1, Introduction (please skip those who don't want to see)
-
Concept: redis is a high-performance NOSQL series non relational database
What is Redis?
Redis is an open-source high-performance key value database developed in C language. It officially provides test data. 50 concurrent 100000 requests are executed. The reading speed is 110000 times / s and the writing speed is 81000 times / s. redis provides a variety of key value data types to meet the storage requirements in different scenarios. So far, redis supports the following key value data types:
1) String type string
2) Hash type hash
3) List type list
4) Set type set
5) Ordered set type sortedset
redis application scenario
• caching (data queries, short connections, news content, product content, etc.)
• online friends list in chat room
• task queue. (second kill, rush purchase, 12306, etc.)
• app Leaderboard
• website access statistics
• data expiration processing (accurate to milliseconds)
• session separation in distributed cluster architecture
What is NOSQL?
NoSQL(NoSQL = Not Only SQL), which means "not just SQL", is a new database concept, generally referring to non relational databases.
With the development of internet web2 0 website, the traditional relational database is dealing with web2 0 websites, especially super large-scale and highly concurrent SNS type web2 0 pure dynamic website has been unable to meet its needs, exposing many insurmountable problems, while non relational database has developed very rapidly due to its own characteristics. The generation of NoSQL database is to solve the challenges brought by large-scale data sets and multiple data types, especially the problems of big data application.
Comparison between NOSQL and relational database
