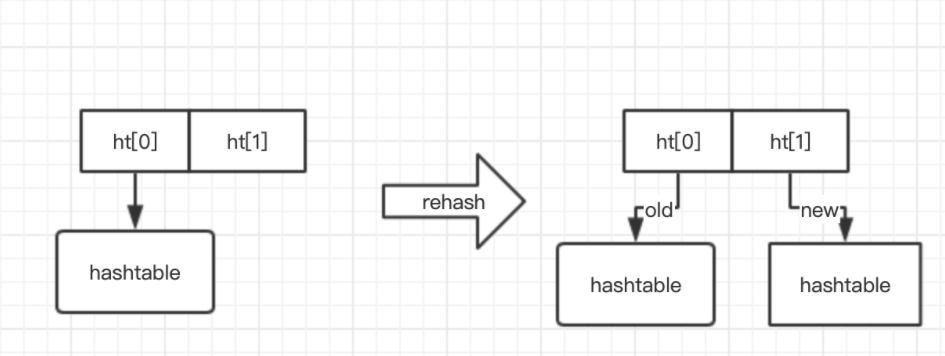
[dictionary internal structure]
The dictionary structure contains two hashtables. Usually, only one has a value. However, when the dictionary is expanded or shrunk, it is necessary to allocate a new hashtable and then move it gradually. At this time, the two hashtables store the old hashtable and the new hashtable respectively. After the move is completed, the old hashtable is deleted and the new hashtable is replaced.
Like hashmap in Java, the structure of hash is to hang a single linked list on an array.
Single linked list structure:
struct dictEntry { void* key; void* val; dictEntry* next; }
Hashtable structure:
struct dictht { dictEntry** table; long size; //Array length long used; //Number of elements ... }
[progressive rehash]
There are two relocation methods in Redis. One is lazy processing when adding elements to the dictionary; The other is a scheduled task, which combines the two to complete the whole migration. For a relatively large hash, this can effectively prevent the relocation of the Caton server caused by too large hash.
The process code for adding elements to the dictionary is as follows:
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing){ long index; dictEntry *entry; dictht *ht; //If it is in the process of relocation, carry out small-scale relocation if(dictIsRehashing(d)) _dictRehashStep(d); //-1 Indicates that the element exists if((index=_dictKeyIndex(d, key, dictHashKey(d,key),existing))==-1){ return NULL; } //Allocate new space. In this case, if it is a relocation process, hang the elements under the new array ht = dictIsRehashing(d) ? &d->ht[1]:&d->ht[0]; entry = zmalloc(sizeof(*entry)); entry->next = ht->table[index]; ht->table[index] = entry; ht->used++; dictSetKey(d, entry, key); return entry; }
Regular relocation process:
void databaseCron(){ ... if(server.activerehashing){ //You can see that the number of times in the scheduled task is also the rated maximum for(j=0;j<dbs_per_call;j++){ int work_done = incrementallyRehash(rehash_db); if(work_done){ break; }else{ //If this slot is not required rehash,Go to the next slot( db0,db1,...) rehash_db++; rehash_db %= server.dbnum; } } } }
[search process]
First, perform hash calculation according to the key and modulo operation with size to obtain the result, that is, the index in the following table of the array, and then query on the linked list at this position. Only if the hash mapping is uniform, the length of the two-dimensional linked list will not be very far.
Therefore, the performance of hashtable completely depends on the quality of hash function. If hash function can disperse key s evenly, then this hash function is a good function.
The default hash function of Redis dictionary is siphash.
[hash attack]
If the performance of hashtable is poor, resulting in uneven distribution, and even all elements are concentrated in individual chains, the search performance will decline, and the limited server computing resources may be dragged down by the search efficiency of hashtable.
[expansion and contraction conditions]
Capacity expansion
Under normal circumstances, when the number of elements in the hash table is equal to the length of the first dimensional array, it will start to expand the size to twice the original size.
However, when Redis performs bgsave, in order to reduce excessive separation of memory pages (at this time, it is using COW to support snapshot storage), Redis tries not to expand the capacity. However, if the hash table is very full and the number of elements reaches 5 times the length of the first dimensional array, it will be forced to expand the capacity.
Volume reduction
If the number of elements is less than 10% of the array length, it will shrink. bgsave will not be considered for shrinking.
[set structure]
The set implementation is also a dictionary, but all value s are NULL.
[thinking and expansion]
Here is a question: why not consider bgsave when shrinking. I think it is mainly due to the space utilization and the complexity of maintenance:
1. In terms of space utilization, shrinking itself is a process of constantly del releasing space. After a large number of del elements, the pages used by its parent process are constantly shrinking, and the space utilization rate is decreasing, so it is not considered.
2. From another perspective, talk about the hit problem of the changed linked list elements in the original page. During volume reduction, it is a process of a large number of dels, and the pages that may be involved have been copied. At this time, even if the remaining 1 / 10 elements change, the parent process does not need to copy a large number of old pages (there is a high probability that they have been copied in the previous del), or the probability is very small. However, if the capacity expansion is doubled, the operation will be performed. Although some old pages will be copied during the set process, two problems are considered here: 1 If you add to a new page, the old page does not copy because the old page has not changed; 2. If you add to the old page, you will copy, but only double the data. It is very likely that a large number of old pages have not been copied because of add. You can directly expand the capacity at this time. Well, the pages involved in the previous data will have a cow. This should be the additional and more cow said by the author. However, when the data grows to 5 times, on the one hand, some of the original linked lists may be very long, affecting the search efficiency. In addition, when the data grows by 5 times, the original old pages may have been copied because of the continuous add operation. At this time, the probability of capacity expansion and new copy will be much lower than before.
[reference]
Core principles and application practice of Redis deep Adventure