advantage:
1) Cost: nosql database is simple and easy to deploy. It is basically open source software. It does not need to spend a lot of cost to buy and use like using oracle. It is cheaper than relational database.
2) Query speed: nosql database stores the data in the cache, while relational database stores the data in the hard disk. Naturally, the query speed is far lower than that of nosql database.
3) Format for storing data: nosql is stored in the form of key,value, document, picture, etc., so it can store basic types and various formats such as objects or collections, while the database only supports basic types.
4) Extensibility: relational database has the limitation of multi table query mechanism like join, which makes it difficult to expand.
Disadvantages:
1) The tools and materials for maintenance are limited, because nosql is a new technology and cannot be compared with the technology of relational database for more than 10 years.
2) It does not provide support for sql. If it does not support industrial standards such as sql, it will cost users to learn and use.
3) Transaction processing by relational database is not provided.
Advantages of non relational database:
1) Performance NOSQL is based on key value pairs, which can be imagined as the corresponding relationship between the primary key and value in the table, and does not need to be parsed by the SQL layer, so the performance is very high.
2) Scalability is also because there is no coupling between data based on key value pairs, so it is very easy to expand horizontally.
Comparison and summary of two databases
Relational database and NoSQL database are not opposite but complementary, that is, relational database is usually used, and NoSQL database is used when NoSQL is suitable,
Let NoSQL database make up for the deficiency of relational database.
Generally, the data will be stored in the relational database, and the data of the relational database will be backed up and stored in the nosql database
-
Mainstream NOSQL products
The key value stores the database (redis used in this article is of this structure)
Related products: Tokyo Cabinet/Tyrant, Redis, Voldemort, Berkeley DB
Typical application: content caching, which is mainly used to handle the high access load of a large amount of data.
Data model: a series of key value pairs
Advantage: quick query
Disadvantage: the stored data is not structured
Column storage database
Related products: Cassandra, HBase, Riak
Typical application: distributed file system
Data model: it is stored in column clusters to store the same column of data together
Advantages: fast search speed, strong scalability and easier distributed expansion
Disadvantages: relatively limited functions
Document database
Related products: CouchDB, MongoDB
Typical application: Web application (similar to key Value, Value is structured)
Data model: a series of key value pairs
Advantage: the data structure requirements are not strict
Disadvantages: low query performance and lack of unified query syntax
Graph database
Related databases: Neo4J, InfoGrid, Infinite Graph
Typical application: Social Network
Data model: diagram structure
Advantages: using graph structure related algorithms.
Disadvantages: you need to calculate the whole graph to get the results. It is not easy to make a distributed cluster scheme.
2, Download, install and use
1. Download and install
- Official website: https://redis.io
- Chinese website: http://www.redis.net.cn/
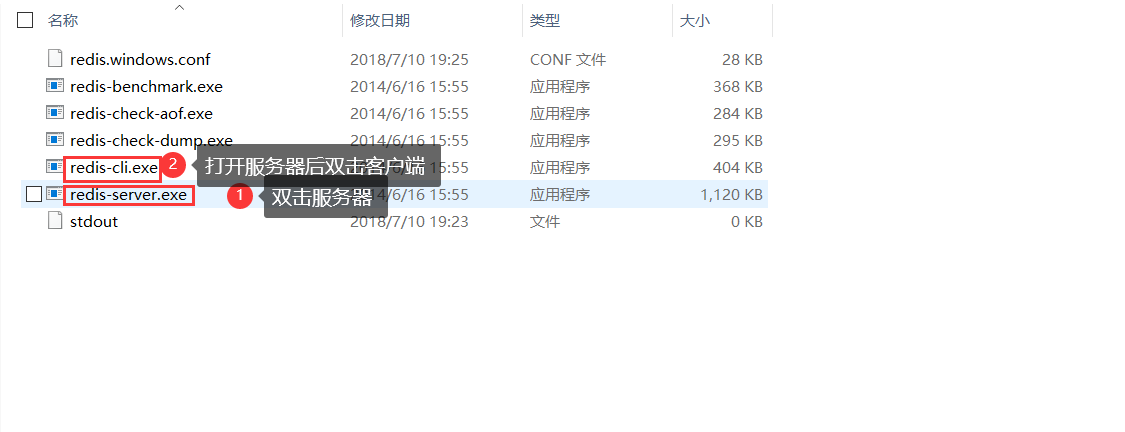
- You can decompress directly using:
* redis.windows.conf: configuration file
* redis-cli.exe: redis client
* redis-server.exe: redis server side
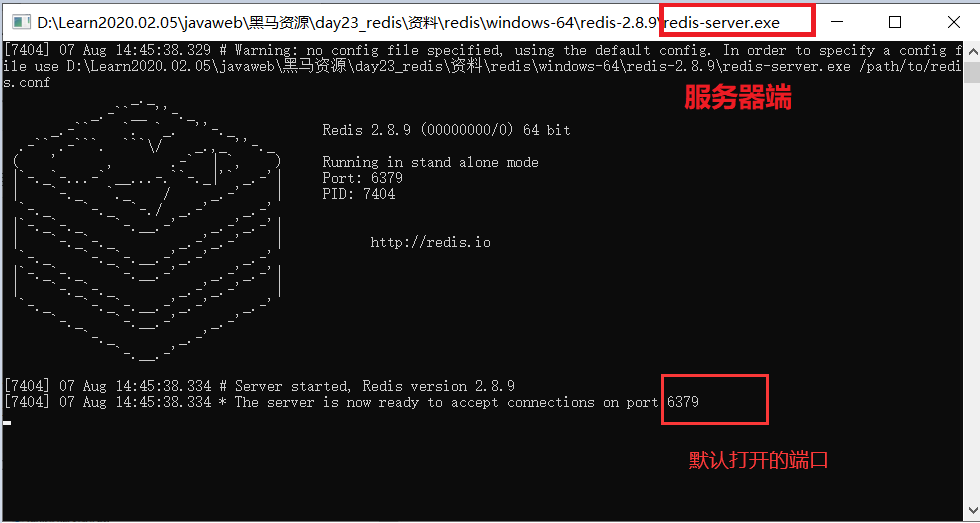
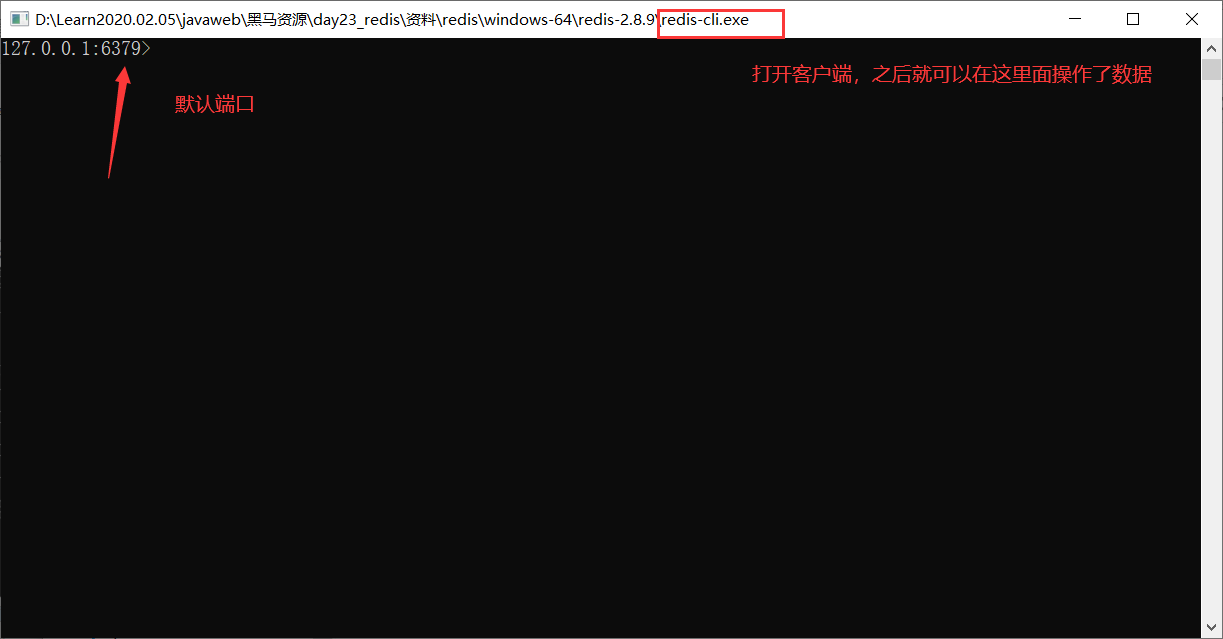
2. Use
This is the extracted file
 redis data structure:
redis data structure:
redis stores data in the format of key and value, where key is a string and value has five different data structures
Data structure of value:
1) String type string
2) Hash type hash: map format
3) List type list: linkedlist format. Duplicate elements are supported
4) Collection type set: duplicate elements are not allowed
5) Ordered collection type sortedset: duplicate elements are not allowed, and the elements are in order
The following operations will be performed on these data structures
Mainly storage, acquisition and deletion
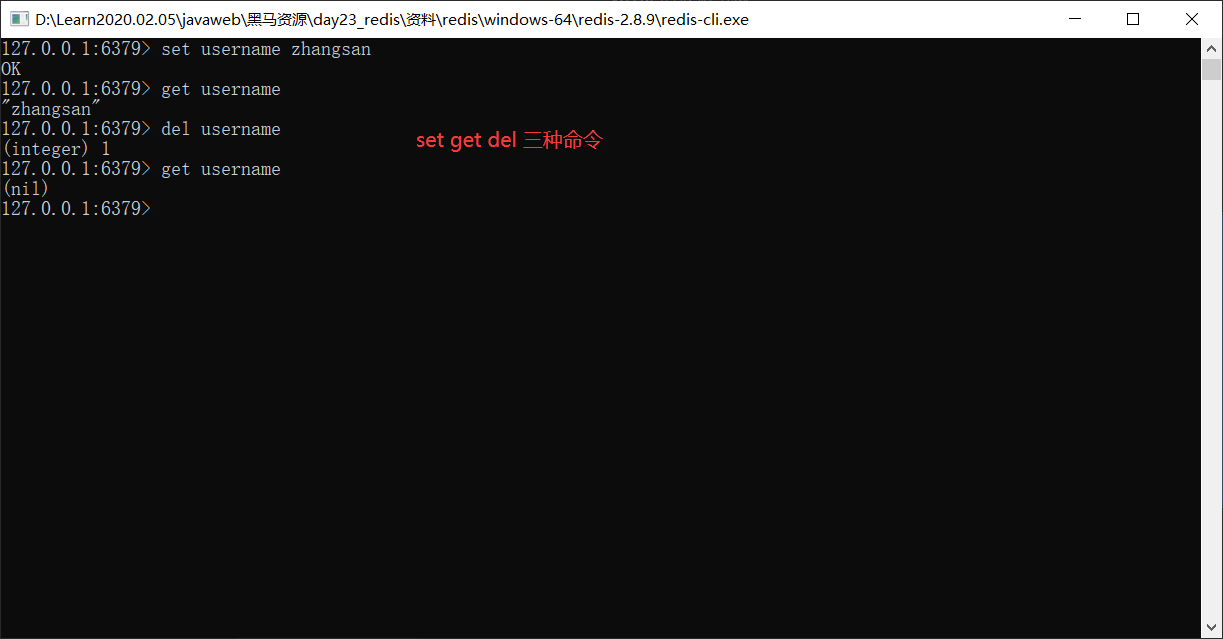
1.String type string 1. Storage: set key value 127.0.0.1:6379> set username zhangsan OK 2. obtain: get key 127.0.0.1:6379> get username "zhangsan" 3. Delete: del key 127.0.0.1:6379> del age (integer) 1
2.Hash type hash 1. Storage: hset key field value 127.0.0.1:6379> hset myhash username lisi (integer) 1 127.0.0.1:6379> hset myhash password 123 (integer) 1 2. obtain: hget key field: Gets the specified field Corresponding value 127.0.0.1:6379> hget myhash username "lisi" hgetall key: Get all field and value 127.0.0.1:6379> hgetall myhash 1) "username" 2) "lisi" 3) "password" 4) "123" 3. Delete: hdel key field 127.0.0.1:6379> hdel myhash username (integer) 1
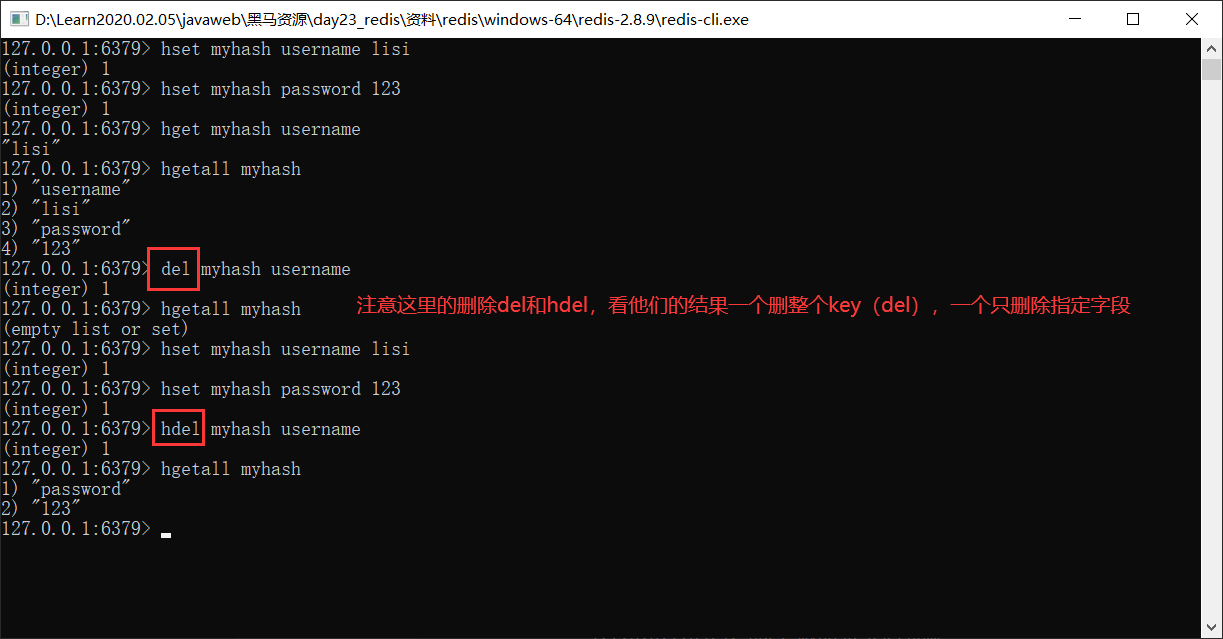
3.List type list:You can add an element to the head (left) or tail (right) of the list 1. add to: lpush key value: Add elements to the left table of the list rpush key value: Add elements to the right of the list 127.0.0.1:6379> lpush myList a (integer) 1 127.0.0.1:6379> lpush myList b (integer) 2 127.0.0.1:6379> rpush myList c (integer) 3 2. obtain: * lrange key start end : Range acquisition 127.0.0.1:6379> lrange myList 0 -1 1) "b" 2) "a" 3) "c" 3. Delete: * lpop key: Delete the leftmost element of the list and return the element * rpop key: Delete the rightmost element of the list and return the element
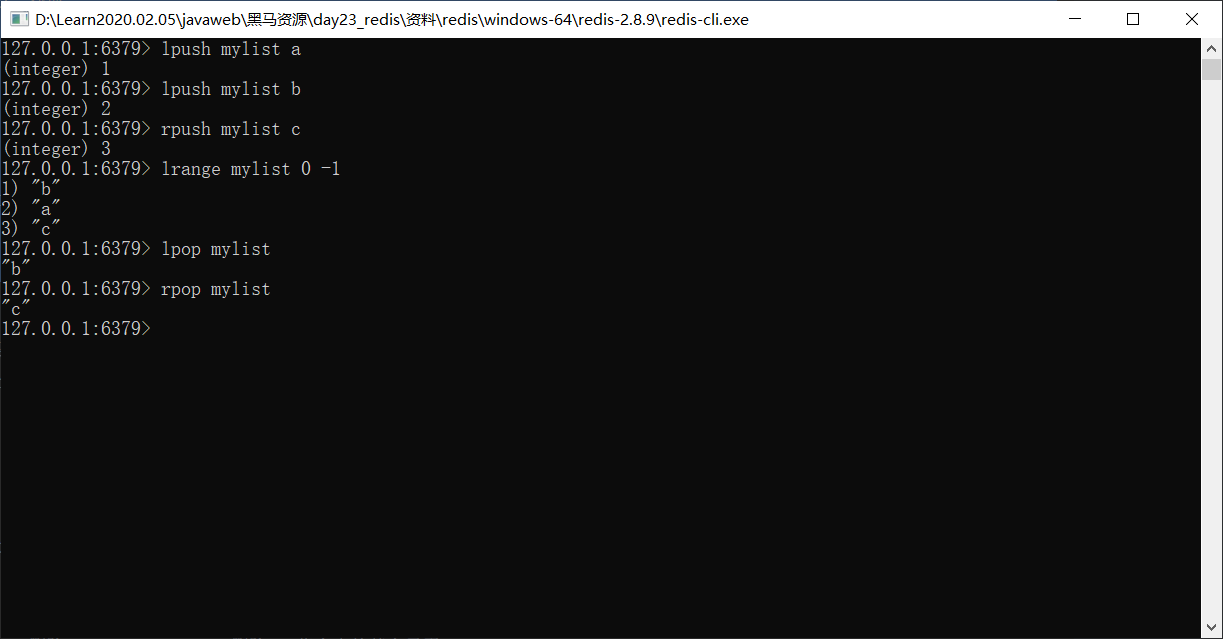
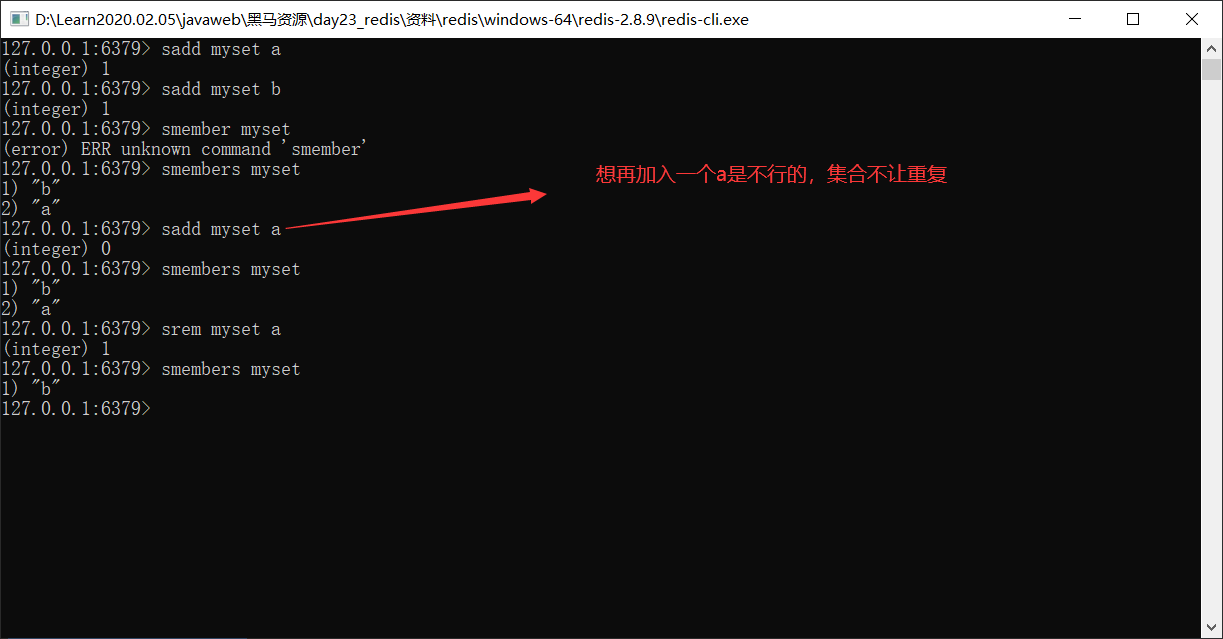
4.Collection type set : Duplicate elements are not allowed 1. Storage: sadd key value 127.0.0.1:6379> sadd myset a (integer) 1 127.0.0.1:6379> sadd myset a (integer) 0 2. obtain: smembers key:obtain set All elements in the collection 127.0.0.1:6379> smembers myset 1) "a" 3. Delete: srem key value:delete set An element in a collection 127.0.0.1:6379> srem myset a (integer) 1
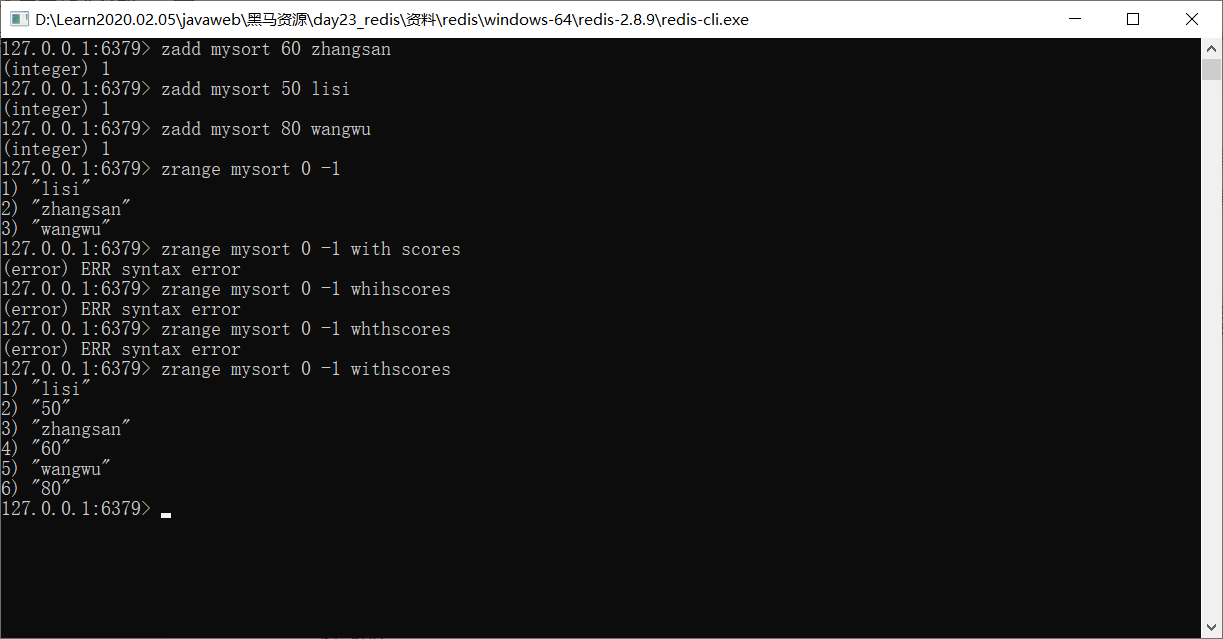
5.Ordered set type sortedset: Duplicate elements are not allowed, and the elements are in order. Each element will be associated with one double Score of type. redis It is through scores that the members of the set are sorted from small to large. 1. Storage: zadd key score value 127.0.0.1:6379> zadd mysort 60 zhangsan (integer) 1 127.0.0.1:6379> zadd mysort 50 lisi (integer) 1 127.0.0.1:6379> zadd mysort 80 wangwu (integer) 1 2. obtain: zrange key start end [withscores] 127.0.0.1:6379> zrange mysort 0 -1 1) "lisi" 2) "zhangsan" 3) "wangwu" 127.0.0.1:6379> zrange mysort 0 -1 withscores 1) "zhangsan" 2) "60" 3) "wangwu" 4) "80" 5) "lisi" 6) "500" 3. Delete: zrem key value 127.0.0.1:6379> zrem mysort lisi (integer) 1d
General commands: 1. keys * : Query all keys 2. type key : Get the corresponding key value Type of 3. del key: Delete the specified key value
3, redis persistence
Redis is a memory database. When the redis server restarts and the computer restarts, the data will be lost. We can persist the data in redis memory and save it to the file on the hard disk.
After you shut down the redis server, the next time you open the server, the data stored in the hard disk can be read out.
redis persistence mechanism (two methods)
1. RDB: By default, this mechanism is used by default without configuration * At certain intervals, detection key And then persist the data 1. edit redis.windwos.conf file # after 900 sec (15 min) if at least 1 key changed save 900 1 # after 300 sec (5 min) if at least 10 keys changed save 300 10 # after 60 sec if at least 10000 keys changed save 60 10000 2. Restart redis Server and specify the profile name (In there redis-server.exe Under folder shift + Right click to open here powerShell Window so that you can specify the configuration file (see the video below) D:\Learn2020.02.05\javaweb\Dark horse resources\day23_redis\data\redis\windows-64\redis-2.8.9> .\redis-server.exe .\redis.windows.conf
Edit redis windwos. Conf file
Before modification
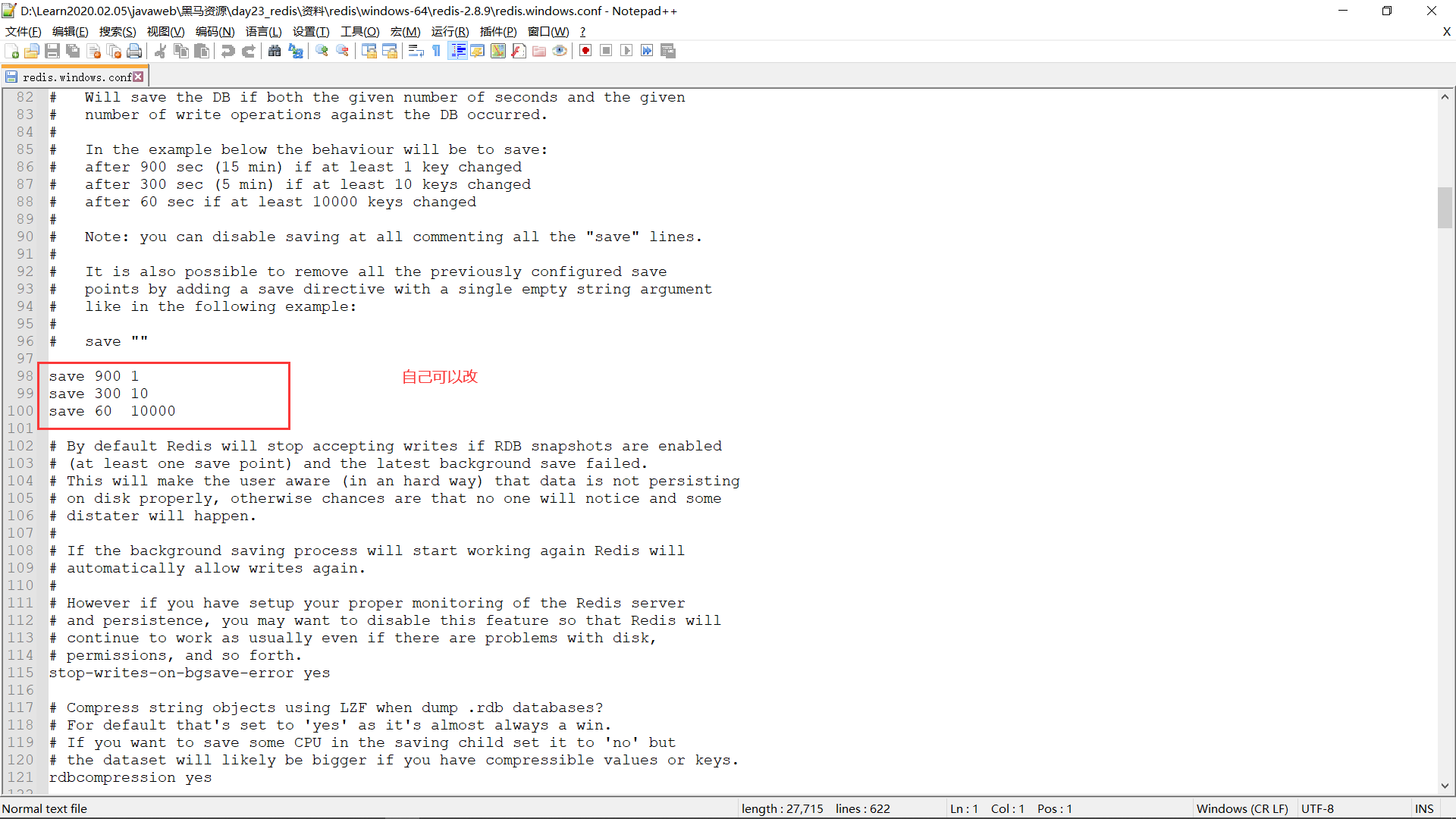
After modification
Specify file open server
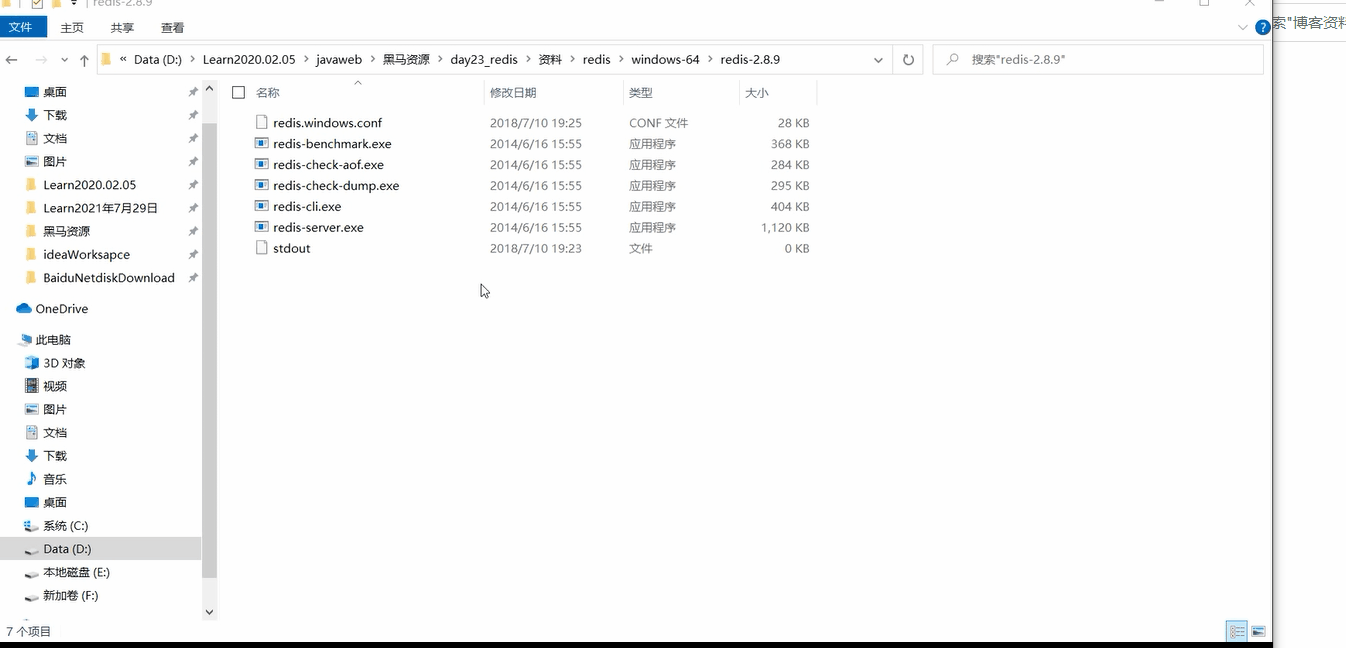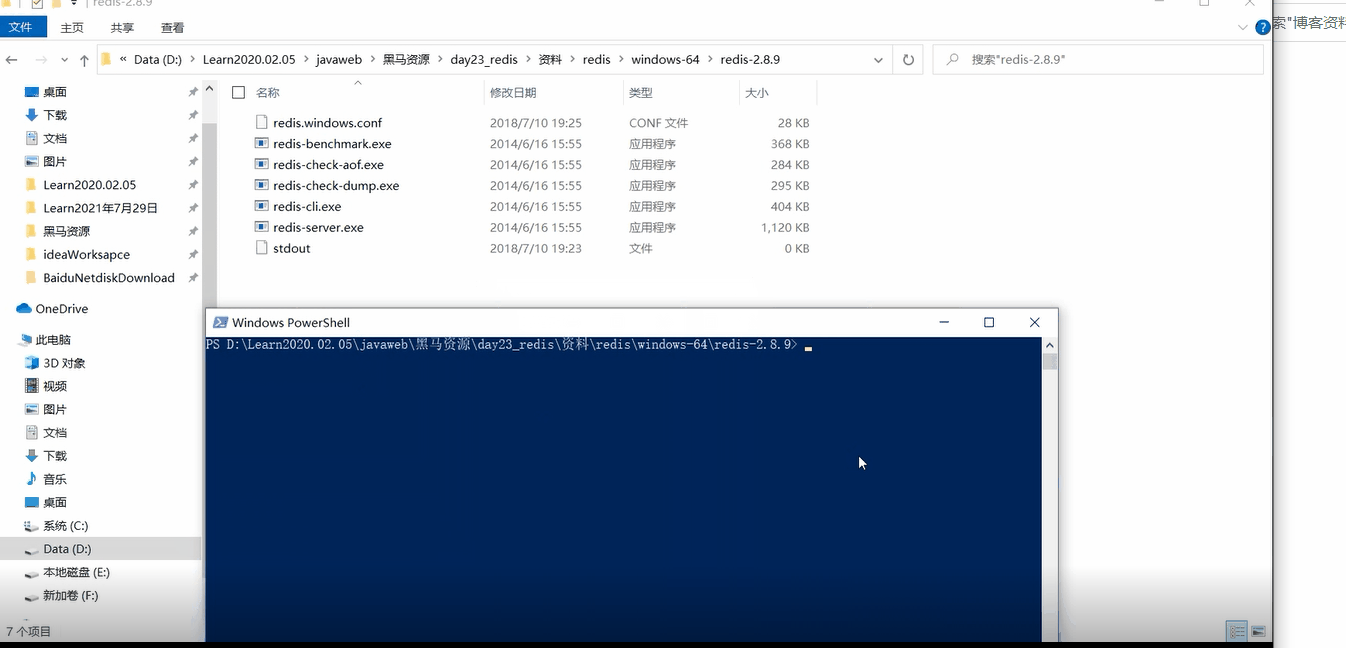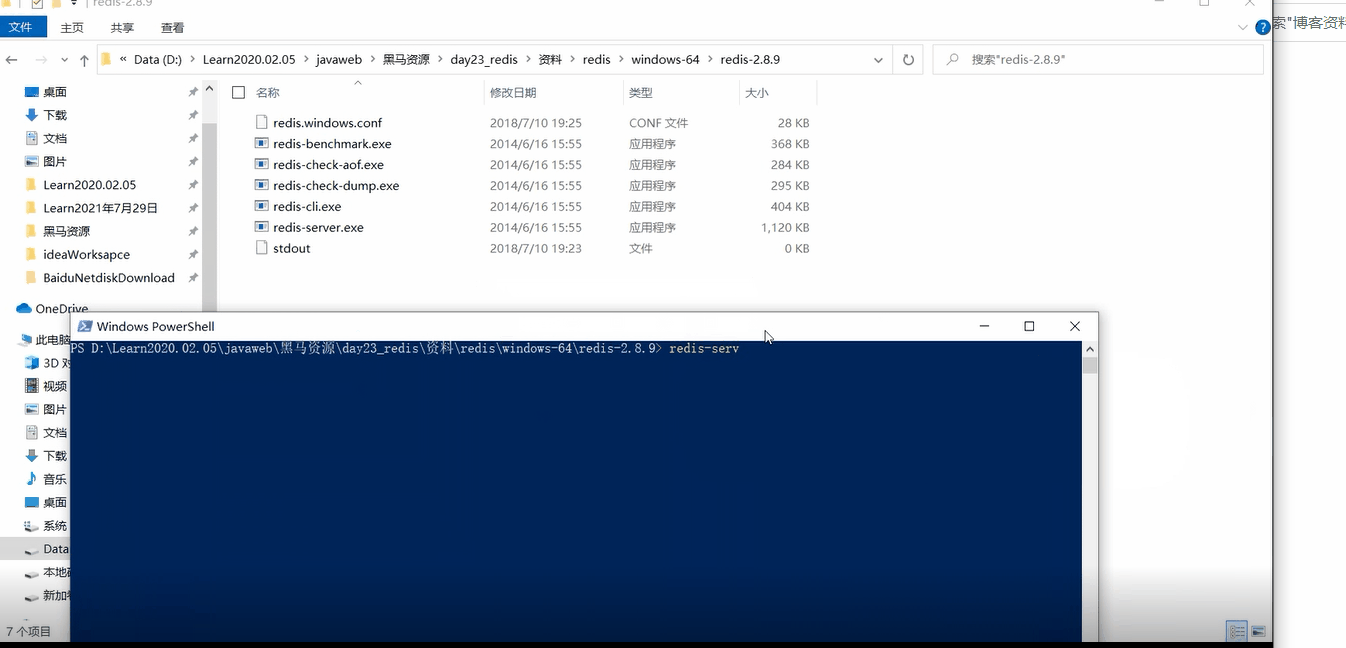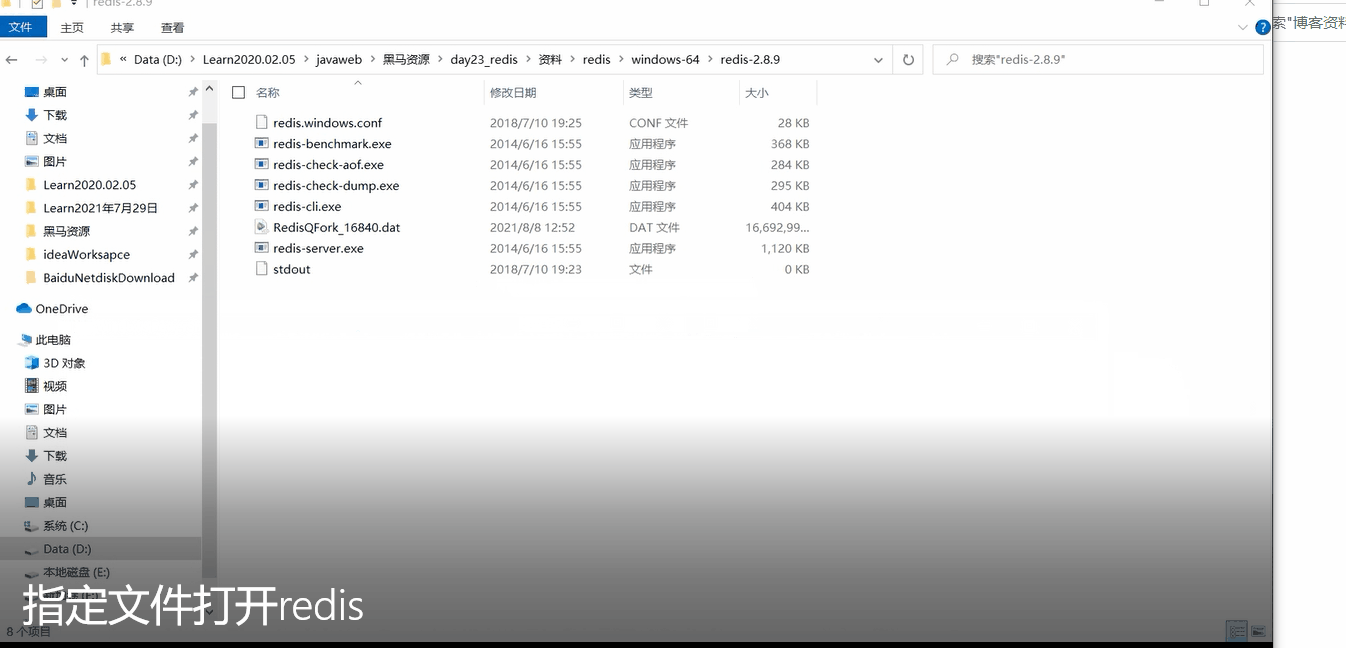
After opening the server, open the client, and generate one for five key operations dbf file (this is just a demonstration to change the configuration file. After changing the configuration file, change the previous one back, and then open the configuration file to restore the default server.)
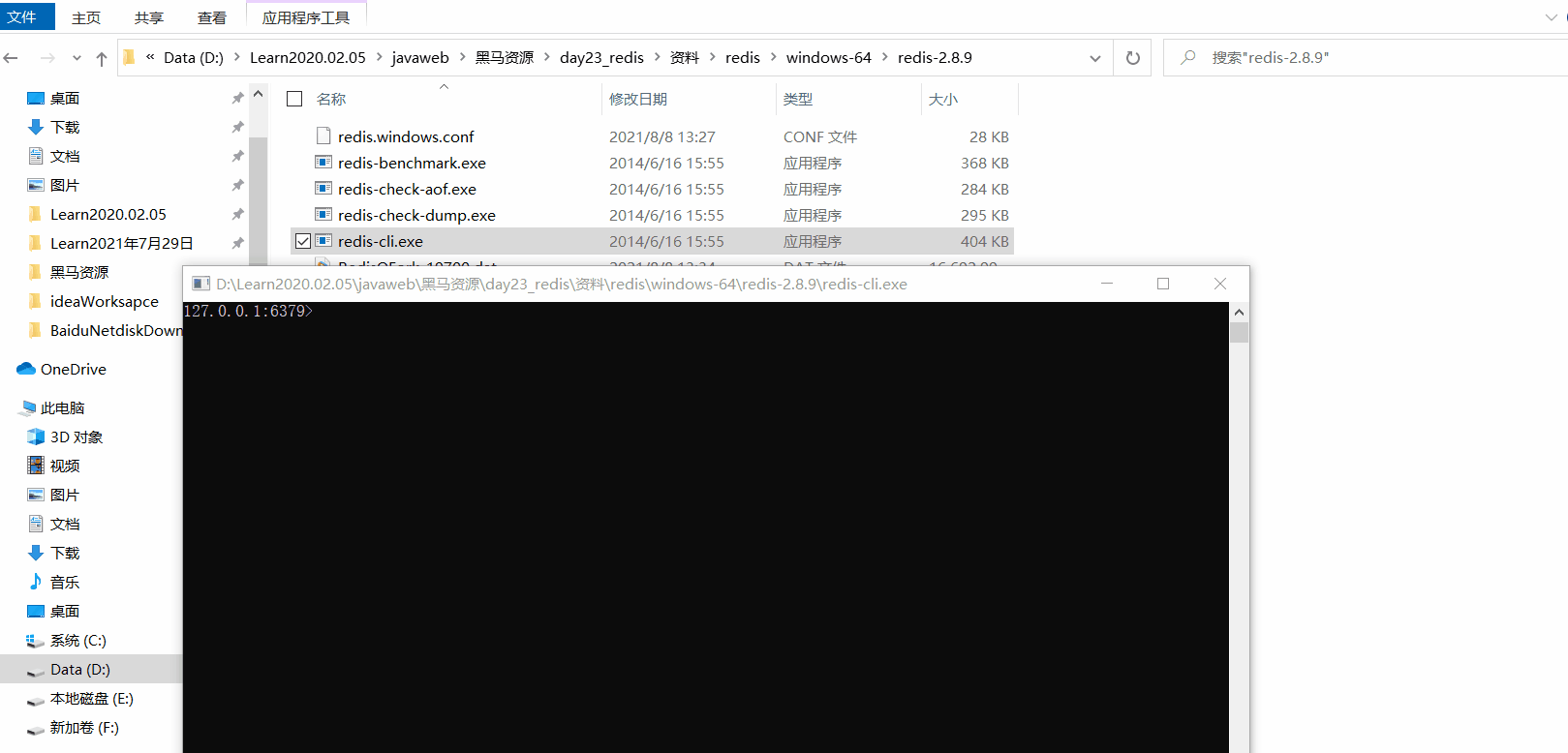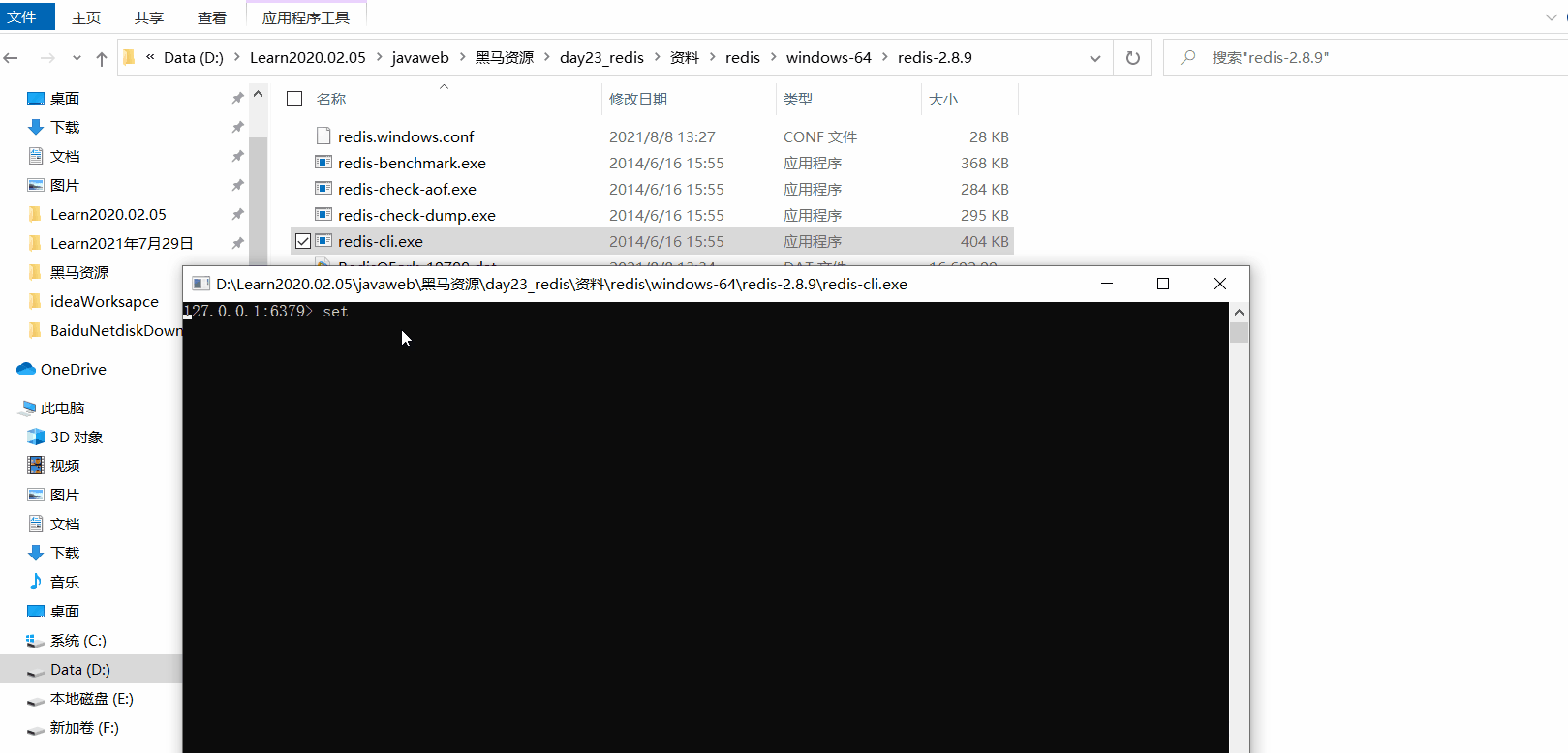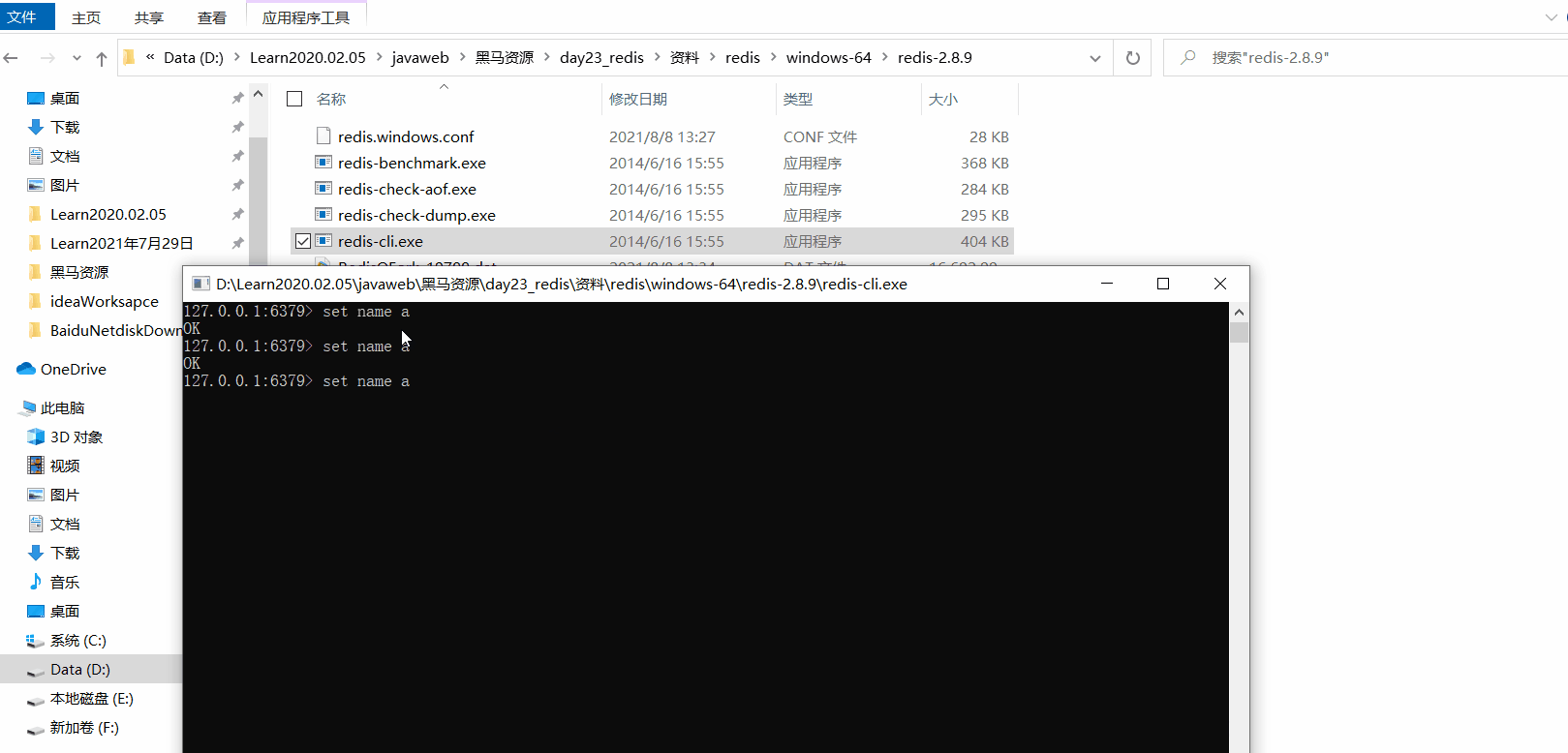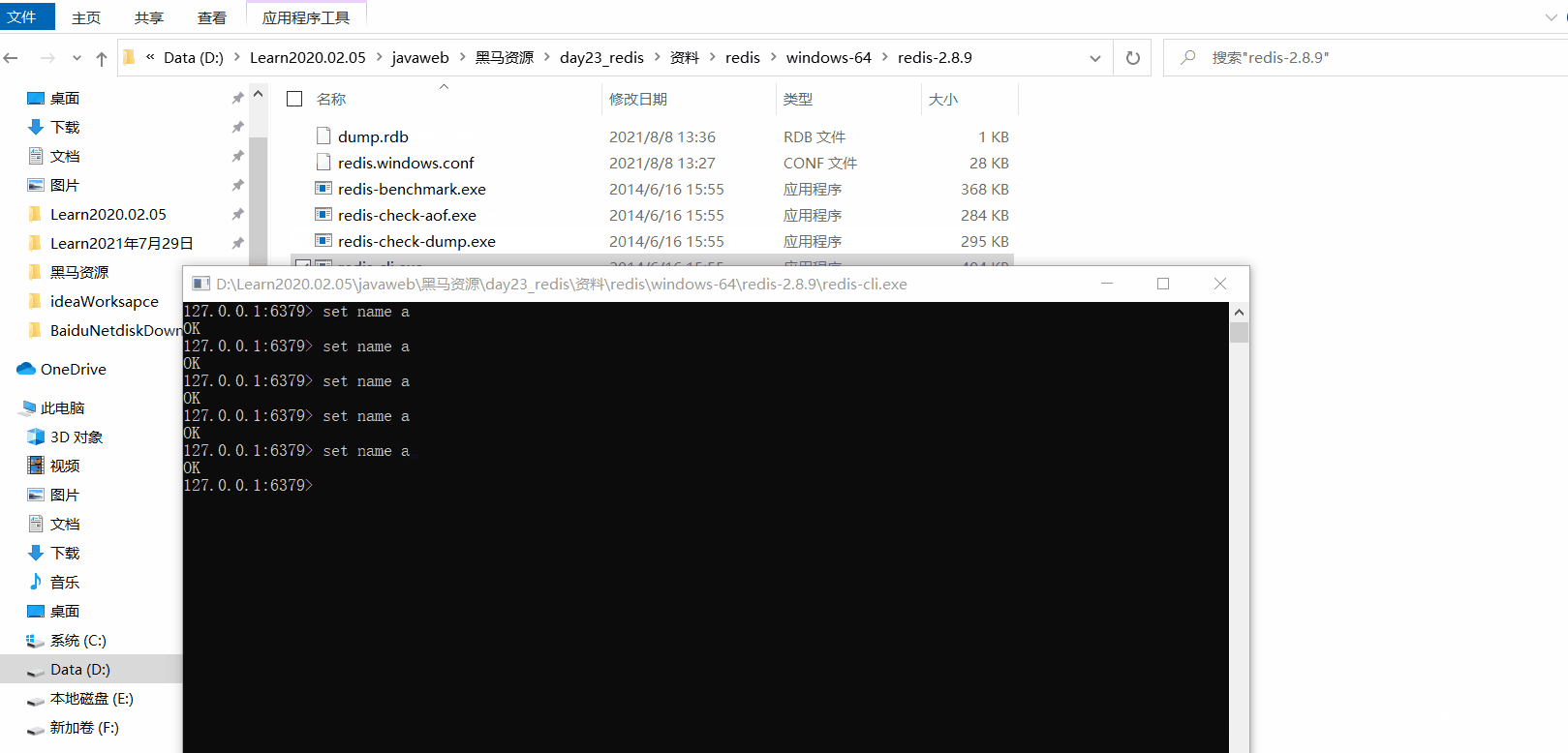
Take a closer look at the dbf file generated in the last video. At this time, the data is persisted to the hard disk. After that, you can turn off the server and turn it on again. You can get your data by using get key
2.AOF: The operation of each command can be recorded by logging. You can persist data after each command operation (It has a great impact on performance. Executing a command will persist data once)There is no detailed introduction here) 1. edit redis.windwos.conf file appendonly no(close aof) --> appendonly yes (open aof) # appendfsync always: persistent for each operation appendfsync everysec : Persistence occurs every second # appendfsync no : No persistence